Desbloqueando los archivos: Cómo transformar documentos no estructurados en una base de datos consultable para el descubrimiento de aguas subterráneas
Cómo Databricks for Good ayudó a MapAid a aprovechar la IA para transformar archivos estáticos en un motor de búsqueda práctico para la crisis del agua en Sudán
- MapAid se asoció con Databricks for Good para clasificar y catalogar casi 700 documentos hidrogeológicos escaneados, transformando una colección no estructurada en una base de datos con capacidad de búsqueda.
- Mediante el uso de IA multimodal, el equipo creó un pipeline serverless que clasifica documentos y extrae información relacionada con el agua directamente a partir de imágenes de páginas escaneadas.
- Ahora, los investigadores pueden localizar estudios históricos relevantes en segundos y acceder a registros de pozos que alimentan directamente los modelos de predicción de aguas subterráneas de MapAid, lo que ayuda a mejorar los resultados de las perforaciones.
Introducción
En todo Sudán, las comunidades dependen de las aguas subterráneas para beber, para el riego y para sobrevivir, pero la perforación de un pozo productivo está lejos de estar garantizada. La geología es compleja, los acuíferos varían mucho y un pozo fallido puede costar miles de dólares. Décadas de estudios geológicos e informes de campo contienen los datos necesarios para mejorar los resultados, pero esta información ha estado dispersa en archivos y nunca se ha organizado sistemáticamente, lo que la hace invisible para las personas que más la necesitan.
MapAid es una organización sin fines de lucro fundada en la Universidad de Stanford cuya misión es empoderar a los actores humanitarios y de desarrollo, principalmente en África, para que tomen decisiones basadas en datos a través de mapas mejorados con AI. Su herramienta principal, la aplicación WellMapr (de uso gratuito), utiliza AI y datos geoespaciales para identificar zonas de aguas subterráneas poco profundas, guiando la perforación de bajo costo para el agua potable y el riego de los pequeños agricultores. Un insumo fundamental para estos modelos son los datos históricos sobre pozos, perforaciones y geología de acuíferos.
La Sudan Association for Archiving Knowledge (SUDAAK) mantiene una de las colecciones más ricas de estos datos: casi 700 PDFs, TIFFs y JPGs escaneados que suman más de 5,000 páginas de estudios geológicos, informes de perforación de pozos y estudios de campo, disponibles públicamente en wossac.com. Sin embargo, la disponibilidad no es lo mismo que la accesibilidad. Un investigador que busque datos de pozos de sondeo en una parte específica de Sudán tendría que filtrar manualmente cientos de documentos. Los datos estaban digitalizados, pero sin un sistema de recuperación, seguían sin aprovecharse.
Clasificación de documentos escaneados con AI multimodal
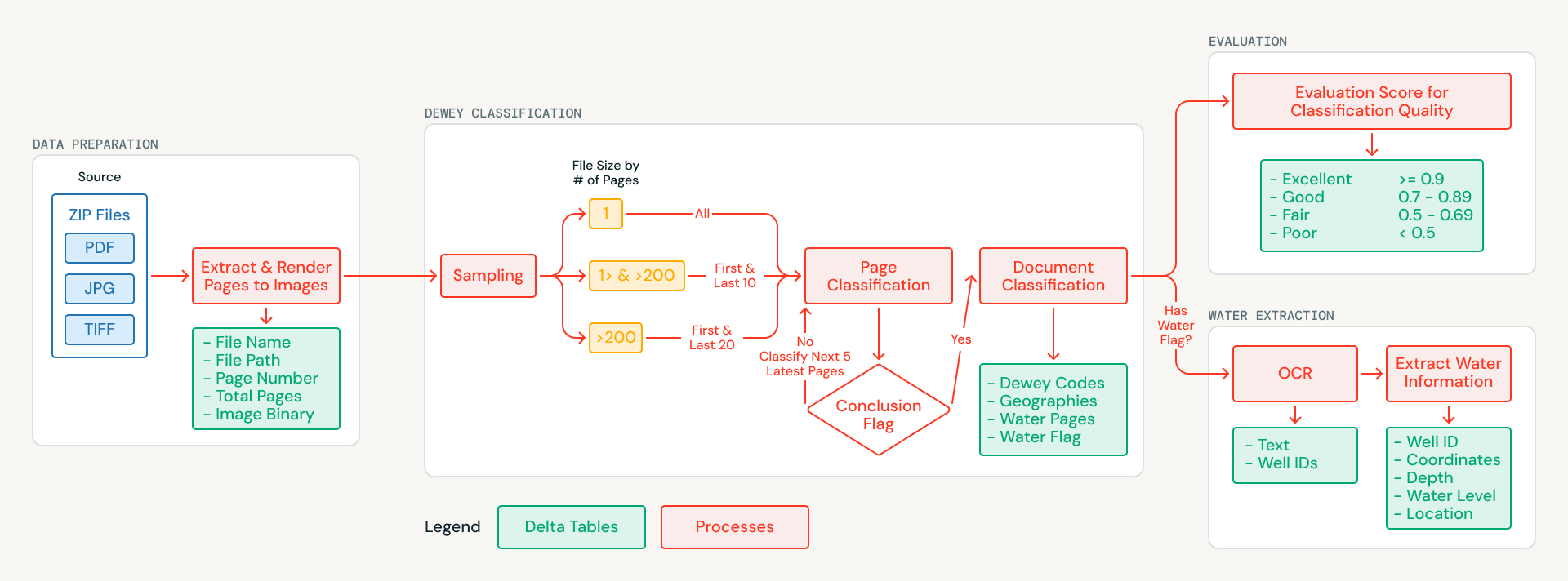
Databricks se asoció con MapAid para crear un pipeline impulsado por AI que clasifica cada documento del archivo, lo etiqueta con metadatos geográficos y temáticos, y extrae registros estructurados de pozos y perforaciones de documentos relacionados con el agua. El sistema se ejecuta completamente en Databricks y está empaquetado para su despliegue con un solo comando. Este artículo analiza el enfoque técnico y cómo se generaliza a cualquier organización que busque extraer conocimiento estructurado de grandes colecciones de documentos escaneados no estructurados.
El archivo presentaba desafíos que descartaban la extracción de texto tradicional. Los documentos son escaneos de informes físicos, de hace muchas décadas, sin ninguna capa de texto incrustada. Algunas páginas están torcidas, otras combinan inglés y árabe, y muchas incluyen notas de campo escritas a mano. En lugar de intentar realizar un OCR como primer paso, el equipo replanteó el problema como uno de comprensión visual: enviar imágenes de páginas escaneadas directamente a modelos de AI multimodal que pudieran interpretar el contenido visualmente.
Las páginas de cada documento se renderizan como imágenes y se almacenan en Unity Catalog Volumes, lo que crea un conjunto de datos fundacional limpio y con control de versiones. A partir de ahí, una estrategia de muestreo inteligente reduce los costos de procesamiento: los documentos más cortos se analizan por completo, mientras que los documentos más largos se muestrean a partir de sus secciones más informativas (portadas, introducciones y conclusiones). Esto redujo el volumen de procesamiento de AI en más del 70% al tiempo que conservó la calidad de la clasificación.
Cada página muestreada se analiza utilizando Databricks AI Functions (ai_query), que admiten de forma nativa entradas multimodales y salidas JSON estructuradas. El modelo examina la imagen de cada página y devuelve:
- Códigos de clasificación decimal de Dewey, el sistema universal de clasificación de bibliotecas
- Zonas geográficas sudanesas a las que se hace referencia en el contenido
- Una etiqueta de relevancia hídrica que indica si la página contiene datos de pozos, perforaciones o acuíferos
Debido a que las AI Functions se ejecutan directamente dentro de SQL, el equipo pudo iterar en los prompts y los esquemas de salida sin tener que crear una infraestructura de servicio de modelos independiente. Los resultados a nivel de página se agregan en clasificaciones a nivel de documento, lo que produce un catálogo estructurado y con capacidad de búsqueda donde cada documento está etiquetado con lo que cubre y dónde se aplica.
{kind=link}
Extracción de registros estructurados de pozos y perforaciones
Muchos de los documentos etiquetados como relevantes para el agua contienen exactamente el tipo de información estructurada de la que dependen los modelos WellMapr de MapAid: ubicaciones de pozos, profundidades de perforación, mediciones del nivel freático y tasas de rendimiento. A menudo, esta información está distribuida por todo el documento: las coordenadas aparecen en una sección, las mediciones de profundidad en otra y los datos de rendimiento en una tabla de resumen varias páginas después. Extraer y vincular estos datos era un objetivo central de la asociación.
Para cada documento relevante para el agua, el pipeline procesa cada página en lugar de solo el subconjunto muestreado utilizado para la clasificación. El OCR se realiza página por página utilizando un modelo multimodal servido a través de la Foundation Model API, que maneja inglés, árabe y diseños complejos, incluidas notas de campo escritas a mano, datos tabulares y páginas de formato mixto. Durante el OCR, el sistema también aplica un enfoque de reconocimiento de entidades, identificando los identificadores de pozos y perforaciones como entidades de anclaje para que los registros que abarcan varias páginas puedan vincularse a un solo sitio.
El texto extraído de todas las páginas se fusiona en una representación de documento unificada, que luego se procesa en una segunda pasada para extraer registros estructurados en formato JSON que capturan nombres de sitios, coordenadas GPS, profundidades de perforación, niveles estáticos de agua y rendimientos de pruebas de bombeo. Databricks AI Functions imponen respuestas restringidas por esquemas, lo que garantiza que estos atributos se capturen de manera constante, incluso cuando aparecen en diferentes formatos o secciones a lo largo del documento. El resultado es un conjunto de registros estructurados de pozos y perforaciones listos para su integración directa en los modelos de predicción WellMapr de MapAid.
Evaluación de calidad automatizada a escala
Validar manualmente cientos de clasificaciones hidrogeológicas especializadas requeriría recursos significativos y una profunda experiencia en el dominio. En lugar de tratar la evaluación como un paso independiente que se realiza a posteriori, el equipo integró la evaluación de calidad automatizada directamente en el pipeline como una etapa de primer nivel. Un modelo de AI independiente, también llamado a través de AI Functions, actúa como juez: califica cada clasificación en una rúbrica estructurada que cubre la precisión, la integridad y la consistencia. Para cada documento, el evaluador compara los códigos decimales de Dewey asignados y las etiquetas geográficas con el contenido de la página muestreada, verificando si las clasificaciones están respaldadas por lo que el modelo realmente observó.
Cada evaluación produce tanto una calificación categórica (excelente, buena, aceptable o deficiente) como una justificación escrita que explica la puntuación, lo que crea un registro auditable para cada decisión que toma el pipeline. Los documentos con una puntuación inferior a un umbral de confianza se marcan para su revisión manual, lo que dirige el esfuerzo humano limitado a los casos en los que más importa. En la primera ejecución completa, solo una pequeña fracción de las clasificaciones requirió atención humana.
Despliegue de una solución autónoma en Databricks
Un proyecto como este abarca todas las capas de la pila de datos y AI: almacenamiento de archivos, ingeniería de datos, inferencia de AI, análisis de salida estructurada, evaluación de calidad y gobernanza. Databricks proporcionó todo esto dentro de un único espacio de trabajo. Los archivos de almacenamiento originales se guardan en volúmenes de Unity Catalog, y todas las salidas del pipeline se escriben en tablas de Delta Lake con confiabilidad ACID, evolución de esquemas y linaje de datos completo. El pipeline se orquesta como un Lakeflow Job en procesamiento serverless, por lo que MapAid solo paga por lo que consume cada ejecución.
Todo el sistema está empaquetado como un Databricks Asset Bundle, lo que significa que se puede desplegar, actualizar y ejecutar con un solo comando. MapAid recibió una solución autónoma que se puede mantener sin necesidad de tener experiencia en múltiples servicios en la nube. Debido a que la lógica del pipeline está desacoplada del archivo específico que procesa, el mismo sistema podría adaptarse a otros archivos de agua, otras regiones u otros dominios donde se necesite clasificar y hacer accesibles mediante búsqueda grandes colecciones de documentos escaneados.
Lo que esto significa sobre el terreno
En su primera ejecución completa, el pipeline entregó:
- 654 documentos y 5,570 páginas clasificadas
- Completado en menos de tres horas
- El 95 % de las clasificaciones fueron calificadas como "excelentes" o "buenas" por el evaluador automatizado
- ~50 % del archivo identificado como contenedor de datos relacionados con el agua
- 299 registros estructurados de pozos y perforaciones extraídos con nombres de ubicación, profundidades y mediciones de rendimiento
El pipeline redujo lo que a los expertos en el dominio les habría llevado semanas o meses a un proceso que se completa en horas. Ahora se pueden realizar búsquedas en el archivo por clasificación, geografía o presencia de datos sobre el agua. Cada registro extraído con coordenadas y datos de profundidad alimenta directamente las predicciones de aguas subterráneas de MapAid, lo que respalda mayores tasas de éxito en la perforación y una entrega más rápida de agua a las comunidades necesitadas.
A medida que SUDAAK continúa digitalizando nuevos documentos, el pipeline puede procesar cada nuevo lote con un solo comando, lo que garantiza que el catálogo se mantenga actualizado a medida que crece el archivo. El trabajo de MapAid abarca África Oriental, incluidos Etiopía y Malaui, y existen archivos no clasificados similares en todo el continente. La metodología y la infraestructura están listas para escalar.
Rupert Douglas-Bate, director ejecutivo (CEO) de MapAid, compartió la siguiente perspectiva sobre la asociación: "Nuestro sistema de AI en evolución, WellMapr, está diseñado para revolucionar la búsqueda y localización a bajo costo de fuentes sostenibles de agua subterránea, pero necesita datos de agua de pozos. Nuestra misión para lograr ese objetivo se aceleró enormemente gracias a nuestra colaboración con Databricks for Good, quienes se conectaron con nosotros a través de Rotary International. El proyecto Databricks for Good fue fundamental para desarrollar nuestra Online Water Library (OWL) con el apoyo de la Sudan Association for Archiving Knowledge (SUDAAK). El equipo de Databricks ayudó a transformar un gran archivo desorganizado de datos históricos de agua y suelo de Sudán en un sistema estructurado utilizando la clasificación decimal de Dewey. Esto nos permite identificar rápidamente datos de pozos de agua subterránea sostenibles a un bajo costo, que ahora se pueden utilizar para ayudar a desarrollar nuestro algoritmo WellMapr. MapAid se complace en utilizar OWL como una herramienta de desarrollo vital para mitigar la sequía, lo que demuestra que cuando los socios adecuados se alinean, podemos lograr lo 'imposible' para quienes más lo necesitan".
Lea más sobre algunos de nuestros otros proyectos pro bono a continuación:
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.