Uso de MemAlign para mejorar la evaluación del aprendizaje automático tradicional en Genie Code
Cerrando la brecha entre los jueces LLM y los expertos humanos con MemAlign y MLflow.
por Stepan Nosov, Pavle Martinović, Tejas Sundaresan, Alkis Polyzotis y Nemanja Petrovic
- Genie Code genera notebooks de ML completos a partir de indicaciones en lenguaje natural: construimos nueve jueces LLM para evaluar la calidad de sus resultados en dimensiones como entrenamiento de modelos, imputación de datos e ingeniería de características.
- La anotación humana reveló que los jueces discreparon con los expertos hasta en 0.68 MAE en una escala de 3 puntos. MemAlign, un marco de alineación de código abierto en MLflow, cerró esta brecha utilizando solo ~50 ejemplos etiquetados.
- En las tres dimensiones peor alineadas, MemAlign redujo el error del juez en un 74-89%, y un estudio de seguimiento mostró que tanto la memoria semántica como la episódica son esenciales para el resultado.
El recientemente anunciado Genie Code es el socio de IA autónomo de Databricks, diseñado específicamente para el trabajo con datos. Reemplazó a Databricks Assistant, al tiempo que integró varios agentes y proporcionó nuevos puntos de integración y capacidades. Genie Code tiene una profunda integración con Unity Catalog, lo que significa que comprende sus tablas, columnas, linaje, vistas de métricas y definiciones de negocio (semántica). Esta conciencia contextual hace que Genie Code sea mucho más útil para los profesionales de datos que los chatbots genéricos.
Cuando Genie Code genera un notebook para tareas de ML tradicionales, como "construir un modelo de predicción de abandono", esperamos que genere un flujo de trabajo listo para producción que incluya la instalación de las bibliotecas de Python apropiadas, la exploración y preprocesamiento de los datos, el entrenamiento, ajuste, registro y despliegue del modelo, y la evaluación de su rendimiento. También esperamos que cada paso esté verdaderamente informado por los datos: por ejemplo, Genie Code deberá entender que las clases desequilibradas en un problema de clasificación binaria resultan en flujos de trabajo y métricas de éxito drásticamente diferentes.
Para garantizar que Genie Code siga consistentemente las mejores prácticas nativas de Databricks y evite, por ejemplo, omitir la validación cruzada, no detectar fugas de datos o imputaciones de datos incorrectas, necesitábamos una forma rigurosa de responder una pregunta: ¿Cómo sabemos si el código generado es realmente bueno? El notebook generado dependerá en gran medida del problema que el cliente intenta resolver, y esto puede variar enormemente entre diferentes clientes, por lo que esta es una pregunta muy no trivial.
En esta publicación, analizaremos cómo construimos un pipeline de evaluación para las capacidades de ML tradicionales de Genie Code y cómo utilizamos MemAlign (un nuevo framework de alineación open-source en MLflow) para cerrar la brecha masiva que encontramos entre los jueces de LLM y los expertos humanos. Los jueces mejorados nos ayudaron a identificar y corregir lagunas en la guía de ML de Genie Code que de otro modo habríamos pasado por alto.
Construyendo el Framework de Evaluación
Se requiere un framework de evaluación robusto para:
- Hillclimbing: cuantificar cómo los prompts, herramientas, habilidades y cambios de arquitectura afectan la salida.
- Proteger contra regresiones: Asegurar que mejorar el "Entrenamiento de Modelos" no degrade accidentalmente la "Exploración de Datos".
- Benchmarking: Medir cómo diferentes modelos fundacionales (backends de LLM) impactan la calidad del notebook.
- CI: Monitorear cómo los cambios en el bucle agéntico subyacente repercuten en las tareas de ML finales.
Evaluar notebooks de ML tradicionales es una de las tareas de evaluación más complejas, ya que abarca la evaluación de la calidad del código, las mejores prácticas de ML y las adaptaciones/personalizaciones informadas por los datos. Para manejar una tarea tan amplia y desordenada como la evaluación de notebooks de ML, utilizamos un LLM-como-juez: un "experto" LLM al que los humanos le enseñaron cómo se ve un buen notebook. Creamos nueve jueces a los que se les pidió evaluar los notebooks de ML a lo largo de nueve dimensiones que aparecen en la mayoría de los flujos de trabajo de ML:
| Dimensiones | Lo que calificamos |
|---|---|
| Instalación de Librerías | Dependencias adecuadas |
| Análisis Exploratorio de Datos | EDA exhaustivo y |
| Imputación de Datos | Tiempo medio de contención |
| Manejo de valores faltantes sin fugas. | Ingeniería de Características |
| Selección/transformación de características. | Entrenamiento de Modelos |
| Selección de modelos, Validación Cruzada, Ajuste de Hiperparámetros | Reutilización del modelo entrenado para realizar inferencias. |
| Evaluación de Métricas | Lógica de inferencia y métricas apropiadas para la tarea (por ejemplo, MAPE para pronósticos, MAE para regresión, Precisión para clasificación). |
| Registro en MLflow | Configuración del seguimiento de experimentos. |
| Organización de Celdas | División del código en celdas, limpieza del código, legibilidad, encabezados de markdown, registro apropiado. |
Para cada dimensión, escribimos rúbricas de puntuación (reutilizadas entre calificadores humanos y jueces de LLM) que asignan una puntuación de 1 a 3, y 0 para "no aplicable":
- 3 (Bueno): El notebook cumple un alto estándar para una dimensión. Demuestra las mejores prácticas, cubre el alcance esperado y maneja adecuadamente los casos extremos.
- 2 (Promedio): Aceptable pero con lagunas. Lo básico está presente, pero el notebook carece de refinamientos que un profesional experimentado esperaría.
- 1 (Malo): Problemas fundamentales. Pasos clave faltan, son incorrectos o se aplican de una manera que llevaría a conclusiones erróneas.
- N/A (No Aplicable): Esta dimensión no es aplicable para este prompt (por ejemplo, la dimensión imputación de datos no se puede aplicar si el conjunto de datos no tiene valores faltantes).
Para dar una idea de la granularidad, aquí está la rúbrica específica que usamos para la dimensión "imputación de datos":
Junto con los jueces, mantenemos un conjunto de casos de prueba de evaluación que abarcan una variedad de tareas de ML (clasificación, regresión, pronóstico), en diferentes tamaños de dataset, dominios y niveles de complejidad. Cada caso de prueba incluye un prompt de usuario que le dice a Genie Code la tarea de ML que se supone que debe resolver en el dataset especificado ("Tengo datos de pasajeros en las tablas titanic_train_table y titanic_test_table. ¿Puedes averiguar quién sobrevivió?"). El bucle de evaluación consiste en usar Genie Code para generar un notebook (o varios) para cada caso de prueba, y luego calificar cada notebook en todas las dimensiones aplicables.
Evaluando el sistema de evaluación
Al usar jueces de LLM, en lugar de humanos, para evaluar artefactos de Genie Code, esencialmente cambiamos un problema difícil por otro: el juez listo para usar no tiene habilidades en la tarea en cuestión y está desalineado con las calificaciones humanas. Nuestro problema es hacer que las puntuaciones de los jueces de LLM se alineen con las de los evaluadores humanos.
El conjunto de evaluación para la evaluación de jueces de LLM contiene 50 notebooks generados por Genie Code ("casos de prueba") donde expertos humanos calificaron cada dimensión aplicable, proporcionando tanto una puntuación como una breve justificación para servir como nuestra verdad fundamental. En las áreas grises entre dos puntuaciones, se permitió a los calificadores expresar su propio juicio, pero los esquemas se escribieron de tal manera que esto rara vez ocurre.
La medida de alineación humano-máquina es el error absoluto medio (MAE) entre las puntuaciones en cada dimensión. Los resultados fueron mixtos, algunas dimensiones mostraron una fuerte alineación (4 dimensiones tuvieron un MAE de <= 0.10), mientras que otras revelaron un desacuerdo significativo:
- Entrenamiento de modelos: MAE de 0.680
- Uso del modelo: MAE de 0.562
- Imputación de datos: MAE de 0.474
- Exploración de datos: MAE de 0.407
Esta brecha existe porque los humanos y los LLM no interpretan la misma rúbrica de la misma manera. Mientras que un calificador humano puede detectar una estrategia de imputación sutilmente defectuosa o un bucle de entrenamiento que 'funciona' pero es lógicamente insound, un juez de LLM a menudo se pierde ese matiz técnico. También descubrimos que el juez sufría de un sesgo de positividad clásico: era simplemente demasiado 'educado' y esto se interpuso en la obtención de resultados objetivos.
Quedó muy claro que, dada la misma rúbrica, los jueces de LLM y los humanos no producirían los mismos resultados, un desalineamiento. Este es exactamente el escenario para el que MemAlign fue diseñado para solucionar.
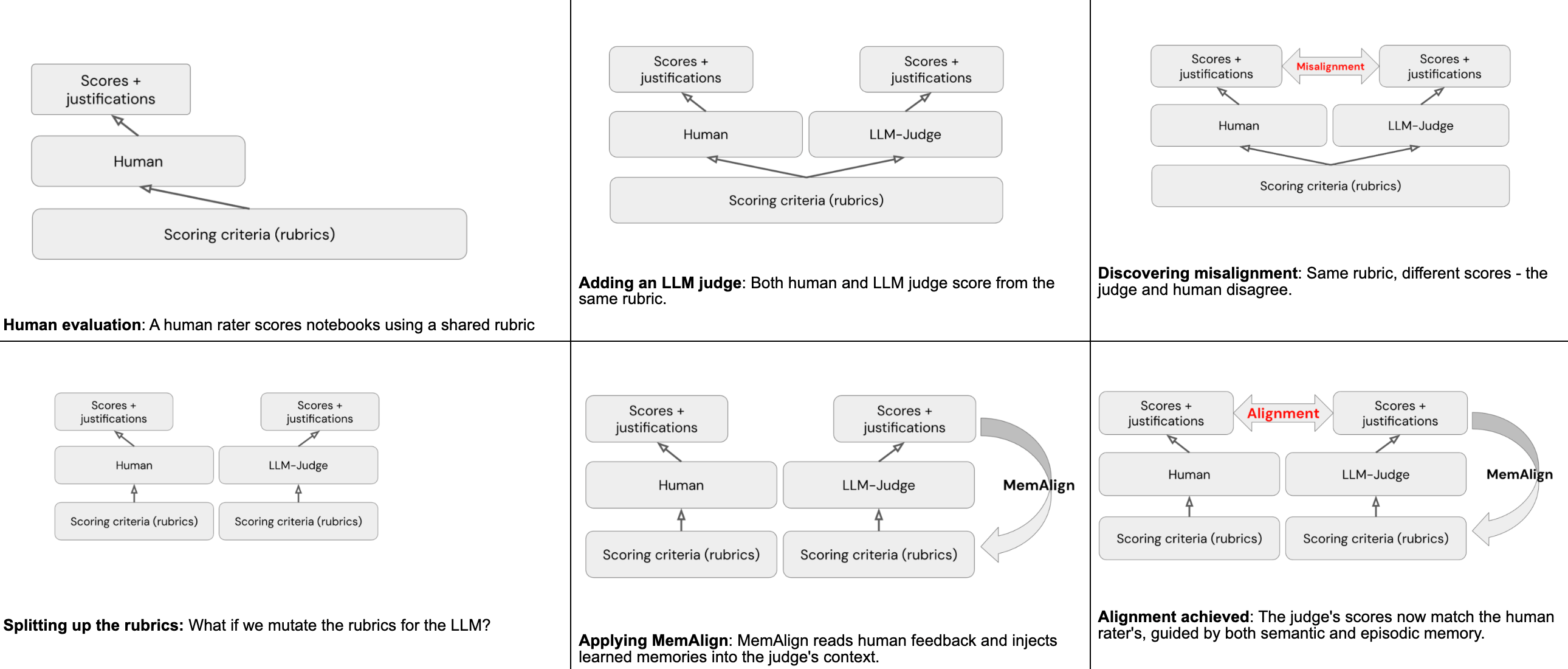
Usando MemAlign para la alineación
MemAlign es un framework dentro de MLflow que puede, dada una cantidad muy pequeña de feedback en lenguaje natural humano, realizar la alineación entre los calificadores humanos y los jueces de LLM. Esto se logra a través de dos tipos de "memorias" formadas al leer el feedback humano:
- Memoria semántica: almacena directrices generalizadas, reglas destiladas de la retroalimentación que se aplican de forma amplia
- Memoria episódica: almacena ejemplos específicos, casos en los que el juez se equivocó, conservados como puntos de referencia para futuras decisiones
En tiempo de inferencia, MemAlign construye un contexto de trabajo extrayendo todas las directrices semánticas y recuperando los ejemplos episódicos más relevantes para la entrada actual. El juez carga todo esto en su contexto, junto con la rúbrica original, y utiliza el conocimiento acumulado para dar una puntuación más precisa a todos los cuadernos futuros.
La propiedad clave que hizo que MemAlign destacara fue su alto rendimiento utilizando solo un pequeño número de ejemplos. Esto se debe a que MemAlign destila eficazmente el aprendizaje de señales de aprendizaje ricas en retroalimentación de lenguaje natural y las incorpora al sistema de memoria dual.
Aquí hay un ejemplo de algunos fragmentos de memoria semántica generados para la dimensión de “imputación de datos”, llenando los vacíos en la rúbrica que definimos previamente proporcionando puntos de referencia, ejemplos y contraejemplos:
Además, como se mencionó anteriormente, la memoria semántica reflejada en el prompt se complementa con ejemplos relevantes de la memoria episódica del juez en el momento de la puntuación, lo que le da al juez aún más contexto para interpretar las instrucciones optimizadas.
Diseño del Experimento
Validación Cruzada K-Fold
Siguiendo el paradigma de entrenamiento-prueba de ML, aplicamos la validación cruzada K-fold (K=4) en 50 casos de prueba (notebooks), evitando así la fuga de datos y la necesidad de etiquetar un conjunto de prueba separado. Para cada fold hicimos lo siguiente:
- Fase de entrenamiento: MemAlign alineó al juez utilizando rastros de los otros folds para obtener el juez.
- Fase de evaluación: Evaluamos los notebooks en el fold i con el juez.
Intervalos de Confianza de Bootstrapping
Para calcular los intervalos de confianza sin datos etiquetados adicionales, generamos 100 muestras bootstrap con reemplazo de las 50 originales. Al repetir esto 10,000 veces y rastrear la MAE entre las puntuaciones humanas y de máquina, calculamos los intervalos de confianza para la alineación humano-máquina con un CI del 95% que define un cambio estadísticamente significativo.
Implementación
El pipeline de evaluación se implementa como un único fragmento de MLflow que orquesta todo el proceso:
El optimizador MemAlign puede alinear jueces de LLM basándose en los rastros de los casos de prueba en solo un par de líneas de código. Utilizamos este nuevo juez “alineado” para calcular la nueva MAE. Alinear un juez en una sola dimensión toma aproximadamente 25 segundos por fold, por lo que la alineación en sí no es un cuello de botella.
Resultados
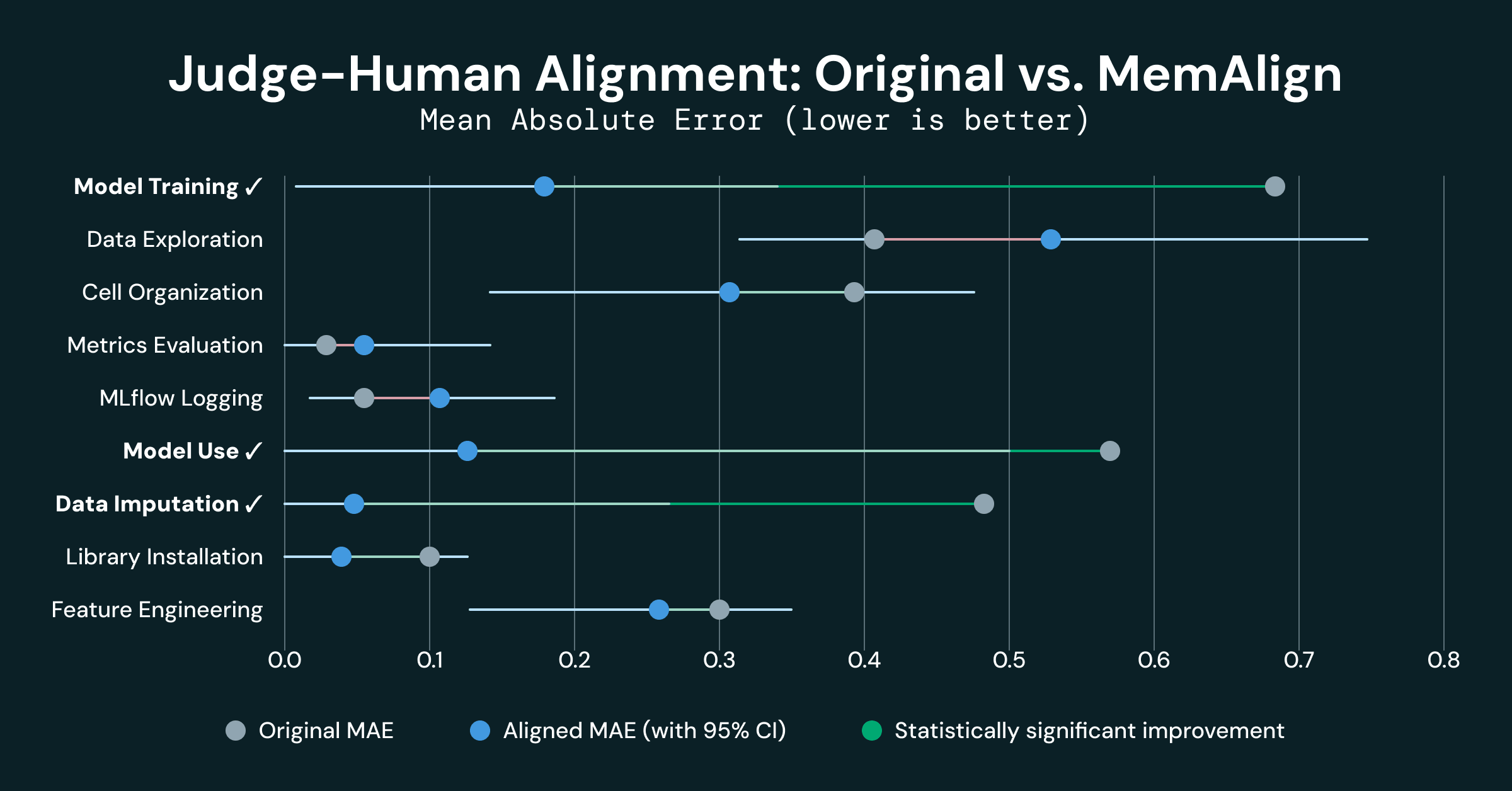
Tres de las 9 dimensiones mostraron una mejora estadísticamente significativa:
- Entrenamiento del modelo mejoró en 0.500 MAE (0.680 → 0.180), una reducción del 74%
- Uso del modelo mejoró en 0.438 MAE (0.562 → 0.125), una reducción del 78%
- Imputación de datos mejoró en 0.421 MAE (0.474 → 0.053), una reducción del 89%
Estas 3 dimensiones se encuentran entre las 4 dimensiones iniciales que estaban muy desalineadas. Una alineación inicial débil es indicativa de que los LLM y los humanos tienen una comprensión fundamentalmente diferente de las rúbricas compartidas, y la memoria inyectada por MemAlign parece proporcionar suficiente contexto para que se “pongan en la misma página”.
- Evaluación de métricas y registro de MLflow ya estaban bien alineados (MAE < 0.10 originalmente), y su degradación no es estadísticamente significativa (ruido del experimento)
- Exploración de datos mostró una ligera regresión (-0.130), pero no estadísticamente significativa dado su intervalo de confianza [-0.33, +0.09]. Esta dimensión exhibió la mayor varianza entre calificadores, y este ruido impidió que MemAlign mejorara (y podría haberlo obstaculizado).
Experimento Solo con Memoria Semántica
La estructura de memoria dual de MemAlign nos llevó a cuestionar si ambas estaban contribuyendo a la alineación del juez. En particular, la memoria episódica se supone que ayuda al juez al proporcionar un conjunto de los cuadernos anotados más similares como punto de referencia (utilizando la búsqueda del vecino más cercano). ¿Pero qué pasa si los cuadernos recuperados (vecinos más cercanos) no son realmente similares al actual, sino solo los menos disímiles? Cargarlos en el contexto del juez podría confundir las cosas en lugar de ayudar. El espacio del problema que estamos calificando (cuadernos de ML) es muy amplio, y al principio hipotetizamos que un conjunto de 50 cuadernos simplemente no sería suficiente para obtener un conjunto de memorias lo suficientemente denso para que el juez lo recordara.
Sin memoria episódica, el panorama se degrada sustancialmente:
- Entrenamiento del modelo todavía mejora (+0.420), pero la ganancia es menor que el +0.500 con MemAlign completo, y la MAE alineada es 0.260 frente a 0.180.
- Uso del modelo pierde completamente la significancia estadística: la mejora cae de +0.438 a +0.294, con el intervalo de confianza ahora cruzando cero.
- Imputación de datos pasa de una reducción del error del 89% a ninguna mejora: la MAE alineada es igual a la MAE original (0.455).
- Registro de MLflow y evaluación de métricas en realidad retroceden significativamente. Sin ejemplos episódicos para anclar al juez, las directrices destiladas por sí solas introducen ruido en dimensiones que ya estaban bien calibradas, llevando el registro de MLflow de 0.062 a 0.396 MAE.
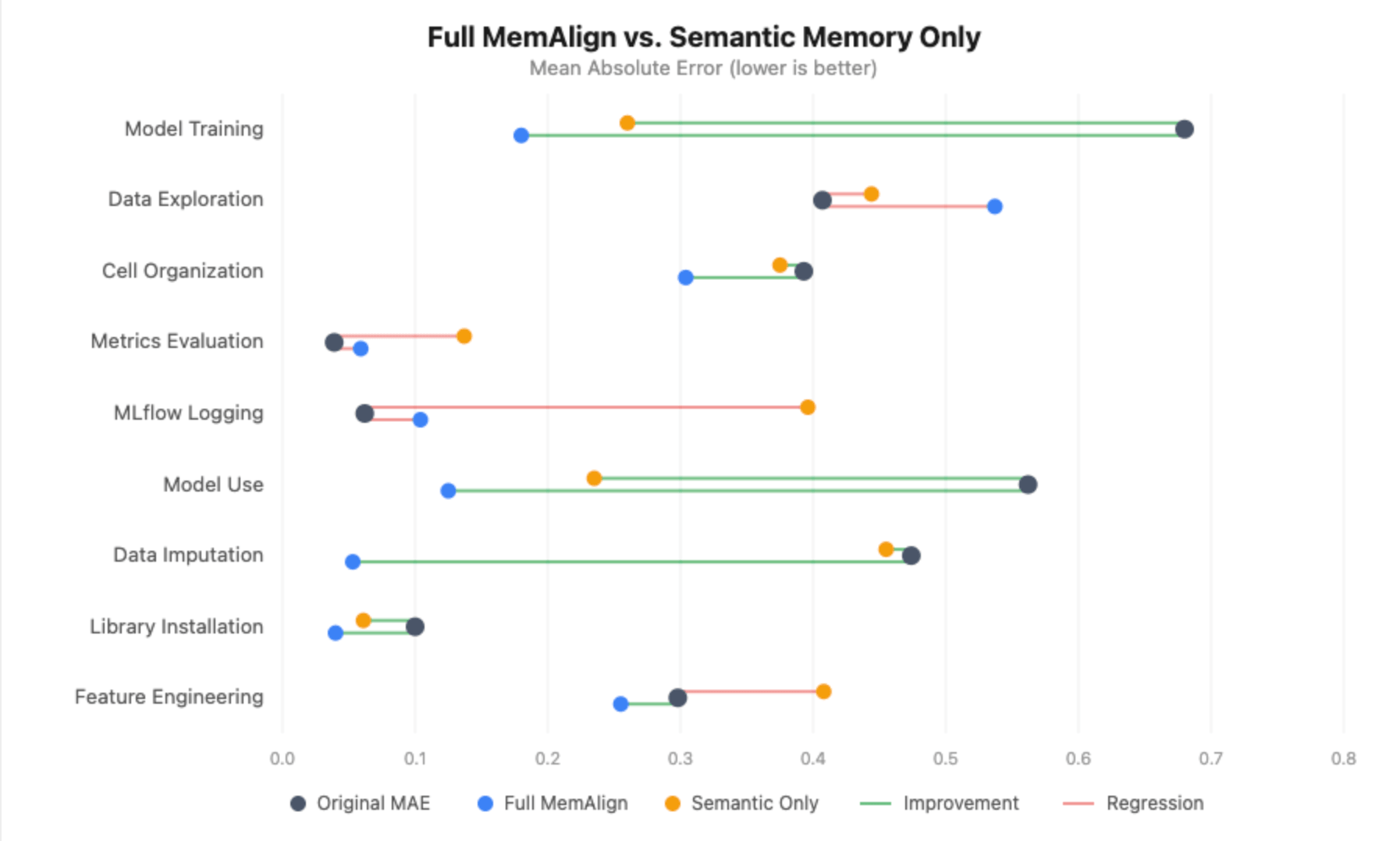
Esto fue lo opuesto a lo que esperábamos. Inicialmente hipotetizamos que nuestro conjunto disperso anotado terminaría confundiendo al juez, pero casi todas las dimensiones empeoraron sin memoria episódica. La única excepción fue la Exploración de Datos, donde eliminar los ejemplos episódicos pudo haber ayudado: sin los cuadernos específicos con los que nuestros anotadores no estaban de acuerdo, el juez solo tenía las directrices destiladas y menos ruido con el que trabajar.
La conclusión: incluso cuando tus entradas son grandes y desordenadas, la memoria episódica aún mejora drásticamente el rendimiento del juez. Tanto la memoria semántica como la episódica son integrales para el funcionamiento de MemAlign.
Conclusión: Cerrando la Brecha de Expertos
Juzgar si un agente de codificación está haciendo su trabajo es bastante difícil, mientras que evaluar a un socio de IA autónomo en la construcción y ejecución de flujos de trabajo de ML tradicionales está en otro nivel de complejidad. Debido a la rápida iteración en los productos de IA, simplemente no hay tiempo suficiente para que los expertos monitoreen la “integración continua” del agente. La única solución escalable viable son los jueces LLM, pero todavía necesitamos un jurado de humanos para mantener a raya al juez LLM.
Al aplicar MemAlign, redujimos el error del juez entre un 74% y un 89% en las dimensiones donde más importaba. Pero, como con cualquier trabajo de ML/LLM, el resultado es tan bueno como la información que pones, así que asegúrate de que el etiquetado sea competente.
Conclusiones:
- Mide tu sistema de medición: Un sistema ruidoso no es bueno para la evaluación, y hasta que invertimos el tiempo y los recursos para validar y mejorar realmente a los jueces, no podíamos confiar en nuestro sistema de evaluación.
- Los reglamentos por sí solos no son suficientes: Existen diferencias sutiles entre cómo un humano percibe las instrucciones y cómo un LLM percibe las instrucciones. Estas diferencias deben tenerse en cuenta, y herramientas de alineación como MemAlign son una forma eficaz de cerrar la brecha.
- Calidad del etiquetado > cantidad: Cuando los anotadores humanos no están de acuerdo entre sí (como vimos en nuestra regresión de exploración de datos), la alineación no tiene una señal coherente de la que aprender.
MemAlign se envía con MLflow y nos funcionó con solo ~50 ejemplos etiquetados. Si tus jueces de LLM no coinciden con tus expertos, vale la pena dedicarle una tarde.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.