¿Qué es un conjunto de datos distribuidos resilientes (RDD)?
Comprenda la estructura de datos fundamental de Spark para el procesamiento paralelo distribuido y tolerante a fallas.
- Comprenda qué son los RDD y cómo funcionan como colecciones de datos particionadas e inmutables para el procesamiento paralelo en Apache Spark.
- Aprenda los cinco escenarios clave en los que los RDD son la mejor opción, incluyendo datos no estructurados y control de transformación de bajo nivel.
- Explore cómo se relacionan los RDD con los DataFrames y los DataSets, y cuándo usar cada API.
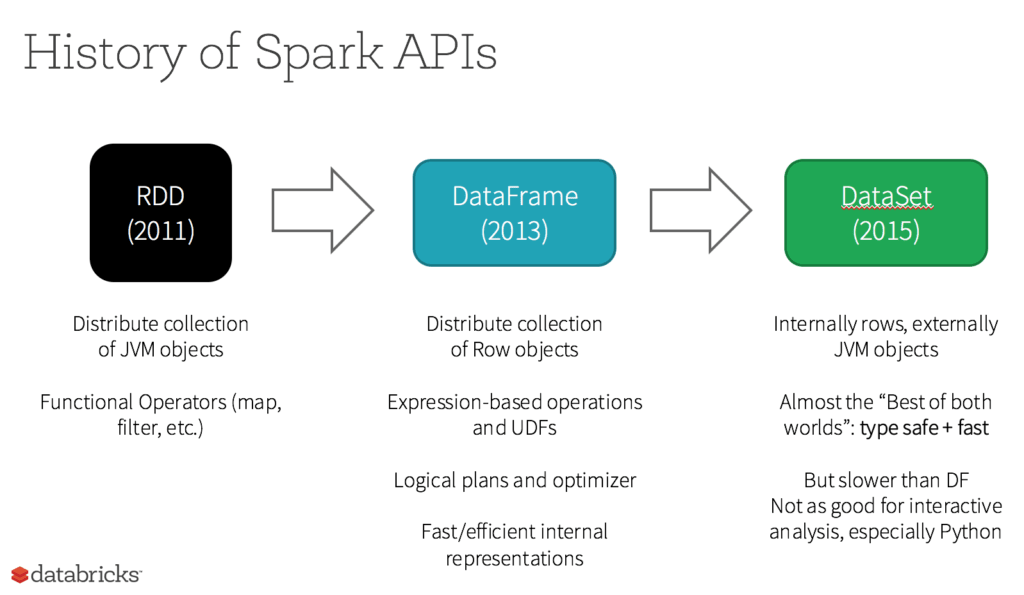
RDD fue la API principal para el usuario en Spark desde su creación. En esencia, un RDD es una colección distribuida inmutable de elementos de tus datos, particionada entre los nodos de tu clúster, que se puede operar en paralelo con una API de bajo nivel que ofrece transformaciones y acciones.
5 razones para usar RDD
- Quieres transformaciones y acciones de bajo nivel y control sobre tu conjunto de datos;
- Tus datos no están estructurados, como flujos de medios o flujos de texto;
- Quieres manipular tus datos con construcciones de programación funcional en lugar de expresiones específicas del dominio;
- No te importa imponer un esquema, como el formato columnar, al procesar o acceder a los atributos de datos por nombre o columna; y
- Puedes prescindir de algunos beneficios de optimización y rendimiento disponibles con DataFrames y Datasets para datos estructurados y semiestructurados.
La guía de IA agéntica para la empresa

¿Qué sucede con los RDD en Apache Spark 2.0?
¿Se están relegando los RDD a un segundo plano? ¿Se van a discontinuar? ¡La respuesta es un rotundo NO! Además, puedes alternar sin problemas entre DataFrame o Dataset y los RDD a tu antojo —mediante simples llamadas a métodos de la API—, y los DataFrame y Dataset están construidos sobre los RDD.
Recursos adicionales
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.