¿Qué es Extraer Transformar Carga?
El proceso fundamental de ingeniería de datos para extraer datos de múltiples fuentes, transformarlos en formatos utilizables y cargarlos en sistemas de destino para su análisis.
- ETL extrae datos sin procesar de diversas fuentes, los limpia y transforma según las reglas de negocio, y luego los carga en almacenes o lagos para su posterior análisis.
- Las canalizaciones de datos automatizan los flujos de trabajo de ETL, pero enfrentan desafíos con código complejo, reutilización limitada y el mantenimiento de la confiabilidad en fuentes de datos dispares.
- Los procesos ETL modernos incorporan bases de datos de prueba para capacidades de reversión y generan registros de auditoría para el cumplimiento normativo y la supervisión de la calidad de los datos.
¿Qué es ETL?
A medida que crece la cantidad de datos, fuentes de datos y tipos de datos en las organizaciones, también crece la importancia de utilizar esos datos en iniciativas de analítica, ciencia de datos y aprendizaje automático para obtener insights empresariales. La necesidad de priorizar estas iniciativas ejerce una presión cada vez mayor sobre los equipos de ingeniería de datos, ya que procesar los datos brutos y desordenados para convertirlos en datos limpios, actualizados y confiables es un paso fundamental antes de poder llevar a cabo estas iniciativas. ETL, que significa extraer, transformar y cargar, es el proceso que emplean los ingenieros de datos para extraer datos de diferentes fuentes, transformar los datos en un recurso utilizable y confiable, y cargar esos datos en los sistemas a los que los usuarios finales pueden acceder y usar para resolver problemas empresariales.
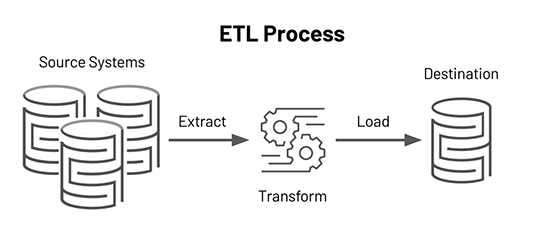
¿Cómo funciona ETL?
Extraer
El primer paso de este proceso consiste en extraer datos de las fuentes de destino, que suelen ser heterogéneas, como sistemas empresariales, API, datos de sensores, herramientas de marketing, bases de datos de transacciones y otras. Como puedes ver, algunos de estos tipos de datos probablemente sean las salidas estructuradas de sistemas ampliamente usados, mientras que otros son registros de servidor JSON semiestructurados. Existen diferentes formas de realizar la extracción, tres métodos de extracción de datos:
- Extracción parcial: la forma más fácil de obtener los datos es si el sistema de origen te notifica cuando se ha cambiado un registro.
- Extracción parcial (con notificación de actualización): no todos los sistemas pueden proporcionar una notificación en caso de que se haya producido una actualización; sin embargo, pueden señalar los registros que se han modificado y proporcionar un extracto de dichos registros.
- Extracto completo: hay ciertos sistemas que no pueden identificar qué datos se cambiaron en absoluto. En este caso, una extracción completa es la única posibilidad de extraer los datos del sistema. Este método requiere tener una copia del último extracto en el mismo formato para que puedas identificar los cambios que se realizaron.
Transformar
El segundo paso consiste en transformar los datos en bruto extraídos de las fuentes en un formato que pueda ser usado por diferentes aplicaciones. En esta etapa, los datos se limpian, mapean y transforman, a menudo a un esquema específico, para satisfacer las necesidades operativas. Este proceso implica varios tipos de transformación que garantizan la calidad e integridad de los datos. Los datos no suelen cargarse directamente en el origen de datos de destino, sino que es común cargarlos en una base de datos provisional. Este paso garantiza una rápida reversión en caso de que algo no salga según lo previsto. Durante esta etapa, tienes la posibilidad de generar informes de auditoría para el cumplimiento normativo, o diagnosticar y reparar cualquier problema de datos.
Cargar
Finalmente, la función de carga es el proceso de escribir datos convertidos desde un área de ensayo a una base de datos de destino, que puede o no haber existido anteriormente. Dependiendo de los requisitos de la aplicación, este proceso puede ser bastante simple o intrincado. Cada uno de estos pasos se puede realizar con herramientas ETL o código personalizado.
¿Qué es un pipeline ETL?
Un pipeline ETL (o pipeline de datos) es el mecanismo mediante el cual se producen los procesos ETL. Los pipelines de datos son un conjunto de herramientas y actividades para mover datos de un sistema con su método de almacenamiento y procesamiento de datos a otro sistema en el que se pueden almacenar y gestionar de forma diferente. Además, los pipelines permiten obtener información automáticamente de muchas fuentes dispares, luego transformarla y consolidarla en un almacenamiento de datos de alto rendimiento.
La guía de IA agéntica para la empresa

Desafíos con ETL
Si bien ETL es esencial, con este aumento exponencial de fuentes y tipos de datos, la creación y el mantenimiento de pipelines de datos confiables se ha convertido en una de las partes más desafiantes de la ingeniería de datos. Desde el principio, construir pipelines de datos que garanticen la confiabilidad de los datos es un proceso lento y difícil. Los pipelines de datos se construyen con código complejo y una reutilización limitada. Un pipeline diseñado en un entorno no se puede usar en otro, incluso si el código subyacente es muy similar. Esto significa que los ingenieros de datos suelen ser el cuello de botella y tienen que recrear el trabajo desde cero cada vez. Más allá del desarrollo de pipelines, gestionar la calidad de los datos en arquitecturas de pipelines cada vez más complejas resulta difícil. A menudo, se permite que los datos incorrectos fluyan a través de un pipeline sin ser detectados, lo que desvaloriza todo el conjunto de datos. Para mantener la calidad y garantizar insights confiables, los ingenieros de datos deben escribir un extenso código personalizado para implementar controles de calidad y validación en cada paso del pipeline. Finalmente, a medida que los pipelines crecen en escala y complejidad, las empresas enfrentan una mayor carga operativa al gestionarlas, lo que hace que la confiabilidad de los datos sea increíblemente difícil de mantener. La infraestructura de procesamiento de datos debe configurarse, escalarse, reiniciarse, parchearse y actualizarse, lo que se traduce en un mayor tiempo y costo. Las fallas en los pipelines son difíciles de identificar y aún más difíciles de resolver, debido a la falta de visibilidad y herramientas. A pesar de todos estos desafíos, un proceso ETL confiable es absolutamente fundamental para cualquier empresa que aspire a basar sus decisiones en datos. Sin herramientas ETL que mantengan un estándar de confiabilidad de datos, los equipos de toda la empresa deben tomar decisiones a ciegas sin métricas o informes confiables. Para continuar escalando, los ingenieros de datos necesitan herramientas para optimizar y democratizar ETL, lo que facilita el ciclo de vida de ETL y permite a los equipos de datos crear y aprovechar sus propios pipelines de datos para obtener insights más rápido.
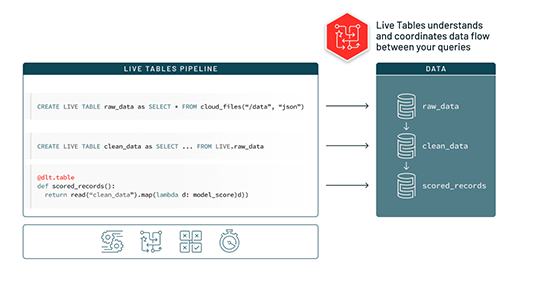
Automatizar un ETL confiable en Delta Lake
Delta Live Tables (DLT) facilita la creación y gestión de pipelines de datos confiables que proporcionan datos de alta calidad en Delta Lake. DLT ayuda a los equipos de ingeniería de datos a simplificar el desarrollo y la gestión de ETL con el desarrollo de pipelines declarativos, pruebas automáticas y visibilidad profunda para la supervisión y recuperación.
Recursos adicionales
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.