Transformando los informes de mantenimiento solar y eólico con Genie y agentes de AI
Cómo Plenitude utiliza Databricks Genie y Agent Bricks para transformar PDF de mantenimiento no estructurados en una capa de datos consultable y analítica en lenguaje natural en plantas solares y eólicas.
por Maria Vallarelli
- Plenitude desarrolló un sistema basado en agentes sobre Databricks Genie que convierte PDF no estructurados de mantenimiento solar y eólico en un modelo de datos unificado y consultable.
- La solución utiliza Genie, junto con los metadatos semánticos de Unity Catalog y AI Functions, para permitir a los usuarios realizar preguntas en lenguaje natural y crear visualizaciones entre plantas y a lo largo del tiempo.
- Los primeros resultados incluyen un análisis multiplanta más rápido, acceso de autoservicio gobernado con seguridad a nivel de fila y una base para el mantenimiento predictivo de activos críticos como inversores.
De PDFs de mantenimiento a información accionable con agentes de AI
Los proveedores de operaciones y mantenimiento de plantas solares y eólicas suelen entregar informes en formato PDF, con información clave distribuida en texto libre, tablas e imágenes. Este formato es accesible pero no escalable: los equipos deben leer manualmente cada documento para comprender fallas, tendencias o problemas recurrentes, lo que hace que las comparaciones entre plantas sean lentas e inconsistentes a medida que crece el número de activos.
Plenitude y Databricks crearon un sistema basado en agentes que convierte estos informes de mantenimiento en PDF en datos estructurados. La idea central es simple: transformar documentos en datos y luego usar un agente de AI para obtener información accionable a partir de esos datos. Ahora, los usuarios pueden hacer preguntas en lenguaje natural, analizar tendencias a lo largo del tiempo, comparar plantas y exportar resultados estructurados, en lugar de navegar por los informes uno por uno.
Arquitectura basada en agentes para analítica de datos a partir de PDFs
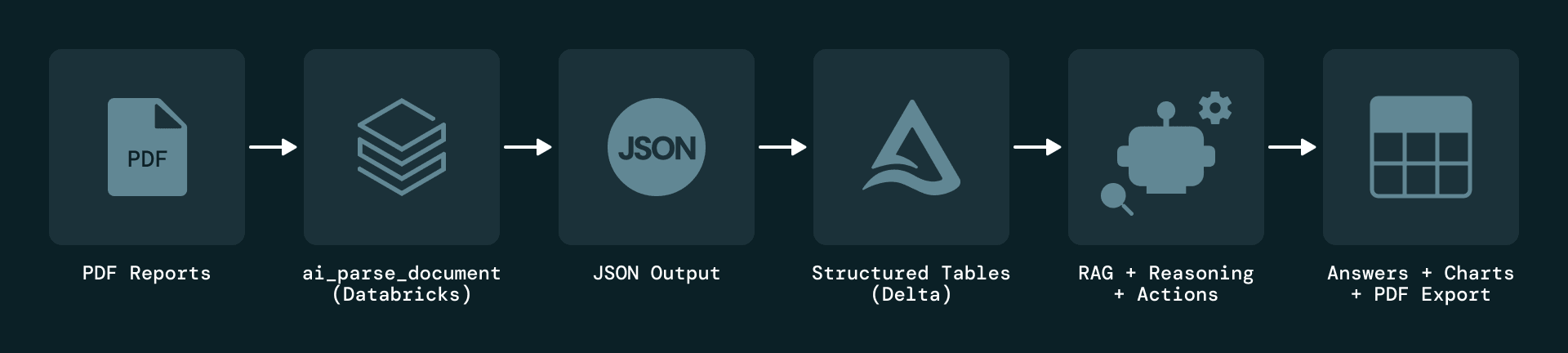
La solución comienza con la ingesta basada en eventos de informes en PDF a nivel de planta. Cada nuevo informe activa un Databricks Job que analiza el documento y aplica una extracción basada en LLM. Los elementos extraídos se serializan como JSON y se almacenan en Delta Lake, que mantiene un historial de versiones completo para auditoría y reproducción.
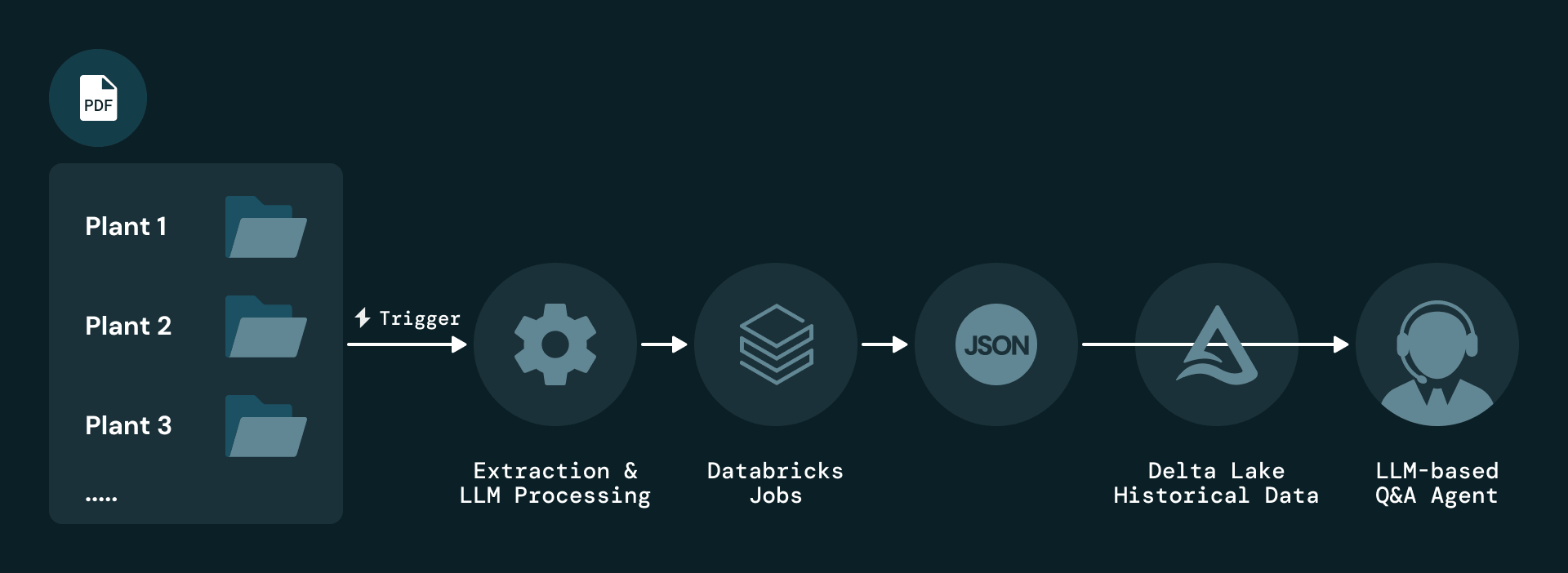
Para abordar el problema fundamental de que la información de mantenimiento reside casi por completo en PDFs no estructurados, Plenitude utiliza las AI Functions de Databricks Document Intelligence, específicamente ai_parse_document, para extraer múltiples tipos de elementos de cada página, incluidos bloques de texto, tablas, figuras y metadatos. Cada elemento se enriquece con atributos como planta, período del informe, número de página y tipo de contenido, y cada registro mantiene un enlace directo al informe original para garantizar la trazabilidad.
Esta estructura habilita capacidades potentes:
- Filtrado por tiempo, categoría y geografía.
- Identificación de tipos de contenido y uso de coordenadas espaciales.
- Trazabilidad de cada insight hasta el PDF original.
- Integración con herramientas de BI y agentes digitales sin modificar los documentos subyacentes.
En lugar de archivos estáticos, los informes de mantenimiento se convierten en una capa de datos persistente lista para la analítica avanzada y el razonamiento de agentes.
Procesamiento de datos en Databricks: de PDF a Delta Lake
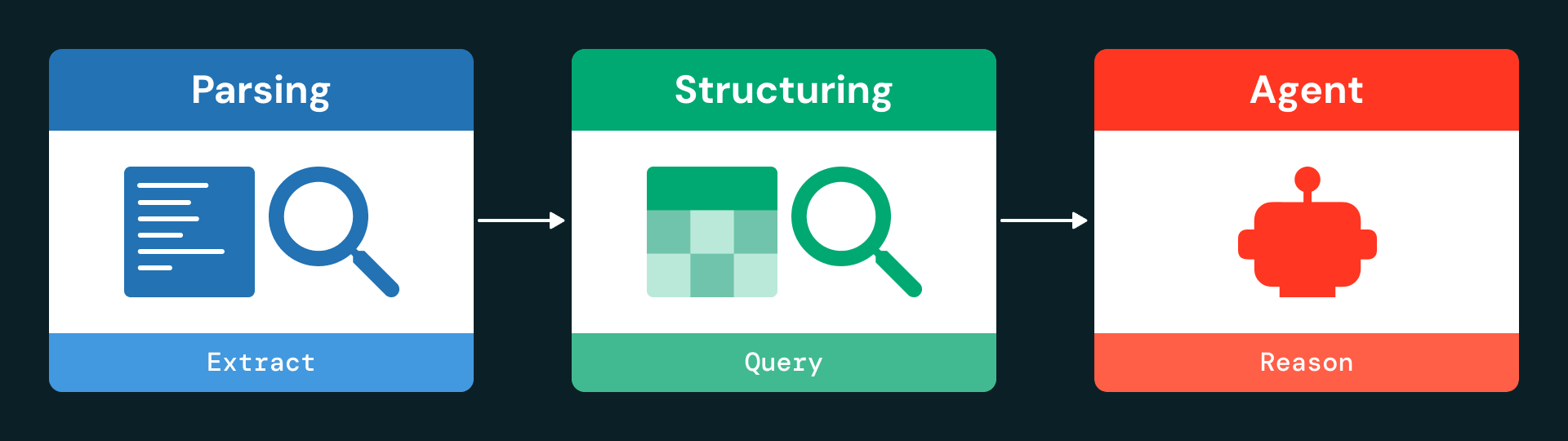
La arquitectura se organiza en tres capas principales: ingesta y análisis, estructuración de datos e interacción basada en agentes.
Paso 1: análisis
Mediante el uso de ai_parse_document, el pipeline extrae texto, tablas y metadatos de cada página y los serializa como objetos JSON estructurados. Incluso las tablas complejas se capturan con todo su contexto, incluida su ubicación en la página y su representación en HTML.
Paso 2: normalización y almacenamiento
Para cada página (page_id) y objeto (id), el sistema crea una fila en una tabla de Delta Lake. Cada fila contiene:
- El contenido JSON extraído.
- Identificadores de página y de objeto.
- Coordenadas (coords) que representan el cuadro delimitador en la página.
- Tipo de contenido (por ejemplo, texto o tabla).
- Metadatos de alto valor como mes, año, nombre de archivo, categoría y país.
Este modelo normalizado convierte los PDFs en un conjunto de datos unificado y consultable que es transparente y fácil de combinar con otras fuentes, al tiempo que conserva la trazabilidad completa de los documentos originales.
Paso 3: espacio de Genie y modo Agent
Sobre esta capa de datos depurada, Plenitude crea un espacio de Genie dedicado y luego aprovecha el modo Agent de Genie para realizar una investigación profunda en los datos. Genie utiliza las tablas estructuradas de Delta Lake como su contexto principal y permite a los usuarios interactuar con los datos de mantenimiento mediante lenguaje natural.
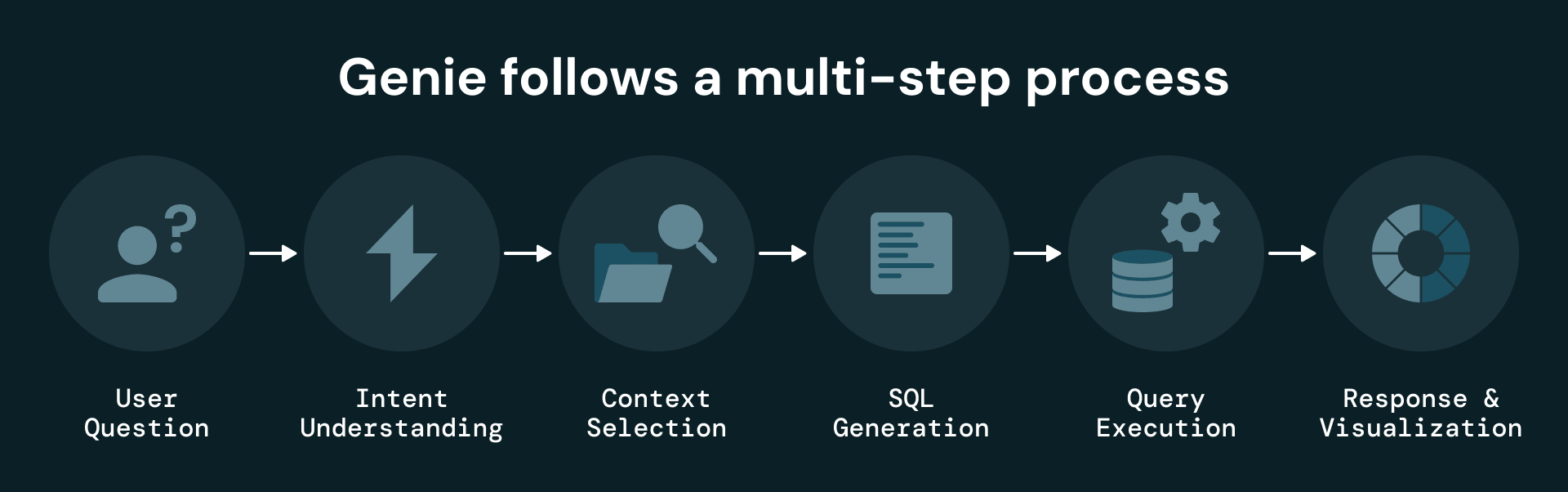
Cuando un usuario hace una pregunta, Genie:
- Utiliza metadatos semánticos en Unity Catalog para identificar las tablas y columnas disponibles.
- Aprovecha descripciones detalladas de columnas, un repositorio de conocimiento depurado y muestras de SQL para guiar la generación de consultas.
- Genera y ejecuta SQL contra la capa estructurada.
- Devuelve respuestas, visualizaciones y, opcionalmente, resultados exportables.
Este diseño permite a Genie comprender tanto la semántica empresarial de los datos de mantenimiento como su estructura subyacente, lo que da como resultado respuestas precisas y conscientes del contexto.
Por qué los metadatos y las instrucciones son importantes para Genie
Para obtener resultados confiables a partir de conjuntos de datos complejos derivados de PDFs, el contexto por sí solo no es suficiente. Plenitude descubrió que dos patrones de diseño son fundamentales: metadatos enriquecidos e instrucciones explícitas para el espacio de Genie.
Los metadatos como un contrato con el agente
Las descripciones bien definidas de tablas y columnas le indican a Genie qué significa cada campo y cómo debe utilizarse. Por ejemplo, page_id identifica la página de origen en el informe original, type indica si el elemento es texto o una tabla, coords codifica la ubicación espacial y content contiene el texto extraído o la representación de la tabla. Estos metadatos convierten el JSON sin procesar en conocimiento comprensible sobre el cual Genie puede razonar.
Instrucciones generales como base operativa
Cuando los datos están fragmentados o abarcan varias páginas, las instrucciones específicas del dominio agregadas al repositorio de conocimiento local del espacio de Genie se vuelven esenciales. Plenitude codifica reglas para manejar tablas de varias páginas, ignorar artefactos HTML, excluir filas de encabezado y aplicar filtros específicos de la planta.
Un ejemplo práctico: incluso con metadatos completos, Genie podría calcular un total trimestral incorrecto si suma las columnas YTD o ignora los meses faltantes. Al agregar instrucciones claras como “utilizar solo columnas a nivel de mes, nunca campos YTD” y “validar que todos los meses requeridos estén presentes antes de sumar”, el equipo proporciona a Genie límites operativos que garantizan resultados consistentes.
Estas instrucciones específicas del espacio de Genie, combinadas con los metadatos de Unity Catalog, ayudan a Genie a aplicar la lógica adecuada para interpretar los datos correctamente.
Uso de Genie y Agent Bricks para flujos de trabajo de agentes escalables
Si bien Genie proporciona una potente experiencia de agente de investigación sobre la capa de mantenimiento estructurada, Plenitude también necesita flujos de trabajo repetibles y orquestación para admitir un conjunto creciente de casos de uso. Agent Bricks es el siguiente paso en esa evolución.
Con Agent Bricks, Plenitude puede pasar de patrones de “LLM más prompt” a flujos de trabajo de agentes que ejecutan secuencias de acciones en nombre de analistas e ingenieros de mantenimiento. Las mismas tablas depuradas de Delta Lake, metadatos e instrucciones que potencian a Genie pueden ser reutilizados por agentes de tipo Supervisor creados con Agent Bricks para:
- Descomponer preguntas complejas en tareas analíticas más pequeñas.
- Llamar a los flujos de herramientas de Genie para generar y ejecutar SQL.
- Desencadenar acciones posteriores, como la generación de informes o la creación de alertas.
Lo que antes requería la conexión manual de prompts, herramientas y lógica de validación ahora se puede centralizar en Agent Bricks, en la misma plataforma Databricks que gestiona los datos.
Optimización del rendimiento con clustering líquido automático
Dado que las consultas dirigidas por agentes son exploratorias y dinámicas, la optimización tradicional basada en Z-ORDER no siempre es ideal. Plenitude observó que los patrones de acceso evolucionan a medida que aparecen nuevos informes, usuarios y preguntas, lo que dificulta el mantenimiento del clustering manual.
El clustering líquido automático, por el contrario, aprende cómo se utilizan realmente las tablas y adapta la distribución en consecuencia. Esto reduce la necesidad de diseñar índices de forma anticipada y de realizar optimizaciones continuas, lo que es especialmente importante durante las fases de prueba de concepto y de lanzamiento inicial. En este contexto, el clustering automático es la opción preferida para las cargas de trabajo dirigidas por agentes y LLM en tablas Delta.
Protección del acceso a los datos para Genie Rooms
Los datos de mantenimiento suelen tener requisitos de acceso específicos por país o región. Para aplicar estas reglas de manera coherente, Plenitude utiliza la seguridad a nivel de fila en combinación con Unity Catalog y tablas.
Una función de Unity Catalog determina a qué países puede acceder el usuario actual y devuelve una lista o la palabra clave ALL si tiene visibilidad completa. A continuación, una tabla filtra las filas en función de esa función, de modo que cada usuario solo ve los datos de los países autorizados.
Cuando los usuarios interactúan a través de Genie Room, todas las consultas se ejecutan en la tabla filtrada, por lo que la seguridad a nivel de fila se aplica automáticamente. Esto significa que los usuarios pueden hacer preguntas en lenguaje natural, pero solo reciben resultados de los datos que tienen permitido ver. El mismo conjunto de datos alimenta a Genie, a los agentes y a las herramientas de BI, mientras que la visibilidad se ajusta por usuario.
Futuras mejoras: hacia el mantenimiento predictivo
Dado que los informes de mantenimiento contienen incidencias abiertas y detalles de fallos, el modelo de datos estructurados es una base sólida para el mantenimiento predictivo. Los inversores son un buen ejemplo: los fallos pueden provocar la pérdida de varios megavatios-hora por unidad, y los problemas recurrentes suelen aparecer primero en las notas de mantenimiento.
Al analizar los patrones de fallos a lo largo del tiempo, Plenitude puede:
- Identificar posibles problemas de registro.
- Detectar señales de alerta temprana.
- Priorizar las plantas que necesitan una investigación más profunda.
- Alimentar los modelos predictivos con historiales de incidencias de mayor calidad.
El sistema basado en agentes convierte esas señales en análisis, tendencias y visualizaciones accesibles para que los equipos puedan anticiparse a los problemas en lugar de limitarse a reaccionar ante ellos.
Principales ventajas y capacidades
En el enfoque anterior, el análisis se limitaba a leer los informes de forma individual, lo que dificultaba la creación de tendencias históricas, la comparación de plantas o la generación de resultados estructurados. Crear gráficos, exportar resultados o combinar información de varios informes era, en el mejor de los casos, un proceso manual y, a menudo, inviable.
Con el modo agente de Genie en Databricks y un modelo de datos adaptado para agentes, Plenitude puede:
- Explorar los datos de mantenimiento a lo largo del tiempo y en diferentes plantas.
- Generar visualizaciones y exportar resultados, incluidos archivos PDF.
- Detectar señales tempranas y patrones recurrentes.
- Escalar el análisis sin aumentar el esfuerzo manual.
Al combinar datos estructurados, metadatos empresariales y razonamiento de IA, el sistema genera análisis, tendencias y visualizaciones que facilitan la detección temprana y la anticipación de problemas, en lugar de limitarse a ofrecer informes retrospectivos.
Obtenga más información sobre Databricks Genie y Agent Bricks.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.