¿Qué es el análisis de Big Data?
Examinar conjuntos de datos masivos y variados de dispositivos IoT, redes sociales y comercio electrónico para descubrir patrones ocultos, correlaciones y conocimientos prácticos.
- Examina datos estructurados, semiestructurados y no estructurados, desde terabytes hasta zettabytes, mediante técnicas avanzadas como aprendizaje automático, procesamiento del lenguaje natural y aprendizaje profundo.
- Aprovecha marcos distribuidos como Hadoop, Spark y Hive para procesar datos en redes completas, superando las limitaciones tradicionales de ETL y la lentitud del procesamiento por lotes.
- Ofrece reducción de costos mediante la computación en la nube, permite la toma de decisiones en tiempo real con análisis en memoria y ayuda a identificar nuevos productos, tendencias del mercado y preferencias de los clientes.

¿Qué es el análisis de Big Data?
El análisis de big data es el proceso a menudo complejo de examinar grandes y variados conjuntos de datos, o big data, que fueron generados por diversas fuentes como el comercio electrónico, los dispositivos móviles, las redes sociales y la Internet de las cosas (IoT). Implica integrar diferentes fuentes de datos, transformar datos no estructurados en datos estructurados y generar información a partir de los datos empleando herramientas y técnicas especializadas que distribuyen el procesamiento de datos en toda una red.
La cantidad de datos digitales crece rápidamente y se duplica aproximadamente cada dos años. El análisis de big data ofrece un enfoque diferente para gestionar y analizar todas estas fuentes de datos. Si bien los principios del análisis de datos tradicional generalmente todavía se aplican, la escala y la complejidad del análisis de big data requirieron el desarrollo de nuevas formas de almacenar y procesar los petabytes de datos estructurados y no estructurados involucrados.
Proceso y métodos centrales
La demanda de velocidades más rápidas y mayores capacidades de almacenamiento creó un vacío tecnológico que pronto se llenó con distintos enfoques, como los siguientes:
- Métodos de almacenamiento como los almacenes de datosy los lagos de datos
- Bases de datos no relacionales como NoSQL
- Tecnologías y frameworks de procesamiento y gestión de datos, como Apache Hadoop de código abierto, Spark y Hive.
El análisis de big data aprovecha las técnicas analíticas avanzadas para analizar conjuntos de datos realmente grandes que incluyen datos estructurados, semiestructurados y no estructurados, de varias fuentes y en diferentes tamaños, desde terabytes hasta zettabytes.
Análisis de datos tradicional vs. análisis de Big Data
Antes de la invención de Hadoop, las tecnologías que sustentaban los sistemas modernos de almacenamiento y cómputo eran relativamente básicas, lo que limitaba a las empresas principalmente al análisis de “datos pequeños”. Incluso esta forma de análisis podría ser difícil, especialmente la integración de nuevas fuentes de datos. Con el análisis de datos tradicional, que se basa en bases de datos relacionales de datos estructurados, cada byte de datos sin procesar debe formatearse de una manera específica antes de poder ingerirse en la base de datos para su análisis. Este proceso, a menudo largo y comúnmente conocido como extracción, transformación y carga (o ETL), es necesario para cada nueva fuente de datos. El principal desafío de este proceso de tres partes es que consume una cantidad increíble de tiempo y mano de obra; a veces requiere hasta 18 meses para que los científicos e ingenieros de datos puedan implementarlo o modificarlo.
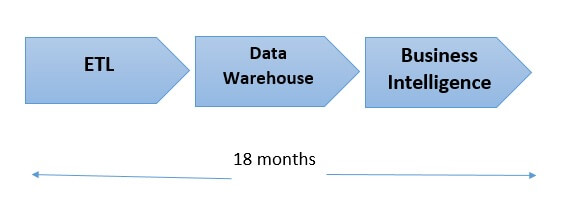
Una vez que los datos estaban dentro de la base de datos, no obstante, a los analistas de datos les resultaba bastante fácil consultarlos y analizarlos. Pero entonces llegaron Internet, el comercio electrónico, las redes sociales, los dispositivos móviles, la automatización del marketing, la Internet de las cosas (IoT), etc., y la escala, el volumen y la complejidad de los datos en bruto se volvieron demasiado grandes para que, salvo unas pocas instituciones, pudieran analizarlos durante el curso normal de las actividades.
La guía de IA agéntica para la empresa

Los tipos de datos más comunes en la analítica de big data
- Datos web. Datos sobre el comportamiento web de los clientes, como visitas, páginas vistas, búsquedas, compras, etc.
- Datos de texto. Los datos generados a partir de fuentes de texto, como correos electrónicos, artículos de noticias, publicaciones de Facebook, documentos de Word y más, constituyen uno de los tipos de datos no estructurados más grandes y de mayor uso.
- Hora y ubicación, o datos geoespaciales: El GPS y los teléfonos celulares, así como las conexiones Wi-Fi, hacen que la información sobre la hora y la ubicación sea una fuente de datos interesantes cada vez mayor. Esto también puede incluir datos geográficos relacionados con carreteras, edificios, lagos, direcciones, personas, lugares de trabajo y rutas de transporte, que se generaron a partir de sistemas de información geográfica.
- Medios de comunicación en tiempo real. Las fuentes de datos en tiempo real pueden incluir datos de transmisión en tiempo real o basados en eventos.
- Datos de sensores y redes inteligentes. Los datos de sensores de automóviles, oleoductos, turbinas de aerogeneradores y otros sensores a menudo se recopilan a frecuencias extremadamente altas.
- Datos de redes sociales: El texto no estructurado (comentarios, 'me gusta', etc.) de sitios de redes sociales como Facebook, LinkedIn, Instagram, etc. está en aumento. Incluso es posible hacer un análisis de enlaces para descubrir la red de un usuario determinado.
- Datos enlazados: este tipo de datos se recopiló con tecnologías en línea estándar como HTTP, RDF, SPARQL y URL.
- Datos de red. Datos relacionados con redes sociales muy grandes, como Facebook y Twitter, o redes tecnológicas como Internet, telefonía y redes de transporte.
El análisis de big data ayuda a las organizaciones a aprovechar sus datos y utilizar técnicas y métodos avanzados de ciencia de datos, como el procesamiento del lenguaje natural, el aprendizaje profundo y el aprendizaje automático, al descubrir patrones ocultos, correlaciones desconocidas, tendencias del mercado y preferencias de los clientes, para identificar nuevas oportunidades y tomar decisiones empresariales más informadas.
Las ventajas del uso de Big Data Analytics incluyen:
- Reducción de costos. Las tecnologías de almacenamiento y cómputo en la nube, como Amazon Web Services (AWS) y Microsoft Azure, así como Apache Hadoop, Spark y Hive, pueden ayudar a las empresas a reducir sus gastos al almacenar y procesar grandes conjuntos de datos.
- Mejora en la toma de decisiones. Con la velocidad de Spark y el análisis en memoria, en combinación con la capacidad de analizar rápidamente nuevas fuentes de datos, las empresas pueden generar información inmediata y procesable necesaria para tomar decisiones en tiempo real.
- Nuevos productos y servicios. Con la ayuda de herramientas de análisis de big data, las empresas pueden analizar con mayor precisión las necesidades de los clientes, lo que facilita ofrecerles lo que desean en términos de productos y servicios.
- Detección de fraudes. El análisis de big data también se emplea para prevenir el fraude, principalmente en la industria de servicios financieros, pero está ganando importancia y uso en todos los sectores.
Recursos adicionales
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.