¿Qué es la ingeniería de características?
Transformación de datos sin procesar en características informativas para modelos de aprendizaje automático mediante técnicas de selección, extracción, construcción y transformación
- La selección identifica las variables más relevantes de los datos disponibles mediante análisis de correlación, información mutua, eliminación recursiva de características o experiencia en el dominio, eliminando características redundantes, irrelevantes o ruidosas.
- La extracción deriva nuevas características a partir de las existentes mediante reducción de dimensionalidad (PCA, t-SNE), vectorización de texto (TF-IDF, incrustaciones de palabras) o aprendizaje automático de características (representaciones de aprendizaje profundo).
- La construcción crea características diseñadas que combinan variables a través del conocimiento del dominio, como proporciones, agregaciones, interacciones, binning, características polinómicas y características temporales (ventanas móviles, retardos), capturando relaciones complejas.

Ingeniería de características para el aprendizaje automático
La ingeniería de características, también conocida como preprocesamiento de datos, es el proceso de transformar datos sin procesar en características que se pueden utilizar para desarrollar modelos de aprendizaje automático. Este tema describe los conceptos principales de la ingeniería de características y el papel que desempeña en la gestión del ciclo de vida de ML.
Las características, en el contexto del aprendizaje automático, son los datos de entrada que se usan para entrenar un modelo. Son los atributos de alguna entidad sobre la que el modelo aprenderá. Por lo general, los datos sin procesar deben procesarse antes de que se puedan usar como entrada para un modelo de ML. Una buena ingeniería de características hace que el proceso de desarrollo de modelos sea más eficiente y conduce a modelos que son más simples, flexibles y precisos.

¿Qué es la ingeniería de características?
La ingeniería de características es el proceso de transformar y enriquecer datos para mejorar el rendimiento de los algoritmos de aprendizaje automático utilizados para entrenar modelos con esos datos.
La ingeniería de características incluye pasos como escalar o normalizar datos, codificar datos no numéricos (como texto o imágenes), agregar datos por tiempo o entidad, unir datos de diferentes fuentes o incluso transferir conocimiento de otros modelos. El objetivo de estas transformaciones es aumentar la capacidad de los algoritmos de aprendizaje automático para aprender del conjunto de datos y, por lo tanto, realizar predicciones más precisas.
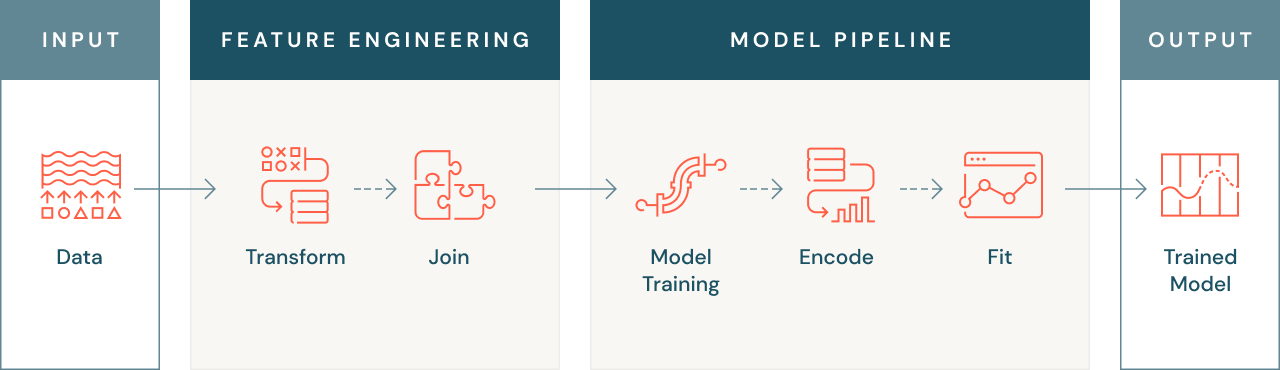
¿Por qué es importante la ingeniería de características?
La ingeniería de características es importante por varias razones. En primer lugar, como se mencionó anteriormente, los modelos de aprendizaje automático a veces no pueden operar con datos sin procesar, por lo que los datos deben transformarse en un formato numérico que el modelo pueda entender. Esto podría implicar convertir datos de texto o imágenes en formato numérico, o crear características agregadas, como los valores medios de las transacciones de un cliente.
A veces, las características relevantes para un problema de aprendizaje automático pueden encontrarse en múltiples fuentes de datos, por lo que la ingeniería de características efectiva implica unir estas fuentes para crear un único conjunto de datos utilizable. Esto te permite usar todos los datos disponibles para entrenar tu modelo, lo que puede mejorar su precisión y rendimiento.
Otro escenario común es que la salida y el aprendizaje de otros modelos a veces se pueden reutilizar en forma de características para un nuevo problema, gracias a un proceso conocido como aprendizaje por transferencia. Esto te permite aprovechar el conocimiento adquirido de modelos anteriores para mejorar el rendimiento de un nuevo modelo. El aprendizaje por transferencia puede ser particularmente útil cuando se trata de conjuntos de datos grandes y complejos donde no es práctico entrenar un modelo desde cero.
La ingeniería de características efectiva también permite características confiables en el momento de la inferencia, cuando el modelo se está usando para hacer predicciones sobre nuevos datos. Esto es importante porque las características utilizadas en el momento de la inferencia deben ser las mismas que las utilizadas en el momento del entrenamiento, para evitar la “desviación en línea/fuera de línea”, donde las características que se usan en el momento de la predicción se calculan de manera diferente a las que se usan para el entrenamiento.
¿En qué se diferencia la ingeniería de características de otras transformaciones de datos?
El objetivo de la ingeniería de características es crear un conjunto de datos que se pueda entrenar para construir un modelo de aprendizaje automático. Muchas de las herramientas y técnicas utilizadas para las transformaciones de datos también se utilizan para la ingeniería de características.
Dado que el énfasis de la ingeniería de características es desarrollar un modelo, hay varios requisitos que no están presentes en todas las transformaciones de características. Por ejemplo, puede que desee reutilizar características en varios modelos o entre equipos de su organización. Esto requiere un método robusto para descubrir características.
Además, tan pronto como se reutilicen las características, necesitarás una forma de rastrear dónde y cómo se calculan. Esto se llama linaje de características. Los cálculos de características reproducibles son de particular importancia para el aprendizaje automático, ya que la característica no solo debe calcularse para entrenar el modelo, sino que también debe recalcularse exactamente de la misma manera cuando el modelo se utiliza para la inferencia.
La guía de IA agéntica para la empresa

¿Cuáles son los beneficios de una ingeniería de características efectiva?
Contar con una canalización de ingeniería de características eficaz implica canalizaciones de modelado más robustas y, en última instancia, modelos más fiables y con mejor rendimiento. Mejorar las características utilizadas tanto para el entrenamiento como para la inferencia puede tener un impacto increíble en la calidad del modelo, por lo que mejores características significan mejores modelos.
Desde otra perspectiva, la ingeniería de características efectiva también fomenta la reutilización, no solo al ahorrarles tiempo a los profesionales, sino también al mejorar la calidad de sus modelos. Esta reutilización de características es importante por dos razones: ahorra tiempo y, además, tener características definidas de forma robusta ayuda a evitar que tus modelos usen datos de características diferentes entre el entrenamiento y la inferencia, lo que generalmente conduce a un sesgo “en línea/fuera de línea”.
¿Qué herramientas se necesitan para la ingeniería de características?
En general, las mismas herramientas que se emplean para la ingeniería de datos se pueden usar para la ingeniería de características, ya que la mayoría de las transformaciones son comunes entre ambas. Esto generalmente implica algún sistema de almacenamiento y gestión de datos, acceso a lenguajes de transformación abiertos estándar (SQL, Python, Spark, etc.) y acceso a algún tipo de cómputo para ejecutar las transformaciones.
Sin embargo, existen algunas herramientas adicionales que se pueden implementar para la ingeniería de características en forma de bibliotecas específicas de Python que pueden ayudar con las transformaciones de datos específicas del aprendizaje automático, como incrustar texto o imágenes, o codificar variables categóricas con one-hot encoding. También hay algunos proyectos de código abierto que ayudan a rastrear las características que utiliza un modelo.
El control de versiones de datos es una herramienta importante para la ingeniería de características, ya que los modelos a menudo pueden entrenarse con un conjunto de datos que ha sido modificado desde entonces. Tener un control de versiones de datos adecuado te permite reproducir un modelo determinado mientras tus datos evolucionan naturalmente con el paso del tiempo.
¿Qué es un almacén de características?
Un almacén de características es una herramienta diseñada para abordar los desafíos de la ingeniería de características. Un almacén de características es un repositorio centralizado de características en una organización. Los científicos de datos pueden usar un almacén de características para descubrir y compartir características y rastrear su linaje. Un almacén de características también garantiza que se usen los mismos valores de características en los momentos de entrenamiento e inferencia. Los cálculos de características reproducibles son de particular importancia para el aprendizaje automático, ya que la característica no solo debe calcularse para entrenar el modelo, sino que también debe recalcularse exactamente de la misma manera cuando el modelo se utiliza para la inferencia.
¿Por qué usar Databricks Feature Store?
Databricks Feature Store está completamente integrado con otros componentes de Databricks. Puede usar Databricks Notebooks para desarrollar código para crear características y diseñar modelos basados en esas características. Cuando sirves modelos con Databricks, el modelo busca automáticamente los valores de las características en el almacén de características para la inferencia. Databricks Feature Store también proporciona los beneficios de los almacenes de características descritos en este artículo:
- Capacidad de descubrimiento. La interfaz de usuario del almacén de características, accesible desde el espacio de trabajo de Databricks, permite explorar y buscar características existentes.
- Linaje. Al crear una tabla de características con Databricks Feature Store, se guardan las fuentes de datos utilizadas para generar la tabla de características y se puede acceder a ellas. Para cada característica de una tabla de características, también puedes acceder a los modelos, documentos interactivos, trabajos y puntos de conexión que utilizan la característica.
Además, Databricks Feature Store proporciona lo siguiente:
- Integración con la puntuación y el servicio de modelos. Cuando usas características de Databricks Feature Store para entrenar un modelo, el modelo se empaqueta con metadatos de características. Cuando usas el modelo para la puntuación por lotes o la inferencia en línea, recupera automáticamente las características de Databricks Feature Store. La persona que realiza la llamada no necesita saber acerca de las características ni incluir lógica para buscar o unir características para puntuar nuevos datos. Esto facilita enormemente la implementación y las actualizaciones de los modelos.
- Consultas en un momento específico. Databricks Feature Store admite casos de uso basados en eventos y series temporales que requieren precisión en un momento específico.
Recursos adicionales
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.