Creación con Databricks Document Intelligence y Lakeflow
Convierta el conocimiento empresarial bloqueado en inteligencia consultable y confiable
- La mayor parte del conocimiento empresarial es inaccesible en documentos no estructurados, mientras que el procesamiento inteligente de documentos (IDP) actual suele ser frágil y poco fiable
- Databricks Document Intelligence y Lakeflow permiten a los ingenieros de datos crear y automatizar fácilmente un flujo de trabajo de IDP de extremo a extremo: ingiriendo datos no estructurados, analizándolos con inteligencia artificial basada en el contexto empresarial y luego orquestando a escala, todo dentro de una plataforma gobernada
- Los equipos de datos pueden exponer documentos previamente ocultos en conjuntos de datos confiables y consultables que ayudan a desbloquear nuevas perspectivas, flujos de trabajo agnósticos y valor para su negocio
A pesar de décadas perfeccionando pipelines de datos estructurados, el 80% del conocimiento empresarial permanece funcionalmente invisible, atrapado en PDFs, imágenes y documentos de oficina.
Tradicionalmente, el Procesamiento Inteligente de Documentos (IDP) ha sido una pesadilla fragmentada. Antes de la era de la IA Generativa, las organizaciones se vieron obligadas a depender de APIs desconectadas de NLP y visión por computadora que estaban fuera de sus plataformas de datos principales. Estos proveedores de OCR (reconocimiento óptico de caracteres) aislados ofrecían precisión limitada y carecían de protocolos formales de gobernanza, creando una fricción significativa. Para cumplir la promesa de la IA Empresarial, necesitamos un enfoque unificado que integre la inteligencia de datos directamente en el ciclo de vida de los datos.
Hoy, mostramos cómo los ingenieros de datos pueden aprovechar Lakeflow, la solución unificada de ingeniería de datos de Databricks, y Databricks Document Intelligence para desbloquear esos datos y convertirlos en inteligencia que impacta al negocio mediante la creación de IDP autónomos de calidad de producción en su Plataforma Databricks.

Paso 1: Ingesta segura con Lakeflow Connect
Los documentos empresariales viven en cementerios aislados, accesibles solo a través de integraciones de API frágiles y codificadas a medida que se rompen en el momento en que se renombra una carpeta. Lakeflow Connect, la solución de Databricks para ingerir datos en el lakehouse, cambia las reglas del juego con conectores integrados para muchas aplicaciones empresariales populares, bases de datos y fuentes de archivos, incluyendo SharePoint y Google Drive.
Esta solución ofrece ingesta sin mantenimiento al eliminar la necesidad de gestionar flujos OAuth complejos o scripts de Python personalizados. Los documentos aterrizan directamente en Unity Catalog Volumes y tablas, por lo que el control de acceso, el linaje y la auditoría se aplican tan pronto como el archivo está en el lakehouse, y puede reutilizar las mismas políticas basadas en atributos y de grano fino en las que ya confía para datos estructurados.
También obtiene una ingesta rápida y eficiente a escala gracias a las capacidades robustas de Lakeflow Connect, incluyendo lecturas y escrituras incrementales que evitan la repetición completa de grandes bibliotecas tanto para rellenos de lotes como para flujos de documentos casi en tiempo real cuando se combinan con streaming downstream.
Paso 2: Primeros pasos con Databricks Document Intelligence
Estos documentos empresariales contienen algunas de las perspectivas más valiosas de su organización, pero son inherentemente desordenados, variables e inconsistentes. Las páginas escaneadas, las notas escritas a mano y las tablas anidadas atrapan sus perspectivas más valiosas. Para solucionar esto, no solo necesita otra herramienta de extracción de documentos; como señala Forrester, necesita una “evolución arquitectónica que priorice el razonamiento”. Con este enfoque, Gartner predice que GenAI reducirá la necesidad de modelos de documentos entrenados a medida en un 70%.
Hoy, con Databricks Document Intelligence, puede llevar la comprensión de documentos de última generación directamente a sus datos. Sus equipos de ingeniería de datos pueden aprovechar funciones de IA diseñadas específicamente que pueden analizar, estructurar y enriquecer de manera confiable documentos complejos junto con sus pipelines de datos existentes, todo gobernado sin problemas por Unity Catalog.
- ai_parse_document (nuevo - GA): Esta función convierte archivos no estructurados en representaciones estructuradas utilizando el tipo de datos Variant. Maneja de forma nativa la complejidad de entrada que normalmente confunde a los analizadores tradicionales, como imágenes escaneadas, escritura a mano y diseños variables, al tiempo que preserva la estructura crítica del documento (por ejemplo, tablas anidadas, secciones y encabezados) que la extracción de texto plano perdería. Esto le permite evolucionar esquemas con el tiempo sin romper sus pipelines. Aguas abajo, trata la salida VARIANT como una representación flexible de bronce/plata, proyectándola en columnas Delta en sus capas de plata/oro utilizando SQL o PySpark en Lakeflow Spark Declarative Pipelines.
Además de la estructura analizada, puede encadenar Funciones de IA adicionales ajustadas para la investigación:
- ai_extract (PuPr) para extraer información estructurada como fechas de entrada y vencimiento de contratos, contrapartes, totales de facturas, impuestos, moneda y números de PO.
- ai_classify (PuPr) para enrutar documentos por tipo (factura, PO, SOW, NDA), urgencia/riesgo o unidad de negocio propietaria.
- ai_prep_search (nuevo - Beta) para dividir inteligentemente los documentos en fragmentos para una incrustación de alta calidad downstream, preparándolos para casos de uso de recuperación o búsqueda
A continuación, se muestra un ejemplo sencillo de encadenamiento de ai_parse_document y ai_extract.
Nota: este ejemplo muestra PySpark, pero también puede usar SQL (consulte la documentación).
Dado que estas son Funciones de IA administradas integradas en la Plataforma Databricks, Document Intelligence puede combinarlas con su contexto empresarial (metadatos del catálogo, semántica empresarial, tablas existentes) para potenciar flujos de trabajo de agentes que razonan sobre sus datos con alta precisión, basados en el contexto de su dominio empresarial.
Paso 3: Producción de cargas de trabajo de IDP a escala
Una vez que tenga la ingesta y el análisis funcionando en los notebooks, necesita producir su IDP: orquestar la ingesta, el análisis, el enriquecimiento y el servicio. Pero también desea monitorear SLAs, fallos y reintentos en CI/CD para garantizar que los pipelines permanezcan saludables.
Con Lakeflow Jobs, el orquestador nativo de Databricks, puede convertir las cargas de trabajo de IDP en pipelines robustos y automatizados con el mismo sistema de orquestación que utiliza para ETL, análisis y ML. Proporciona orquestación unificada para cada tarea en el DAG de IDP, por lo que puede encadenar notebooks, scripts de Python, consultas SQL, pipelines, LLMs o llamadas a agentes en un solo trabajo y modelar el flujo completo desde la ingesta de documentos.
Lakeflow Jobs también viene con flujo de control avanzado incorporado (incluyendo condiciones if/else, for each, reintentos, etc.) y disparadores (actualización de tabla, llegada de archivo, continuo, etc.). Esto facilita 1) reprocesar solo particiones fallidas o lotes de documentos específicos y 2) administrar trabajos para que se ajusten a horarios específicos, disparadores basados en eventos o modo continuo para flujos de documentos en tiempo real.
Con la computación sin servidor de Lakeflow Jobs con observabilidad nativa, también obtiene escalado automático con picos en el volumen de documentos mientras muestra monitoreo en tiempo real, métricas y alertas para que pueda identificar cuellos de botella y reparar fallos sin necesidad de volver a ejecutar tareas exitosas.
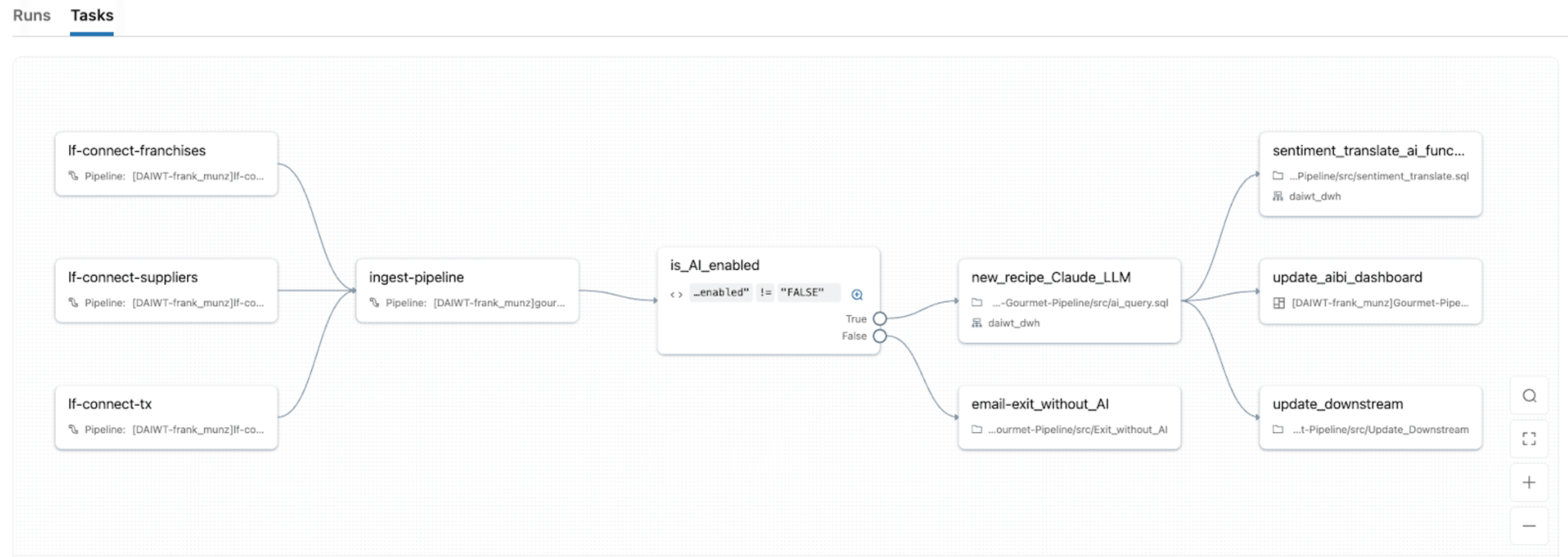
Fundamentando la IA en el contexto empresarial
IDP es más valioso cuando está respaldado por el contexto empresarial: sus esquemas únicos, definiciones de negocio y semántica personalizada.
Unity Catalog
Unity Catalog proporciona gobernanza y descubrimiento unificados en datos estructurados, archivos no estructurados, modelos de ML y métricas de negocio en cualquier nube. Para IDP, eso significa:
- Un único lugar para definir políticas de acceso, linaje y auditoría tanto para documentos sin procesar como para tablas estructuradas derivadas
- Compatibilidad con formatos abiertos (Delta, Apache Iceberg, Hudi, Parquet) para que no quede atrapado en una representación de documentos propietaria
- Semántica de negocio y metadatos a nivel de catálogo que los agentes pueden usar para nombrar e interpretar de manera consistente entidades como "Proveedor", "Cliente" o "Valor del Contrato".
Inteligencia de Documentos
Inteligencia de Documentos utiliza este contexto para crear agentes de IA de producción que saben qué tablas, herramientas y modelos usar para una tarea de IDP dada, están gobernados de extremo a extremo para que nunca accedan a más de lo que deberían, y mejoran continuamente a través de puntuación de calidad basada en LLM, benchmarks específicos de tareas y bucles de aprendizaje. Para los desarrolladores, Databricks proporciona APIs y SDKs para que puedan definir estos agentes como código e integrarlos en sus pipelines de CI/CD existentes, al igual que cualquier otro activo de datos o ML.
Mejores Prácticas para el Stack Moderno de IDP
Para pasar de piloto a plataforma, tenga en cuenta estas mejores prácticas:
- Enriquecimiento de Datos: No se limite a extraer un "Nombre de Proveedor". Únase a sus datos maestros internos o fuentes de terceros (como Dun & Bradstreet) para proporcionar un contexto de negocio completo.
- Excelencia Operativa: Utilice Service Principals para trabajos de Lakeflow para garantizar la estabilidad del pipeline.
- Monitorización: Utilice Lakehouse Monitoring para rastrear la deriva del modelo y la precisión de la extracción a lo largo del tiempo.
El Camino hacia la Inteligencia de Datos Moderna
Con Databricks, puede poseer el ciclo de vida completo del Procesamiento Inteligente de Documentos en una plataforma de datos moderna. La combinación de Lakeflow y funciones de IA le permite convertir datos no estructurados y ocultos en conjuntos de datos confiables y consultables y ejecutar sin problemas pipelines de documentos observables junto con su ETL y ML principal.
Ahora que hemos cubierto el valor estratégico de la inteligencia de documentos autónoma, es hora de construirla. Consulte nuestra publicación complementaria, De PDF a Insights, para obtener una guía técnica paso a paso sobre la implementación de esta arquitectura exacta utilizando Databricks.
También puede explorar la documentación de Inteligencia de Documentos y Lakeflow para comenzar a construir su primer pipeline de IDP hoy mismo.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.