¿Qué son las aplicaciones Spark?
Aprenda cómo los procesos del controlador y del ejecutor trabajan juntos para ejecutar cálculos distribuidos en un clúster
- Comprenda la arquitectura de las aplicaciones Spark, incluyendo cómo los procesos controladores gestionan la lógica de la aplicación y coordinan el trabajo en todo el clúster.
- Aprenda cómo los procesos ejecutores ejecutan las tareas asignadas e informan del estado de los cálculos al controlador.
- Explore cómo los administradores de clústeres como YARN, Mesos y Spark independiente asignan recursos para múltiples aplicaciones concurrentes.
Las aplicaciones de Spark se componen de un proceso de controlador y un conjunto de procesos de ejecutor. El proceso del driver ejecuta tu función main(), se encuentra en un nodo del clúster y es responsable de tres cosas: mantener la información sobre la aplicación de Spark, responder al programa o a la entrada de un usuario, y analizar, distribuir y programar el trabajo entre los ejecutores (que se definirán en breve). El proceso del driver es absolutamente esencial: es el corazón de una aplicación de Spark y mantiene toda la información relevante durante el ciclo de vida de la aplicación. Los ejecutores son responsables de ejecutar el trabajo que el driver les asigna. Esto significa que cada ejecutor es responsable de solo dos cosas: ejecutar el código que le asigna el driver e informar el estado del cómputo, en ese ejecutor, de vuelta al nodo del driver.
La guía de IA agéntica para la empresa

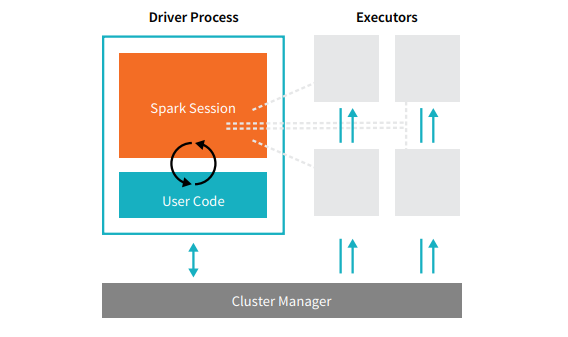
El administrador del clúster controla las máquinas físicas y asigna recursos a las aplicaciones de Spark. Este puede ser uno de varios administradores de clúster principales: el administrador de clúster independiente de Spark, YARN o Mesos. Esto significa que puede haber varias aplicaciones de Spark ejecutándose en un clúster al mismo tiempo. Hablaremos más a fondo sobre los administradores de clúster en la Parte IV: Aplicaciones de producción de este libro. En la ilustración anterior vemos a la izquierda nuestro driver y a la derecha los cuatro ejecutores. En este diagrama, eliminamos el concepto de nodos de clúster. El usuario puede especificar cuántos ejecutores deben estar en cada nodo a través de las configuraciones. [glossary-cta]
Recursos adicionales
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.