¿Qué es una base de datos relacional (RDBMS)?
Almacenar y administrar datos estructurados en tablas con relaciones definidas, garantizando la integridad de los datos mediante propiedades ACID
- Comprender qué son los sistemas de gestión de bases de datos relacionales (RDBMS) y cómo organizan los datos en tablas estructuradas con relaciones.
- Aprender sobre los principios de las bases de datos relacionales, incluyendo claves primarias, claves externas, normalización y consultas basadas en SQL.
- Descubrir por qué las soluciones RDBMS siguen siendo esenciales para los sistemas transaccionales que requieren consistencia de datos e integridad referencial.
¿Qué es una base de datos relacional?
Una base de datos relacional es un tipo de base de datos que almacena y proporciona acceso a datos en tablas que pueden vincularse entre sí mediante columnas y filas compartidas, denominadas relaciones, con identificadores únicos (claves) que muestran las diferentes relaciones entre las tablas.
Este modelo relacional es similar a un modelo de hoja de cálculo, en el que las filas representan los registros individuales, como clientes, cuentas o transacciones, mientras que las columnas representan los atributos de esos registros, como el ID del cliente, el número de cuenta o el importe de la transacción. Con este modelo, las filas de una tabla se pueden vincular a las filas de otra tabla mediante claves comunes que establecen las relaciones entre las tablas.
Este modelo proporciona una forma estándar de representar y consultar datos que pueden usar una variedad de aplicaciones.
Un sistema de gestión de bases de datos relacionales (RDBMS) es un sistema de software (a veces denominado motor de base de datos) que implementa el modelo de base de datos relacional y administra datos relacionales, no solo tablas, desde escrituras y lecturas en discos hasta el mantenimiento de índices, la ejecución de consultas y la aplicación de la integridad de los datos.
Conceptos básicos del modelo relacional
Tablas, filas y columnas
La estructura fundamental del modelo relacional es la organización de los datos en tablas, filas y columnas. Las tablas son estructuras de datos bidimensionales creadas para mostrar una colección de datos relacionados organizados de manera lógica para permitir la ejecución de consultas estructuradas.
Las filas representan entidades o registros específicos (tuplas) en una tabla de base de datos relacional y contienen el valor de cada columna.
Las columnas representan las categorías de atributos de cada registro en una fila.
En esencia, las columnas definen la estructura y las filas proporcionan los datos reales. Una tabla de productos sencilla podría incluir las siguientes filas de productos específicos con columnas de atributos asociados:
| ID de producto | Nombre del producto | Tipo de producto | Precio ($) |
|---|---|---|---|
| PSHL16 | Salchicha de cerdo picante de Chuck | Salchichas de cerdo picantes (1 lb) | 5.99 |
| PSML16 | Salchicha de cerdo suave de Chuck | Salchichas de cerdo suaves (1 lb) | 5.99 |
| GTS16 | Salchicha de pavo molido de Chuck | Carne de pavo molido sazonado (1 lb) | 6.59 |
| GT48 | Pavo molido de Chuck | Pavo molido (3 lb) | 18.59 |
Esquema y datos estructurados
El esquema de una base de datos relacional describe la estructura de la base de datos. Define un plan de cómo deben ser los datos y las reglas que debe seguir. Los datos estructurados se almacenan en un formato coherente y predecible según ese esquema (filas y columnas con relaciones coherentes que definen qué tipos de datos pueden ir en cada lugar y cómo deben representarse).
Un buen esquema proporciona integridad y consistencia de los tipos de datos. Con una estructura conocida, puedes optimizar el almacenamiento y las consultas para mantener el rendimiento y mejorar la comprensión, ya que todas las tablas y columnas tienen el mismo significado.
Restricciones e índices
Puede haber restricciones y reglas al escribir en una tabla. Por ejemplo, en el ejemplo anterior, cada producto debe estar asociado con un ID de producto real y cada tipo de producto describirá productos en caja (enlaces) o productos molidos junto con el peso de manera consistente. Además, puede establecer restricciones, como que cada columna debe contener valores (NO NULOS) sin duplicados (ÚNICOS), excepto el precio.
Esto significa que cada fila tiene los mismos campos y cada campo tiene el mismo significado. Con un esquema estricto, los datos permanecen limpios, las relaciones siguen siendo válidas y las consultas siguen siendo previsibles.
Las bases de datos relacionales también pueden tener índices que agilizan la búsqueda de filas sin necesidad de realizar un escaneo completo de la tabla. Un índice almacena los valores de las columnas y proporciona punteros a las filas de la tabla donde aparecen esos valores. El rendimiento puede ralentizarse al consultar tablas grandes, y la indexación evita tener que escanear cada fila de una tabla.
Las bases de datos almacenan índices en varios tipos de estructuras optimizadas para mejorar la velocidad de recuperación de datos:
- La indexación de árbol B es una estructura de datos común diseñada para manejar grandes conjuntos de datos de manera eficiente para reducir la altura del árbol. Cada nodo de un árbol B puede almacenar varias claves y tener varios elementos secundarios, lo que minimiza la cantidad de operaciones de E/S del disco necesarias para acceder a los datos. Al permitir más elementos secundarios bajo un nodo que un árbol binario de búsqueda autobalanceado normal, el árbol B reduce la altura del árbol y coloca los datos en menos bloques separados.
- Las tablas hash son estructuras de datos que asignan claves a valores y utilizan una función hash para convertir una clave en un índice donde se almacena el valor correspondiente. Los índices basados en hash son efectivos para búsquedas de coincidencia exacta, pero no se admiten universalmente ni se utilizan como el tipo de índice predeterminado en todos los RDBMS y no conservan el orden como árboles B.
Claves y relaciones
Las claves son esenciales para garantizar la unicidad, la integridad y la recuperación eficiente de los datos. Identifican de forma única las filas, establecen relaciones entre tablas y evitan la duplicación, lo que forma la columna vertebral del diseño de esquemas relacionales. Los puntos de datos de las tablas se pueden unir con claves comunes, lo que hace posible consultar las tablas para generar reportes. Al utilizar claves comunes, las relaciones pueden ser de uno a uno, de uno a muchos y de muchos a muchos.
Las tablas se conectan con varios tipos de claves:
- Las superclaves son conjuntos de uno o más atributos que pueden identificar un registro de forma única.
- Una clave candidata es un conjunto mínimo de atributos que pueden identificar un registro de forma única.
- Una clave primaria es una clave única que identifica una fila en su tabla. Por ejemplo, en una tabla de clientes, el ID del cliente sería una clave principal.
- Una clave alternativa es una clave candidata que no se elige como clave principal.
- Una clave externa es una columna que apunta a una clave primaria en otra tabla. Por ejemplo, una tabla de transacciones podría hacer referencia al ID de cliente de la tabla de clientes con Orders.customer_id.
- Se requiere una clave compuesta cuando se necesita una combinación de dos o más atributos para identificar todos los registros de una tabla.
Propiedades clave de las bases de datos relacionales
Las bases de datos relacionales son grupos de operaciones (transacciones) que funcionan juntas y tienen varias características que las hacen confiables. Estas transacciones siguen un conjunto de reglas denominadas ACID que significa:
- Atomicidad: todas las actualizaciones deben finalizarse completamente.
- Consistencia: Las reglas siempre se aplican
- Aislamiento: las transacciones concurrentes no interfieren con los estados intermedios de cada una.
- Durabilidad: una vez comprometidos, los datos pueden sobrevivir a fallas o interrupciones.
Estas reglas ayudan a garantizar la integridad de los datos a nivel transaccional, lo que asegura que las operaciones de la base de datos se completen de manera confiable y correcta. El diseño del esquema, los tipos de datos y las restricciones se encargan de garantizar que los valores de las columnas sean atómicos y coherentes en su significado. Las restricciones se utilizan para mantener la coherencia entre varias tablas.
Otra propiedad clave de las bases de datos relacionales es el lenguaje de consulta estructurada (SQL), el lenguaje más común para extraer datos. Dado que los datos se almacenan en tablas predecibles con relaciones, se utiliza SQL para responder de manera eficiente a preguntas complejas y ayudar a analizar los datos. Ofrece un método estándar para ejecutar consultas, recuperar datos, insertar, actualizar o eliminar registros, crear bases de datos o tablas nuevas y establecer permisos en tablas, procedimientos y vistas.
Las bases de datos relacionales también deben garantizar la seguridad y el control de acceso para proteger los datos en varios aspectos:
- Autenticación – Aquellos que acceden a la base de datos son quienes dicen ser
- Autorización: estás haciendo lo que se te permite hacer.
- Auditoría: confirmación de lo que hiciste y cuándo.
La seguridad de las bases de datos también incluye características como el cifrado para proteger los datos en caso de intercepciones o robos, y el respaldo y la recuperación para que los datos no se pierdan durante fallas del sistema.
Las bases de datos relacionales se convirtieron en los “sistemas de registro” predeterminados debido a su estandarización y madurez. Las características, estructuras y capacidades estándar mantienen un RDBMS predecible, confiable, seguro y escalable a lo largo del tiempo. Por ejemplo, con SQL como método estándar para realizar consultas, los conceptos y habilidades fundamentales se pueden transferir de un RDBMS a otro, y las aplicaciones y herramientas de datos se pueden mantener a través de las migraciones. La estandarización también aumenta la competencia y las opciones entre los proveedores.
Las bases de datos relacionales existen desde hace mucho tiempo. Esta madurez significa que las bases se probaron en situaciones reales y se optimizaron para transacciones extremadamente refinadas.
Bases de datos relacionales vs. no relacionales
La diferencia más evidente entre las bases de datos relacionales y no relacionales es que estas últimas no almacenan datos estructurados en tablas. Tienen la flexibilidad de almacenar datos en contenedores en el formato que sea más adecuado para los datos que se van a almacenar. Estos datos no estructurados y poco definidos pueden comprender correos electrónicos, documentos comerciales, videos e imágenes. Pero también pueden almacenar una combinación de datos transaccionales estructurados y datos no estructurados.
Las bases de datos no relacionales se suelen denominar bases de datos NoSQL, un término que originalmente significaba “no solo SQL”, lo que refleja que estos sistemas no dependen de SQL como su interfaz principal, a pesar de que muchos ahora admiten consultas basadas en SQL.
Las bases de datos relacionales utilizan un esquema fijo con filas y columnas y relaciones con claves y uniones SQL, mientras que las bases de datos no relacionales almacenan los datos en estructuras flexibles que no requieren un esquema preestablecido, como pares clave-valor, nodos/aristas y documentos. Con bases de datos relacionales, los datos deben coincidir con el esquema al escribir, mientras que la forma de los datos puede variar en bases de datos no relacionales, donde los datos se interpretan al leer y las relaciones suelen gestionarse en las aplicaciones, no en la base de datos.
Las bases de datos relacionales también utilizan fuertes transacciones ACID de forma predeterminada, mientras que las bases de datos NoSQL están diseñadas tradicionalmente para una consistencia eventual y priorizan la disponibilidad y la velocidad sobre la corrección.
Las bases de datos relacionales se eligen cuando se necesita una estructura clara con reglas sólidas junto con una abundancia de relaciones entre puntos de datos. Un modelo relacional es el más adecuado para la generación de informes y análisis con transacciones que siempre deben ser correctas. Las bases de datos relacionales son excelentes para análisis ad hoc y filtrado y agrupación complejos, mientras que las no relacionales se suelen optimizar para un conjunto de consultas limitado. Las bases de datos relacionales suelen escalar verticalmente, y los sistemas modernos admiten el escalado horizontal mediante réplicas, fragmentación o ejecución distribuida, a menudo con una complejidad mayor, mientras que las bases de datos no relacionales están diseñadas para escalar horizontalmente y suelen elegirse para redes grandes y distribuidas.
Las bases de datos no relacionales se eligen para datos flexibles o que evolucionan rápidamente a gran escala con patrones de consulta simples.
Ejemplos comunes de RDBMS
- MySQL: un RDBMS de código abierto, ahora propiedad de Oracle Corp., que implementa el estándar SQL. Suele ser la opción preferida para aplicaciones web, sistemas empresariales y servicios críticos basados en datos que requieren un alto rendimiento. Se utiliza habitualmente para aplicaciones web, tiendas y catálogos en línea, cuentas de usuario y sistemas de autenticación, registro y análisis, aplicaciones SaaS y paneles de control.
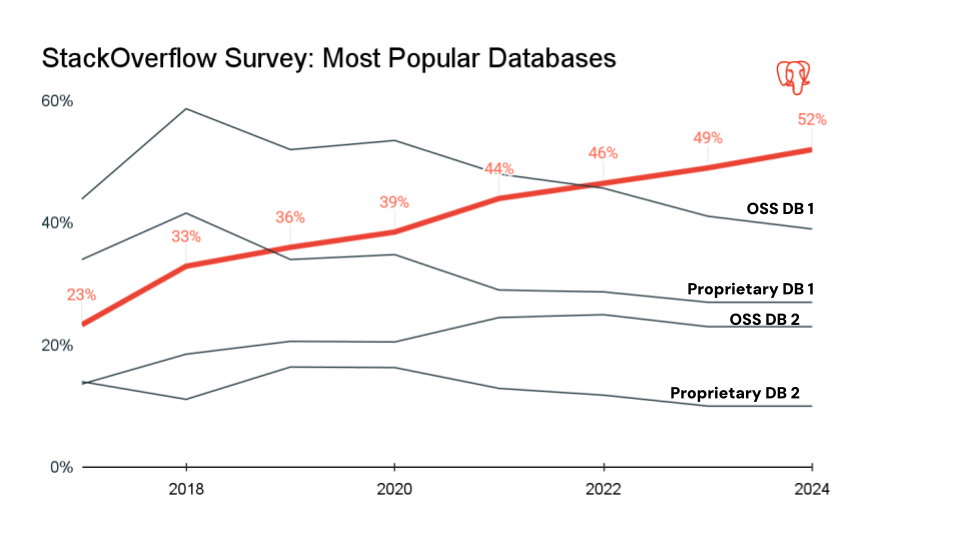
- PostgreSQL: un RDBMS de código abierto altamente extensible conocido por sus estándares sólidos y el cumplimiento de ACID con un buen equilibrio entre confiabilidad y flexibilidad. Soporta almacenamiento de información SQL y JSON/JSONB semiestructurado y utiliza el control de concurrencia de múltiples versiones. PostgreSQL se utiliza para aplicaciones web, plataformas SaaS multitenant, transacciones financieras, análisis e informes, datos científicos y cargas de trabajo OLTP. Es popular entre los negocios que operan exclusivamente en línea. En los últimos siete años, Postgres se convirtió en la base de datos más popular dentro de la comunidad de desarrolladores y es la opción de facto para aplicaciones modernas.
- SQLite: una base de datos relacional sin servidor, multiplataforma y de código abierto que utiliza SQL y se ejecuta dentro de una aplicación a través de una biblioteca C ligera. No requiere configuración ni administración. SQLite se utiliza principalmente para sistemas integrados y aplicaciones pequeñas de dispositivos personales.
- Oracle: un RDBMS propietario de nivel empresarial desarrollado por Oracle Corp. Conocido por su escalabilidad, agrupación en clústeres y fiabilidad, está optimizado tanto para cargas de trabajo transaccionales (OLTP) como analíticas (OLAP) y se utiliza en bancos, aerolíneas, salud, telecomunicaciones, gobiernos y sistemas ERP/CRM a gran escala.
- Microsoft SQL Server: RDBMS de nivel empresarial propiedad de Microsoft basado en Transact-SQL (T-SQL), la extensión SQL de Microsoft. Disponible en Windows y Linux, SQL Server es conocido por sus herramientas de gestión y administración y su integración sólida con Microsoft Azure y otras tecnologías de Microsoft. Los casos de uso típicos incluyen ERP, CRM, RRHH, comercio electrónico, inteligencia empresarial y análisis. SQL Server se destaca en los sectores financieros, bancarios y de salud.
- IBM Db2: una familia patentada de sistemas RDBMS desarrollada por IBM para ofrecer un alto rendimiento, fiabilidad y procesamiento de datos a escala empresarial. Las versiones de Db2 RDBMS se ejecutan en múltiples plataformas, incluidas Linux, UNIX, Windows, IBM AS/400 y mainframes de IBM. Está basado en SQL, pero admite documentos JSON, almacenamiento de información XKL, datos de series temporales, almacenamiento de información en columnas y capacidades de Graph en algunas versiones. Es ampliamente utilizado en finanzas, gobiernos, salud y seguros, comercios minoristas, aerolíneas y entornos de TI empresariales.
- MariaDB: un RDBMS de código abierto creado como un reemplazo inmediato impulsado por la comunidad para MySQL y administrado por MariaDB Foundation. Se utiliza ampliamente tanto para cargas de trabajo OLTP como OLAP en aplicaciones de sitios web, plataformas SaaS, sistemas en la nube y empresas, y es una opción frecuente para sistemas Linux y pilas de código abierto. Los casos de uso comunes incluyen aplicaciones web y sitios web, plataformas SaaS, gestión de contenido, comercio electrónico y análisis.
La guía de IA agéntica para la empresa

SQL, RDBMS y preguntas frecuentes relacionadas
¿SQL es una base de datos relacional?
No, SQL es un lenguaje de consulta utilizado para interactuar con una base de datos relacional, no con un sistema de base de datos.
¿MySQL es una base de datos relacional?
Sí, MySQL es un RDBMS con una estructura basada en tablas que admite relaciones entre tablas.
¿Excel es relacional?
No, Excel es el programa de hojas de cálculo de Microsoft, no un RDBMS. Si bien Excel utiliza un formato de tabla, no existe un esquema impuesto con una estructura y restricciones consistentes. Excel no puede ejecutar consultas SQL por sí solo y no hay transacciones ACID.
¿Cuál es la diferencia entre la terminología de base de datos relacional y RDBMS?
Aunque están estrechamente relacionados y a veces se utilizan indistintamente, las bases de datos relacionales se refieren al modelo de datos en sí, mientras que un RDBMS es un sistema de software que gestiona ese modelo de datos.
Beneficios y limitaciones
Los beneficios del uso de bases de datos relacionales incluyen:
- Fuerte integridad y consistencia de datos reforzadas por transacciones ACID para garantizar que no haya actualizaciones parciales, datos corruptos y operaciones confiables. Los datos estructurados y bien definidos garantizan datos limpios y predecibles.
- Las capacidades y herramientas de consulta estandarizadas con SQL proporcionan filtrado, agrupación, agregación, indexación y uniones complejas para hacer que las bases de datos relacionales sean ideales para analítica, reportes y lógica empresarial compleja.
- Con décadas de madurez, las bases de datos relacionales cuentan con un buen soporte, un rendimiento confiable, modelos de seguridad y disponibilidad sólidos, y un ecosistema de herramientas para reducir el riesgo.
Las limitaciones incluyen:
- El esquema rígido y fijo de las bases de datos relacionales reduce la agilidad y no es adecuado para datos no estructurados o semiestructurados ni para formas de registro que cambian frecuentemente.
- Las bases de datos relacionales son excelentes para la escalabilidad vertical, pero la escalabilidad horizontal es compleja.
- El rendimiento puede degradarse con conjuntos de datos muy grandes y uniones complejas, lo que puede ralentizar las cargas de trabajo distribuidas.
- Los RDBMS comerciales pueden ser costosos, especialmente a escala.
- OLTP no está diseñado para consultas analíticas complejas.
- Facilidad para crear silos de datos, lo que aumenta los costos de almacenamiento de información.
- Complejidad de ETL (en el caso de mover datos entre almacenes operativos y analíticos).
- Manejo de datos semiestructurados (Delta, Iceberg, Parquet, o lo que encuentres en el lakehouse).
- Dificultad con los tipos de datos no estándar para la integración ML/IA.
- No está diseñado para manejar datos de transmisión.
- Dependencia de un proveedor de nube
Evolución más allá de los RDBMS tradicionales
- Era del almacenamiento de datos: los RDBMS están diseñados para usar datos actuales y están optimizados para muchas lecturas o escrituras pequeñas para el procesamiento de transacciones en línea (OLTP). Por eso, pueden tener dificultades con el análisis a gran escala. Para superar esa limitación, los almacenes de datos utilizan esquemas desnormalizados que pueden manejar consultas enormes y complejas contra datos actuales e históricos para el procesamiento analítico en línea (OLAP).
- El reto del big data: los RDBMS tienen dificultades para gestionar datos masivos, rápidos, diversos y distribuidos. Su esquema rígido, escalado vertical y sobrecarga de transacciones ACID los dejaban menos adecuados para análisis distribuidos a gran escala. Los RDBMS tradicionales se basan en uniones ejecutadas en almacenamiento gestionado localmente, lo que limita la escalabilidad en entornos distribuidos.
- Requisitos nativos de la nube: los sistemas de bases de datos relacionales tradicionales tienen dificultades en las arquitecturas nativas de la nube que favorecen el almacenamiento de objetos. Están diseñados para almacenamiento de información en bloques con hardware estrechamente acoplado y acceso a discos de baja latencia. Históricamente, el almacenamiento de objetos no ofrecía las garantías de baja latencia necesarias para el procesamiento clásico de transacciones ACID, lo que suponía un reto para los diseños tradicionales de RDBMS. El almacenamiento de objetos está optimizado para el rendimiento en lugar de la latencia. Las aplicaciones nativas de la nube también escalan horizontalmente, mientras que los diseños tradicionales de SGBD dependen del cómputo y almacenamiento estrechamente acoplados, la mayoría centrados alrededor de un servidor principal.
- Lagos de datos modernos: las arquitecturas Lakehouse evolucionaron para abordar las limitaciones de los lagos de datos tradicionales al combinar la escalabilidad y el bajo costo de los lagos de datos con la estructura, la gobernanza y las características de rendimiento de los almacenes de datos y los sistemas relacionales.
Un lakehouse utiliza almacenamiento de objetos nativo de la nube para la persistencia de datos, mientras introduce formatos de tabla gestionados, capas de metadatos y registros de transacciones que permiten la aplicación de esquemas, acceso SQL y transacciones ACID directamente en ese almacenamiento. Esto permite que los datos estructurados, semiestructurados y no estructurados coexistan en un solo sistema.
A diferencia de los primeros lagos de datos, que dependían en gran medida del esquema en lectura y la lógica de procesamiento externo, los lakehouses admiten el esquema en escritura o la evolución del esquema gestionado a nivel de tabla. Esto permite obtener definiciones de datos coherentes, garantizar la calidad de los datos y realizar análisis fiables. Al desacoplar el almacenamiento de la computación, las arquitecturas lakehouse permiten que múltiples motores de computación operen sobre los mismos datos para realizar análisis, ingeniería de datos, transmisiones y aprendizaje automático. Esta flexibilidad hace que los lakehouses sean adecuados para el análisis a gran escala, inteligencia empresarial y cargas de trabajo de datos avanzadas mientras mantienen la eficiencia de costos y la apertura a través de formatos de archivos y tablas abiertos. - Arquitectura de Lakebase: Lakebase es una nueva categoría de base de datos operativa diseñada para aplicaciones modernas e inteligentes. Si bien los RDBMS se destacan por su consistencia transaccional y sus esquemas estructurados, están aislados de los datos analíticos, los procesos de aprendizaje automático y la inteligencia en tiempo real de los que dependen cada vez más las aplicaciones. Un Lakebase combina capacidades centrales de base de datos como transacciones, indexación y acceso de baja latencia con integración nativa al lakehouse, permitiendo que las aplicaciones operen directamente sobre datos frescos, compartidos, analíticos y preparados para IA. Esto permite que un solo sistema soporte tanto las cargas de trabajo operativas como el comportamiento inteligente y basado en datos de las aplicaciones sin duplicar datos ni dividir arquitecturas.
Abordando mitos comunes
- Todas las bases de datos son relacionales
Existen muchas bases de datos no relacionales que no siguen el modelo relacional (almacenamiento de datos en tablas y uso de SQL para definir y consultar relaciones). - Las bases de datos relacionales solo utilizan SQL
La mayoría de las bases de datos relacionales utilizan SQL como lenguaje principal. SQL se creó para el modelo relacional, pero algunas bases de datos utilizan otros lenguajes relacionales, como Quel, Tutorial D, Rel y Datalog. - Las bases de datos relacionales están obsoletas
Las bases de datos relacionales están lejos de estar obsoletas. Siguen siendo inigualables para datos complejos y estructurados, y siguen siendo la columna vertebral de los sistemas críticos actuales. Y SQL sigue siendo uno de los lenguajes más utilizados. Hoy en día, las bases de datos relacionales coexisten con NoSQL, data lakes y lakehouses a medida que los casos de uso de datos continúan evolucionando.
Conclusión
Las bases de datos relacionales con esquemas estructurados que organizan los datos en tablas, filas y columnas, con claves y uniones para una rápida recuperación de datos y transacciones ACID confiables, siguen siendo una arquitectura básica para aplicaciones empresariales críticas y seguras. Con una estructura diseñada para consultas rápidas y confiables, las bases de datos relacionales proporcionan la integridad y la consistencia de los tipos de datos, y puede optimizar el almacenamiento y las consultas para mantener el rendimiento. También pueden coexistir con bases de datos no relacionales en entornos modernos distribuidos de data lake y lakehouse.
La estandarización y madurez de los SGBDR hacen que estén probados para cargas reales y optimizados para transacciones extremadamente refinadas. Arquitecturas modernas como lakebase extienden estas bases relacionales probadas a entornos nativos en la nube, permitiendo que la fiabilidad relacional y el análisis basado en SQL coexistan con el almacenamiento escalable de objetos y el cálculo distribuido.
Recursos adicionales
- Introducción fácil para principiantes que abarca tablas, relaciones y conceptos básicos
- Visión general completa de la arquitectura, las características y las aplicaciones empresariales de RDBMS
- Explicación completa de 1NF a 5NF con ejemplos
- Desglose detallado de atomicidad, consistencia, aislamiento y durabilidad
- Cobertura integral que incluye las reglas y fundamentos teóricos de Codd
- Lakehouse: una nueva generación de plataformas abiertas que unifican el almacenamiento de datos y la analítica avanzada
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.