Por qué tus agentes no pueden leer documentos empresariales y cómo solucionarlo
Presentamos Document Intelligence en Databricks
- Los agentes de vanguardia todavía obtienen menos del 50% en tareas reales de documentos empresariales. El cuello de botella no es el razonamiento, es la lectura.
- El procesamiento de documentos es el techo de precisión para cada flujo de trabajo agéntico.
- Estamos anunciando Document Intelligence para cerrar esta brecha: ofreciendo precisión respaldada por investigación, escala empresarial y simplicidad de extremo a extremo.
La inteligencia de negocios más importante no solo se almacena en almacenes de datos — vive en los millones de documentos que impulsan los flujos de trabajo empresariales centrales todos los días: contratos, reclamaciones, facturas y más. Durante una década, el Procesamiento Inteligente de Documentos (IDP) se trató como un problema de automatización estrecho y de back-office. En la era de los agentes, las apuestas son fundamentalmente diferentes: el IDP es la base crítica que determina si sus agentes toman decisiones en las que realmente confiaría.
Tomemos el procesamiento de reclamaciones de seguros. En teoría, es un flujo de trabajo de agente ideal: ingerir una reclamación, extraer detalles, marcar anomalías y dirigirla. Los agentes de vanguardia de hoy manejan el razonamiento fácilmente. Donde fallan es en la lectura de los documentos: PDFs escaneados con diseños inconsistentes, tablas anidadas, notas escritas a mano y variaciones de formato entre cada proveedor. Un "$10,000" se alucina como "$3,000", el agente toma una decisión desinformada y se paga la cantidad incorrecta en silencio.
Estamos viendo este patrón en todos los ámbitos: los agentes razonan bien sobre texto limpio pero fallan cuando se enfrentan a documentos empresariales reales. Hace unos meses, Databricks AI Research lanzó OfficeQA, un benchmark basado en flujos de trabajo de documentos empresariales del mundo real. Descubrimos que incluso los agentes de vanguardia altamente capaces obtuvieron menos del 50% de precisión en tareas de razonamiento de documentos. El cuello de botella no era el razonamiento, era la lectura.
Por eso estamos emocionados de anunciar Document Intelligence, construido sobre tres pilares fundamentales: precisión respaldada por la investigación, escala empresarial y simplicidad de extremo a extremo.
En Intercontinental Exchange, procesamos millones de documentos financieros complejos y altamente variables cada mes. Document Intelligence nos ayuda a convertir esa complejidad en inteligencia de mercado estructurada, lo que nos permite movernos más rápido, ofrecer un mayor valor a nuestros clientes y desbloquear flujos de trabajo de agentes que aceleran el análisis y la toma de decisiones a escala." —Anand Pradhan, CTO y Head of AI, Mortgage Data en Intercontinental Exchange (NYSE)
Mejorando la calidad del agente en documentos empresariales del mundo real
El procesamiento de documentos es el techo de precisión para cada agente. Para hacer esto bien, el equipo de Databricks AI Research se propuso construir sistemas especializados diseñados para la realidad desordenada con la que las empresas realmente lidian: diseños inconsistentes, tablas anidadas, imágenes y escritura a mano.
Esta investigación impulsa un conjunto de Funciones de IA encadenables que dividen el procesamiento de documentos en pasos componibles: ai_parse_document (ahora disponible de forma general) convierte escaneos sin procesar en texto estructurado enriquecido con diseño, mientras que aguas abajo, ai_classify dirige los documentos correctamente, y ai_extract extrae los conocimientos estructurados clave que más importan. Juntos, forman un pipeline de inteligencia de documentos que puede ensamblar con facilidad: analizar una vez, luego clasificar, extraer y re-extraer sin reprocesar el documento original.
Entonces, ¿el mejor procesamiento de documentos realmente hace que los agentes sean más precisos? Cuando comparamos documentos de bonos del tesoro del mundo real a través de OfficeQA, el preprocesamiento con ai_parse_document entregó una ganancia de rendimiento promedio del 16% en todos los frameworks de agentes que probamos. El arnés de razonamiento del agente no cambió en absoluto, pero la capa de datos del documento debajo de él sí.
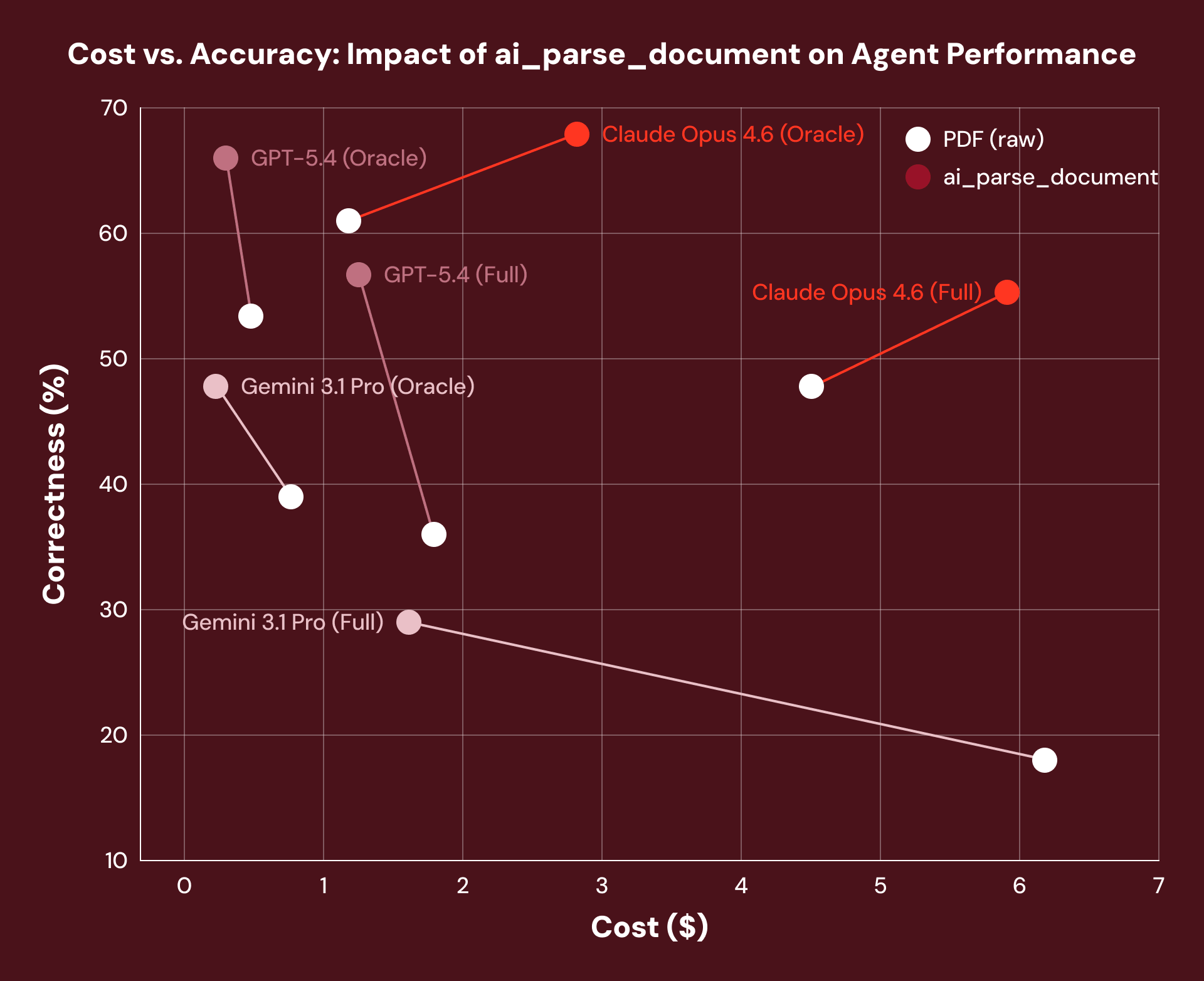
Nota: Observamos un aumento en los costos de Claude Opus 4.6 debido a la tendencia del modelo a recuperar más tokens cuando se le proporcionaba el texto de diseño estructurado de un documento.
Es exactamente por eso que construimos Document Intelligence como la base de sus flujos de trabajo de agentes: las ganancias de calidad y costo del procesamiento de documentos se acumulan a través de todo lo que se construye sobre él.
Con Document Intelligence, estamos sentando las bases para un pipeline de procesamiento inteligente de documentos que desbloquea información estructurada clave de millones de PDFs técnicos no estructurados cada año, obtenidos de miles de organizaciones y que abarcan formatos altamente inconsistentes. —Graham Lammers, Director Ejecutivo de Inteligencia de Datos, Accuris
Desbloqueando la inteligencia de documentos a escala empresarial
Incluso cuando se resuelve la calidad, el cementerio de IDP empresarial está lleno de proyectos que clavaron el piloto pero no pudieron sobrevivir a la economía de producción. Esto se debe a costos que se disparan a seis cifras y trabajos por lotes que tardan días en lugar de horas.
Diseñamos Document Intelligence para la economía de producción a escala desde el principio, no como una ocurrencia tardía. Debido a que las Funciones de IA como ai_parse_document están especializadas en investigación, logran una precisión de vanguardia sin la sobrecarga computacional de los modelos de propósito general.
En varias soluciones, comparamos la precisión y el costo en tareas de extracción de documentos estructurados que identifican entidades clave de facturas empresariales, contratos, notas médicas y presentaciones financieras. Document Intelligence logró consistentemente la mayor precisión a un costo 5-7 veces menor que los pipelines comparables.

Nota: Las ofertas marcadas (analizar + extraer) utilizan una arquitectura de pipeline de dos pasos: analizar una vez en una capa plateada reutilizable, luego extraer y re-extraer sin volver a analizar. Las ofertas basadas en VLM reprocesan el documento completo en cada llamada de extracción.
Es importante destacar que, para el procesamiento a escala, cada Función de IA se ejecuta en una infraestructura de batch sin servidor construida para cargas de trabajo de alto volumen: la misma llamada SQL de una línea que procesa 100 facturas procesa 100,000 sin rediseñar su pipeline.
Con Document Intelligence, logramos la misma extracción de entidades de alta calidad a casi un 90% menos de costo en semanas. Esa ventaja de precio-rendimiento ahora impulsa nuestros pipelines de producción, lo que nos permite expandirnos a nuevas áreas de enfermedades más rápido, procesar cientos de millones de notas clínicas de manera eficiente y ofrecer información a nuestros clientes a escala. —Jerry Dennany, CTO Loopback Analytics
Es importante destacar que, para el procesamiento a escala, cada Función de IA se ejecuta en una infraestructura de batch sin servidor construida para cargas de trabajo de alto volumen: la misma llamada SQL de una línea que procesa 100 facturas procesa 100,000 sin rediseñar su pipeline.
De pipelines fragmentados a un flujo de trabajo unificado
Para la mayoría de las empresas hoy en día, la inteligencia de documentos no es una capacidad de plataforma. Es una colección de pipelines únicos. Para un solo caso de uso, un equipo une un servicio de OCR, conecta una API de extracción distinta e integra un modelo de clasificación de otro proveedor. En poco tiempo, están administrando de tres a cinco API desconectadas unidas por código personalizado frágil — un pipeline que es quebradizo, costoso de mantener y casi imposible de depurar cuando falla a las 3 AM. Y cuando otro equipo necesita procesar un tipo de documento diferente, no hay nada reutilizable en lo que basarse. Empiezan desde cero.
Este es el ciclo que mantiene la inteligencia de documentos atrapada como una serie de proyectos únicos en lugar de una capacidad en toda la empresa. Document Intelligence rompe ese ciclo. En lugar de unir servicios desconectados, cada paso se ejecuta de forma nativa dentro de su capa de orquestación y gobernanza de Databricks existente:
- Ingesta de documentos (por ejemplo, desde SharePoint) usando Lakeflow Connect.
- Orquesta el pipeline completo usando Lakeflow Jobs o Spark Declarative Pipelines, con manejo de errores integrado, observabilidad y manejo automático de nuevos documentos.
- Gobierna el linaje, la seguridad y los controles de acceso de extremo a extremo de sus pipelines y datos — desde el documento sin procesar hasta la salida de tabla estructurada — con Unity Catalog.
- Construye agentes sobre la nueva y enriquecida capa de datos de documentos utilizando la plataforma Agent Bricks.
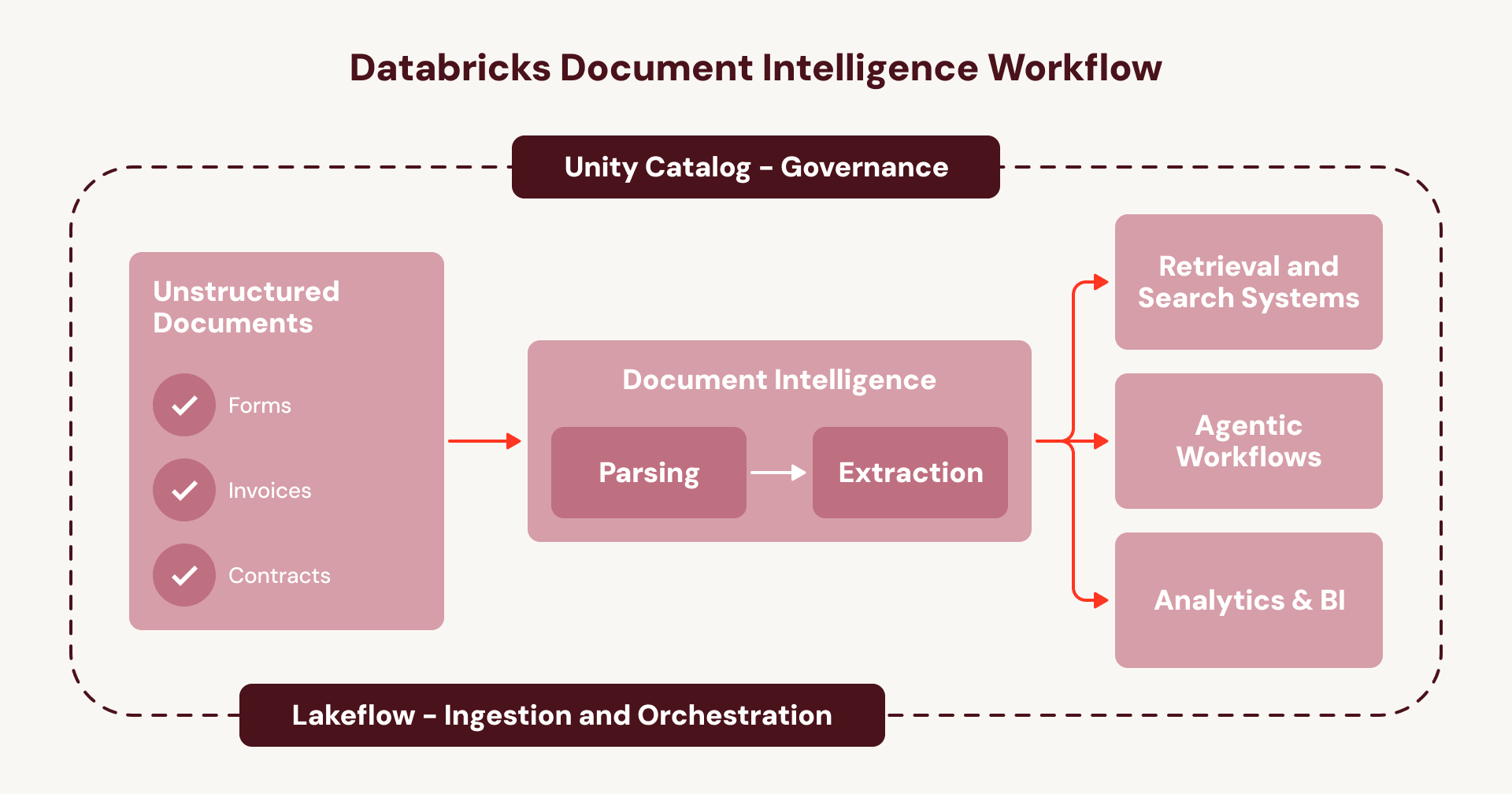
Para las empresas, esto significa que la inteligencia de documentos se ejecuta en un flujo de trabajo unificado y gobernado en lugar de una red de servicios opacos y fragmentados — un playbook repetible para escalar casos de uso de agentes en todos sus documentos.
Con Databricks, hemos pasado de procesos manuales y fragmentados a inteligencia automatizada y escalable. Lo que antes tomaba semanas, ahora lo hacemos en días, desbloqueando información que nuestros clientes no pueden obtener en ningún otro lugar. —Tony Qui, EY-Parthenon Global Innovation Leader, Strategy and Transactions
Tus agentes solo son tan buenos como tu capa de procesamiento de documentos
La promesa de los agentes empresariales descansa en una pregunta que la mayoría de las organizaciones aún no han respondido: ¿pueden tus agentes entender realmente los millones de documentos de tu negocio?
Por eso, nos complace anunciar Document Intelligence para cerrar esa brecha: lo suficientemente preciso para flujos de trabajo críticos para el negocio, gobernado de extremo a extremo para que tu equipo de cumplimiento no persiga datos entre proveedores, y construido para escalar desde tu primer piloto hasta la producción sin cambiar una línea de código.
Tus documentos son la fuente más rica de inteligencia en tu empresa. Es hora de que tus agentes puedan leerlos.
- Lee nuestro blog de cómo hacerlo sobre cómo crear con Document Intelligence y Lakeflow.
- Regístrate para la Prueba de Databricks.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.