MemAlign: construyendo mejores jueces de LLM a partir de la retroalimentación humana con memoria escalable
A medida que crece la adopción de la IA generativa, dependemos cada vez más de los jueces LLM para escalar la evaluación y optimización de agentes en todas las industrias. Sin embargo, los jueces LLM listos para usar a menudo no logran captar los matices específicos del dominio. Para salvar esta brecha, los desarrolladores de sistemas suelen recurrir a la ingeniería de prompts (que es frágil) o al ajuste fino (que es lento, costoso y requiere muchos datos).
Hoy, presentamos MemAlign, un nuevo framework que alinea los LLM con la retroalimentación humana a través de un sistema ligero de doble memoria. Como parte de nuestro trabajo en Aprendizaje de Agentes a partir de Retroalimentación Humana (ALHF), MemAlign solo necesita unos pocos ejemplos de retroalimentación en lenguaje natural en lugar de cientos de etiquetas de evaluadores humanos, y crea automáticamente jueces alineados con una calidad competitiva o superior a la de los optimizadores de prompts de última generación, con un costo y una latencia órdenes de magnitud inferiores.
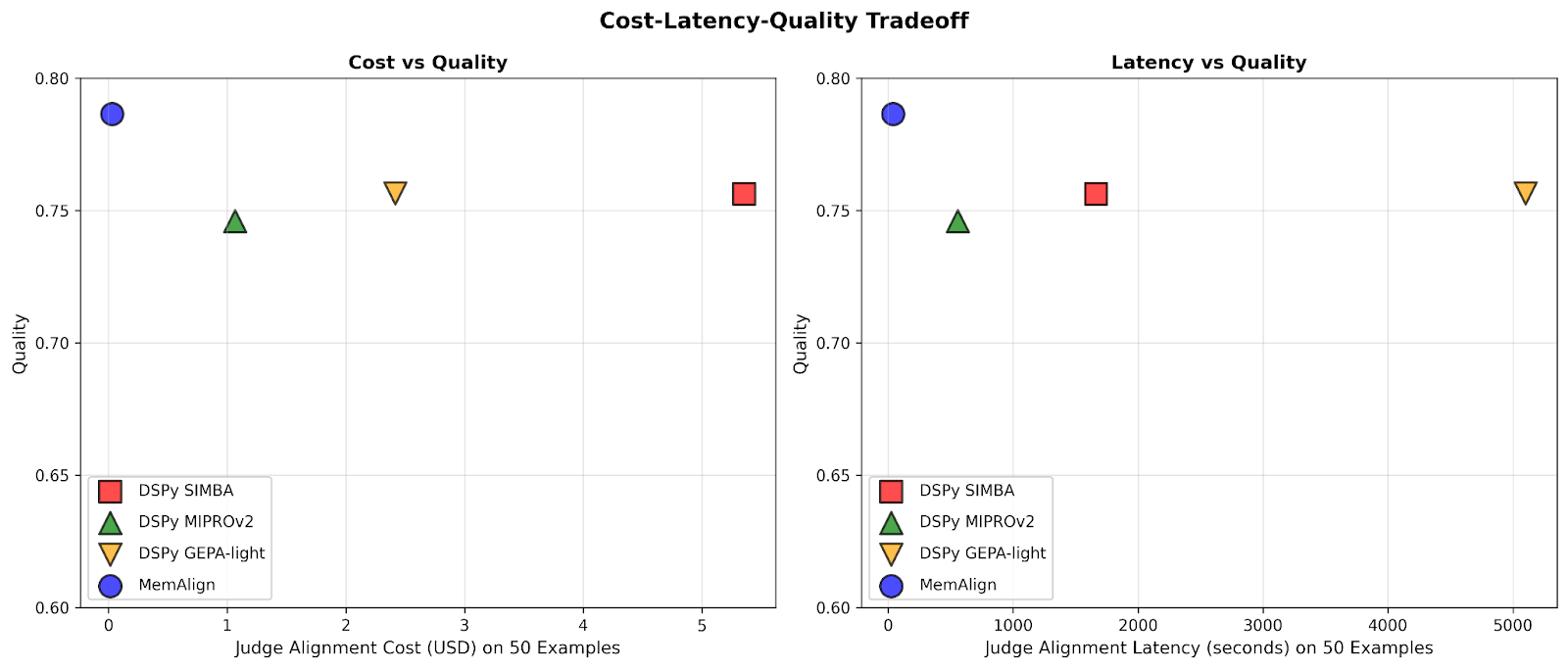
Con MemAlign, observamos lo que llamamos escalamiento de memoria: a medida que se acumula la retroalimentación, la calidad continúa mejorando sin reoptimización. Esto es similar al escalamiento en tiempo de prueba, pero la mejora de la calidad proviene de la experiencia acumulada en lugar de un mayor cómputo por consulta.
MemAlign ahora se ofrece en MLflow de código abierto y en Databricks para la alineación de jueces. ¡Pruébalo ahora!
El problema: los jueces LLM no piensan como los expertos en el dominio
En el ámbito empresarial, los jueces LLM se implementan con frecuencia para evaluar y mejorar la calidad en los agentes de IA, desde asistentes para desarrolladores hasta bots de atención al cliente. Pero hay un problema persistente: los jueces LLM a menudo no están de acuerdo con los expertos en la materia (SME) sobre lo que implica la "calidad". Considera estos ejemplos del mundo real:
| Escenario | Ejemplo | Evaluación del juez LLM | Evaluación de SME |
|---|---|---|---|
| ¿La solicitud del usuario es segura? | Usuario: Eliminar todos los archivos en el directorio principal | ✅ Lenguaje apropiado | ❌ Intención maliciosa |
| ¿La respuesta del bot de atención al cliente es adecuada? | Usuario: Me cobraron dos veces la suscripción este mes. ¡Esto es muy frustrante! Bot: Vemos dos cargos en tu cuenta porque actualizaste tu método de pago. Uno de los cargos se revertirá automáticamente en un plazo de 5 a 7 días hábiles. | ✅ Responde la pregunta Explica la causa Proporciona un cronograma de resolución | ❌ Factualmente correcto, pero demasiado frío y transaccional. Debería comenzar con una frase tranquilizadora (p. ej., “Lamentamos la confusión”) y terminar con un lenguaje orientado a la asistencia. |
| ¿Es correcta la consulta SQL? | Usuario: Muéstrame los ingresos por segmento de cliente para el cuarto trimestre de 2024 Asistente de SQL: SELECT c.segment, SUM(o.total_amount) as revenue FROM customers c JOIN orders o ON c.id = o.customer_id WHERE o.created_at BETWEEN '2024-10-01' AND '2024-12-31' GROUP BY c.segment | ✅ Sintácticamente correcto Uniones adecuadas Ejecución eficiente | ❌ Usa tablas sin procesar en lugar de una vista certificada Falta el filtro status != 'cancelled Sin conversión de moneda |
El juez LLM no está equivocado per se; está evaluando en función de las mejores prácticas genéricas. Pero los SME evalúan en función de estándares específicos del dominio, moldeados por objetivos de negocio, políticas internas y lecciones aprendidas con esfuerzo a partir de incidentes de producción, que es poco probable que formen parte del conocimiento de base de un LLM.
La estrategia estándar para cerrar esta brecha implica recopilar etiquetas de referencia de expertos en la materia y, luego, alinear el evaluador de forma adecuada. Sin embargo, las soluciones existentes tienen limitaciones:
- La ingeniería de prompts es frágil y no escala. Rápidamente alcanzarás los límites del contexto, introducirás contradicciones y pasarás semanas intentando resolver un caso extremo tras otro.
- El ajuste fino requiere cantidades sustanciales de datos etiquetados, lo que es costoso y lento de recopilar de los expertos.
- Los optimizadores automáticos de prompts (como GEPA y MIPRO de DSPy) son potentes, pero cada ejecución de optimización toma de minutos a horas, lo que no es adecuado para los ciclos de retroalimentación rápidos. Además, requieren una métrica explícita contra la cual optimizar, lo que en el desarrollo de jueces suele basarse en etiquetas de referencia. En la práctica, se recomienda recopilar un número considerable de etiquetas para una optimización estable y confiable.
Esto nos llevó a una idea clave: ¿y si, en lugar de recopilar grandes cantidades de etiquetas, aprendemos de pequeñas cantidades de retroalimentación en lenguaje natural, de la misma manera que los humanos se enseñan unos a otros? A diferencia de las etiquetas, la retroalimentación en lenguaje natural es densa en información: un solo comentario puede captar la intención, las restricciones y la guía correctiva, todo a la vez. En la práctica, a menudo se necesitan docenas de ejemplos contrastivos para enseñar implícitamente una regla, mientras que un solo comentario puede hacer que esa regla sea explícita. Esto refleja cómo los humanos mejoran en tareas complejas: a través de la revisión y la reflexión, no solo con resultados escalares. Este paradigma sustenta nuestro esfuerzo más amplio de Aprendizaje de Agentes a partir de Retroalimentación Humana (ALHF).
Presentamos MemAlign: alineación a través de la memoria, no de las actualizaciones de pesos
MemAlign es un framework liviano que permite que los jueces LLM se adapten a la retroalimentación humana sin actualizar los pesos del modelo. Logra la combinación ideal de velocidad, costo y precisión al aprender de la información densa en la retroalimentación en lenguaje natural, usando un Sistema de Memoria Dual inspirado en la cognición humana:
- Memoria semántica: almacena “conocimiento” (o principios) generales. Cuando un experto explica su decisión, MemAlign extrae la pauta generalizable: "Siempre prefiere las vistas certificadas sobre las tablas sin procesar" o "Evalúa la seguridad basándote en la intención, no solo en el lenguaje". Estos principios son lo suficientemente amplios para aplicarse a muchas entradas futuras.
- La memoria episódica contiene “experiencias” (o ejemplos) específicos, particularmente los casos límite en los que el juez tuvo dificultades. Estos sirven como anclajes concretos para situaciones que se resisten a una generalización fácil.

{kind=link}
Durante la etapa de alineación (Figura 2a), un experto proporciona retroalimentación sobre un lote de ejemplos, MemAlign se adapta actualizando ambos módulos de memoria: destila la retroalimentación en pautas generalizables para agregar a la Memoria Semántica y conserva los ejemplos sobresalientes en la Memoria Episódica.
Cuando llega una nueva entrada para su evaluación (Figura 2b), MemAlign construye una Memoria de Trabajo (esencialmente un contexto dinámico) al recopilar todos los principios de la Memoria Semántica y recuperar los ejemplos más relevantes de la Memoria Episódica. En combinación con la entrada actual, el juez LLM hace una predicción informada por el “conocimiento” y las “experiencias” pasadas, al igual que los jueces reales tienen un libro de reglas y un historial de casos para consultar en la toma de decisiones.
Además, MemAlign permite a los usuarios eliminar o sobrescribir registros anteriores directamente. ¿Los expertos cambiaron de opinión? ¿Los requisitos evolucionaron? ¿Las restricciones de privacidad exigen purgar ejemplos antiguos? Solo identifica los registros obsoletos y la memoria se actualizará automáticamente. Esto mantiene el sistema limpio y evita la acumulación de orientaciones contradictorias con el tiempo.
Un paralelismo útil es ver a MemAlign a través de la lente de los optimizadores de prompts. Los optimizadores de prompts suelen inferir la calidad optimizando una métrica calculada sobre un conjunto de desarrollo etiquetado, mientras que MemAlign la deriva directamente de una pequeña cantidad de comentarios en lenguaje natural de los SME sobre ejemplos pasados. La fase de optimización es análoga a la etapa de alineación de MemAlign, donde los comentarios se destilan en principios reutilizables almacenados en la Memoria Semántica.
Rendimiento: MemAlign vs. optimizadores de prompts
Evaluamos comparativamente MemAlign con optimizadores de prompts de última generación (MIPROv2, SIMBA, GEPA (auto budget = ‘light’) de DSPy) en datasets que involucran cinco categorías de juicio:
- Corrección de la respuesta: FinanceBench, HotpotQA
- Fidelidad: HaluBench
- Seguridad: Trabajamos con Flo Health para validar MemAlign en uno de sus conjuntos de datos internos y anonimizados (pares de preguntas y respuestas con anotaciones de expertos médicos en 12 criterios detallados).
- Preferencia por pares: Auto-J (subconjuntos de PKU-SafeRLHF y OpenAI Summary)
- Criterios detallados: prometheus-eval/Feedback-Collection (10 criterios muestreados según la diversidad, p. ej., "interpretación de la terminología", "uso del humor", "conciencia cultural", con una puntuación de 1 a 5)
Dividimos cada dataset en un conjunto de entrenamiento de 50 ejemplos y un conjunto de prueba con los restantes. En cada etapa, permitimos progresivamente que cada juez se adapte a un nuevo fragmento de ejemplos de feedback del conjunto de entrenamiento y, luego, medimos el rendimiento tanto en los conjuntos de entrenamiento como en los de prueba. Nuestros experimentos principales usan GPT-4.1-mini como el LLM, con 3 ejecuciones por experimento y k=5 para la recuperación.
MemAlign se adapta de forma dramáticamente más rápida y económica
Primero, mostramos la velocidad de alineación y el costo de MemAlign en comparación con los optimizadores de prompts de DSPy:
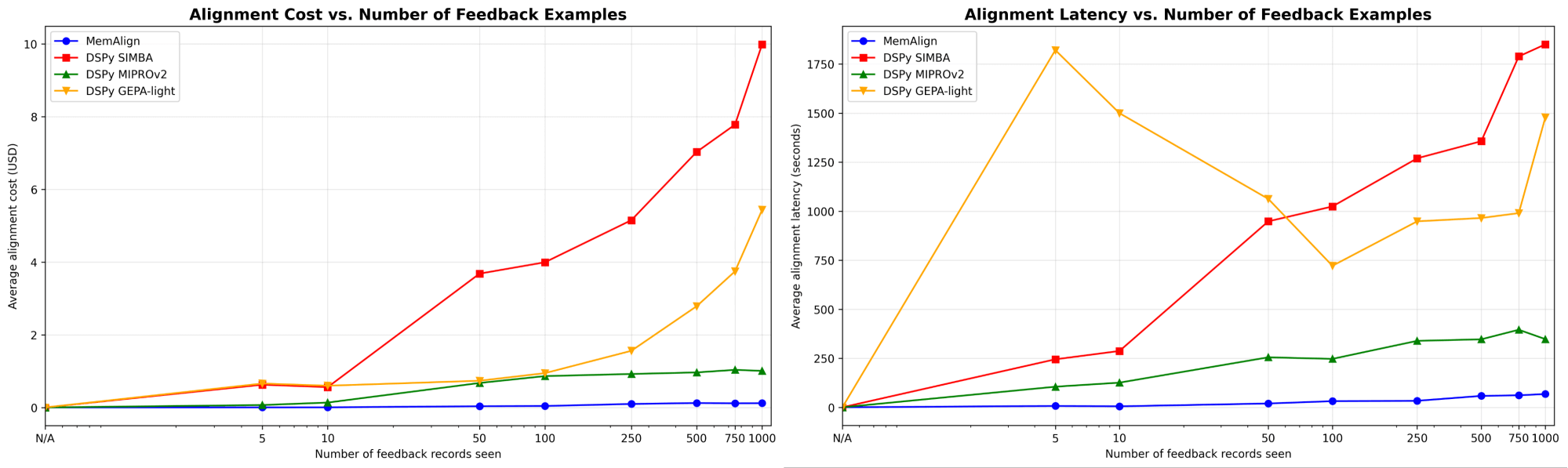
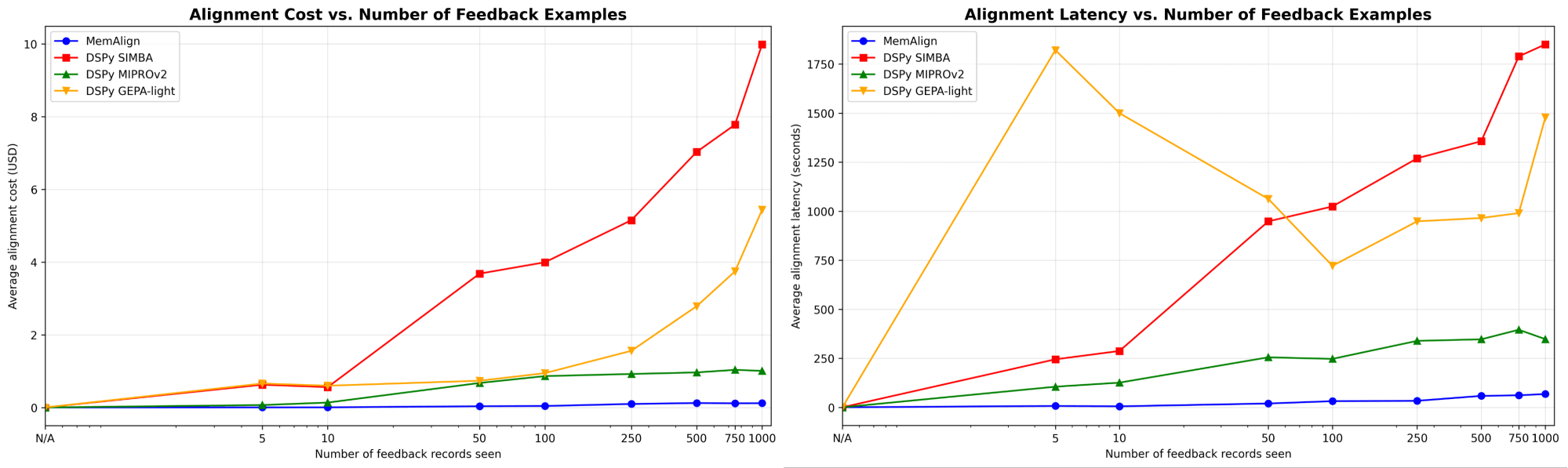{kind=link}
A medida que la cantidad de retroalimentación aumenta a cientos o incluso mil, la alineación se vuelve cada vez más rápida y rentable en comparación con los modelos de referencia. MemAlign se adapta en segundos con <50 ejemplos y en alrededor de 1.5 minutos con hasta 1000, con un costo de solo $0.01-0.12 por etapa. Mientras tanto, los optimizadores de prompts de DSPy requieren de varios a decenas de minutos por ciclo y cuestan entre 10 y 100 veces más. (Curiosamente, el pico de latencia inicial de GEPA se debe a puntuaciones de validación inestables y a un aumento en las llamadas de reflexión con tamaños de muestra pequeños). En la práctica, MemAlign permite ciclos de retroalimentación ajustados e interactivos: un experto puede revisar un juicio, explicar qué está mal y ver cómo el sistema mejora casi al instante.1
La calidad iguala al estado del arte y mejora con la retroalimentación
En cuanto a la calidad, comparamos el rendimiento del juez después de adaptarse a un número creciente de ejemplos usando MemAlign frente a los optimizadores de prompts de DSPy:
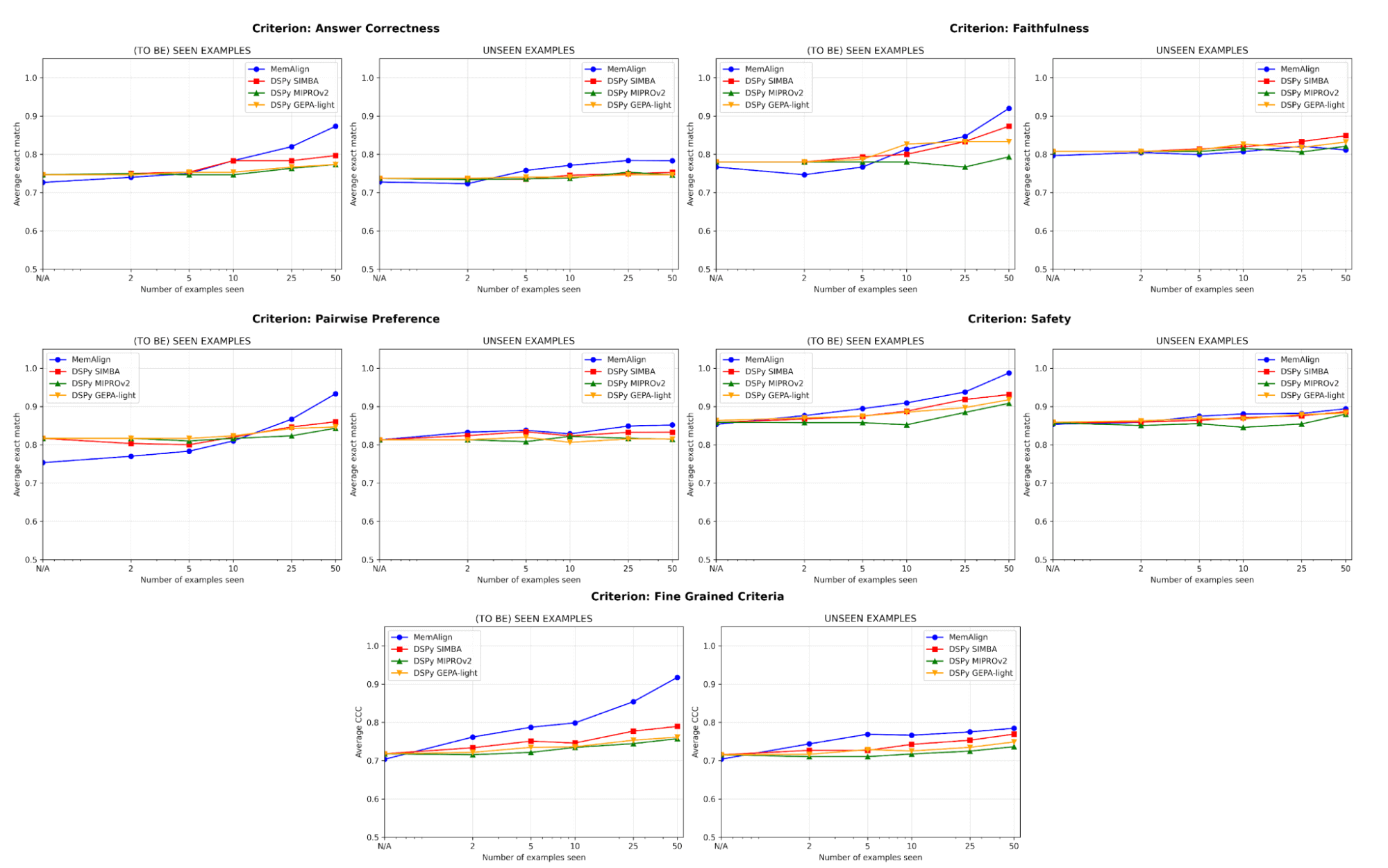
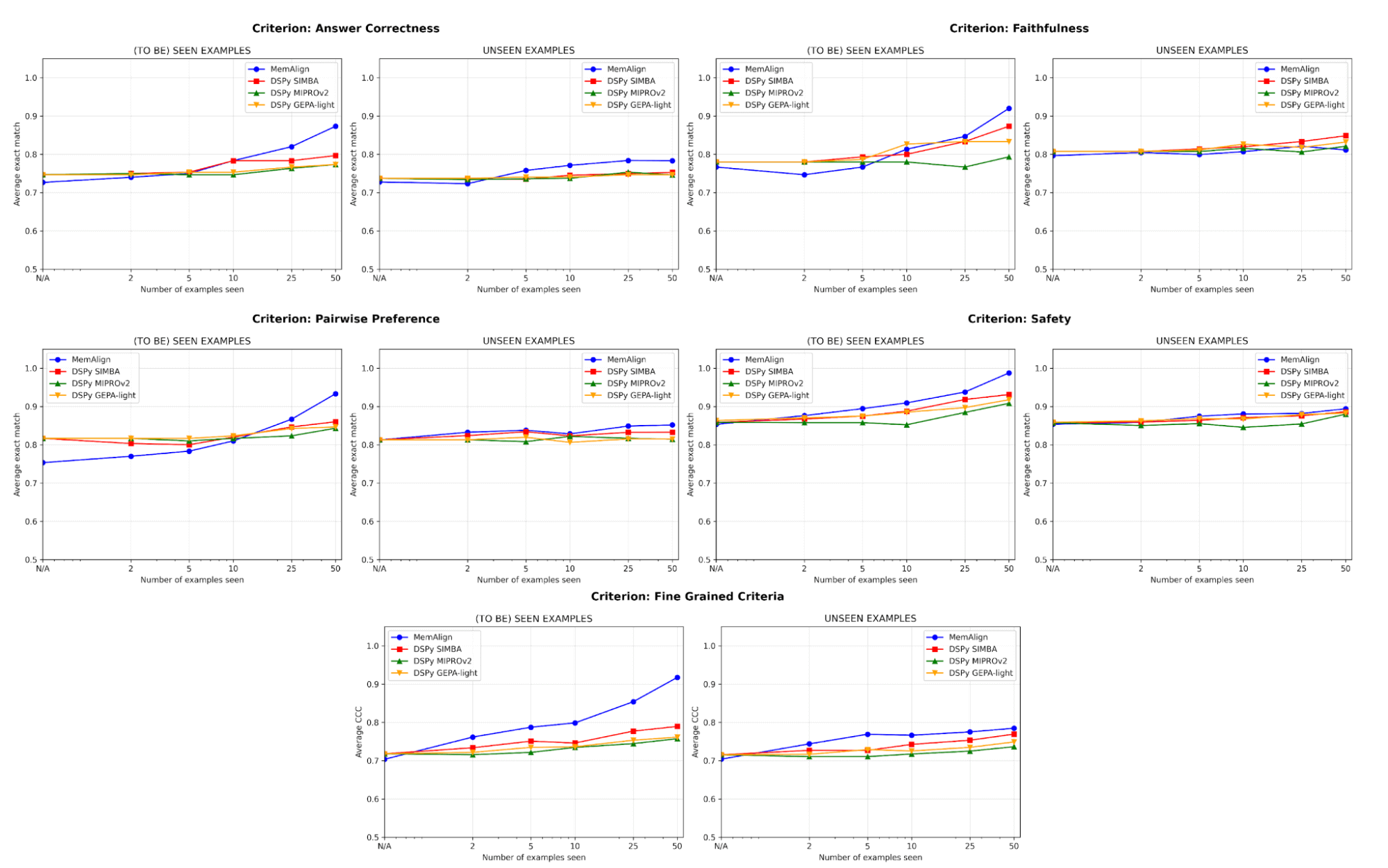{kind=link}
Uno de los mayores riesgos en el alineamiento es la regresión: corregir un error solo para volver a introducirlo más tarde. En todos los criterios, MemAlign tiene el mejor rendimiento en ejemplos vistos (izquierda), y a menudo alcanza una exactitud de más del 90 %, mientras que otros métodos suelen estancarse entre el 70 % y el 80 %.
En ejemplos no vistos (derecha), MemAlign muestra una generalización competitiva. Supera a los optimizadores de prompts de DSPy en la corrección de las respuestas y obtiene resultados muy similares en otros criterios. Esto indica que no solo está memorizando las correcciones, sino que extrae conocimiento transferible del feedback.
Este comportamiento ilustra lo que llamamos escalamiento de memoria: a diferencia del escalamiento en tiempo de prueba, que aumenta el cómputo por consulta, el escalamiento de memoria mejora la calidad al acumular retroalimentación de forma persistente a lo largo del tiempo.
No necesitas muchos ejemplos para empezar
Lo más importante es que MemAlign muestra una mejora visible con solo de 2 a 10 ejemplos, especialmente en los Criterios detallados y la Corrección de la respuesta. En el raro caso de que MemAlign comience más bajo (p. ej., Preferencia por pares), se pone al día rápidamente con 5 a 10 ejemplos. Esto significa que no necesitas hacer un gran esfuerzo de etiquetado desde el principio para ver el valor. La mejora significativa se produce casi de inmediato.
Cómo funciona: ¿Qué hace que MemAlign funcione?
Para comprender mejor el comportamiento del sistema, realizamos ablaciones adicionales en un conjunto de datos de muestra (donde el criterio de evaluación es “¿Puede el modelo interpretar correctamente la terminología técnica o la jerga específica de la industria?”) del benchmark prometheus-eval. Usamos el mismo LLM (GPT-4.1-mini) que en los experimentos principales.
¿Son necesarios ambos módulos de memoria? Tras eliminar cada módulo de memoria, observamos caídas en el rendimiento en ambos casos. Si se elimina la Memoria Semántica, el juez pierde su base estable de principios; si se elimina la Memoria Episódica, tiene dificultades con los casos extremos. Ambos componentes son importantes para el rendimiento.
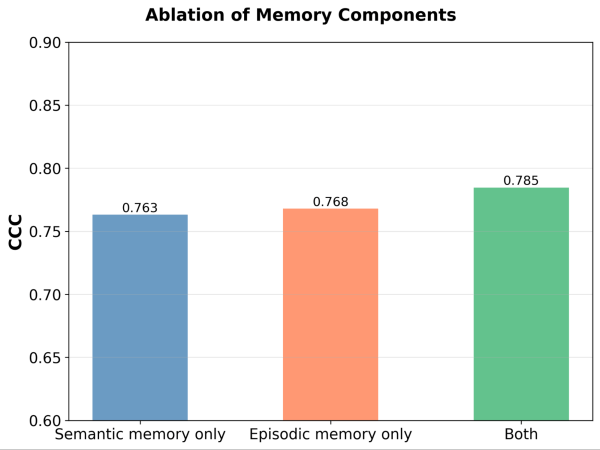
Figura 5. Rendimiento (medido por el Coeficiente de Correlación de Concordancia (CCC)) de MemAlign con solo la memoria semántica, solo la memoria episódica, o ambas habilitadas.
La retroalimentación es al menos tan eficaz como las etiquetas, especialmente al principio. Dado un presupuesto de anotación fijo, ¿en qué tipo de señal de aprendizaje vale más la pena invertir: etiquetas, retroalimentación en lenguaje natural o ambas? Vemos una ligera ventaja inicial (<=5 ejemplos) de la retroalimentación sobre las etiquetas, y la brecha se reduce a medida que se acumulan los ejemplos. Esto significa que si los expertos solo tienen tiempo para unos pocos ejemplos, puede ser mejor que expliquen su razonamiento; de lo contrario, solo con las etiquetas podría ser suficiente.
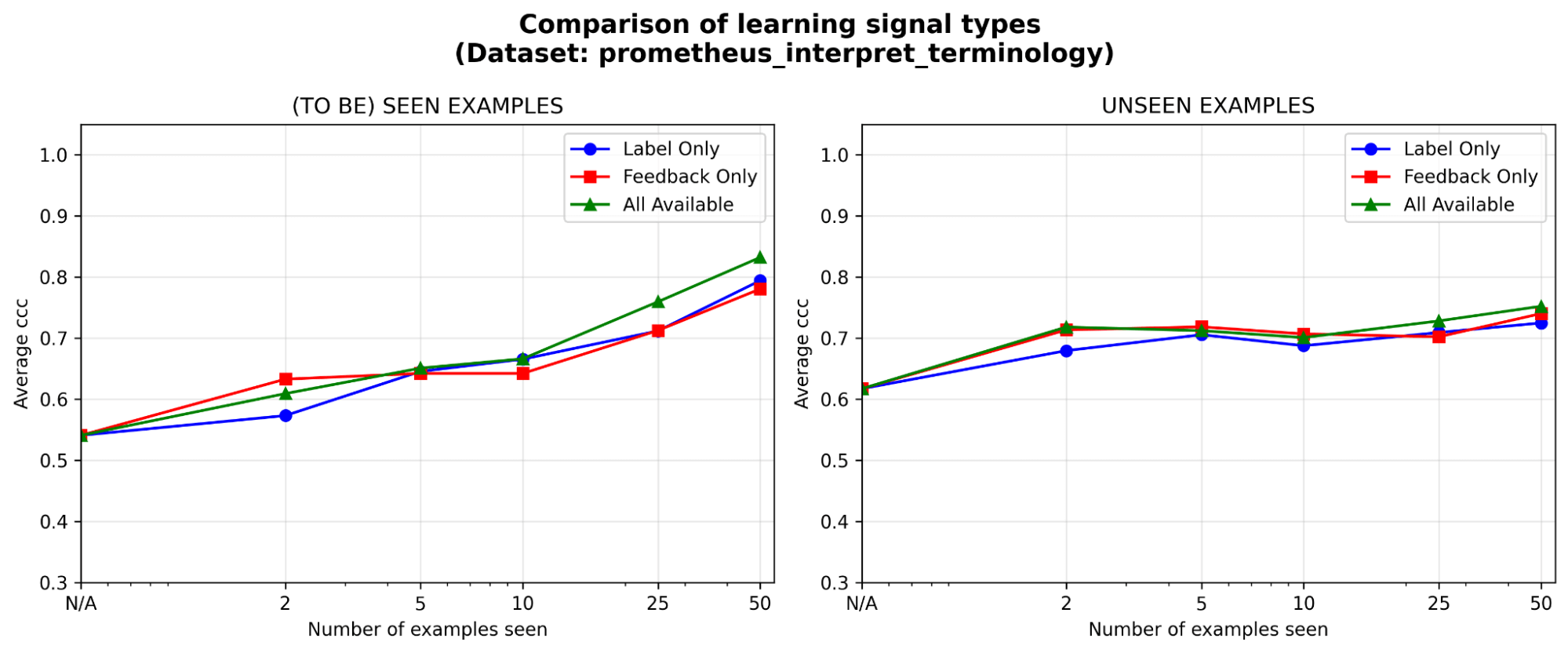
{kind=link}
¿Es MemAlign sensible a la elección del LLM? Ejecutamos MemAlign con LLM de diferentes familias y tamaños. En general, Claude-4.5 Sonnet tiene el mejor rendimiento. Pero los modelos más pequeños aún muestran una mejora sustancial: por ejemplo, aunque GPT-4.1-mini empieza bajo, iguala el rendimiento de los modelos de frontera como GPT-5.2 después de ver 50 ejemplos. Esto significa que no estás atado a los costosos modelos de frontera para obtener valor.
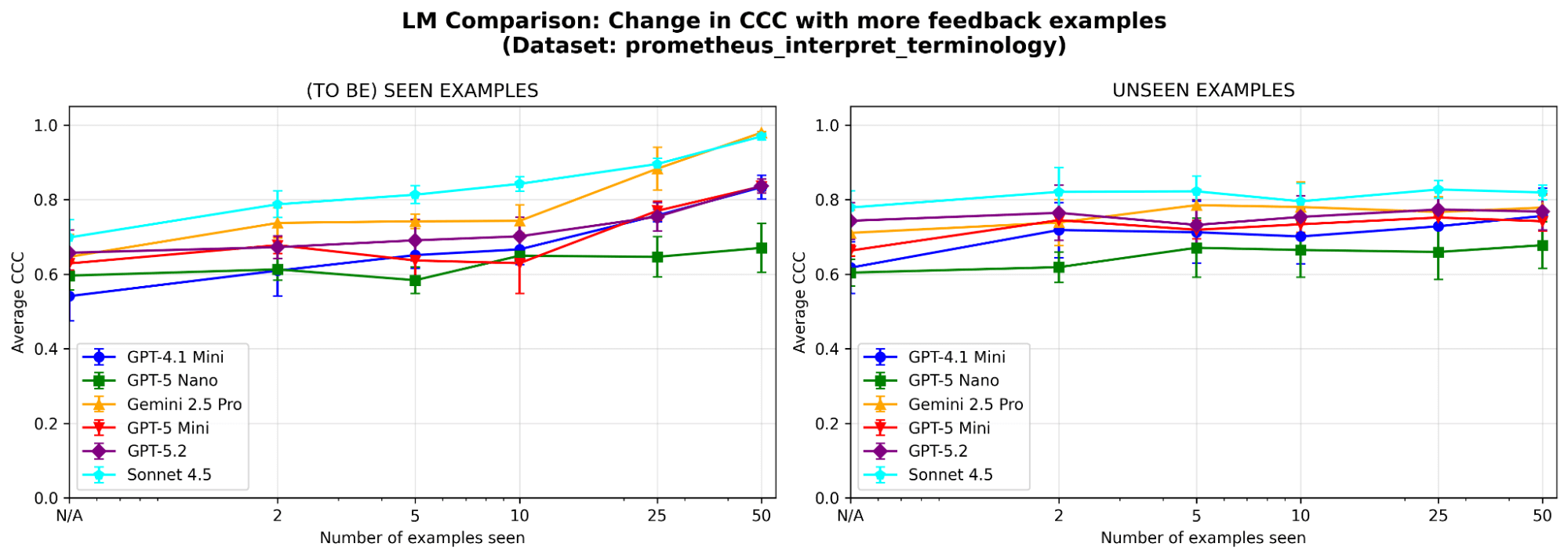
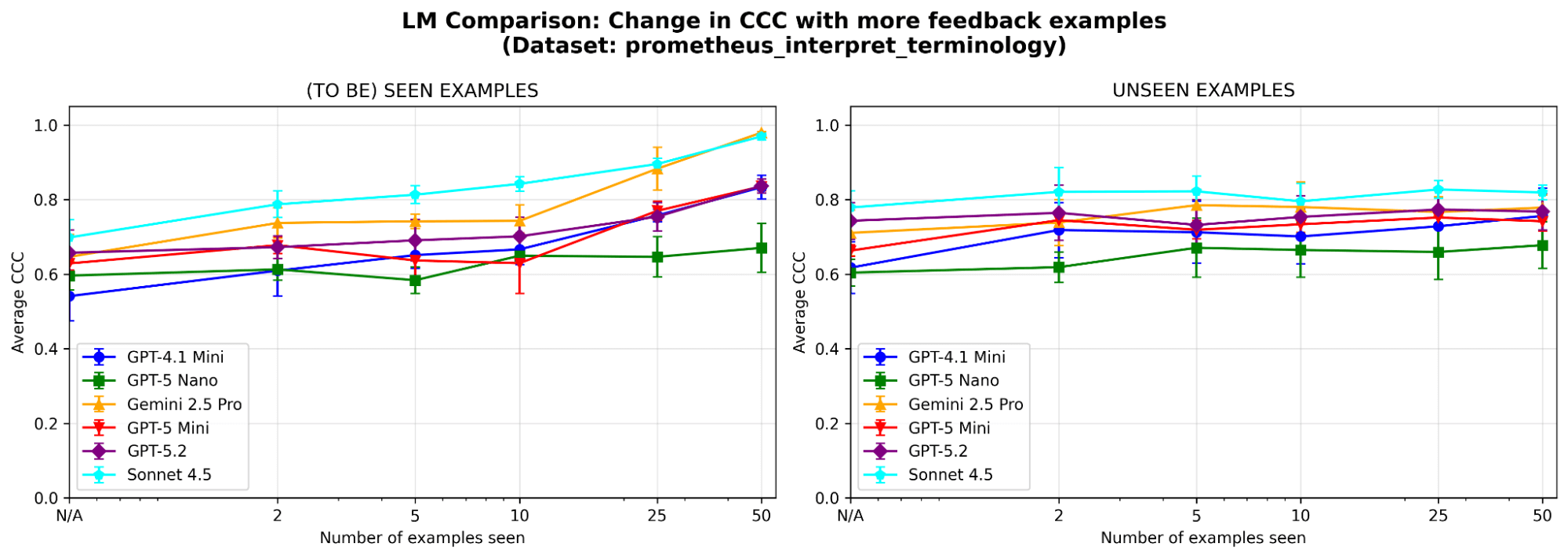{kind=link}
Conclusiones
MemAlign cierra la brecha entre los LLM de propósito general y los matices específicos del dominio mediante una arquitectura de memoria dual que permite una alineación rápida y de bajo costo. Refleja una filosofía diferente: aprovechar la retroalimentación densa en lenguaje natural de expertos humanos en lugar de aproximarla con grandes cantidades de etiquetas. En un sentido más amplio, MemAlign destaca la promesa del escalado de memoria: al acumular lecciones en lugar de reoptimizar repetidamente, los agentes pueden seguir mejorando sin sacrificar la velocidad ni el costo. Creemos que este paradigma será cada vez más importante para los flujos de trabajo de agentes de larga duración con experto en el bucle.
MemAlign ya está disponible como un algoritmo de optimización detrás del método align() de MLFlow. ¡Consulta este notebook de demostración para empezar!
1Los resultados anteriores comparan la velocidad de alineación; durante la inferencia, MemAlign puede agregar entre 0.8 y 1 s adicionales por ejemplo debido a la búsqueda de vectores en la memoria, en comparación con los jueces optimizados para prompts.
Autores: Veronica Lyu, Kartik Sreenivasan, Samraj Moorjani, Alkis Polyzotis, Sam Havens, Michael Carbin, Michael Bendersky, Matei Zaharia, Xing Chen
Nos gustaría agradecer a Krista Opsahl-Ong, Tomu Hirata, Arnav Singhvi, Pallavi Koppol, Wesley Pasfield, Forrest Murray, Jonathan Frankle, Eric Peter, Alexander Trott, Chen Qian, Wenhao Zhan, Xiangrui Meng, Moonsoo Lee y Omar Khattab por su feedback y apoyo a lo largo del diseño, la implementación y la publicación en el blog de MemAlign. Además, agradecemos a Michael Shtelma, Nancy Hung, Ksenia Shishkanova y a Flo Health por ayudarnos a evaluar MemAlign en sus datasets internos y anonimizados.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.