Simplifique las pruebas de PySpark con funciones de igualdad de DataFrame
Presentación de las funciones de prueba de igualdad de PySpark DataFrame, por qué son importantes y cómo usarlas.
por Haejoon Lee, Allison Wang y Amanda Liu
Las funciones de prueba de igualdad de DataFrame se introdujeron en Apache Spark™ 3.5 y Databricks Runtime 14.2 para simplificar las pruebas unitarias de PySpark. El conjunto completo de capacidades que se describen en esta entrada de blog estará disponible a partir de las próximas versiones de Apache Spark 4.0 y Databricks Runtime 14.3.
Escriba transformaciones de DataFrame más seguras con funciones de prueba de igualdad de DataFrame
Trabajar con datos en PySpark implica aplicar transformaciones, agregaciones y manipulaciones a los DataFrames. A medida que se acumulan las transformaciones, ¿cómo puede estar seguro de que su código funciona según lo previsto? Las funciones de utilidad de prueba de igualdad de PySpark proporcionan una forma eficaz y efectiva de comprobar sus datos con los resultados esperados, lo que le ayuda a identificar diferencias inesperadas y detectar errores al principio del proceso de análisis. Además, devuelven información intuitiva que señala con precisión las diferencias para que pueda actuar de inmediato sin perder mucho tiempo en la depuración.
Uso de funciones de prueba de igualdad de DataFrame
En Apache Spark 3.5 se introdujeron dos funciones de prueba de igualdad para DataFrames de PySpark: assertDataFrameEqual y assertSchemaEqual. Echemos un vistazo a cómo usar cada una de ellas.
assertDataFrameEqual: Esta función le permite comparar dos DataFrames de PySpark para comprobar la igualdad con una sola línea de código, comprobando si los datos y los esquemas coinciden. Devuelve información descriptiva cuando hay diferencias.
Veamos un ejemplo. Primero, crearemos dos DataFrames, introduciendo intencionadamente una diferencia en la primera fila:
A continuación, llamaremos a assertDataFrameEqual con los dos DataFrames:
La función devuelve un mensaje descriptivo que indica que la primera fila de los dos DataFrames es diferente. En este ejemplo, las primeras cantidades enumeradas para Alfred en esta fila no son las mismas (esperado: 1500, real: 1200):
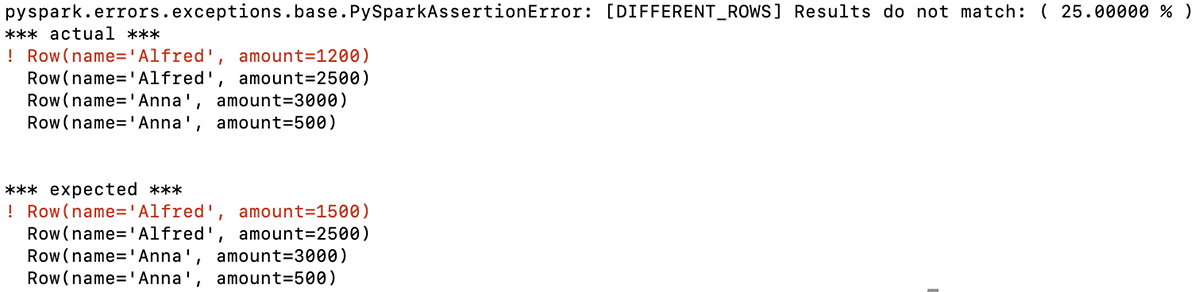
Con esta información, sabe inmediatamente el problema con el DataFrame que generó su código y puede dirigir su depuración en función de eso.
La función también tiene varias opciones para controlar la rigurosidad de la comparación de DataFrame para que pueda ajustarla de acuerdo con sus casos de uso específicos.
assertSchemaEqual: Esta función compara solo los esquemas de dos DataFrames; no compara los datos de las filas. Le permite validar si los nombres de las columnas, los tipos de datos y la propiedad que acepta valores NULL son los mismos para dos DataFrames diferentes.
Veamos un ejemplo. Primero, crearemos dos DataFrames con esquemas diferentes:
Ahora, llamemos a assertSchemaEqual con estos dos esquemas de DataFrame:
La función determina que los esquemas de los dos DataFrames son diferentes, y la salida indica dónde divergen:

En este ejemplo, hay dos diferencias: el tipo de datos de la columna amount es LONG en el DataFrame real, pero DOUBLE en el DataFrame esperado, y como creamos el DataFrame esperado sin especificar un esquema, los nombres de las columnas también son diferentes.
Ambas diferencias se resaltan en la salida de la función, como se ilustra aquí.
assertPandasOnSparkEqual no se trata en esta entrada de blog, ya que está en desuso desde Apache Spark 3.5.1 y está previsto que se elimine en la próxima versión de Apache Spark 4.0.0. Para probar la API de Pandas en Spark, consulte Funciones de prueba de igualdad de la API de Pandas en Spark.
Salida estructurada para depurar diferencias en DataFrames de PySpark
Si bien las funciones assertDataFrameEqual y assertSchemaEqual están dirigidas principalmente a las pruebas unitarias, donde normalmente se usan conjuntos de datos más pequeños para probar sus funciones de PySpark, puede usarlas con DataFrames con más de unas pocas filas y columnas. En tales escenarios, puede recuperar fácilmente los datos de las filas que son diferentes para facilitar aún más la depuración.
Veamos cómo hacerlo. Usaremos los mismos datos que usamos antes para crear dos DataFrames:
Y ahora tomaremos los datos que difieren entre los dos DataFrames de los objetos de error de aserción después de llamar a assertDataFrameEqual:
La creación de un DataFrame basado en las filas que son diferentes y su visualización, como hemos hecho en este ejemplo, ilustra lo fácil que es acceder a esta información:

Como puede ver, la información sobre las filas que son diferentes está disponible de inmediato para su posterior análisis. Ya no tiene que escribir código para extraer esta información de los DataFrames reales y esperados con fines de depuración.
Esta característica estará disponible a partir de las próximas versiones de Apache Spark 4.0 y DBR 14.3.
Funciones de prueba de igualdad de la API de Pandas en Spark
Además de las funciones para probar la igualdad de DataFrames de PySpark, los usuarios de la API de Pandas en Spark tendrán acceso a las siguientes funciones de prueba de igualdad de DataFrame:
assert_frame_equalassert_series_equalassert_index_equal
Las funciones proporcionan opciones para controlar la rigurosidad de las comparaciones y son excelentes para las pruebas unitarias de su API de Pandas en DataFrames de Spark. Proporcionan exactamente la misma API que las funciones de utilidad de prueba de pandas, por lo que puede usarlas sin cambiar el código de prueba de pandas existente que desea ejecutar usando la API de Pandas en Spark.
Aquí hay un par de ejemplos que demuestran el uso de assert_frame_equal con diferentes parámetros, comparando la API de Pandas en DataFrames de Spark:
En este ejemplo, los esquemas de los dos DataFrames son diferentes. La salida de la función enumera las diferencias, como se muestra aquí:

Podemos especificar que queremos que la función compare los datos de las columnas incluso cuando las columnas no tienen el mismo tipo de datos usando el argumento check_dtype, como en este ejemplo:
Dado que especificamos que assert_frame_equal debe ignorar los tipos de datos de las columnas, ahora considera que los dos DataFrames son iguales.
Estas funciones también permiten comparaciones entre la API de Pandas en objetos Spark y objetos pandas, lo que facilita las comprobaciones de compatibilidad entre diferentes bibliotecas de DataFrame, como se ilustra en este ejemplo:
Usar las nuevas funciones de prueba de igualdad de DataFrame de PySpark y la API de Pandas en Spark es una excelente manera de asegurarse de que su código de PySpark funciona según lo previsto. Estas funciones le ayudan no solo a detectar errores, sino también a comprender exactamente qué ha ido mal, lo que le permite identificar rápida y fácilmente dónde está el problema. Consulte la página Testing PySpark para obtener más información.
Estas funciones estarán disponibles a partir de la próxima versión de Apache Spark 4.0. DBR 14.2 ya lo admite.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.