¿Qué son los pipelines de ML?
Descubra cómo las canalizaciones de ML automatizan y agilizan el flujo de trabajo de aprendizaje automático desde el preprocesamiento de datos hasta la validación del modelo.
- Comprenda qué son las canalizaciones de aprendizaje automático (ML) y cómo conectan el preprocesamiento, la extracción de características, el ajuste de modelos y la validación en un flujo de trabajo unificado.
- Aprenda la diferencia entre transformadores y estimadores, los dos tipos principales de etapas de una canalización.
- Explore cómo las canalizaciones de Spark ML permiten un aprendizaje automático escalable y distribuido con creación y ajuste de canalizaciones nativas.
Normalmente, al ejecutar algoritmos de aprendizaje automático, se realiza una secuencia de tareas que incluye etapas de preprocesamiento, extracción de características, ajuste del modelo y validación. Por ejemplo, clasificar documentos de texto podría implicar la segmentación y limpieza del texto, la extracción de características y el entrenamiento de un modelo de clasificación con validación cruzada. Aunque hay muchas bibliotecas que podemos usar para cada etapa, conectar todo no es tan fácil como parece, especialmente con conjuntos de datos a gran escala. La mayoría de las bibliotecas de ML no están diseñadas para la computación distribuida o no proporcionan soporte nativo para la création y el ajuste de pipelines.
La guía de IA agéntica para la empresa

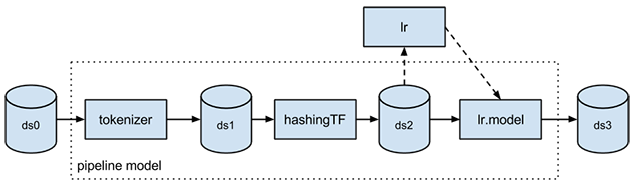
Las canalizaciones de ML son una API de alto nivel para MLlib que se encuentra en "spark.ml" paquete. Una canalización consiste en una secuencia de etapas. Existen dos tipos básicos de etapas de pipeline: Transformer y Estimator. Un Transformer toma un conjunto de datos como entrada y produce un conjunto de datos aumentado como salida. P. ej., un tokenizer es un Transformer que transforma un conjunto de datos con texto en un conjunto de datos con palabras tokenizadas. Un Estimator primero debe ajustarse en el conjunto de datos de entrada para producir un modelo, que es un Transformer que transforma el conjunto de datos de entrada. P. ej., la regresión logística es un Estimator que se entrena con un conjunto de datos con etiquetas y atributos y produce un modelo de regresión logística.
Recursos adicionales
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.