Fotón
El motor de próxima generación para Lakehouse
Photon es el motor de próxima generación en la plataforma Databricks Lakehouse que ofrece un rendimiento de consultas extremadamente rápido a bajo costo, desde la ingesta de datos, ETL, transmisión, ciencia de datos y consultas interactivas, directamente en tu lago de datos. Photon es compatible con las API de Apache Spark™, por lo que comenzar es tan fácil como activarlo, sin cambios en el código ni dependencia de un proveedor.
Más económico y más rápido
Diseñado desde cero para ofrecer el rendimiento más rápido con un menor costo, Photon proporciona un ahorro de hasta el 80 % en el TCO, a la vez que acelera las cargas de trabajo de datos y analítica, logrando aumentos de velocidad de hasta 12 veces.
Diseñado para todos los casos de uso
Photon es el primer motor que permite a los equipos de datos estandarizar un conjunto de API para todas las cargas de trabajo —ETL, análisis y ciencia de datos— por lotes o en streaming.
Sin cambios de código
Photon es un motor compatible con ANSI diseñado para ser compatible con las API modernas de Apache Spark y simplemente funciona con tu código existente, SQL, Python, R, Scala y Java, sin necesidad de reescritura.
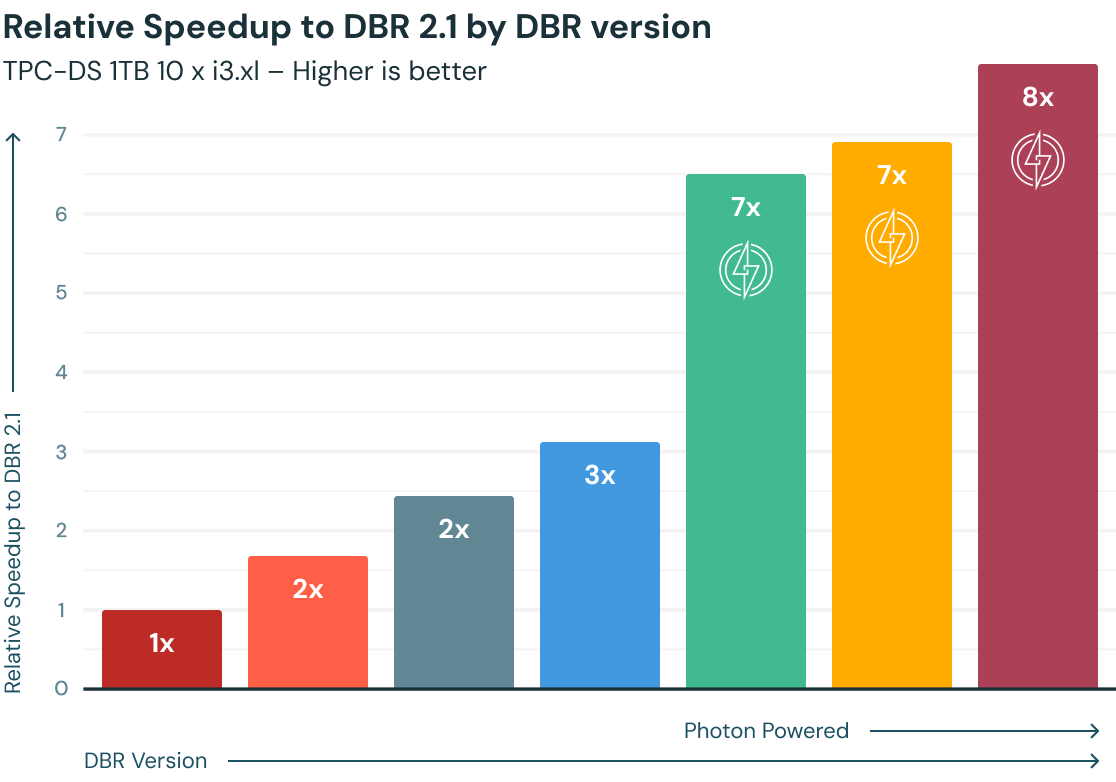
¿Por qué Photon?
El rendimiento de las consultas en Databricks ha aumentado constantemente a lo largo de los años, impulsado por Apache Spark y miles de optimizaciones empaquetadas como parte de Databricks Runtimes (DBR). Photon, un nuevo motor vectorizado nativo escrito completamente en C++, proporciona una aceleración adicional de 2 veces según el punto de referencia TPC-DS de 1 TB, y los clientes observaron aceleraciones de 3 a 8 veces en promedio, en función de sus cargas de trabajo, en comparación con las últimas versiones de DBR.
CASOS DE USO

Trabajos de producción
Acelera trabajos de producción a gran escala en SQL y Spark DataFrames

Aplicaciones de IoT
Análisis de series temporales más rápido usando Photon en comparación con Spark y Databricks Runtime tradicional

Privacidad de datos y cumplimiento
Consulta conjuntos de datos a escala de petabytes para identificar y eliminar registros sin duplicar datos con Delta Lake, trabajos de producción y Photon.

Carga de datos en Delta Lake y Parquet
La E/S vectorizada de Photon acelera las cargas de datos para las tablas de Delta Lake y Parquet, lo que disminuye el tiempo de ejecución general y el costo de los trabajos de ingeniería de datos.
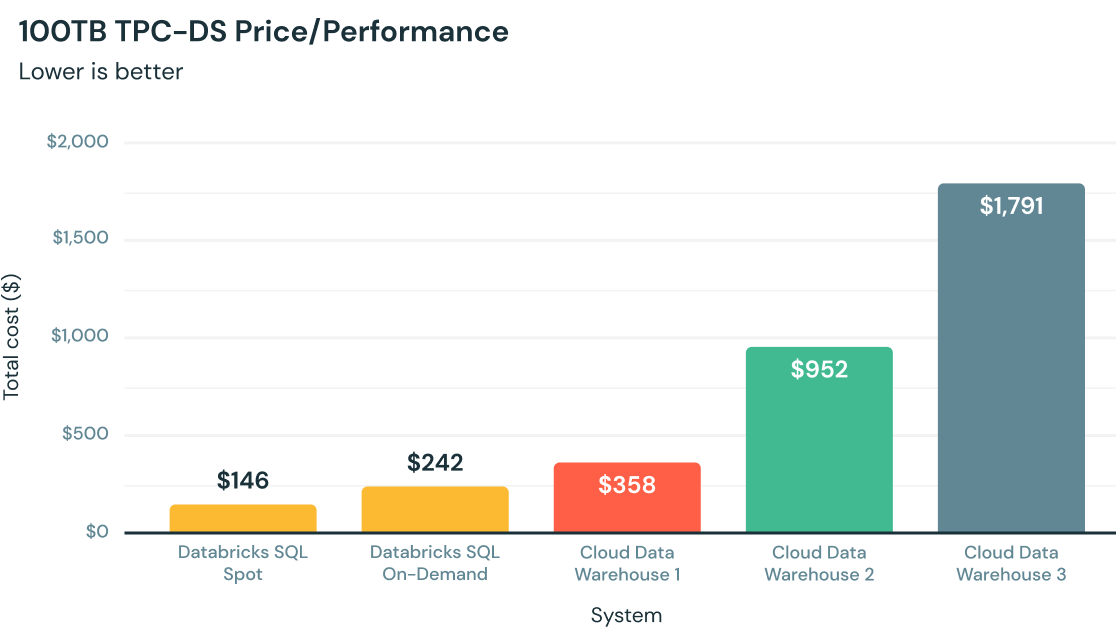
¿Cómo funciona?
La mejor relación precio/rendimiento para análisis en la nube
Escrito desde cero en C++, Photon aprovecha el hardware moderno para consultas más rápidas, al ofrecer hasta 12 veces una mejor relación precio/rendimiento en comparación con otros almacenes de datos en la nube, todo de forma nativa en tu lago de datos.
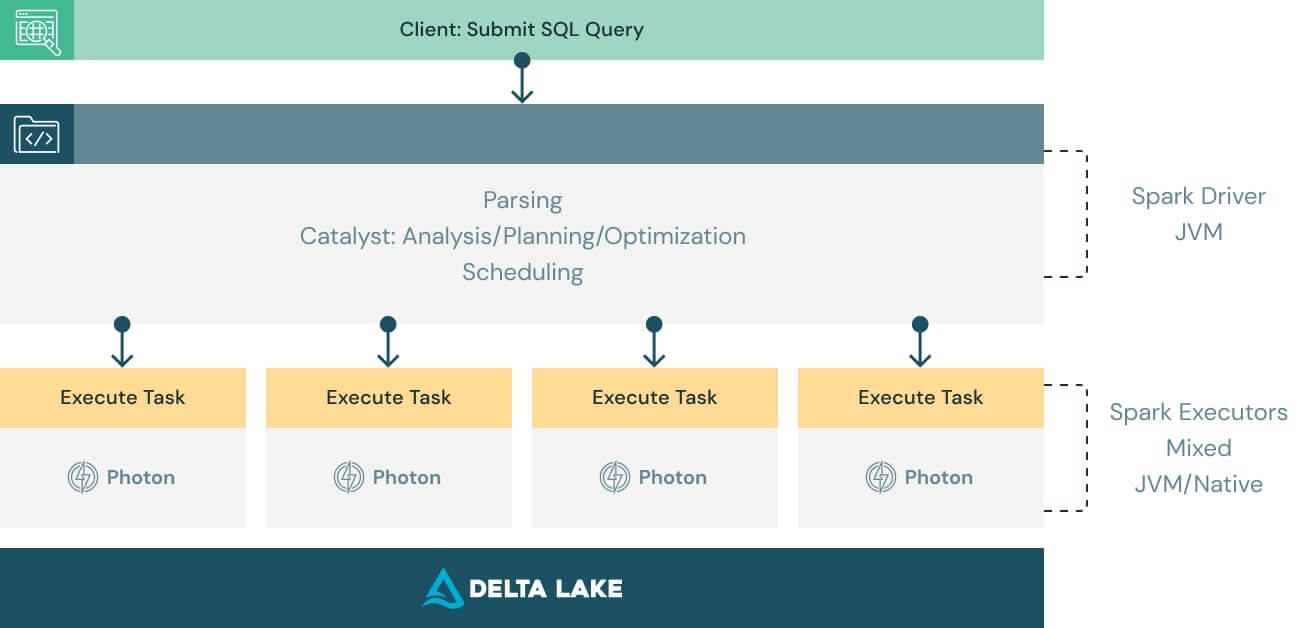
Funciona con tu código existente y evita la dependencia de un proveedor
Photon está diseñado para ser compatible con las API de Apache Spark DataFrame y SQL, a fin de garantizar que las cargas de trabajo se ejecuten sin problemas y sin necesidad de cambios en el código. Todo lo que tienes que hacer para beneficiarte de Photon es activarlo. Photon coordinará sin problemas el trabajo y los recursos y acelerará de manera transparente partes de tus consultas SQL y Spark. No se requiere ajuste ni intervención del usuario.

Optimización para todos los casos de uso de datos y cargas de trabajo
Si bien comenzamos Photon centrándonos principalmente en SQL para ofrecerles a los clientes un rendimiento de almacenamiento de datos de primer nivel en sus lagos de datos, desde entonces hemos ampliado significativamente el alcance de las fuentes de ingesta, los formatos, las API y los métodos compatibles con Photon. Como resultado, los clientes han visto importantes ahorros en costos de infraestructura y aumentos de velocidad en Photon en todas sus cargas de trabajo modernas de Spark (por ejemplo, Spark SQL y DataFrame).
Descubre más
RECURSOS
Documentos
Eventos
Blogs
¿Listo para empezar?