Conecta cualquier fuente de datos en una sola plataforma
Enriquezca sus agentes de IA con un contexto empresarial completo.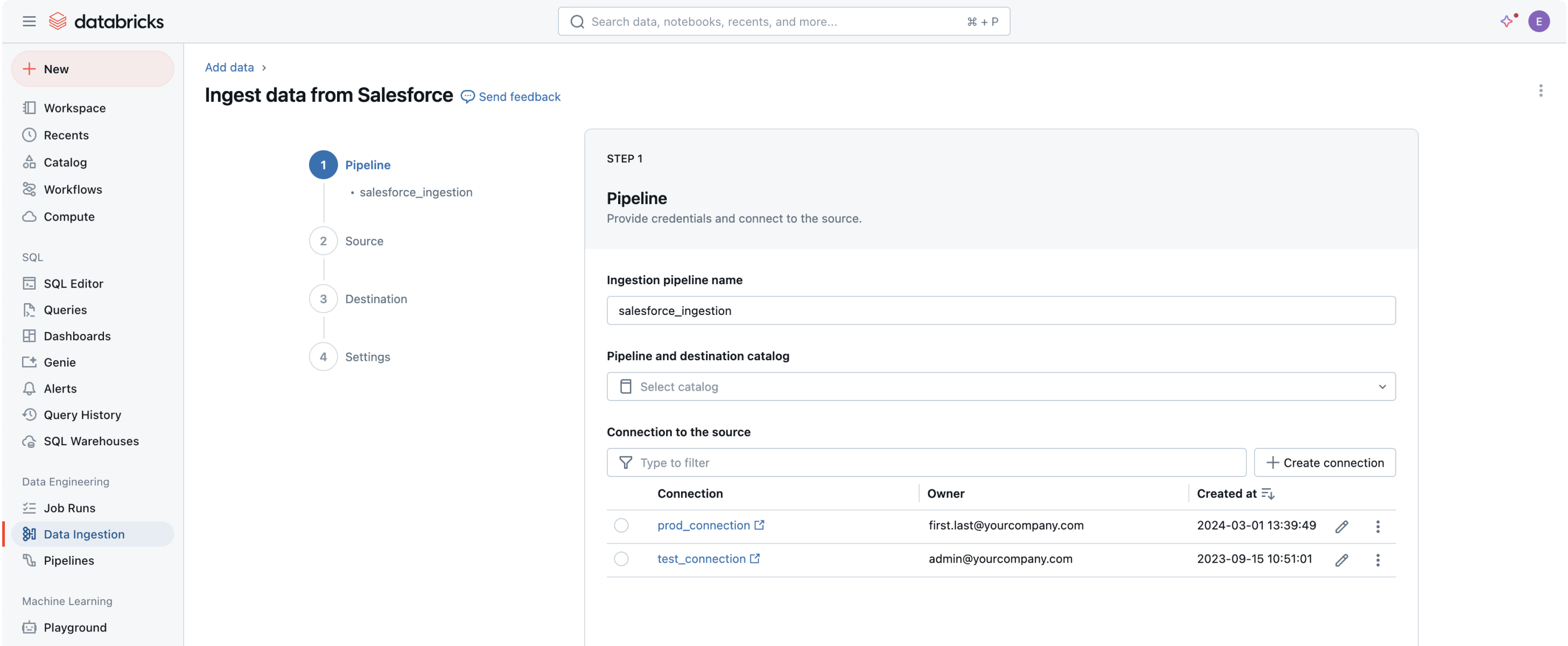

Conecta cualquier fuente de datos en una sola plataforma
Más de 100 conectores integrados para aplicaciones empresariales, bases de datos y fuentes de archivos les brindan a tus agentes de IA un contexto completo y confiable.Flexible y fácil
Los conectores totalmente gestionados proporcionan una IU y una API sencillas para facilitar la configuración y democratizar el acceso a los datos. Las funciones automatizadas también ayudan a simplificar el mantenimiento de los pipelines con una sobrecarga mínima.
Conectores integrados
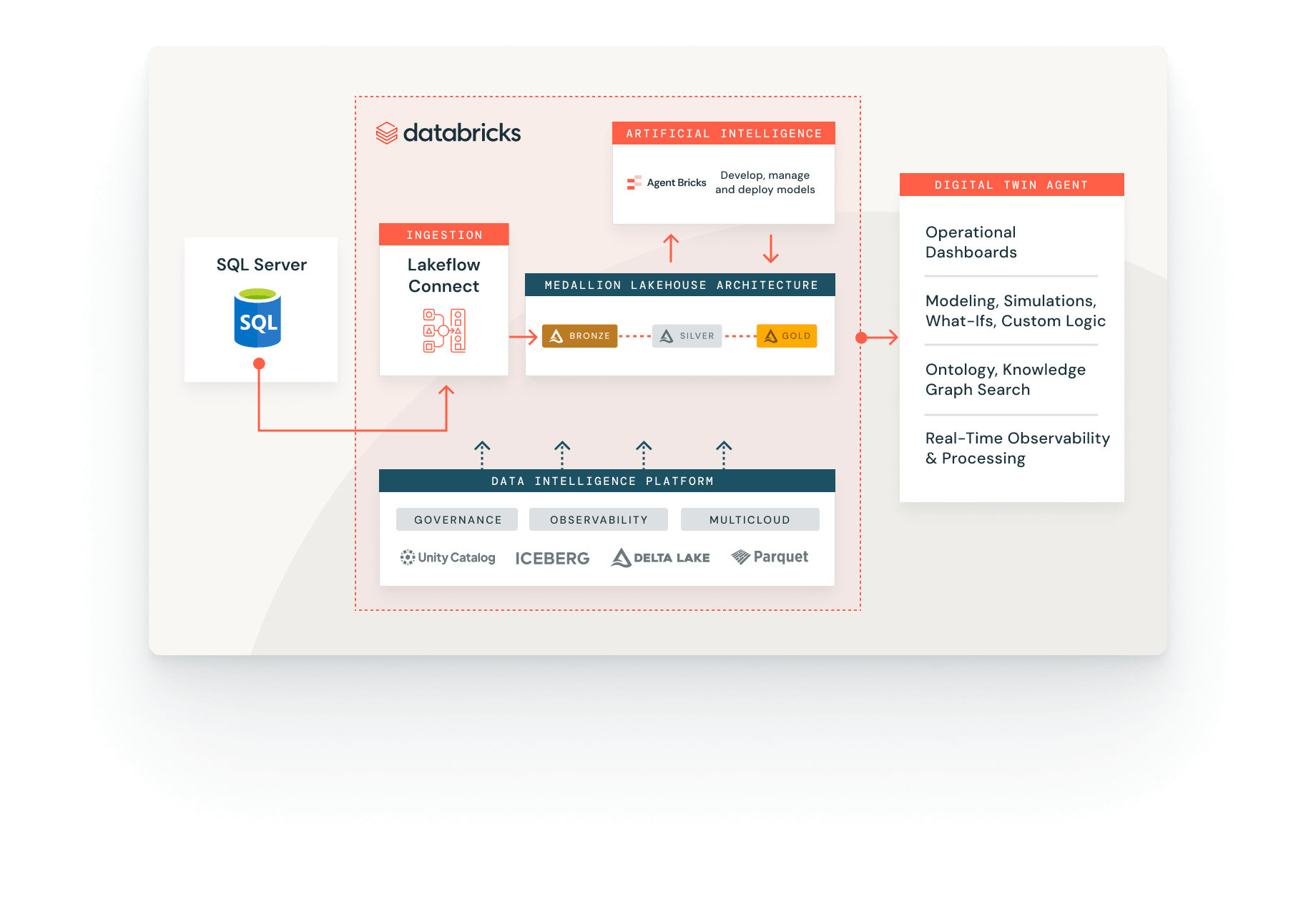
La ingesta de datos está completamente integrada con la plataforma de inteligencia de datos. Crea pipelines de ingesta con gobernanza usando Unity Catalog, observabilidad con Lakehouse Monitoring y orquestación perfecta con flujos de trabajo para analítica, aprendizaje automático y BI.
Integración directa con agentes de IA
Alimenta tus procesos posteriores de IA y BI con contexto empresarial de alta fidelidad. Elimine los silos y alimente a sus agentes de IA con una lógica de negocio completa para un razonamiento confiable.
Capacidades robustas de ingesta para fuentes de datos populares
El primer paso para extraer valor y ayudar a resolver los problemas de datos más complejos de tu organización es incorporar todos tus datos a la plataforma de inteligencia de datos.La interfaz de usuario (IU) sin código o una API simple les da a los profesionales de datos la capacidad de autoservicio, lo que ahorra horas de programación.
Solo trae datos nuevos o actualizaciones de tablas, lo que hace que la ingesta de datos sea rápida, escalable y eficiente en términos operativos.

Ingesta de datos en un entorno 100 % sin servidor que proporciona un arranque rápido y un escalado automático de la infraestructura.

La integración profunda con Databricks Unity Catalog ofrece capacidades robustas, que incluyen linaje y calidad de datos.

Ingesta de datos con Databricks
Resolver los problemas de los clientes en una variedad de industrias

Mide el rendimiento de la campaña y mapea el recorrido del cliente
Consolida los datos fragmentados de anuncios y campañas de Meta, Google Ads y TikTok Ads. Captura los estados históricos de la plataforma para realizar análisis precisos en un momento determinado y crear un recorrido del cliente unificado.





Los precios basados en el uso mantienen el gasto bajo control
Paga solo por los productos que usas, con granularidad por segundo.Descubre más
Explora otras ofertas integradas e inteligentes en la plataforma de inteligencia de datos.
Trabajos de Lakeflow
Dota a tus equipos de herramientas para automatizar y orquestar mejor cualquier flujo de trabajo de ETL, análisis e IA con una profunda observabilidad, alta confiabilidad y amplio soporte de tipos de tareas.
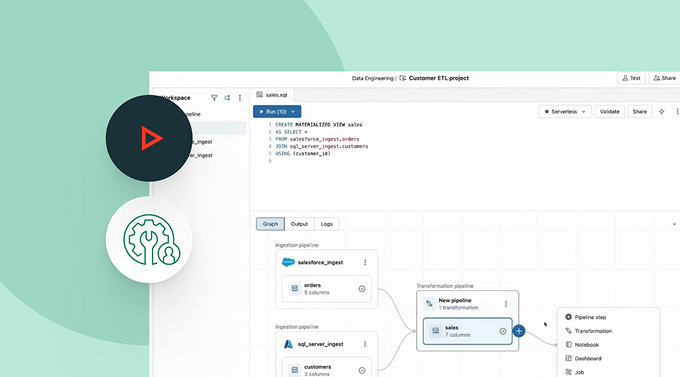
Pipelines declarativos de Apache Spark™
Simplifica el ETL por lotes y de transmisión con calidad de datos automatizada, captura de datos modificados (CDC), ingesta de datos, transformación y gobernanza unificada.

Unity Catalog
Controla sin problemas todos tus activos de datos con la única solución de gobernanza abierta y unificada de la industria para datos e IA, integrada en la plataforma de inteligencia de datos de Databricks.

Delta Lake
Unifica los datos en tu lakehouse, en todos los formatos y tipos, para todas tus cargas de trabajo de analítica e IA.

Genie Code
Cree y mantenga flujos de datos con IA automatizada que comprenda sus datos.
Comenzar
Explorar la documentación sobre la ingesta de datos
Ingiere datos de diferentes fuentes, a través de las nubes y mediante Lakeflow Connect.
Tour de Lakeflow Connect
Lakeflow Connect ya está disponible de forma general para Salesforce, Workday y SQL Server.
Para obtener acceso en versión preliminar a otros conectores, ponte en contacto con tu equipo de cuenta de Databricks.
Contenido relacionado



Preguntas frecuentes sobre la ingesta de datos
¿Estás listo para convertirte en una empresa de datos e IA?
Da los primeros pasos en tu transformación de datos