¿Qué es la virtualización de datos?
Acceda y consulte datos de múltiples fuentes sin moverlos ni replicarlos físicamente, creando una capa virtual unificada
- Comprenda qué es la virtualización de datos y cómo abstrae el acceso a los datos en sistemas dispares mediante una interfaz unificada.
- Aprenda cómo la virtualización reduce el movimiento de datos, simplifica la arquitectura y proporciona acceso en tiempo real a fuentes de datos distribuidas.
- Descubra casos de uso que incluyen consultas federadas, integración de sistemas heredados y análisis ágil sin procesos ETL complejos.
¿Qué es la virtualización de datos?
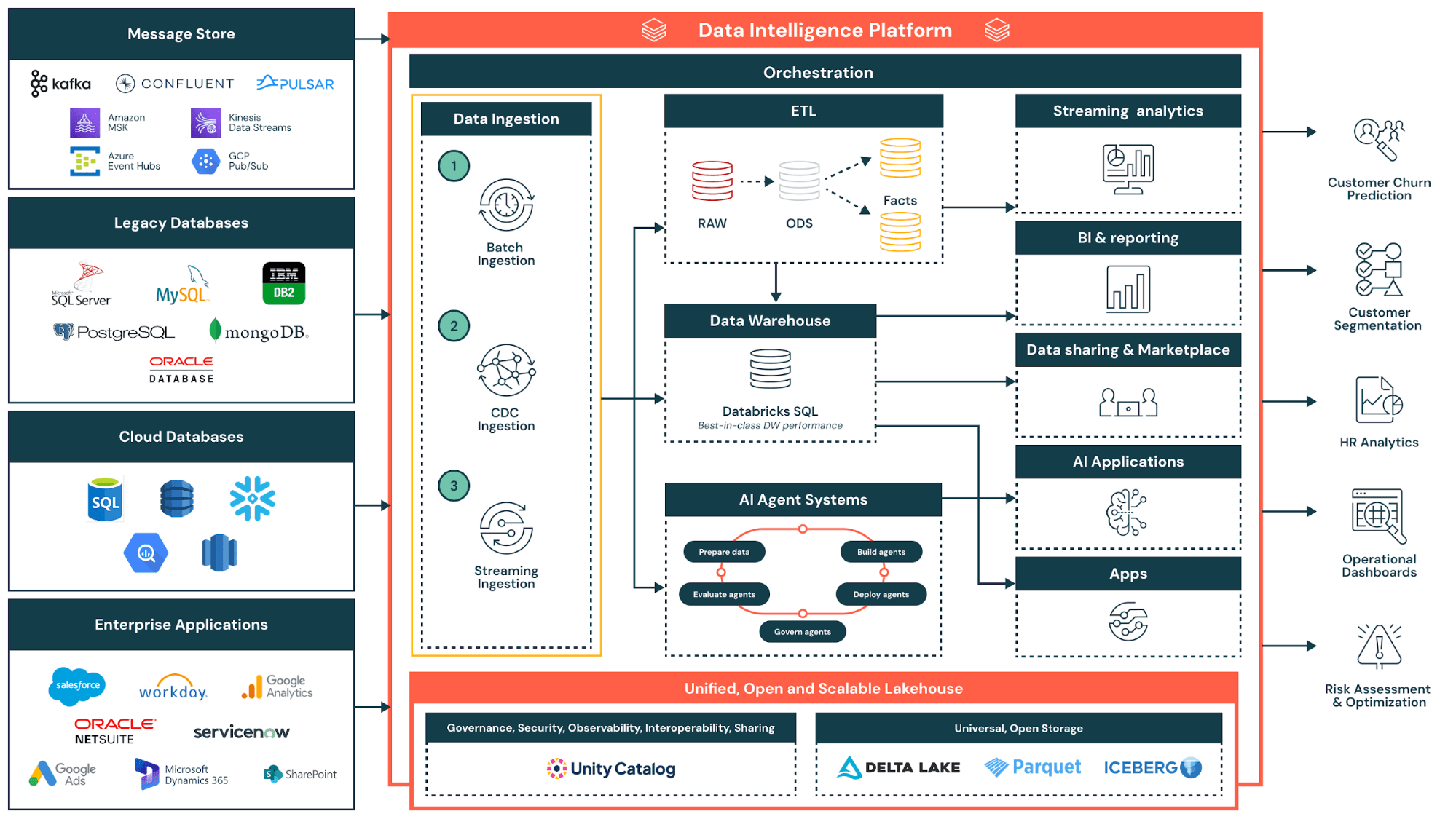
La virtualización de datos es un método de integración de datos que permite a las organizaciones crear vistas unificadas de la información de múltiples fuentes de datos sin necesidad de mover ni copiar los datos físicamente. Como tecnología central de virtualización de datos, este enfoque de gestión de datos permite a los consumidores acceder a datos de sistemas dispares a través de una única capa virtual. En lugar de extraer datos a un repositorio central, la virtualización de datos coloca una capa abstracta entre los consumidores de datos y los sistemas de origen. Los usuarios consultan esta capa a través de una única interfaz, mientras que los datos subyacentes permanecen en su ubicación original.
La virtualización de datos aborda un desafío fundamental en la gestión moderna de datos: los datos empresariales están dispersos en múltiples fuentes, incluidas bases de datos, lagos de datos, aplicaciones en la nube y sistemas heredados. Los enfoques tradicionales de integración de datos requieren la creación de procesos complejos para trasladar los datos a un almacén central antes de que pueda comenzar el análisis. La virtualización de datos elimina esa demora al proporcionar acceso en tiempo real, independientemente de dónde se encuentre la información.
El interés en la virtualización de datos se ha acelerado a medida que las organizaciones adoptan entornos multinube, arquitecturas de lakehouse y el intercambio de datos entre organizaciones. Estas tendencias multiplican la cantidad de fuentes a las que los equipos necesitan acceder, lo que hace que la consolidación física sea cada vez más impracticable. La virtualización de datos ofrece una manera de unificar el acceso sin unificar el almacenamiento.
La tecnología de virtualización de datos crea una capa de virtualización que se encuentra entre los consumidores de datos y los sistemas de origen. Esta capa virtual permite a los usuarios empresariales consultar datos a través de lagos de datos, almacenes de datos y servicios de espacio en la nube sin comprender las complejidades técnicas de cada fuente. Al implementar la virtualización de datos, las organizaciones permiten a sus equipos combinar datos de múltiples fuentes en tiempo real, mientras mantienen una gobernanza centralizada.
Hay un punto común de confusión que es importante aclarar: la virtualización de datos y la visualización de datos suenan similares, pero resuelven problemas completamente diferentes. La virtualización de datos es una tecnología de integración que crea capas de acceso entre fuentes distribuidas. La visualización de datos es una tecnología de presentación que representa la información como gráficos, diagramas y paneles para la inteligencia empresarial. Ambos son complementarios: la virtualización de datos proporciona un acceso unificado, que las herramientas de visualización muestran en formatos legibles para el ser humano.
Para las organizaciones que buscan una gestión de datos ágil, la virtualización de datos ofrece un camino hacia la obtención de información más rápida sin la sobrecarga de infraestructura de los enfoques tradicionales.
Crosslink: Procesos ETL y estrategias de integración de datos
Cómo funciona la virtualización de datos: arquitectura y componentes
La arquitectura de virtualización de datos se basa en tres componentes principales de la infraestructura de gestión de datos: una capa semántica de datos para definiciones empresariales, una capa de virtualización para la federación de consultas y la gestión de metadatos para la gobernanza. Las plataformas modernas integran estos componentes para crear entornos de datos virtuales completos donde los científicos de datos, los usuarios empresariales y los consumidores de datos pueden acceder a fuentes y servicios de datos sin saber dónde se almacena la información.
La capa de virtualización se encuentra entre los consumidores de datos (como analistas, aplicaciones y herramientas de BI) y las fuentes de datos subyacentes. Esta capa mantiene metadatos sobre dónde residen los datos, cómo están estructurados y cómo acceder a ellos. La capa en sí no almacena ningún dato; funciona como un motor de enrutamiento y traducción inteligente. Las soluciones de gobernanza como Unity Catalog pueden gestionar estos metadatos de forma centralizada para ofrecer un único punto de control para las políticas de descubrimiento y acceso.
Cuando un usuario envía una consulta, el motor de virtualización de datos determina qué fuentes de datos contienen la información relevante. Traduce la consulta al idioma nativo de cada sistema, ya sea SQL para bases de datos relacionales, llamadas API para aplicaciones en la nube o protocolos de acceso a archivos para lagos de datos. Luego, el motor federa la solicitud entre los sistemas y reúne los resultados en una respuesta unificada.
La virtualización de datos permite la federación de consultas, que describe este modelo de ejecución distribuida. Las consultas complejas se separan en subconsultas, cada una enrutada a la fuente correspondiente. Los resultados regresan a la capa de virtualización, que los une y transforma antes de ofrecer una única respuesta al usuario. Lakehouse Federation, por ejemplo, permite a los usuarios realizar consultas desde bases de datos externas, almacenes y aplicaciones en la nube directamente desde el lakehouse sin necesidad de migrar datos antes. La optimización del rendimiento se realiza mediante técnicas como la inserción de predicados (predicate pushdown), en las que la lógica de filtrado se ejecuta en el origen y no de forma centralizada.
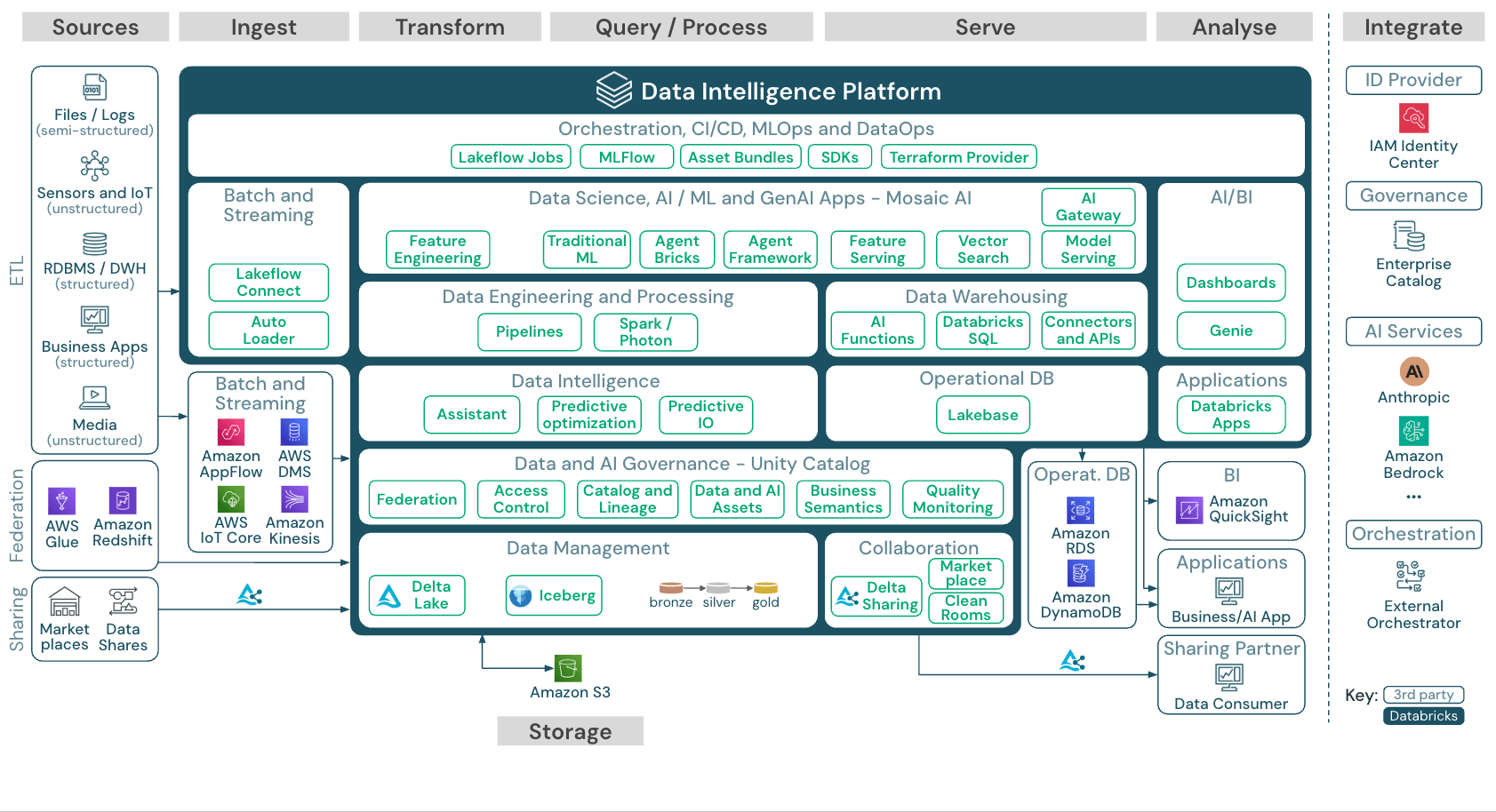
Las plataformas modernas también implementan el join pushdown, la poda de columnas y la caché inteligente. Cuando las fuentes tienen tiempos de respuesta variables, el motor ejecuta las consultas en paralelo y aplica un control de tiempo de espera para evitar que las fuentes lentas bloqueen los resultados. Estas optimizaciones ayudan a las consultas virtualizadas a abordar el rendimiento de las consultas frente a datos físicamente consolidados.
La virtualización de datos nativa de Lakehouse ofrece un beneficio adicional: gobernanza unificada en datos federados e internos. Con Unity Catalog gestionando las políticas de acceso, las organizaciones aplican las mismas reglas de seguridad a las bases de datos externas y a las tablas de lakehouse. Los usuarios consultan datos virtuales y físicos en la misma instrucción SQL sin gestionar sistemas o licencias separadas.
Virtualización de datos vs. ETL: Diferencias clave
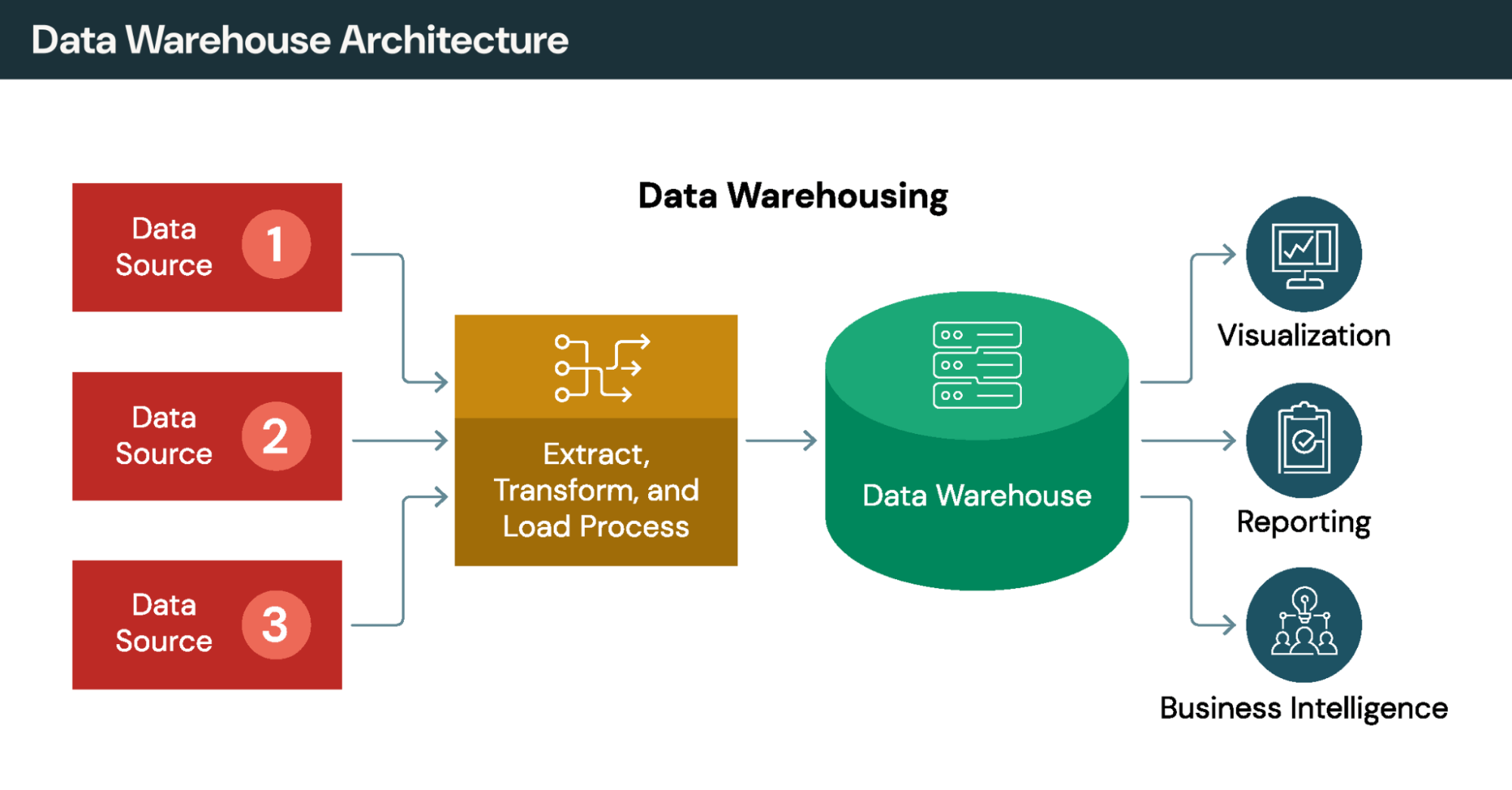
El ETL tradicional (extraer, transformar, cargar) mueve físicamente los datos de los sistemas de origen a un almacén o lago centralizado. Esto crea copias, introduce latencia entre los ciclos de extracción y requiere un mantenimiento continuo del proceso. La virtualización de datos adopta el enfoque opuesto: los datos permanecen en su lugar, a los que se accede bajo demanda.
Cada enfoque aborda diferentes casos de uso. Considera cómo difieren en dimensiones clave:
Movimiento de datos: ETL copia los datos a un repositorio central. La virtualización de datos consulta los datos en su ubicación original sin crear duplicados.
Actualización de los datos: ETL proporciona datos tan actuales como el último ciclo de actualización, que puede tener horas o días de antigüedad. La virtualización de datos proporciona acceso en tiempo real a datos de origen en vivo.
Tiempo para obtener información: ETL requiere la construcción de canalizaciones antes de que pueda comenzar el análisis, lo que suele llevar semanas o meses. La virtualización de datos proporciona acceso inmediato una vez configuradas las conexiones.
Transformaciones complejas: ETL se destaca en el procesamiento de múltiples pasos y el análisis histórico. La virtualización de datos maneja las uniones y los filtros, pero tiene dificultades con la lógica de transformación elaborada.
La mayoría de las organizaciones utilizan ambos enfoques juntos. ETL y ELT manejan transformaciones complejas, tendencias históricas y cargas de trabajo por lotes de rendimiento crítico. La virtualización de datos proporciona acceso ágil y en tiempo real para análisis ad hoc y paneles operativos. La elección depende de las características de la carga de trabajo más que de la ideología.
Crosslink: Catálogo de Unity para gobernanza unificada y patrones de arquitectura de datos
Beneficios clave: acceso en tiempo real sin movimiento de datos
El caso empresarial para la virtualización de datos se centra en la velocidad, la reducción de costos y la simplificación de la gobernanza. La virtualización de datos permite a las organizaciones reducir los costos de almacenamiento, mejorar el acceso a los datos para los usuarios empresariales y simplificar la infraestructura en fuentes dispares.
1. Reducción de los costos de almacenamiento e infraestructura
La virtualización de datos genera un valor inmediato al reducir los costos de replicación de datos. Eliminar la duplicidad significa que las organizaciones dejen de pagar para almacenar múltiples copias de la misma información en almacenes, supermercados y entornos analíticos. El ahorro de almacenamiento se acumula a medida que crecen los volúmenes y los equipos evitan la complejidad de la infraestructura de mantener copias sincronizadas.
2. Perspectivas casi en tiempo real para los consumidores de datos
Las consultas afectan a los sistemas activos en lugar de a las copias obsoletas del almacén. Por ejemplo, las empresas de servicios financieros utilizan esta capacidad para detectar fraudes. Los minoristas realizan un seguimiento del inventario en todos los canales a medida que se producen las transacciones; y los sistemas de salud pueden acceder a los registros actuales de los pacientes durante los episodios de atención médica. El análisis en tiempo real se vuelve posible sin necesidad de construir canalizaciones de transmisión.
3. Infraestructura simplificada
Al implementar la virtualización de datos, las organizaciones centralizan las reglas de acceso, las políticas de seguridad y los metadatos en una capa de datos virtual, en lugar de replicar la gobernanza en múltiples sistemas. Los administradores definen las políticas una sola vez, en lugar de mantenerlas por separado en cada fuente. Cuando se integra en una plataforma lakehouse en lugar de implementarse como una infraestructura independiente, los equipos evitan gestionar otro sistema más.
4. Tiempo de conversión a valor más rápido para las iniciativas empresariales
Las organizaciones informan de la reducción de los plazos de entrega de semanas a días u horas. La aceleración proviene de la eliminación de los meses que normalmente se requieren para diseñar, construir, probar y mantener las canalizaciones ETL para cada nuevo caso de uso analítico.
Estas ventajas se aplican sobre todo a situaciones en las que intervienen diversas fuentes de datos, requisitos que cambian rápidamente y se da prioridad a la actualidad de los datos frente a la profundidad histórica.
Enfoques de integración comparados
Los métodos de integración tradicionales, como ETL, trasladan físicamente los datos a repositorios centrales. La virtualización de datos adopta un enfoque diferente: acceder a los datos en su ubicación sin necesidad de replicarlos. Las organizaciones suelen combinar ambas estrategias: ETL para transformaciones complejas y virtualización de datos para un acceso ágil.
Crosslink: Capacidades de análisis en tiempo real y almacenamiento de datos moderno.
La guía de IA agéntica para la empresa

Casos de uso prácticos y aplicaciones en la industria
La tecnología de virtualización de datos se destaca cuando las organizaciones necesitan acceso unificado entre sistemas operativos, lagos de datos y aplicaciones en la nube. La virtualización de datos permite el acceso en tiempo real desde múltiples fuentes sin el tiempo de espera de los proyectos tradicionales de integración de datos. Los siguientes ejemplos ilustran patrones comunes.
Venta minorista
Los minoristas operan a través de plataformas de comercio electrónico, sistemas de tiendas físicas, aplicaciones de gestión de almacenes, terminales de punto de venta y redes de proveedores. Implementar la virtualización de datos crea visibilidad de extremo a extremo en la cadena de suministro al proporcionar acceso a través de múltiples sistemas sin necesidad de construir integraciones punto a punto.
La gestión de inventario se beneficia especialmente de la virtualización de datos en tiempo real. En lugar de sincronizar por lotes los conteos de inventario cada noche, los minoristas consultan datos en vivo de todos los canales para proporcionar una disponibilidad precisa. Esto permite capacidades como comprar en línea y recoger en la tienda, donde los clientes necesitan información actualizada sobre el stock antes de hacer pedidos. Las organizaciones que implementan la virtualización de datos para el acceso a la cadena de suministro informan de un ahorro significativo en los costos gracias a la reducción de los costos de mantenimiento de inventario y a la mejora en la precisión de las previsiones de demanda.
Servicios financieros
Las empresas de servicios financieros utilizan soluciones de virtualización de datos para agregar datos de clientes procedentes de transacciones con tarjetas de crédito, depósitos, sistemas de préstamos, plataformas CRM y proveedores externos con el fin de crear perfiles completos de los clientes. La virtualización de datos recopila estas vistas bajo demanda en lugar de mantener registros de clientes preconstruidos que se vuelven obsoletos entre las actualizaciones.
La detección de fraudes en tiempo real requiere un acceso en menos de un segundo a los patrones de transacciones de todas las cuentas. Los almacenes orientados a lotes no pueden soportar este requisito de latencia. El cumplimiento normativo también se beneficia: se posibilita la presentación de informes consolidados en todos los sistemas mientras se mantienen los registros de auditoría para la revisión por parte de los examinadores.
Asistencia médica
Los datos de los pacientes son confidenciales y están distribuidos entre registros médicos electrónicos, sistemas de facturación, archivos de imágenes y sistemas de información de laboratorios. La virtualización de datos permite a los médicos acceder a vistas unificadas de los pacientes durante la prestación de atención, lo que mantiene los datos en su origen. Un médico que revisa el historial de un paciente puede ver los registros de atención primaria, visitas a especialistas y resultados de laboratorio en una sola consulta, aunque cada sistema almacene datos de forma independiente.
Esta arquitectura cumple con los requisitos de privacidad porque la información sensible nunca se concentra en una sola ubicación vulnerable a violaciones. Los hospitales y los sistemas de salud pueden compartir el acceso sin transferir físicamente los datos entre organizaciones, lo que permite una atención coordinada.
Cuando la virtualización de datos no es la opción adecuada
La virtualización de datos tiene limitaciones claras. El procesamiento por lotes de gran volumen aún requiere de movimiento físico. El procesamiento de millones de filas no ofrece ninguna ventaja de rendimiento sobre el movimiento de datos una vez. Un procesador de pagos que maneja millones de transacciones por hora, por ejemplo, no obtendría ningún beneficio al virtualizar esa carga de trabajo. El análisis histórico que requiere instantáneas puntuales necesita un almacén que registre el estado a lo largo del tiempo, ya que la virtualización de datos sólo accede a los datos actuales. Las transformaciones complejas de varios pasos superan las capacidades, que se limitan a uniones, filtros y agregaciones de estilo de base de datos.
Las implementaciones de almacenes muy grandes, las operaciones entre centros de datos y las cargas de trabajo que requieren una baja latencia garantizada suelen justificar el movimiento físico a través de canalizaciones de ingeniería de datos.
Crosslink: lagos de datos y aplicaciones de inteligencia empresarial
Gobernanza, seguridad y consideraciones de calidad
La virtualización de datos refuerza la gobernanza al consolidar el control en una capa de virtualización centralizada. Las herramientas de virtualización de datos permiten a los administradores definir políticas de seguridad una sola vez, en lugar de gestionarlas por separado en fuentes dispares.
Las capacidades de seguridad en las plataformas modernas incluyen control de acceso basado en roles, seguridad a nivel de fila y columna, y enmascaramiento de datos para campos sensibles. El control de acceso basado en atributos vinculado a etiquetas de clasificación permite que las políticas viajen con los datos independientemente de cómo los usuarios accedan a ellos. Ya sea que los analistas se conecten a través de consultas SQL, API REST o herramientas de BI, se aplican las mismas reglas de seguridad.
El seguimiento de auditoría y linaje captura quién accedió a qué datos, cuándo y desde qué aplicación. Unity Catalog proporciona registros de auditoría a nivel de usuario y linaje en todos los idiomas para los informes de cumplimiento. Esta visibilidad respalda el RGPD, HIPAA, CCPA y las regulaciones financieras que requieren una gobernanza demostrable.
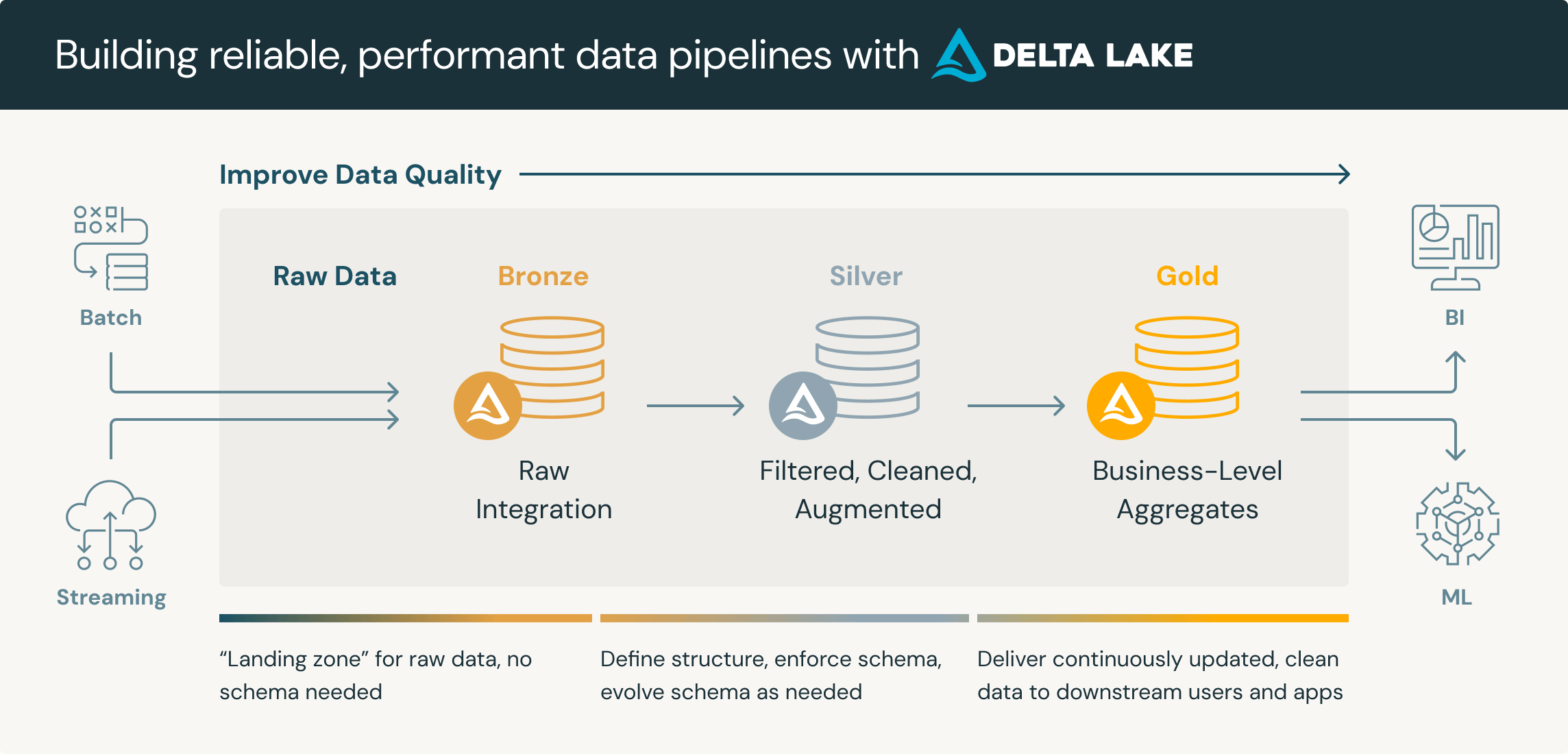
La vigencia de los datos es inherente a la virtualización de datos, ya que las consultas llegan a fuentes en vivo. Pero esto plantea consideraciones sobre la calidad de los datos: si los sistemas contienen errores o inconsistencias, la virtualización de datos expone esos problemas directamente a los consumidores. Las implementaciones eficaces combinan la virtualización de datos con la supervisión de la calidad de los datos para garantizar que la vista unificada mantenga su integridad.
La consistencia semántica presenta otro desafío. Diferentes sistemas pueden usar nombres diferentes para el mismo concepto y diferentes tipos de datos para campos equivalentes o definiciones comerciales alternativas para métricas similares. La capa de virtualización debe aplicar convenciones de nombres consistentes para que los datos del cliente en el CRM coincidan con el mismo cliente en el sistema de facturación, incluso si cada sistema etiqueta y formatea los datos de manera diferente. Algunas organizaciones agregan una capa de datos semánticos para definir términos comerciales canónicos y cálculos que se aplican en todas las fuentes virtualizadas, lo que garantiza que los analistas vean definiciones consistentes independientemente del sistema subyacente que almacene los datos.
Crosslink: gobernanza de datos con Unity Catalog y mejores prácticas de gestión de datos
Mejores prácticas de implementación y selección de herramientas
Las organizaciones que implementan la virtualización de datos deben seguir patrones probados para garantizar una implementación exitosa. Comience poco a poco: las implementaciones exitosas suelen comenzar con un equipo pequeño que aborda proyectos específicos y de alto valor, y solo se amplían después de demostrar su valor a las partes interesadas. Define primero la gobernanza al establecer la propiedad, los modelos de seguridad y los estándares de desarrollo antes de desplegar la tecnología. Monitorea el rendimiento periódicamente para identificar consultas de ejecución lenta, optimizar las vistas virtuales a las que se accede con frecuencia y ajustar las conexiones a medida que evolucionan los patrones de uso.
Cómo se ve la virtualización de datos en la práctica: Implementación en el mundo real
Considera un ejemplo concreto. Una empresa minorista quiere analizar el valor de por vida del cliente, pero los datos del cliente viven en el CRM de Salesforce, el historial de transacciones reside en una base de datos PostgreSQL, el comportamiento del sitio web está en Google Analytics y los datos de retorno permanecen en un sistema Oracle heredado.
La integración de datos tradicional requiere la creación de canales ETL para extraer, transformar y cargar todos estos datos en un almacén. Ese proyecto lleva meses. Con la virtualización de datos, un administrador crea conexiones a cada fuente y publica una vista virtual que combina datos de todos los sistemas. Los analistas consultan esta vista a través de SQL familiar o conectan herramientas de BI directamente. Ven datos actuales de todas las fuentes en un esquema unificado. Cuando la empresa agrega posteriormente una aplicación móvil con su propia base de datos, la incorporación de esa fuente a la vista virtual lleva días, en lugar de requerir un rediseño del almacén.
Este patrón también soporta una estrategia de "virtualizar primero y migrar después". Los equipos empiezan federando consultas a fuentes externas y luego monitorizan qué datos se acceden con más frecuencia. Los conjuntos de datos de alto uso se convierten en candidatos para la migración física a Delta Lake, donde el rendimiento de las consultas mejora y los costos de almacenamiento de información pueden disminuir. Los datos de menor uso permanecen virtualizados, lo que evita esfuerzos de migración innecesarios.
Evaluación de software y herramientas de virtualización de datos
Al evaluar las herramientas de virtualización de datos, prioriza tres criterios.
Compatibilidad con diversas fuentes: ¿La plataforma se conecta a todas sus fuentes actuales y previstas, incluidas las bases de datos relacionales, aplicaciones en la nube, API y almacenamiento basado en archivos? Considera si es compatible con los servicios de datos que necesitas. Las brechas en la conectividad obligan a buscar soluciones alternativas que socavan las promesas de virtualización de datos de acceso unificado.
Características de seguridad: busca seguridad a nivel de fila y columna, enmascaramiento, cifrado e inicio de sesión de auditoría integral. Estas capacidades deben aplicarse de manera consistente, independientemente de cómo accedan los usuarios a los datos virtualizados.
Capacidades de autoservicio: ¿Pueden los usuarios del negocio descubrir y acceder a datos virtualizados sin intervención de TI para cada solicitud? El valor de la virtualización de datos disminuye si cada consulta nueva requiere la intervención del administrador.
Además de estos tres aspectos, ten en cuenta los requisitos de rendimiento de las consultas, las preferencias del modelo de implementación y el costo total de propiedad.
Crosslink: LakeFlow para la integración de datos y capacidades de capa semántica
Conclusión: Cuándo elegir la virtualización de datos
La virtualización de datos se destaca por la analítica operativa en tiempo real, la exploración periódica de diversas fuentes, el desarrollo de pruebas de concepto y escenarios donde la frescura de los datos importa más que el rendimiento de las consultas. La virtualización de datos permite a las organizaciones acceder a datos de múltiples fuentes sin canalizaciones complejas, mientras que los enfoques tradicionales a través de almacenes siguen siendo superiores para transformaciones complejas, tendencias históricas, procesamiento por lotes de alto volumen y cargas analíticas críticas en latencia.
La cuestión no es qué enfoque elegir en exclusiva, sino dónde encaja cada uno dentro de una arquitectura integral. Las organizaciones implementan cada vez más ambas tecnologías: la virtualización de datos para un acceso ágil y la experimentación y la integración física cuando las características de la carga de trabajo así lo exigen. El patrón de "virtualizar primero, migrar después" permite a los equipos ofrecer valor inmediatamente mediante consultas federadas mientras utilizan datos de uso real para priorizar qué fuentes justifican la inversión de migración física a Delta Lake u otro almacenamiento en lakehouse.
Comienza por identificar casos de uso en los que el acceso en tiempo real a datos distribuidos genere un claro valor comercial. Prueba la virtualización de datos allí, mide los resultados y amplía el proyecto en función del éxito demostrado.
Crosslink: marco de decisión ETL vs. ELT
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.