iFood, una plataforma líder en reparto de comida en Brasil, opera a una escala asombrosa: 300 000 conductores, 55 millones de usuarios y 350 000 socios de restaurantes. Este ecosistema genera diariamente un inmenso volumen de datos en transmisión, que abarca los pedidos de los clientes, la logística de entrega y las interacciones con las aplicaciones. Con una amplia gama de productos y plataformas que recopilan datos en toda la empresa, iFood procesa miles de millones de registros de datos diariamente para su análisis y modelado con el fin de respaldar las decisiones estratégicas empresariales. Con la ambición de expandir y mejorar sus ofertas, iFood necesitaba una plataforma de datos más confiable, escalable y eficiente para satisfacer la creciente demanda de información e innovación en tiempo real.
Los silos de datos y la arquitectura compleja obstaculizaban la agilidad y la precisión
Antes de Databricks, iFood lidiaba con una arquitectura de datos fragmentada que dificultaba su capacidad de escalar eficazmente. La empresa dependía de una infraestructura compleja con múltiples sistemas para gestionar grandes cantidades de datos sobre los viajes de los usuarios, que comprendían miles de millones de registros procedentes de diversas fuentes, entre ellas el sistema de gestión de pedidos de la empresa, la aplicación para consumidores y la aplicación para conductores. A medida que el ecosistema crecía y surgían nuevos modelos de negocio, el volumen y la variedad de datos también aumentaban, lo que complicaba aún más el procesamiento de datos. Con estos conjuntos de datos distribuidos en sistemas dispares, consolidar y acceder a la información crítica de manera rápida y confiable se convirtió en un desafío considerable.
Esta fragmentación provocó ineficiencias operativas importantes, ya que los equipos de iFood tenían dificultades para realizar un seguimiento de los datos dispersos de los eventos. Con los datos distribuidos en varios sistemas y sin un control adecuado, la resolución de problemas y la garantía de la precisión de los datos se convirtieron en un proceso lento y propenso a errores. El equipo de ingeniería de datos de iFood enfrentó desafíos inmensos, como el importante esfuerzo de ingeniería para codificar manualmente, optimizar y mantener flujos de trabajo complejos para el procesamiento de datos. El equipo de ingeniería de datos de la empresa dedicaba anteriormente muchas horas a solucionar errores y coordinar con varios equipos para implementar incluso los cambios más pequeños.
Esta constante lucha contra incendios agotaba los recursos, dificultaba la innovación y dejaba a los ingenieros con poco tiempo para los trabajos estratégicos. La situación se complicó aún más por el crecimiento explosivo de los datos de iFood. Lo que antes era una arquitectura heredada capaz de gestionar 100 millones de eventos diarios ahora se veía superada por un aumento de entre 8000 a 10 000 millones de eventos diarios. A medida que la empresa comenzó a entrenar modelos en tiempo real para analizar los recorridos de los usuarios de las aplicaciones y obtener información útil, la baja latencia a gran escala se convirtió en un requisito fundamental.
Optimización de las canalizaciones, reducción del mantenimiento y obtención de información en tiempo real
Los pipelines declarativos de Spark resultaron ser un cambio radical para iFood. Los pipelines declarativos de Spark permitieron a iFood cambiarse a un enfoque declarativo para el desarrollo de pipelines. Los ingenieros podían describir las transformaciones deseadas en código sencillo, lo que les permite a los pipelines declarativos de Spark gestionar automáticamente la complejidad operativa detrás de estos pipelines, como la ejecución, el escalado y el monitoreo. “Hasta ahora hemos reducido el tiempo de codificación en aproximadamente un 30 % gracias al enfoque declarativo, lo que nos permite construir pipelines con mucha más rapidez que antes”, dijo Thiago Julião, especialista en arquitectura de datos en iFood. Esta transición también simplificó y consolidó la arquitectura de datos de iFood, lo que redujo la cantidad de tablas de casi 4000 a solo 100. Esta reducción también hizo que la gobernanza fuera más manejable y sentó las bases para mejorar la calidad de los datos.
Antes de los pipelines declarativos de Spark, los pipelines de iFood se veían obstaculizados por errores de falta de memoria durante las ingestas de eventos de gran volumen, lo que conducía a frecuentes apagones de controladores e interrupciones operativas. Estas fallas recurrentes requerían una atención constante por parte del equipo de ingeniería de datos. Sin embargo, desde que se implementaron los pipelines declarativos de Spark en la producción, la transformación fue notable.
"Con los pipelines declarativos de Spark, logramos una mayor facilidad para rastrear el recorrido del usuario en la aplicación, mientras aseguramos un alto rendimiento en el uso de datos por parte de los equipos de consumidores. Esto marcó un cambio revolucionario en nuestro proceso", afirmó Maristela Albuquerque, directora de datos en iFood.
Arquitectura unificada de datos de iFood
La arquitectura técnica de iFood ahora está diseñada para procesar datos de transmisión a una escala inmensa, lo que garantiza la eficiencia, gobernanza y escalabilidad. A continuación, se ofrece un desglose detallado de la arquitectura y de cómo sus componentes funcionan conjuntamente para gestionar 10 000 millones de eventos diarios y proporcionar información en tiempo real.
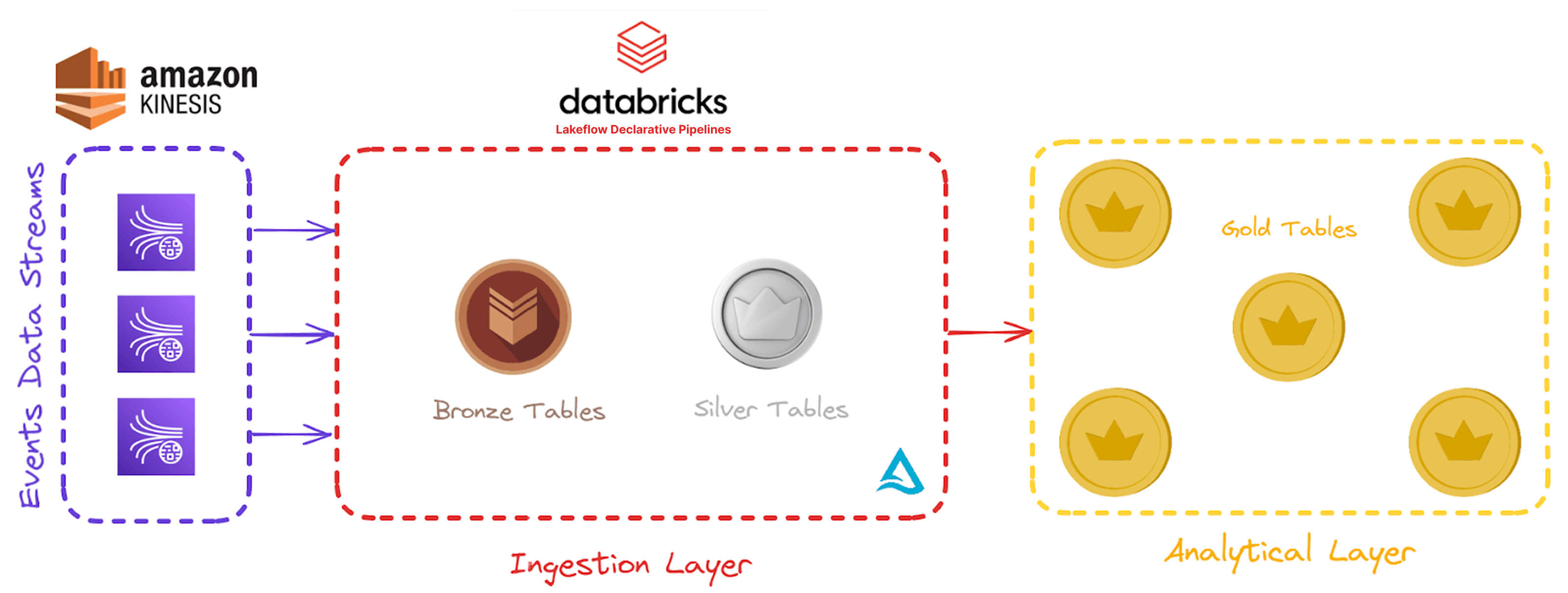
La cadena de datos comienza con la ingesta en tiempo real de eventos del ecosistema de iFood, como la aplicación para consumidores, la de repartidores y el portal de socios. Estos eventos fluyen a través de las colas de Amazon Kinesis, donde se ingieren aproximadamente 10 000 millones de registros diariamente.
La tubería de ingestión, impulsada por pipelines declarativos de Spark, permite la ingesta de datos en tiempo real con escalabilidad, resiliencia y calidad. Al adoptar pipelines declarativos de Spark, iFood redujo la latencia de ingestión de horas a segundos, lo que aseguró una disponibilidad de datos de baja latencia crítica para los análisis en tiempo real, como modelos de entrenamiento y extracción de información durante el recorrido del usuario sin demoras. “Los pipelines ahora funcionan sin errores y ofrecen un rendimiento confiable incluso con las cargas de trabajo más pesadas”, afirmó Julião. "El cambio de errores frecuentes a problemas casi nulos al pasar a pipelines declarativos de Spark no solo ha mejorado la eficiencia operativa, sino que también ha liberado a nuestro equipo para centrarse en iniciativas estratégicas en lugar de apagar incendios. Hemos reducido los esfuerzos de mantenimiento de los pipelines de datos en aproximadamente un 70 % al consolidar todos los pipelines a los pipelines declarativos de Spark."
La arquitectura de iFood aprovecha un enfoque estructurado de medallón para gestionar enormes volúmenes de datos. La capa de bronce consolida los datos de varias plataformas en una sola tabla por producto mediante un esquema predefinido dividido según la fecha de procesamiento. Al actuar como zona de preparación, garantiza una retención de datos extendida en comparación con las colas de mensajes.
En la capa de plata, iFood aplica las expectativas y reglas de calidad de los pipelines declarativos de Spark para validar los datos. Al reemplazar la partición tradicional por Liquid Clustering, todos los eventos de un producto se consolidan en una única tabla, lo que mejora significativamente el rendimiento y la usabilidad. Esta optimización permite a iFood administrar conjuntos de datos masivos, como su tabla más grande, que abarca 210 TB y 800 mil millones de registros, mientras mantiene una alta calidad de datos y control. “Anteriormente, la administración de dos entornos separados requería una comunicación constante entre los equipos, lo que hacía que incluso los pequeños cambios sean desafiantes. Ahora, con todo bajo nuestro control, el proceso se ha optimizado y es más eficiente", afirma Gabriel Campos, director de datos e inteligencia artificial de iFood.
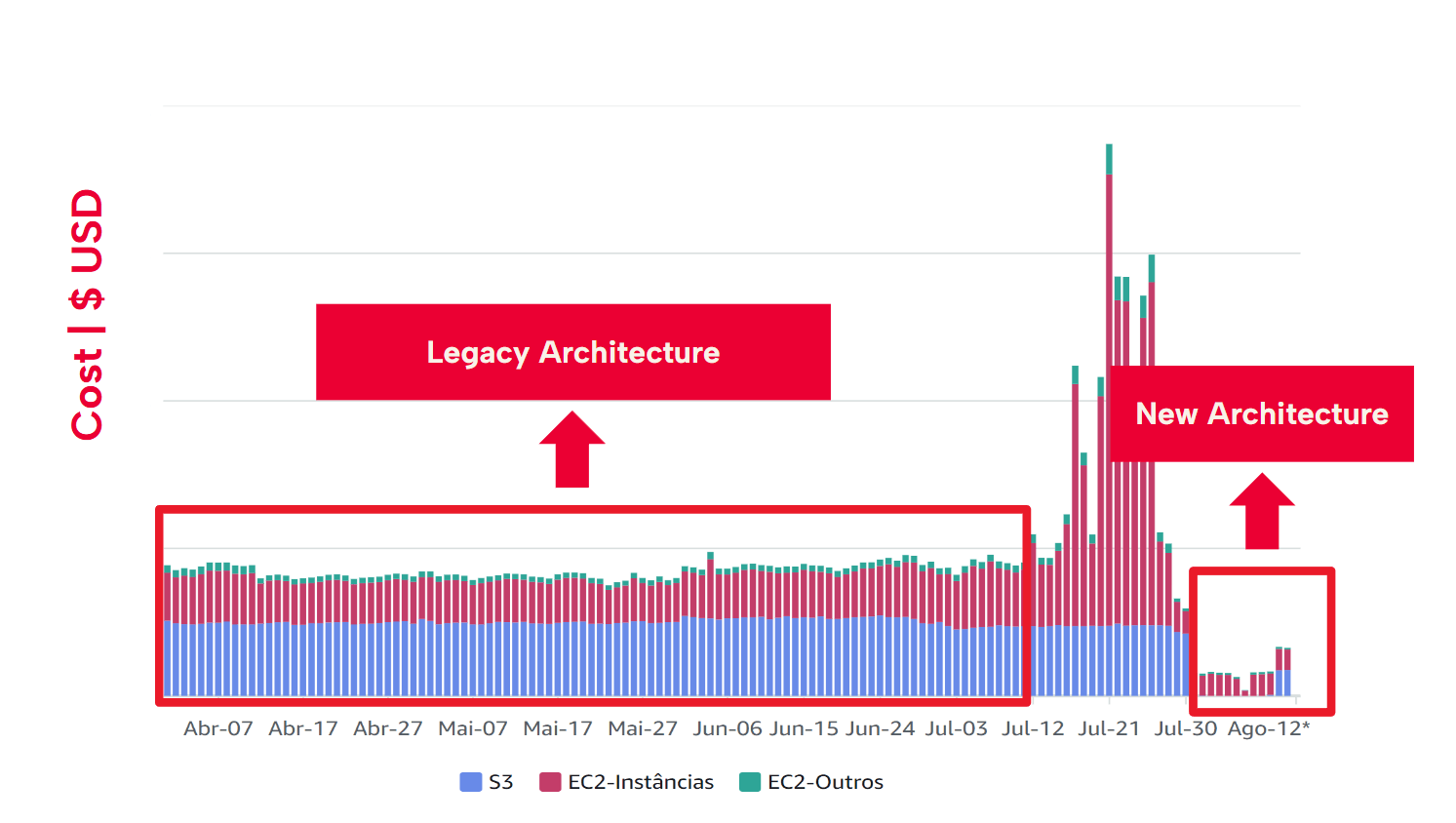
La nueva arquitectura ha permitido a iFood centralizar la gestión de datos y mejorar su calidad sin comprometer el rendimiento ni la usabilidad. Además, ha reducido significativamente los costos de procesamiento y almacenamiento. Logró una reducción de costos del 67 %, lo que ha permitido reducir los gastos de cientos de miles a solo miles de dólares al mes.
Gracias a la automatización y optimización de la gestión de los flujos de datos que ofrece Spark Declarative Pipelines, los analistas de negocios de los equipos de crecimiento y productos de iFood ahora pueden acceder fácilmente a los datos de la capa Silver para crear tablas analíticas Gold, lo que les permite generar con facilidad información clave para el negocio. Esto permite analizar el recorrido del usuario y realizar pruebas A/B sobre el comportamiento de los consumidores en las distintas etapas de su recorrido, lo que facilita la creación de estrategias basadas en datos para mejorar la experiencia del cliente en todo el ecosistema de iFood. Por ejemplo, la aplicación para conductores proporciona información fundamental al equipo de logística, lo que les ayuda a comprender cómo interactúan los conductores con la aplicación y a optimizar su usabilidad. Estos conocimientos permiten a iFood afinar tanto los procesos orientados al consumidor como los operativos, asegurando una experiencia fluida para los clientes y eficiencia para los conductores.
iFood planea mejorar aún más su implementación de Databricks al aprovechar los paquetes de activos de Databricks Asset Bundles (Databricks Asset Bundles, DABs) para un desarrollo más eficiente y la computación sin servidor para mayor flexibilidad. Entre las próximas iniciativas se incluyen la implementación del enmascaramiento de columnas para datos confidenciales en la capa de consumo y la optimización del rendimiento de las tablas con el manejo de tipos variantes para estructuras de datos complejas, como estructuras y mapas.
La transformación de iFood hacia una arquitectura de datos moderna y unificada ha redefinido la forma en que la empresa procesa y aprovecha su vasto ecosistema de datos. Además, al adoptar Spark Declarative Pipelines, iFood optimizó sus operaciones, eliminó ineficiencias y sentó las bases para obtener información en tiempo real y mejorar la gobernanza. Este cambio no solo ha mejorado la confiabilidad y agilidad de los flujos de datos de la empresa, sino que también ha liberado a sus equipos para que se centren en la innovación y en aportar valor al negocio. Con una arquitectura escalable, eficiente y preparada para el futuro, iFood ahora está equipada para responder a las demandas de un mercado dinámico y seguir mejorando la experiencia del cliente.