Apache Spark y Photon reciben premios SIGMOD
por Reynold Xin y Matei Zaharia
Esta semana, muchos de los ingenieros e investigadores más influyentes de la comunidad de gestión de datos se reúnen en persona en Filadelfia para la conferencia ACM SIGMOD, después de dos años de reuniones virtuales. Como parte del evento, nos emocionó ver los siguientes dos premios:
- Apache Spark recibió el Premio de Sistemas SIGMOD.
- Databricks Photon recibió el premio al Mejor Artículo de la Industria
Quisimos aprovechar esta oportunidad para analizar el contexto y cómo llegamos hasta aquí.
¿Qué es ACM SIGMOD y cuáles son los premios?
ACM SIGMOD significa Grupo de Interés Especial en la Gestión de Datos de la Association of Computing Machinery. Lo sabemos, es un nombre largo. Todos le dicen SIGMOD. Es la conferencia más prestigiosa para investigadores e ingenieros de bases de datos, ya que muchas de las ideas más influyentes en el campo de las bases de datos, desde los almacenes de columnas hasta las optimizaciones de consultas, se han publicado en este evento.
El Premio de Sistemas SIGMOD se otorga anualmente a un “sistema cuyas contribuciones técnicas han tenido un impacto significativo en la teoría o la práctica de los sistemas de gestión de datos a gran escala”. Estos sistemas tienden a tener aplicaciones a gran escala en el mundo real, además de haber influido en la forma en que se diseñan los futuros sistemas de bases de datos. Entre los ganadores anteriores se encuentran Postgres, SQLite, BerkeleyDB y Aurora.
El Premio al Mejor Artículo de la Industria se otorga anualmente a un artículo en función de la combinación de su impacto en el mundo real, la innovación y la calidad de la presentación.
Origen de los datos y la IA de Apache Spark
Hace aproximadamente una década, Netflix inició una competencia llamada Premio Netflix, en la que anonimizaron su vasta colección de calificaciones de películas de los usuarios y pidieron a los competidores que crearan algoritmos para predecir cómo calificarían los usuarios las películas. El trofeo de 1 millón de dólares sería para el equipo con el mejor modelo de machine learning.
Un grupo de estudiantes de doctorado de la UC Berkeley decidió competir. El primer desafío con el que se encontraron fue que las herramientas simplemente no eran lo suficientemente buenas. Para crear mejores modelos, necesitaban una forma rápida e iterativa de limpiar, analizar y procesar grandes cantidades de datos (que no cabían en la laptop de un estudiante), y necesitaban un framework lo suficientemente expresivo para componer algoritmos de ML experimentales.
Los almacenes de datos, que eran el estándar para los datos empresariales, no podían manejar los datos no estructurados y carecían de expresividad. Discutieron este desafío con otro estudiante de doctorado, Matei Zaharia. Juntos, diseñaron un nuevo marco de computación paralela llamado Spark, con una nueva e innovadora estructura de datos distribuidos llamada RDD. Spark permitía a sus usuarios ejecutar operaciones de datos en paralelo de forma rápida y concisa.
O dicho de otra manera, es rápido para escribir código y rápido para ejecutarlo. La rapidez de escritura es importante porque hace que el programa sea más comprensible y permite componer algoritmos más complejos con facilidad. La rapidez de ejecución significa que los usuarios pueden obtener respuesta más rápido y crear sus modelos usando datos en constante crecimiento.

Resultó que los estudiantes no estaban solos. Eran los inicios de las aplicaciones de datos e IA en la industria, y todos enfrentaban desafíos similares. Por demanda popular, el proyecto se trasladó a la Apache Software Foundation y se convirtió en una comunidad masiva.
Hoy en día, Spark es el estándar de facto para el procesamiento de datos y sigue creciendo:
- Se ha descargado 45 millones de veces el mes pasado, solo en PyPI y Maven Central. Esto representa un crecimiento interanual del 90 % en las descargas.
- Se utiliza en al menos 204 países y regiones.
- Ocupa el puesto n.º 1 entre las tecnologías mejor pagadas en la encuesta para desarrolladores de Stack Overflow de 2021.
El premio SIGMOD Systems es una validación de la adopción del proyecto, así como de su influencia en las futuras generaciones de sistemas para que consideren los datos y la IA como un paquete unificado.
Photon: nuevas cargas de trabajo y Lakehouse
A medida que Apache Spark ganaba popularidad, descubrimos que las organizaciones querían hacer algo más que el procesamiento de datos a gran escala y el aprendizaje automático con él: querían ejecutar aplicaciones tradicionales de almacenamiento de datos interactivas en los mismos conjuntos de datos que utilizaban en otras partes de su negocio, eliminando la necesidad de gestionar múltiples sistemas de datos. Esto llevó al concepto de sistemas lakehouse: un único almacén de datos que puede realizar procesamiento a gran escala y consultas SQL interactivas, combinando los beneficios de los sistemas de data warehouse y data lake.
Para dar soporte a este tipo de casos de uso, desarrollamos Photon, un motor de ejecución vectorizado y rápido de C++ para cargas de trabajo de Spark y SQL que se ejecuta detrás de las interfaces de programación existentes de Spark. Photon permite consultas interactivas mucho más rápidas y una concurrencia mucho mayor que Spark, a la vez que admite las mismas API y cargas de trabajo, incluidas las aplicaciones de SQL, Python y Java. Hemos visto excelentes resultados con Photon en cargas de trabajo de todos los tamaños, desde establecer el récord mundial en el benchmark de almacenes de datos a gran escala TPC-DS el año pasado hasta ofrecer un rendimiento 3 veces superior en consultas pequeñas y concurrentes.
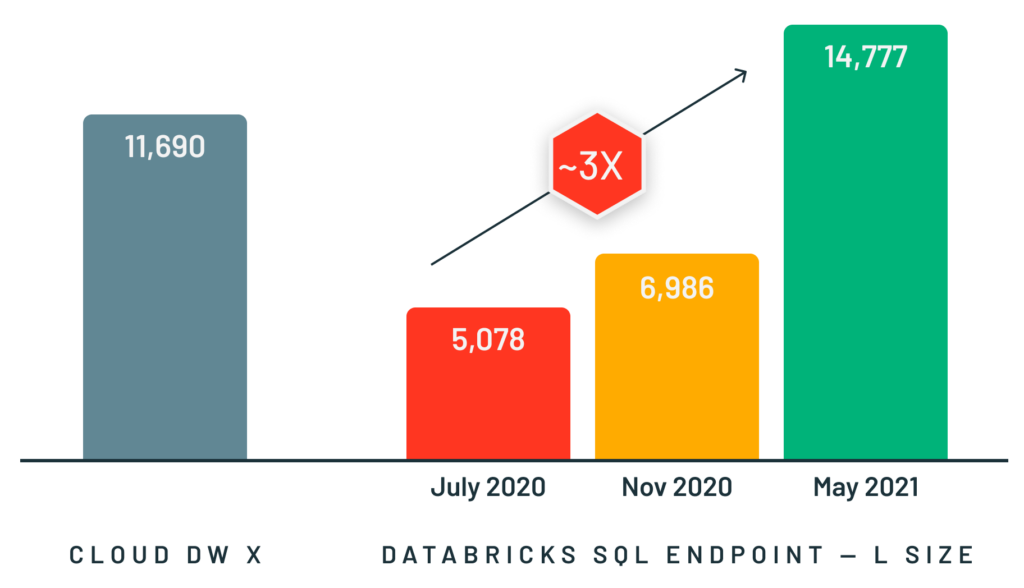
Diseñar e implementar Photon fue un desafío porque necesitábamos que el motor conservara la expresividad y la flexibilidad de Spark (para admitir la amplia gama de aplicaciones), que nunca fuera más lento (para evitar regresiones de rendimiento) y que fuera significativamente más rápido en nuestras cargas de trabajo objetivo. Además, a diferencia de un motor de data warehouse tradicional que asume que todos los datos se han cargado en un formato propietario, Photon necesitaba funcionar en el entorno de lakehouse, procesando datos en formatos abiertos como Delta Lake y Apache Parquet, con suposiciones mínimas sobre el proceso de ingesta (p. ej., disponibilidad de índices o estadísticas de datos). Nuestro artículo de SIGMOD describe cómo abordamos estos desafíos y muchos de los detalles técnicos de la implementación de Photon.
Nos emocionó mucho ver que este trabajo fuera reconocido como el Mejor Artículo de la Industria y esperamos que les dé a los ingenieros de bases de datos y a los investigadores buenas ideas sobre los desafíos de este nuevo modelo de sistemas de lakehouse. Por supuesto, también estamos muy entusiasmados con lo que nuestros clientes han hecho con Photon hasta ahora; el nuevo motor ya ha crecido hasta representar una fracción significativa de nuestra carga de trabajo.
Si asiste a SIGMOD, pase por el stand de Databricks y salúdenos. Nos encantaría conversar juntos sobre el futuro de los sistemas de datos. A cambio, le regalaremos una camiseta con la frase “el mejor data warehouse es un lakehouse”.

Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.