Almacén de datos

¿Qué es un almacén de datos?
Un almacén de datos (DWH) es un sistema de gestión de datos que guarda los datos actuales e históricos de varias fuentes con el fin de favorecer a las empresas y facilitarles la obtención de información y la elaboración de informes. Los almacenes de datos se suelen usar para la inteligencia empresarial (BI), la analítica, la generación de informes, las aplicaciones de datos, la preparación de datos para el aprendizaje automático (ML) y el análisis de datos.
Los almacenes de datos permiten analizar de forma rápida y fácil los datos empresariales cargados desde sistemas operativos como los sistemas de punto de venta, los sistemas de gestión de inventario o las bases de datos de marketing o ventas. Los datos pueden pasar por un almacén de datos operacional y requerir una limpieza de datos para garantizar su calidad antes de poder utilizarlos en el almacén de datos para la creación de reportes.
Más temas para descubrir


¿Para qué se utilizan los almacenes de datos?
Los almacenes de datos se usan en BI, analítica, generación de informes, aplicaciones de datos, preparación de datos para el aprendizaje automático y análisis de datos para extraer y resumir datos de las bases de datos operativas. La información que es difícil de analizar directamente desde las bases de datos transaccionales se puede analizar a través de los almacenes de datos; por ejemplo, si la gerencia quiere saber los ingresos totales generados por cada vendedor mensualmente para cada categoría de producto. Es posible que las bases de datos transaccionales no capturen estos datos, pero el almacén de datos sí.
¿Cuáles son los tipos de almacenes de datos?
- Almacén de datos tradicional: Este tipo de almacén de datos solo almacena datos estructurados. Simple: la estructura de un almacén de datos permite a los usuarios acceder de manera rápida y fácil a los datos para crear informes y análisis
- Almacén de datos inteligente: Este es un tipo moderno de almacén de datos que se basa en una arquitectura de lakehouse y que tiene una plataforma inteligente y con optimización automática. Un almacén de datos inteligente no solo proporciona acceso a los modelos de IA y ML, sino que también usa la IA para ayudar con las consultas, la creación de paneles y la optimización del rendimiento y el tamaño.
Arquitectura del almacén de datos
Un modelo común para la arquitectura de almacenamiento de datos es multinivel. Esta arquitectura fue creada por Bill Inmon, el científico informático a menudo considerado el padre del data warehouse.
Nivel inferior
El nivel inferior de la arquitectura de un data warehouse se compone de fuentes de datos y almacenamiento de datos. Este nivel incluye métodos de acceso a los datos, como API, gateways, ODBC, JDBC y OLE-DB. La ingesta de datos o ETL también se incluye en el nivel inferior.
Capa intermedia
El nivel intermedio de la arquitectura de un data warehouse se compone de un servidor OLAP, que es relacional (ROLAP) o multidimensional (MOLAP). Estos dos tipos se pueden combinar en un OLAP híbrido (HOLAP).
De primer nivel
El nivel superior de la arquitectura de un almacén de datos se compone de los clientes de frontend para realizar consultas, BI, dashboarding, generación de informes y análisis.
¿Cuáles son las tres variaciones de un data warehouse?
- Almacén de datos empresarial (EDW): un almacén de datos centralizado que utilizan diferentes equipos de una organización. Suele ser la fuente única de verdad para BI, analítica e informes.
- Almacén de datos operativos (ODS): un tipo de data warehouse que se centra en los datos operativos o transaccionales más recientes.
- Data mart: Una versión simplificada del data warehouse que se usa para una sola línea de negocio (LOB) o un solo proyecto. Un data mart es más pequeño que un EDW, pero la cantidad de data marts suele aumentar a medida que crece una organización y las LOBs quieren tener autoservicio.
Data lake frente a base de datos y data warehouse
¿Cuál es la diferencia entre un lago de datos y un almacén de datos?
Un lago de datos y un almacén de datos son dos enfoques distintos para la gestión y almacenamiento de datos.
Un lago de datos es un repositorio de datos no estructurados o semiestructurados que permite almacenar grandes cantidades de datos en bruto en su formato original. Los lagos de datos están diseñados para ingerir y almacenar todo tipo de datos —estructurados, semiestructurados o no estructurados— sin ningún esquema predefinido. Los datos a menudo se almacenan en su formato nativo y no se limpian, transforman ni integran, lo que facilita el almacenamiento y acceso a grandes cantidades de datos.
Un almacén de datos es un repositorio estructurado que almacena datos de varias fuentes de manera bien organizada, con el objetivo de proporcionar una única fuente de verdad para la inteligencia empresarial y el análisis. Los datos se limpian, transforman e integran en un esquema optimizado para consultas y análisis.
Un almacén de datos inteligente, que usa la arquitectura lakehouse, también proporciona una única fuente de verdad para inteligencia de negocios y analítica. Amplía un almacén de datos tradicional al almacenar datos estructurados, semiestructurados o no estructurados. Se incluyen funciones de administración de datos, como calidad de los datos y alertas de umbral.
¿Cuál es la diferencia entre un lago de datos y una base de datos?
Una base de datos es una colección de datos estructurados que va más allá del texto y los números para incluir imágenes, videos y mucho más. Muchos se refieren a este sistema de gestión de bases de datos por su sigla: DBMS. Un DBMS es el sistema de almacenamiento de datos que alimenta las aplicaciones y los análisis.
Por otro lado, un almacén de datos tradicional es un repositorio estructurado que proporciona datos para la inteligencia de negocios y la analítica. Los datos se depuran, se transforman y se integran en un esquema que está optimizado para consultas y análisis, lo que incluye agregar agregaciones comunes.
¿Cuál es la diferencia entre un lago de datos, un almacén de datos y un lakehouse de datos?
Un lakehouse de datos es un enfoque híbrido que combina lo mejor de ambos mundos. Es una arquitectura de datos moderna que integra las capacidades de un almacén de datos y un lago de datos en una plataforma unificada. Permite el almacenamiento de datos sin procesar en su formato original como un lago de datos, a la vez que proporciona capacidades de procesamiento y análisis de datos como un almacén de datos.
En resumen, la principal diferencia entre un lago de datos, un almacén de datos y un lakehouse de datos radica en su enfoque para gestionar y almacenar datos. Un almacén de datos almacena datos estructurados en un esquema predefinido, mientras que un lago de datos almacena datos sin procesar en su formato original, y un lakehouse de datos es un enfoque híbrido que combina las capacidades de ambos.
Lago de datos | Data Lakehouse | Almacén de datos tradicional | |
|---|---|---|---|
Tipos de datos | Todos los tipos: datos estructurados, datos semiestructurados, datos no estructurados (sin procesar) | Todos los tipos: datos estructurados, datos semiestructurados, datos no estructurados (sin procesar) | Solo datos estructurados |
Costo | $ | $ | $$$ |
Formato | Formato abierto | Formato abierto | Formato cerrado y propietario |
Escalabilidad | Escala para almacenar cualquier cantidad de datos a bajo costo, independientemente del tipo | Escala para almacenar cualquier cantidad de datos a bajo costo, independientemente del tipo | La ampliación se vuelve exponencialmente más costosa debido a los costos de los proveedores |
Usuarios previstos | Limitado: científicos de datos | Unificado: analistas de datos, científicos de datos, ingenieros de aprendizaje automático | Limitado: Analistas de datos |
Fiabilidad | Baja calidad, pantano de datos | Alta calidad, datos confiables | Alta calidad, datos confiables |
Facilidad de uso | Difícil: explorar grandes cantidades de datos sin procesar puede ser complicado sin herramientas para organizar y catalogar los datos | Simple: proporciona la simplicidad y la estructura de un almacén de datos con los casos de uso más amplios de un lago de datos | Simple: la estructura de un almacén de datos permite a los usuarios acceder de manera rápida y fácil a los datos para crear informes y análisis |
Rendimiento | Escaso | Alto | Alto |
¿Un lago de datos puede reemplazar a un almacén de datos?
En realidad no. Un lago de datos y un almacén de datos son dos enfoques diferentes para gestionar y almacenar datos, cada uno con sus propias fortalezas y debilidades. Si bien un lago de datos puede complementar un almacén de datos al proporcionar datos sin procesar para análisis avanzados, en su sentido tradicional no puede reemplazar completamente un almacén de datos. En su lugar, un lago de datos y un almacén de datos pueden complementarse entre sí, ya que el lago de datos sirve como fuente de datos sin procesar para análisis avanzados, y el almacén de datos proporciona una fuente estructurada, organizada y confiable de datos del negocio para informes y análisis.
Un data lake es la base para un data lakehouse, que puede reemplazar un data warehouse tradicional, con confiabilidad y rendimiento en formatos de datos abiertos como Delta Lake y Apache Iceberg™.
¿Un data lakehouse puede reemplazar a un data warehouse tradicional?
Sí. Un lakehouse de datos es una arquitectura de datos moderna que combina los beneficios de un almacén de datos y un lago de datos en una plataforma unificada. Un data lakehouse se basa en un lago de datos abierto y puede servir como reemplazo de un almacén de datos tradicional porque proporciona las capacidades tanto de un lago de datos como de un almacén de datos en una única plataforma.
Un lakehouse de datos permite el almacenamiento de datos sin procesar en su formato original como un lago de datos, a la vez que proporciona capacidades de procesamiento y análisis de datos como un almacén de datos. También aporta un enfoque de esquema en lectura, que permite flexibilidad en el procesamiento y la consulta de datos. La combinación de un lago de datos y un almacén de datos en una sola plataforma proporciona una mayor flexibilidad, escalabilidad y rentabilidad.
¿Qué es un almacén de datos moderno?
El almacenamiento de datos continúa evolucionando. Un almacén de datos moderno también se conoce como un almacén de datos inteligente porque usa tecnologías más recientes como AI. Un data warehouse inteligente aprovecha la arquitectura abierta de data lakehouse en lugar de la arquitectura de data warehouse tradicional. Un almacén de datos inteligente comprende el carácter único de sus datos y optimiza automáticamente la plataforma para escalar con baja latencia y alta concurrencia. Un almacén de datos inteligente también necesita una gobernanza unificada para la seguridad, los controles y el flujo de trabajo. Un almacén de datos inteligente usa IA para generar consultas, corregir errores, sugerir visualizaciones y más.
¿Qué es ETL en un almacén de datos?
Un data warehouse requiere datos. Esos datos deben cargarse en el almacén de datos (o referenciarse, con un concepto llamado federación de lakehouse). El proceso de extraer datos de los sistemas de origen, transformar los datos y, luego, cargarlos en el data warehouse se denomina ETL (extraer, transformar, cargar). El ETL se suele usar para integrar datos estructurados de múltiples fuentes en un esquema predefinido.
La federación de consultas es un estilo de ETL que se usa para ejecutar consultas en fuentes de datos de varios orígenes y en varias nubes. Puedes ver y consultar todos los datos desde un solo lugar sin necesidad de migrarlos a un sistema unificado. A veces, este concepto también se conoce como virtualización de datos.
¿Qué es una dimensión en un data warehouse?
Una dimensión de almacén de datos se utiliza para describir los datos con información de etiquetado estructurada. Una dimensión utiliza la información para filtrar, agrupar y etiquetar. Por ejemplo, una dimensión podría ser una entidad de negocio, como un cliente o un producto.
¿Qué es un hecho en un almacén de datos?
Un hecho de un data warehouse se usa para cuantificar los datos con números. Por ejemplo, un hecho podría ser pedidos de clientes o datos financieros.
¿Qué es el modelado dimensional en un almacén de datos?
El modelado dimensional es una técnica de almacenamiento de datos que organiza los datos en dimensiones y hechos. El modelado de dimensiones identifica los procesos de negocio importantes y, luego, modela el almacén de datos para dar soporte a esos procesos de negocio.
¿Qué es un esquema de estrella en un data warehouse?
Un esquema de estrella es un modelo de datos multidimensional que se usa para organizar datos en una base de datos de manera que sea fácil de entender y analizar. Los esquemas de estrella se pueden aplicar a almacenes de datos, bases de datos, data marts y otras herramientas. El diseño de esquema de estrella está optimizado para consultar grandes conjuntos de datos.
Presentados por Ralph Kimball en la década de 1990, los esquemas de estrella son eficientes para almacenar datos, mantener el historial y actualizar datos, ya que reducen la duplicación de definiciones de negocio repetitivas, lo que agiliza la agregación y el filtrado de datos en el almacén de datos.
¿Qué beneficios del almacén de datos pueden esperar las empresas?
- La consolidación de datos obtenidos de muchas fuentes. Un almacén de datos puede convertirse en un único punto de acceso para todos los datos, en lugar de requerir que los usuarios se conecten a decenas o incluso cientos de almacenes de datos individuales.
- Inteligencia histórica. Un almacén de datos integra datos de muchas fuentes para mostrar tendencias históricas.
- Separa el procesamiento analítico de las bases de datos transaccionales, lo que mejora el rendimiento de ambos sistemas.
- Calidad, consistencia y precisión de los datos. Los almacenes de datos utilizan un conjunto estándar de semántica en torno a los datos, incluida la consistencia en las convenciones de nomenclatura, códigos para varios tipos de productos, idiomas, monedas, etc.
- Cualquier persona puede encontrar respuestas en los datos, incluso los usuarios sin experiencia en SQL
Desafíos con los almacenes de datos
Sin importar el tipo de almacén de datos que uses, siguen existiendo desafíos:
- Las herramientas desarticuladas en los activos de datos y de IA crean un enfoque fragmentado, lo que compromete el gobierno de datos
- Los usuarios necesitan conocimientos y capacitación especializados para escribir consultas, comprender las estructuras de datos, encontrar y conectarse a las mejores fuentes de datos, etc.
- A medida que los almacenes de datos crecen, se vuelven más lentos —y en la nube, eso se encarece rápidamente por los costos de cómputo.
Escalabilidad y rendimiento
Con los crecientes volúmenes de datos, una arquitectura de lakehouse distribuye las funciones de computación, independientemente del almacenamiento, con el objetivo de mantener un rendimiento constante a costos óptimos. Necesitas una plataforma que esté diseñada para la elasticidad, lo que permite a las organizaciones escalar sus operaciones de datos según sea necesario. La escalabilidad se extiende a través de varias dimensiones:
- Serverless: La plataforma debe permitir que las cargas de trabajo se ajusten y escalen elásticamente en función de la capacidad de procesamiento necesaria. Esa asignación dinámica de recursos garantiza un procesamiento y análisis de datos rápido, incluso durante los picos de demanda.
- Concurrencia: La plataforma debería aprovechar la computación sin servidor y las optimizaciones impulsadas por AI para facilitar el procesamiento de datos concurrente y la ejecución de consultas. Esto garantiza que múltiples usuarios y equipos puedan realizar tareas de análisis simultáneamente sin restricciones de rendimiento.
- Almacenamiento: La plataforma debe integrarse sin problemas con los data lakes para facilitar el almacenamiento rentable de grandes volúmenes de datos y, a la vez, garantizar su disponibilidad y confiabilidad. También debería optimizar el almacenamiento de datos para mejorar el rendimiento y reducir los costos de almacenamiento.
La escalabilidad, aunque es esencial, se complementa con el rendimiento. La plataforma debería usar una variedad de optimizaciones impulsadas por IA para optimizar el rendimiento:
- Consulta optimizada: la plataforma debería usar técnicas de optimización de machine learning para acelerar la ejecución de consultas. Aprovecha la indexación automática, el almacenamiento en caché y la transferencia de predicados para garantizar que las consultas se procesen de manera eficiente, lo que permite obtener información valiosa rápidamente.
- Autoescalado: la plataforma debe escalar de forma inteligente los recursos sin servidor para que coincidan con tus cargas de trabajo, lo que garantiza que pagues solo por la capacidad de procesamiento que usas, a la vez que se mantiene un rendimiento de consulta óptimo.
- Rendimiento rápido de las consultas: la plataforma debe proporcionar un rendimiento de consultas extremadamente rápido a bajo costo (desde la ingesta de datos, ETL, streaming, ciencia de datos y consultas interactivas) directamente en su data lake.
- Delta Lake: La plataforma debe usar modelos de IA para resolver los desafíos comunes del almacenamiento de datos, de modo que obtenga un rendimiento más rápido sin tener que administrar tablas manualmente, incluso cuando cambian con el tiempo.
- Optimización predictiva: optimiza automáticamente tus datos para obtener el mejor rendimiento y precio. Aprende de tus patrones de uso de datos, crea un plan para realizar las optimizaciones correctas y luego ejecuta esas optimizaciones en una infraestructura serverless hiperoptimizada.
Desafíos con los almacenes de datos tradicionales
Los almacenes de datos tradicionales tienen una serie de desafíos adicionales:
- No tienen soporte para los datos no estructurados como imágenes, texto, datos de IoT o marcos de mensajería como HL7, JSON y XML. Los almacenes de datos tradicionales solo pueden almacenar datos limpios y altamente estructurados, a pesar de que Gartner estima que hasta el 80 % de los datos de una organización no son estructurados. Las organizaciones que desean utilizar sus datos no estructurados para desbloquear el poder de la IA tienen que buscar en otro lado.
- No tienen soporte para la IA y el aprendizaje automático. Los almacenes de datos están diseñados y optimizados específicamente para cargas de trabajo comunes de DWH, como informes históricos, BI y consultas. No se diseñaron ni se pensaron para soportar cargas de trabajo de aprendizaje automático.
- Solo SQL : los almacenes de datos (DWH) generalmente no ofrecen soporte para Python o R, los lenguajes preferidos por desarrolladores de aplicaciones, científicos de datos e ingenieros de aprendizaje automático.
- Duplicación de datos: muchas empresas tienen almacenes de datos y data marts temáticos o (departamentales), además de un lago de datos, lo que resulta en datos duplicados, gran cantidad de ETL redundantes y la ausencia de una única fuente de verdad.
- Dificultad en mantener la sincronización: mantener dos copias de los datos sincronizadas entre el lago y el almacén de datos genera una complejidad y fragilidad difíciles de gestionar. La desviación de datos puede causar informes inconsistentes y análisis defectuosos.
- Los formatos cerrados y patentados aumentan el bloqueo de los proveedores: la mayoría de los almacenes de datos empresariales utilizan su propio formato de datos patentado, en lugar de formatos basados en código abierto y estándares abiertos. Esto aumenta la dependencia del proveedor, dificulta o imposibilita el análisis de los datos con otras herramientas y dificulta la migración de los datos.
- Es costoso: los almacenes de datos comerciales te cobran por almacenar sus datos y también por analizarlos. Por lo tanto, los costos de almacenamiento y cómputo siguen estando estrechamente vinculados. La separación de cómputo y almacenamiento con un lago de datos significa que puede escalar cada componente de forma independiente según sea necesario.
- Soluciones de generación de informes independientes: Muchas veces, necesita hacer preguntas simples sobre sus datos sin todas las características de una solución de informes independiente, como “¿Cuáles son los ingresos por ventas del tercer trimestre?”
- Dependencia del formato de tabla: Necesitas flexibilidad en las distintas líneas de negocio y casos de uso, pero, a veces, los almacenes de datos te obligan a usar un formato de tabla particular (por ejemplo, Apache Iceberg).
Formatos de tabla propietarios
El formato de tabla es la tecnología principal que aporta las ventajas de los almacenes de datos a los data lakes. Los formatos de tabla organizan los datos y metadatos de una manera que representa el estado de una tabla a lo largo del tiempo.
Los formatos de tabla propietarios se suelen usar en entornos en la nube, donde el acceso eficiente a grandes conjuntos de datos es crucial para tareas como analytics, la generación de informes y el machine learning. Algunos proveedores crearán formatos o estructuras de archivos para solucionar problemas específicos, como reducir el tamaño de almacenamiento, disminuir las velocidades de lectura y escritura o agregar control de versiones.
El formato propietario de Databricks, Delta Lake, es una capa de gestión y gobierno de datos de código abierto y formato abierto que combina lo mejor de los data lakes y los data warehouses. Algunas de las características principales incluyen:
- Transacciones ACID: Delta Lake permite tener datos coherentes incluso mientras se ejecutan operaciones simultáneas como actualizaciones, eliminaciones e inserciones. Esto garantiza que tus datos estén siempre actualizados y coherentes.
- Metadatos escalables: A medida que los conjuntos de datos crecen, Delta Lake escala con ellos y permite a los usuarios almacenar metadatos en tablas. Esto hace que los cambios en los datos sean más fáciles de rastrear y compartir.
- Aplicación del esquema: Delta Lake garantiza que todos sus datos cumplan con un formato específico en una tabla.
- Compatibilidad con Apache Spark™: Como Delta Lake es de código abierto, es compatible con las API de Apache Spark. Puedes usar Delta Lake en tus aplicaciones de Spark existentes sin modificar tu código.
Para evitar la dependencia de un formato de tabla abierto (OTF) o tener que elegir entre Delta Lake y Apache Iceberg, puedes usar un formato universal como Delta Lake UniForm.
Multicloud
Es posible que su organización tenga datos distribuidos en dos o más proveedores de servicios en la nube para optimizar costos o para satisfacer las necesidades particulares de su conjunto de datos. Esto puede generar problemas si los datos se administran en diferentes redes y con diferentes esquemas para almacenarlos.
Una arquitectura de lakehouse moderna puede gestionar datos entre múltiples proveedores de servicios en la nube en lugar de depender de un solo sistema en la nube. Esto le permite a tu organización:
- Distribuir datos: Con datos en diferentes plataformas en la nube, tu empresa puede encontrar el conjunto de servicios que mejor se adapte a tu presupuesto o a tus requisitos de cumplimiento.
- Mejorar la resiliencia: los entornos multinube mejoran la disponibilidad de los datos al distribuir las cargas de trabajo y las copias de seguridad entre varios proveedores. Esto puede ser crucial si un servicio en la nube experimenta una interrupción o un tiempo de inactividad inesperado.
- Integración de datos: un data warehouse compatible con múltiples nubes también puede integrar datos de todas estas fuentes en tiempo real, lo que te da acceso a datos de calidad y te permite tomar mejores decisiones.
- Cumplimiento: La arquitectura multinube puede ayudarte a cumplir con requisitos legales y regulatorios específicos que pueden dictar dónde se almacenan tus datos geográficamente o cómo se almacenan en varios servicios en la nube.
Desafíos de los data warehouses inteligentes
Los almacenes de datos inteligentes tienen un conjunto de desafíos diferente:
- Este enfoque moderno sigue evolucionando, por lo que necesitas una organización que esté dispuesta a hacer evolucionar su estrategia
- Políticas de IA: Tu organización debe establecer políticas que rijan qué personas y sistemas deben poder usar las funciones de IA en un almacén de datos inteligente.
¿Qué soluciones ofrece Databricks para el almacenamiento de datos?
Databricks ofrece un data warehouse inteligente, Databricks SQL, que se basa en la arquitectura abierta de lakehouse de datos. Databricks SQL forma parte de una plataforma integrada, la Data Intelligence Platform, que incluye ML, gobierno de datos, flujos de trabajo y más. Al utilizar una base abierta y unificada para todos sus datos, obtiene ML/AI, streaming, orquestación, ETL y análisis en tiempo real, data warehousing, seguridad unificada, gobierno y catalogación, así como almacenamiento de datos unificado para la confiabilidad y el uso compartido en la misma plataforma. Además, como la Data Intelligence Platform de Databricks se basa en una arquitectura abierta de lakehouse de datos, puede almacenar todos los datos sin procesar, como registros, textos, audio, video e imágenes.
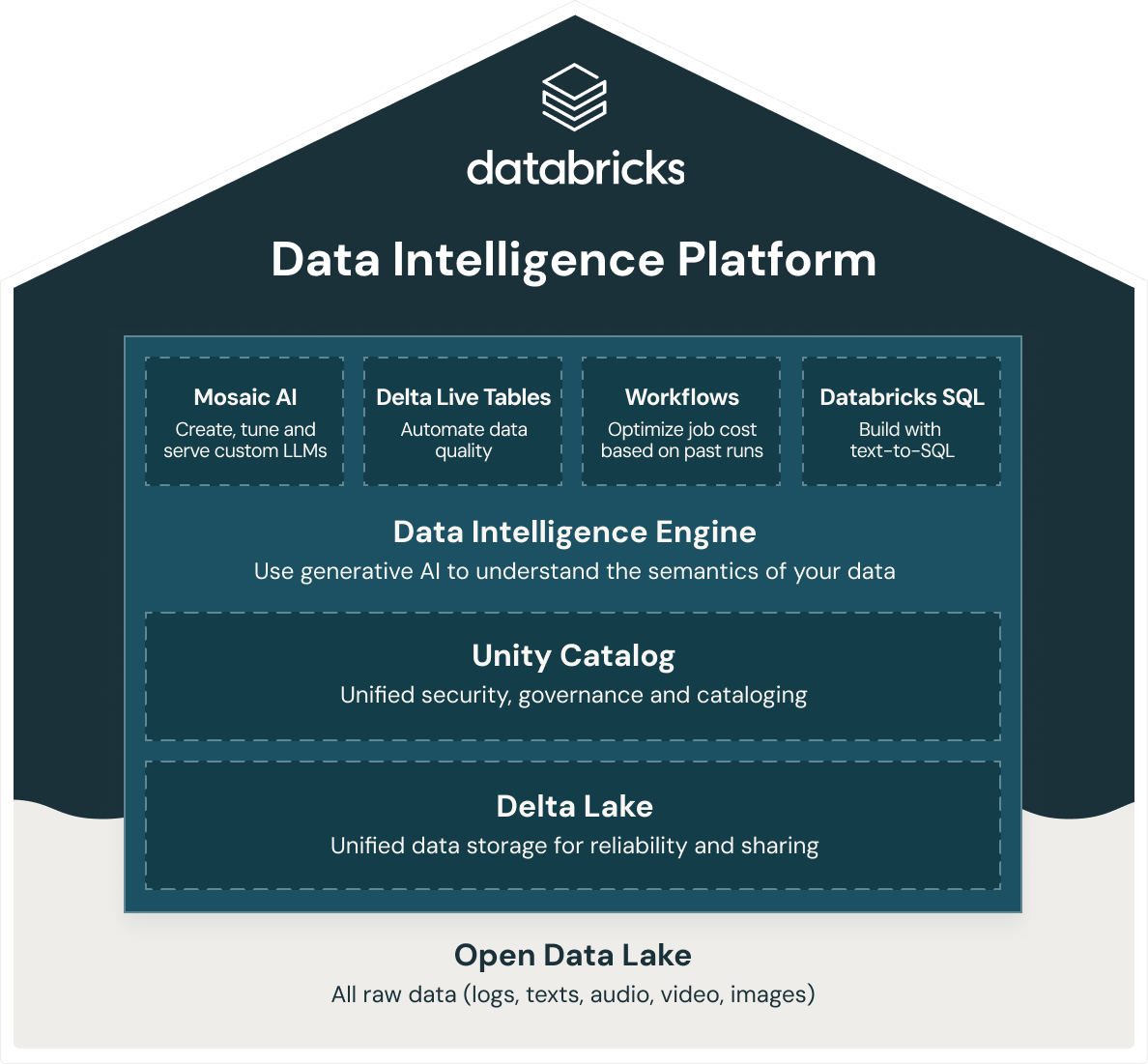
Para crear un lakehouse exitoso, las organizaciones han recurrido a Delta Lake, una capa de gestión y gobernanza de datos de código abierto y formato abierto que combina lo mejor de los lagos y almacenes de datos. La Data Intelligence Platform de Databricks utiliza Delta Lake para ofrecerle:
- Rendimiento récord mundial de almacén de datos con la economía de un lago de datos.
- Cómputo SQL sin servidor que elimina la necesidad de gestionar la infraestructura.
- Integración perfecta con la pila de datos moderna, como dbt, Tableau, PowerBI y Fivetran para ingerir, consultar y transformar datos en contexto.
- Una experiencia de desarrollo SQL de primera clase para todos los profesionales de datos de tu organización con soporte ANSI-SQL.
- Gobernanza detallada con linaje de datos, etiquetas a nivel de tabla/fila, controles de acceso basados en roles y más.
- Motor de inteligencia de datos impulsado por IA para comprender la semántica de sus datos