¿Qué es el aprendizaje automático operativo?
Implementación de modelos de ML en producción para realizar predicciones en tiempo real sobre datos en vivo, lo que requiere infraestructura para el servicio, la supervisión, el reentrenamiento y la integración.
- Los patrones de implementación incluyen API REST para predicciones síncronas, puntuación por lotes para inferencia sin conexión, implementación en el borde de la aplicación en dispositivos y modelos integrados en aplicaciones que equilibran la latencia, el rendimiento y las limitaciones de recursos.
- La monitorización rastrea la precisión de las predicciones, las métricas de rendimiento del modelo, la desviación de datos que detecta cambios en la distribución, la desviación de conceptos que identifica cambios en las relaciones, la utilización de recursos y los KPI empresariales que miden el impacto del modelo.
- Las prácticas de MLOps abarcan pipelines de CI/CD para la implementación de modelos, activadores de reentrenamiento automatizados, marcos de pruebas A/B, implementaciones canarias que minimizan el riesgo, capacidades de reversión y procedimientos de respuesta a incidentes ante fallos del modelo.
Autor: Kevin Stumpf, Cofundador y CTO
En 2015, cuando comenzamos a implementar la plataforma de aprendizaje automático de Uber, Michelangelo, notamos un patrón interesante: el 80 % de los modelos de ML lanzados en la plataforma impulsaban casos de uso de aprendizaje automático operativo, que impactan directamente en la experiencia del usuario final (pasajeros y conductores de Uber). Solo el 20 % fueron casos de uso de aprendizaje automático analítico, que potencian la toma de decisiones analíticas.
La proporción entre ML operativo y ML analítico que observamos era exactamente opuesta a la forma en que la mayoría de las demás empresas aplicaban el ML en la práctica: el ML analítico era el rey. En retrospectiva, la adopción masiva del ML operativo por parte de Uber no es una gran sorpresa: Michelangelo hizo que fuera extremadamente fácil implementar el ML operativo, y la empresa tenía una larga lista de casos de uso de alto impacto. Hoy, siete años después, la dependencia de Uber del ML operativo solo aumentó: sin él, habría precios de viajes poco rentables, terribles predicciones de tiempo estimado de llegada y cientos de millones de dólares perdidos por fraude. En resumen, sin el ML operativo, la empresa se paralizaría.
El aprendizaje automático operativo fue clave para el éxito de Uber, y durante mucho tiempo parecía algo que solo los gigantes tecnológicos podían lograr. Pero la buena noticia es que muchas cosas han cambiado en los últimos siete años. Existen tecnologías y tendencias nuevas que permiten a cualquier empresa pasar de usar principalmente ML analítico a usar ML operativo, y tenemos algunos consejos para quienes estén interesados en hacerlo. Profundicémonos en el tema.
ML operacional vs. ML analítico
El aprendizaje automático operativo es cuando una aplicación utiliza un modelo de ML para tomar decisiones de manera autónoma y continua que impactan el negocio en tiempo real. Estas aplicaciones son de misión crítica y se ejecutan “en línea” en producción en la pila operacional de una empresa.
Algunos ejemplos comunes son los sistemas de recomendación, la clasificación de búsquedas, la fijación dinámica de precios, la detección de fraudes y la aprobación de solicitudes de préstamos.
El hermano mayor del ML operativo en el mundo “offline” es el aprendizaje automático analítico. Son aplicaciones que ayudan a los usuarios empresariales a tomar mejores decisiones gracias al aprendizaje automático. Las aplicaciones analíticas de ML se encuentran en la pila analítica de la empresa y, por lo general, se incorporan directamente a informes, paneles de control y herramientas de inteligencia empresarial.
Los ejemplos comunes incluyen pronóstico de ventas, predicciones de abandono y segmentación de clientes.
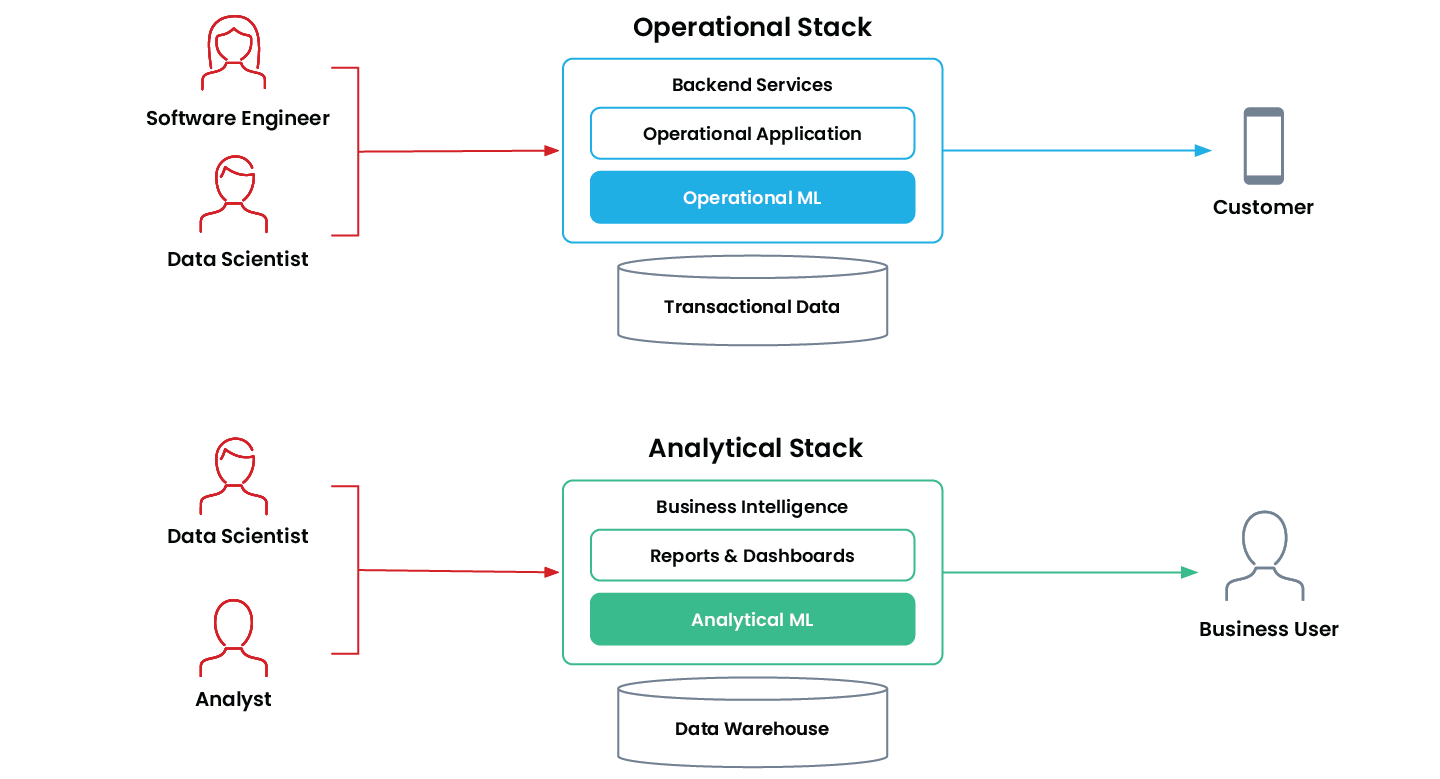
Las organizaciones utilizan ML operativo y ML analítico para diferentes propósitos, y cada una de ellas tiene diferentes requerimientos técnicos.
| ML analítico | ML operativo | |
|---|---|---|
| Automatización de decisiones | Intervención humana | Totalmente autónomo |
| Velocidad de decisión | Velocidad humana | Tiempo real |
| Optimizado para | Procesamiento por lotes a gran escala | Baja latencia y alta disponibilidad |
| Audiencia principal | Usuario empresarial interno | Cliente |
| Poderes | Informes y paneles | Aplicaciones de producción |
| Ejemplos | Previsión de ventas Puntuación de clientes potenciales Segmentación de clientes Predicciones de abandono | Recomendaciones de productos Detección de fraude Predicción de tráfico Precios en tiempo real |
Características del ML analítico frente al ML operativo
Aprendizaje automático operativo en la práctica
Analicemos un ejemplo más concreto de una operación de aprendizaje automático en el mundo real de Uber Eats. Cuando abres la app, te recomienda una lista de restaurantes y sugiere cuánto tiempo tendrías que esperar hasta que el pedido llegue a tu puerta. Lo que parece simple en la aplicación es en realidad bastante complejo en segundo plano:
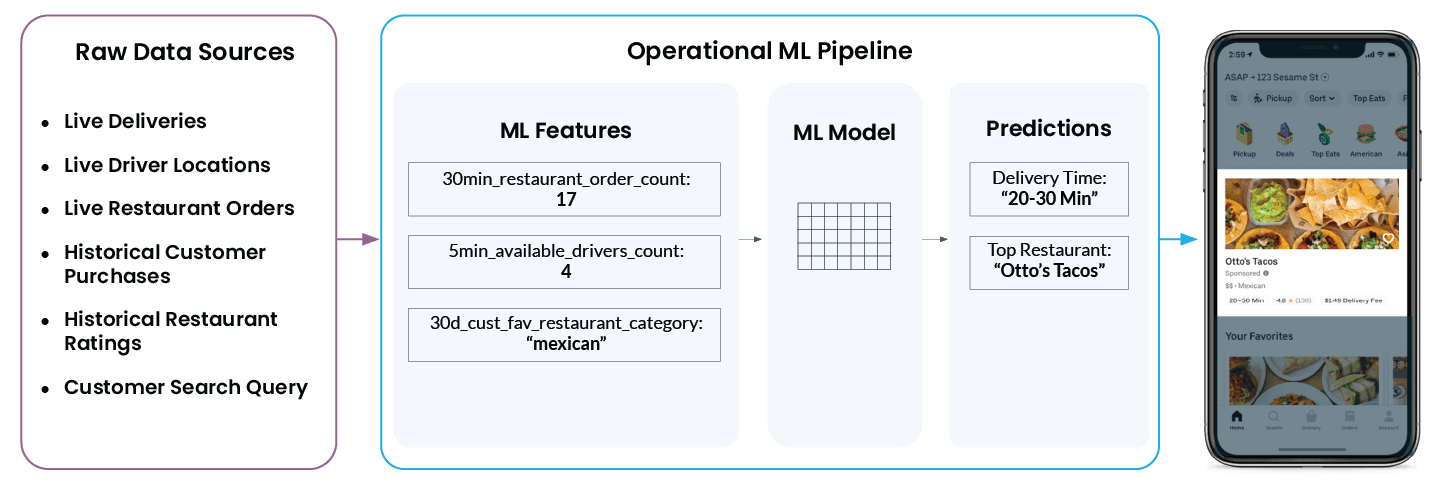
Para que finalmente aparezcan “Otto’s Tacos” y “20-30 min” en la aplicación, la plataforma de ML de Uber necesita examinar una amplia gama de datos de varias fuentes de datos sin procesar:
- ¿Cuántos conductores hay ahora en las inmediaciones del restaurante? ¿Están entregando un pedido o están disponibles para el próximo envío?
- ¿Qué tan ocupada está la cocina del restaurante en estos momentos? Cuantos más pedidos esté procesando actualmente un restaurante, más tardará en comenzar a trabajar en un nuevo pedido.
- ¿Qué restaurantes son los que el cliente calificó mejor y peor en el pasado?
- ¿Qué cocina, si la hay, está buscando activamente el usuario en este momento?
- Y… ¿cuál es la ubicación actual del usuario?
La plataforma de características de Michelangelo convierte estos datos en funcionalidades de ML. Estas son las se�ñales con las que se entrena un modelo y que utiliza para realizar predicciones en tiempo real. Por ejemplo, ‘num_orders_last_30_min’ se utiliza como una característica de entrada para predecir el tiempo de entrega, que finalmente aparecerá en tu aplicación móvil.
Los pasos que se establecieron anteriormente, que convierten los datos sin procesar de una variedad de diferentes fuentes de datos en características, y las características en predicciones, son comunes en todos los casos de uso de aprendizaje automático operativo. Ya sea que un sistema intente detectar fraudes con tarjetas de crédito, predecir la tasa de interés del préstamo para un auto, sugerir un artículo de periódico en la sección de asuntos internacionales o recomendar el mejor juguete para un niño de 2 años, los retos técnicos son idénticos. Y es exactamente este punto en común técnico fundamental lo que nos permitió construir una plataforma central para todos los casos de uso de ML operativos.
La guía de IA agéntica para la empresa

Las tendencias que permiten el aprendizaje automático operativo
Uber estaba preparado para aprovechar el ML operativo porque construyó toda su pila tecnológica sobre una arquitectura de datos moderna y principios modernos. En los últimos años, hemos visto una modernización similar en las afueras de Silicon Valley:
Los datos históricos se conservan casi indefinidamente
Los costos de almacenamiento de datos se desplomaron en los últimos años. Como resultado, las empresas pudieron recopilar, adquirir y almacenar información sobre cada punto de contacto con los clientes. Esto es crucial para ML: la capacitación de un buen modelo requiere una gran cantidad de datos históricos. Y sin datos, no hay aprendizaje automático.
Los silos de datos se están rompiendo
Desde el primer día, Uber centralizó prácticamente todos sus datos en su sistema de archivos distribuido basado en Hive. El almacenamiento centralizado de datos (o, como alternativa, el acceso centralizado a almacenes de datos descentralizados) es importante porque permite a los científicos de datos, que entrenan los modelos de ML, saber qué datos están disponibles, dónde encontrarlos y cómo acceder a ellos. La mayoría de las empresas aún no han centralizado completamente todos sus datos (acceso). Sin embargo, las tendencias arquitectónicas como The Modern Data Stack acercaron mucho más el sueño del científico de datos de democratizar el acceso a los datos a la realidad.
Los datos en tiempo real están disponibles mediante las transmisiones
En Uber, tuvimos la suerte de tener un “sistema nervioso central” para los flujos de datos: Kafka. Muchas señales en tiempo real de servicios y aplicaciones m�óviles se transmiten a través de Kafka. Esto es crucial para el aprendizaje automático operativo.
No se puede detectar el fraude si solo se sabe lo que ocurrió ayer. Necesitas saber qué pasó en los últimos 30 segundos. Los almacenes de datos y data lakes están diseñados para el almacenamiento a largo plazo de datos históricos. Y en los últimos años, fuimos testigos de la adopción masiva de infraestructuras de transmisiones, como Kafka o Kinesis, para proporcionar señales en tiempo real a las aplicaciones.
MLOps permite una iteración rápida
En Uber, los ingenieros individuales tienen la facultad de realizar cambios diarios en el sistema de producción. Este proceso se apoya siguiendo y automatizando los principios de DevOps. Con Michelangelo, aplicamos esos principios al ML operativo antes de que el proceso se denominara MLOps 🙂. Para nosotros era importante que los científicos de datos pudieran entrenar modelos y desplegarlos de manera segura a la producción literalmente en un solo día.
Fuera de Uber y muy lejos de Silicon Valley, vimos un número creciente de adoptantes tempranos que llevan los principios de DevOps y la automatización no solo a su ingeniería de software, sino también a sus equipos de ciencia de datos a través de MLOps. Por supuesto, el ML sigue siendo mucho más doloroso que el software para la mayoría de las empresas, por razones que describo en este blog. Pero estoy convencido de que la industria se dirige de forma constante hacia un futuro en el que el típico científico de datos en una organización Fortune 500 puede iterar sobre un modelo operativo de ML varias veces al día.
Así es como se ve una arquitectura de datos moderna que permite el ML operativo:
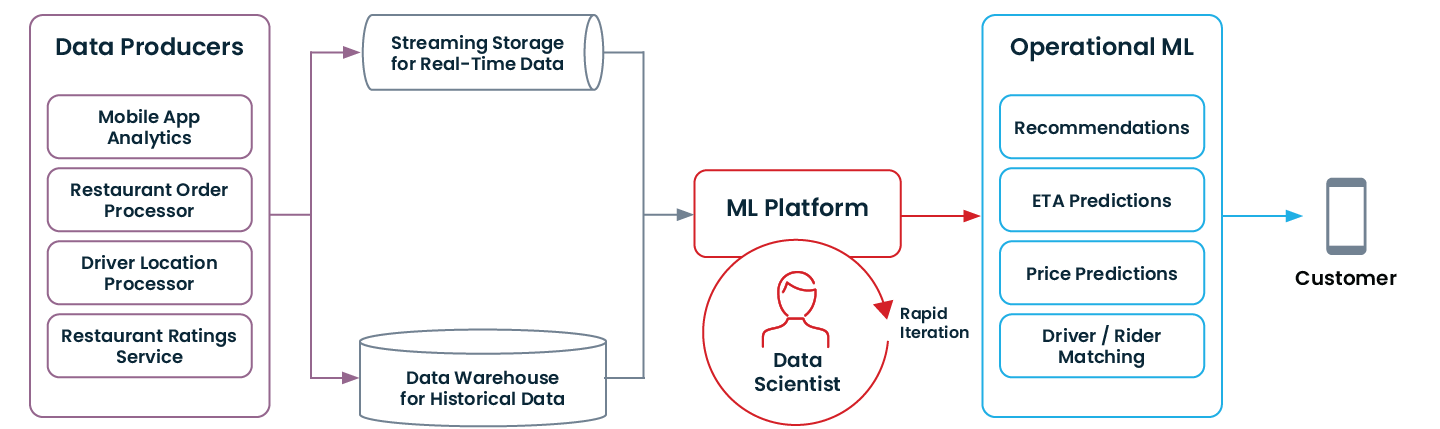
Si tu organización pasó por algunas de las modernizaciones mencionadas anteriormente (o comenzó con ellas desde cero), es posible que estés listo para comenzar con el ML operativo.
Introducción al aprendizaje automático operativo
En 2013, Uber no utilizaba el aprendizaje automático en producción. Actualmente, se encuentran en producción decenas de miles de modelos. Ese cambio no sucedió de la noche a la mañana.
Si buscas aprovechar el ML operativo en tu organización, te recomiendo seguir los siguientes pasos:
Elige un caso de uso que sea adecuado para el aprendizaje automático
No todos los problemas se pueden resolver con ML. Calificadores de un problema que puede ser adecuado para ML:
- Tu sistema está tomando muchas decisiones muy similares y repetidas (al menos decenas de miles)
- Tomar la decisión correcta no es trivial
- Un poco después de tomar la decisión, tienes una forma de determinar si fue una buena o mala decisión.
Si estos elementos son ciertos, una aplicación de aprendizaje automático puede tomar decisiones, aprender de ellas y mejorar continuamente.
Elige un caso de uso que realmente importe
Como se mencionó antes, el camino para poner el primer modelo en producción es difícil. Si los futuros beneficios de tu primera aplicación de aprendizaje automático no son muy prometedores, será muy fácil rendirse cuando las cosas se pongan difíciles. Las prioridades cambiarán, los líderes pueden impacientarse y el esfuerzo no perdurará. Elige un caso de uso con alto potencial.
Empodera a un equipo pequeño y minimiza la cantidad de partes interesadas para tu primer modelo
La probabilidad de fracaso de un proyecto aumenta con la cantidad de traspasos implicados en el entrenamiento y despliegue de un modelo. Idealmente, empieza con un equipo muy pequeño de dos o tres personas que tengan acceso a todos los datos necesarios, sepan capacitar un modelo sencillo y estén lo suficientemente familiarizados con tu pila de producción como para poner una aplicación en producción.
Los ingenieros de ML son los más adecuados para allanar el camino, dado que generalmente tienen una combinación rara de habilidades de ingeniería de datos, ingeniería de software y ciencia de datos. Así es también como debe escalar los equipos de aprendizaje automático, con pequeños grupos de expertos en ML integrados en los equipos de productos.
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.