Databricks establece el récord oficial de rendimiento de almacenamiento de datos
por Reynold Xin y Mostafa Mokhtar
Hoy, nos enorgullece anunciar que Databricks SQL ha establecido un nuevo récord mundial en TPC-DS de 100 TB, el benchmark de rendimiento por excelencia para el data warehousing. Databricks SQL superó en 2.2 veces el récord anterior. A diferencia de la mayoría de las otras noticias sobre benchmarks, este resultado ha sido auditado y revisado formalmente por el consejo de TPC.
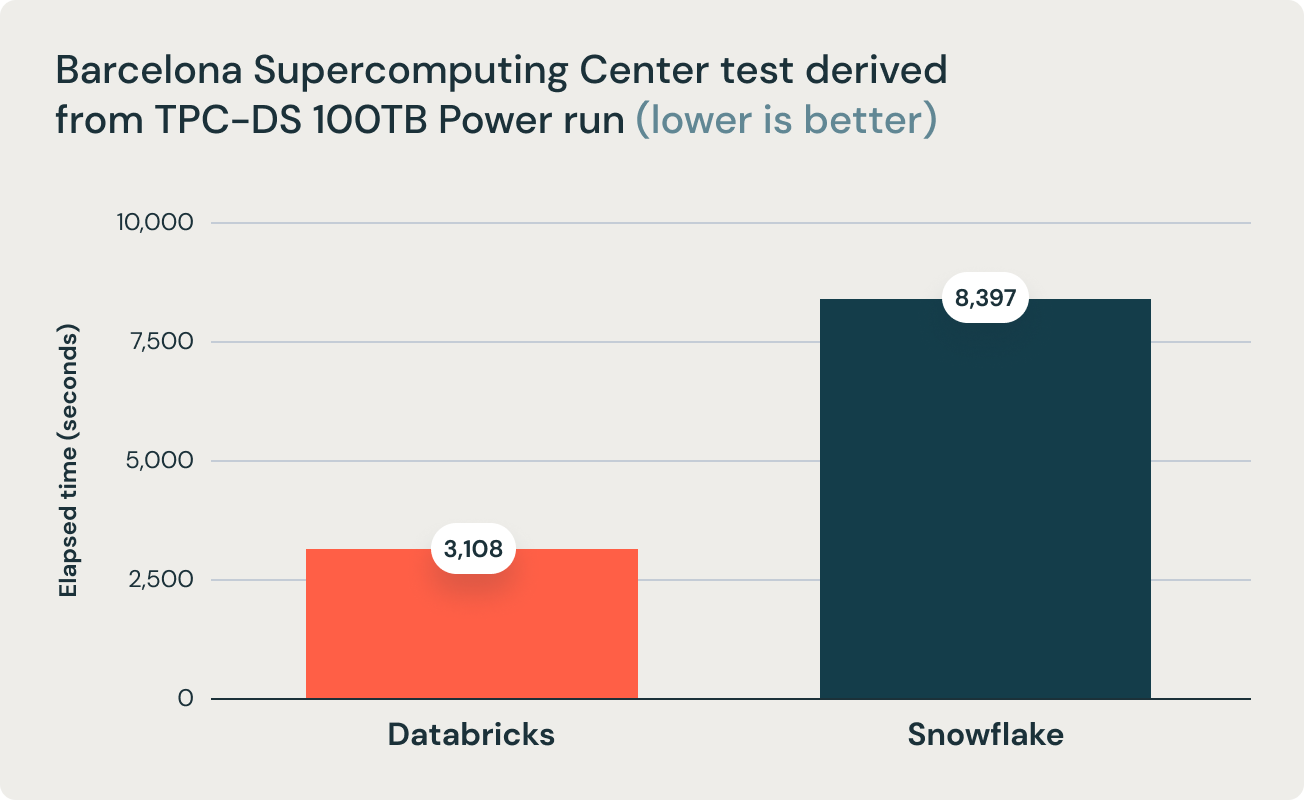
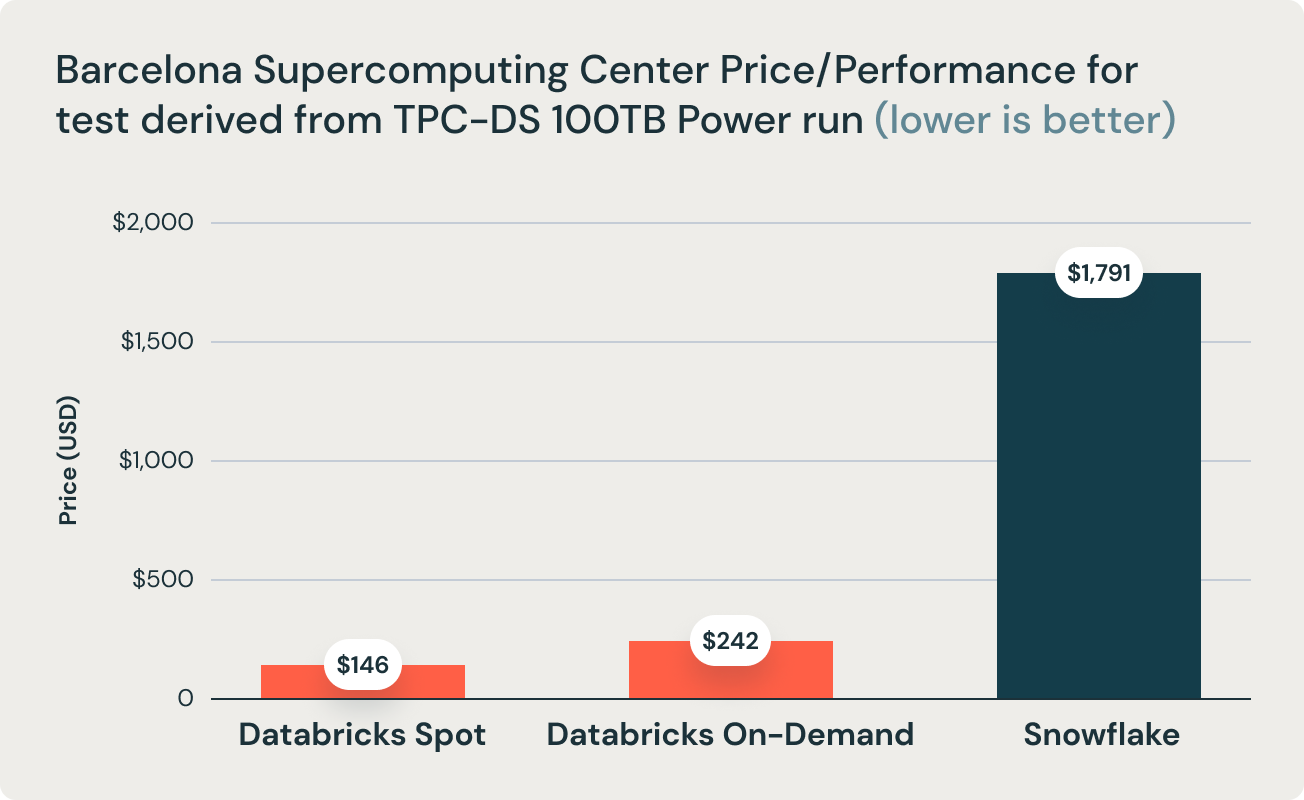
Estos resultados fueron corroborados por una investigación del Barcelona Supercomputing Center, que ejecuta con frecuencia benchmarks derivados de TPC-DS en data warehouses populares. Su investigación más reciente comparó Databricks y Snowflake, y encontró que Databricks era 2.7 veces más rápido y 12 veces mejor en términos de relación precio-rendimiento. Este resultado validó la tesis de que los almacenes de datos como Snowflake se vuelven prohibitivamente caros a medida que el tamaño de los datos aumenta en producción.
Databricks ha estado desarrollando rápidamente capacidades completas de data warehousing directamente en los data lakes, uniendo lo mejor de ambos mundos en una arquitectura de datos única denominada el data lakehouse. Anunciamos nuestro conjunto completo de capacidades de data warehousing como Databricks SQL en noviembre de 2020. Desde entonces, la pregunta abierta ha sido si una arquitectura abierta basada en un lakehouse puede ofrecer el rendimiento, la velocidad y el costo de los data warehouses clásicos. Este resultado demuestra sin lugar a dudas que esto es posible y alcanzable por la arquitectura lakehouse.
En lugar de solo compartir los resultados, nos gustaría aprovechar esta oportunidad para compartir con ustedes la historia de cómo logramos este nivel de rendimiento y el esfuerzo que implicó. Pero comenzaremos con los resultados:
Récord mundial de TPC-DS
Databricks SQL alcanzó 32,941,245 QphDS @ 100TB. Esto supera por 2,2x el récord mundial anterior que ostentaba el sistema personalizado de Alibaba, que alcanzó 14,861,137 QphDS @ 100TB. (Alibaba tenía un sistema impresionante que respaldaba la plataforma de comercio electrónico más grande del mundo). Databricks SQL no solo superó significativamente el récord anterior, sino que lo hizo reduciendo el costo total del sistema en un 10 % (basado en los precios de lista publicados sin descuentos).
Es perfectamente normal si no sabe qué significa la unidad QphDS. (Nosotros tampoco lo sabemos sin ver la fórmula.) QphDS es la métrica principal para TPC-DS, que representa el rendimiento de una combinación de cargas de trabajo, que incluyen (1) la carga del conjunto de datos, (2) el procesamiento de una secuencia de consultas (prueba de potencia), (3) el procesamiento de varios flujos de consulta simultáneos (prueba de rendimiento) y (4) la ejecución de funciones de mantenimiento de datos que insertan y eliminan datos.
La conclusión antes mencionada se ve respaldada por el equipo de investigación del Barcelona Supercomputing Center (BSC), que recientemente ejecutó un benchmark diferente derivado de TPC-DS que compara Databricks SQL y Snowflake, y descubrió que Databricks SQL era 2.7 veces más rápido que una configuración de Snowflake de tamaño similar.
¿Qué es TPC-DS?
TPC-DS es un benchmark de data warehousing definido por el Transaction Processing Performance Council (TPC). TPC es una organización sin fines de lucro creada por la comunidad de bases de datos a finales de los 80, que se enfoca en crear benchmarks que emulan escenarios del mundo real y, como resultado, pueden utilizarse objetivamente para medir el rendimiento de los sistemas de bases de datos. TPC ha tenido un profundo impacto en el campo de las bases de datos, con "guerras de benchmarks" que duraron décadas entre proveedores establecidos como Oracle, Microsoft e IBM que han impulsado el campo.
La sigla "DS" en TPC-DS significa "soporte de decisiones". Incluye 99 consultas de diversa complejidad, desde agregaciones muy simples hasta minería de patrones complejos. Es una prueba de rendimiento relativamente nueva (el trabajo comenzó a mediados de la década de 2000) que refleja la creciente complejidad de la analítica. En la última década aproximadamente, TPC-DS se ha convertido en la prueba de rendimiento estándar de facto para el almacenamiento de datos, adoptada por prácticamente todos los proveedores.
Sin embargo, debido a su complejidad, muchos sistemas de almacenamiento de datos, incluso los creados por los proveedores más consolidados, han modificado la prueba de rendimiento oficial para que sus propios sistemas tuvieran un buen rendimiento. (Algunos ajustes comunes incluyen la eliminación de ciertas características de SQL, como los rollups, o el cambio en la distribución de datos para eliminar el sesgo). Esta es una de las razones por las que ha habido muy pocas presentaciones para el benchmark oficial de TPC-DS, a pesar de que existen más de 4 millones de páginas en Internet sobre TPC-DS. Aparentemente, estos ajustes también explican por qué la mayoría de los proveedores parecen superar a todos los demás según sus propios benchmarks.
¿Cómo lo hicimos?
Como se mencionó anteriormente, ha habido dudas sobre si es posible que Databricks SQL supere a los data warehouses en rendimiento de SQL. La mayoría de los desafíos pueden resumirse en los siguientes cuatro problemas:
- Los data warehouses aprovechan formatos de datos propietarios y, como resultado, pueden evolucionarlos rápidamente, mientras que Databricks (basado en Lakehouse) se basa en formatos abiertos (como Apache Parquet y Delta Lake) que no cambian tan rápidamente. Como resultado, los EDW tendrían una ventaja inherente.
- Un gran rendimiento de SQL requiere la arquitectura MPP (procesamiento masivamente paralelo), y Databricks y Apache Spark no eran MPP.
- La clásica compensación entre el rendimiento y la latencia implica que un sistema puede ser excelente para consultas grandes (centradas en el rendimiento) o para consultas pequeñas (centradas en la latencia), pero no para ambas. Como Databricks se centraba en las consultas grandes, teníamos que tener un rendimiento bajo para las consultas pequeñas.
- Incluso si fuera posible, la creencia popular es que llevaría una década o más construir un sistema de almacenamiento de datos. No hay forma de que se pueda progresar tan rápidamente.
En el resto de la entrada del blog, los analizaremos uno por uno.
Formatos de datos propietarios vs. abiertos
Uno de los principios clave de la arquitectura Lakehouse es el formato de almacenamiento abierto. "Abierto" no solo evita la dependencia de un proveedor, sino que también permite que se desarrolle un ecosistema de herramientas de forma independiente del proveedor. Uno de los principales beneficios de los formatos abiertos es la estandarización. Como resultado de esta estandarización, la mayoría de los datos empresariales se encuentran en data lakes abiertos y Apache Parquet se ha convertido en el estándar de facto para almacenar datos. Al llevar el rendimiento de nivel de almacén de datos a los formatos abiertos, esperamos minimizar el movimiento de datos y simplificar la arquitectura de datos para las cargas de trabajo de BI e IA.
Un ataque obvio contra lo "abierto" es que los formatos abiertos son difíciles de cambiar y, como resultado, difíciles de mejorar. Aunque en teoría este argumento tiene sentido, en la práctica no es exacto.
En primer lugar, es definitivamente posible que los formatos abiertos evolucionen. Parquet, el formato abierto más popular para el almacenamiento de grandes volúmenes de datos, ha pasado por múltiples iteraciones de mejoras. Una de las principales motivaciones para introducir Delta Lake fue la de incorporar capacidades adicionales que eran difíciles de implementar en la capa Parquet. Delta Lake incorporó indexación y estadísticas adicionales a Parquet.
En segundo lugar, el sistema de Databricks transcodifica automáticamente los datos brutos de Delta Lake y Parquet a un formato más eficiente al cargar datos desde almacenes de objetos a SSD NVMe locales (sin intervención del usuario). Esto permite más oportunidades de optimización.
Dicho esto, para la mayoría de las cargas de trabajo de almacenamiento de datos, Delta Lake y Parquet ya proporcionan optimizaciones suficientes en comparación con los formatos propietarios que utilizan los almacenes de datos. Para estas cargas de trabajo, las oportunidades de optimización provienen principalmente de la capacidad de procesar las consultas más rápido, en lugar de analizar más datos con mayor rapidez. De hecho, para TPC-DS, consultar datos almacenados en caché en un formato interno más optimizado es solo un 10 % más rápido que consultar datos fríos en S3 (hemos descubierto que esto es cierto tanto para los almacenes de datos que evaluamos como para Databricks).
Arquitectura MPP
Un error común es que los almacenes de datos emplean la arquitectura MPP, que es excelente para el rendimiento de SQL, mientras que Databricks no lo hace. La arquitectura MPP se refiere a la capacidad de aprovechar múltiples nodos para procesar una sola consulta. Así es exactamente como está diseñado Databricks SQL. No se basa en Apache Spark, sino en Photon, una reescritura completa de un motor, creado desde cero en C++, para el hardware SIMD moderno y que realiza un procesamiento paralelo de consultas intensivo. Así, Photon es un motor MPP.
Compensación entre rendimiento y latencia
El rendimiento frente a la latencia es la clásica compensación en los sistemas informáticos, lo que significa que un sistema no puede obtener un alto rendimiento y una baja latencia simultáneamente. Si un diseño favorece el rendimiento (p. ej., al procesar datos por lotes), tendría que sacrificar la latencia. En el contexto de los sistemas de datos, esto significa que un sistema no puede procesar consultas grandes y pequeñas de manera eficiente al mismo tiempo.
No negaremos que esta contrapartida existe. De hecho, a menudo lo discutimos en nuestros documentos de diseño técnico. Sin embargo, los sistemas de vanguardia actuales, incluidos los nuestros y todos los almacenes populares, están muy lejos de la frontera óptima tanto en el frente del rendimiento como en el de la latencia.
En consecuencia, es totalmente posible crear un nuevo diseño e implementación que mejore simultáneamente tanto su rendimiento como su latencia. Así es exactamente como hemos desarrollado casi todas nuestras tecnologías clave en los últimos dos años: Photon, Delta Lake y muchas otras tecnologías de vanguardia han mejorado el rendimiento tanto de las consultas grandes como de las pequeñas, estableciendo un nuevo récord de rendimiento.
Tiempo y enfoque
Por último, la creencia general es que un sistema de base de datos tardaría al menos una década en madurar. Dado el enfoque reciente de Databricks en Lakehouse (para admitir cargas de trabajo de SQL), se necesitaría un esfuerzo adicional para que SQL tuviera un buen rendimiento. Esto es válido, pero permítanos explicarle cómo lo hicimos mucho más rápido de lo que se podría esperar.
Antes que nada, esta inversión no comenzó hace solo un año o dos. Desde la creación de Databricks, hemos invertido en diversas tecnologías fundamentales para admitir las cargas de trabajo de SQL que también beneficiarían a las cargas de trabajo de IA en Databricks. Esto incluye un optimizador de consultas completo basado en costos, un motor de ejecución vectorizado nativo y diversas capacidades como las funciones de ventana. La gran mayoría de las cargas de trabajo en Databricks se ejecutan a través de estos gracias a la API DataFrame de Spark, que se asigna a su motor de SQL, por lo que estos componentes han tenido años de pruebas y optimización. No habíamos puesto tanto énfasis en las cargas de trabajo de SQL. El cambio de posicionamiento hacia el Lakehouse es reciente, impulsado por el deseo de nuestros clientes de simplificar sus arquitecturas de datos.
En segundo lugar, el modelo SaaS ha acelerado los ciclos de desarrollo de software. En el pasado, la mayoría de los proveedores tenían ciclos de lanzamiento anuales y luego otro ciclo de varios años para que los clientes instalaran y adoptaran el software. En SaaS, nuestro equipo de ingeniería puede proponer un nuevo diseño, implementarlo y lanzarlo a un subconjunto de clientes en cuestión de días. Este ciclo de desarrollo más corto permitió a los equipos obtener retroalimentación rápidamente e innovar más rápido.
En tercer lugar, Databricks podría aportar un enfoque mucho más significativo a este problema, tanto en términos de capacidad de liderazgo como de capital. Los intentos anteriores de crear un nuevo sistema de data warehouse fueron realizados por startups o por un nuevo equipo dentro de una gran empresa. Nunca ha habido una startup de bases de datos tan bien financiada como Databricks (con más de 3500 millones de dólares recaudados) para atraer el talento necesario para construir esto. Un nuevo esfuerzo dentro de una gran empresa sería simplemente otro esfuerzo más y no contaría con toda la atención de los directivos.
Aquí tuvimos una situación única: al principio, nos enfocamos en establecer nuestro negocio no en el almacenamiento de datos, sino en campos relacionados (ciencia de datos e IA) que compartían muchos de los problemas tecnológicos comunes. Este éxito inicial nos permitió financiar la formación del equipo de SQL más ambiciosa de la historia; en poco tiempo, hemos reunido un equipo con una amplia experiencia en almacenamiento de datos, una hazaña que a muchas otras empresas les llevaría alrededor de una década. Entre ellos se encuentran ingenieros y diseñadores principales de algunos de los sistemas de datos más exitosos, como Amazon Redshift; BigQuery, F1 (el sistema interno de almacenamiento de datos de Google) y Procella (el sistema interno de almacenamiento de datos de YouTube) de Google; Oracle; IBM DB2 y Microsoft SQL Server.
En resumen, se necesitan varios años para desarrollar un gran rendimiento de SQL. No solo aceleramos esto aprovechando nuestras circunstancias únicas, sino que también empezamos hace años, aunque no lo hayamos anunciado a los cuatro vientos.
Cargas de trabajo reales de los clientes
Nos entusiasma ver que nuestros clientes validen los resultados de este benchmark. Más de 5000 organizaciones de todo el mundo utilizan la plataforma Lakehouse de Databricks para resolver algunos de los problemas más difíciles del mundo. Por ejemplo:
- Bread Finance es una plataforma de pagos impulsada por la tecnología con casos de uso de big data, como informes financieros, detección de fraudes, riesgo crediticio, estimación de pérdidas y un motor de recomendación de embudo completo. En la Databricks Lakehouse Platform, pueden pasar de trabajos por lotes nocturnos a una ingesta casi en tiempo real y reducir el tiempo de procesamiento de datos en un 90 %. Además, la plataforma de datos puede escalar hasta 140 veces el volumen de datos con solo 1.5 veces el costo.
- Shell está utilizando nuestra plataforma lakehouse para permitir que cientos de analistas de datos ejecuten consultas rápidas en conjuntos de datos a escala de petabytes con herramientas de BI estándar, lo que consideran un "punto de inflexión".
- Regeneron está acelerando la identificación de dianas farmacológicas, lo que proporciona información más rápida a los biólogos computacionales al reducir el tiempo que tardan en ejecutar consultas en todo su conjunto de datos de 30 minutos a 3 segundos, una mejora de 600 veces.
Resumen
Databricks SQL, desarrollado sobre la arquitectura Lakehouse, es el almacén de datos más rápido del mercado y ofrece la mejor relación precio/rendimiento. Ahora puede obtener un gran rendimiento en todos sus datos con baja latencia tan pronto como se ingieren nuevos datos, sin tener que exportarlos a un sistema diferente.
Esto es un testimonio de la visión de Lakehouse, de llevar el rendimiento de data warehousing de clase mundial a los data lakes. Por supuesto, no construimos solo un data warehouse. La arquitectura Lakehouse proporciona la capacidad de cubrir todas las cargas de trabajo de datos, desde el warehousing hasta la ciencia de datos y el machine learning.
Pero aún no hemos terminado. Hemos reunido al mejor equipo del mercado, y están trabajando arduamente para ofrecer el próximo gran avance en rendimiento. Además del rendimiento, también estamos trabajando en una infinidad de mejoras en la facilidad de uso y la gobernanza. Esperen más noticias de nuestra parte en el próximo año.
El TPC no audita ni valida los resultados de los benchmarks derivados del TPC-DS y no considera que los resultados de los benchmarks derivados sean comparables a los resultados publicados del TPC-DS.
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.