Lagos de datos en Azure
Fuente de datos completa y autorizada para potenciar tu arquitectura lakehouse
¿Qué es un lago de datos?
Ejecuta tus cargas de trabajo de datos, analítica e IA en una plataforma nativa de la nube, simple, abierta y colaborativa que se integra fácilmente con tus herramientas de seguridad y gestión, y que te permite extender tus políticas de gobernanza existentes para mayor tranquilidad y control.

¿Qué es un lago de datos de Azure?
Un lago de datos de Azure incluye almacenamiento de datos escalable en la nube y servicios de analítica. Azure Data Lake Storage permite a las organizaciones almacenar datos de cualquier tamaño, formato y velocidad para una amplia variedad de casos de uso en procesamiento, analítica y ciencia de datos. Cuando se usa con otros servicios de Azure, como Azure Databricks, Azure Data Lake Storage es una forma mucho más rentable de almacenar y recuperar datos en toda tu organización.
Tanto si tus datos son grandes como pequeños, rápidos o lentos, estructurados o no estructurados, Azure Data Lake se integra con la identidad, la administración y la seguridad de Azure para simplificar la gestión y la gobernanza de los datos. Azure Storage cifra automáticamente tus datos, y Azure Databricks proporciona herramientas para protegerlos y satisfacer las necesidades de seguridad y cumplimiento normativo de tu organización.

¿Por qué necesitas un lago de datos de Azure?
Los lagos de datos tienen un formato abierto, lo que permite a los usuarios evitar quedar atrapados en un sistema propietario como un almacén de datos. Los estándares y formatos abiertos se han vuelto cada vez más importantes en las arquitecturas de datos modernas. Los lagos de datos también son altamente duraderos y de bajo costo debido a su capacidad para escalar y aprovechar el almacenamiento de objetos. Además, la analítica avanzada y el aprendizaje automático sobre datos no estructurados son algunas de las prioridades estratégicas más importantes para las empresas hoy en día. La capacidad única de ingerir datos sin procesar en una variedad de formatos, estructurados, no estructurados y semiestructurados, junto con los otros beneficios mencionados, hace que un lago de datos sea la opción clara para el almacenamiento de datos.
Cuando se les da una arquitectura adecuada, los lagos de datos proporcionan la siguiente capacidad:
- Potencian la ciencia de datos y el aprendizaje automático.
- Centralizan, consolidan y catalogan tus datos.
- Integre rápidamente y sin problemas diversas fuentes y formatos de datos
- Democratizan tus datos al ofrecerles a los usuarios herramientas de autoservicio.
¿Cuál es la diferencia entre un lago de datos de Azure y un almacén de datos de Azure?
Un lago de datos es una ubicación central que almacena una gran cantidad de datos en su formato nativo y sin procesar, además de proporcionar una forma de organizar grandes volúmenes de datos muy diversos. En comparación con un almacén de datos jerárquico, que almacena datos en archivos o carpetas, un lago de datos utiliza una arquitectura plana para almacenar los datos. Los lagos de datos generalmente se configuran en un clúster de hardware básico escalable. Es por ello por lo que puedes almacenar datos sin procesar en el lago en caso de que sean necesarios en el futuro, sin preocuparte por el formato, el tamaño o la capacidad de almacenamiento de los datos.
Además, los clústeres de lagos de datos pueden existir en las instalaciones o en la nube. Históricamente, el término "lago de datos" se asociaba a menudo con el almacenamiento de objetos orientado a Hadoop, pero hoy en día el término generalmente se refiere a la categoría más amplia de almacenamiento de objetos. El almacenamiento de objetos almacena datos con etiquetas de metadatos y un identificador único, lo que facilita la localización y recuperación de datos en todas las regiones y mejora el rendimiento. Databricks Lakehouse Platform pone todos los datos de tu lago de datos a disposición para cualquier cantidad de casos de uso basados en datos.

¿Por qué usar el formato Delta Lake para tu lago de datos en Azure?
Aquí tienes cinco razones clave para convertir lagos de datos de Apache Parquet, CSV, JSON y otros formatos al formato Delta Lake:
- Evitar la corrupción de datos
- Consultas más rápidas
- Aumentar la vigencia de los datos
- Reproducir modelos de ML
- Logra el cumplimiento
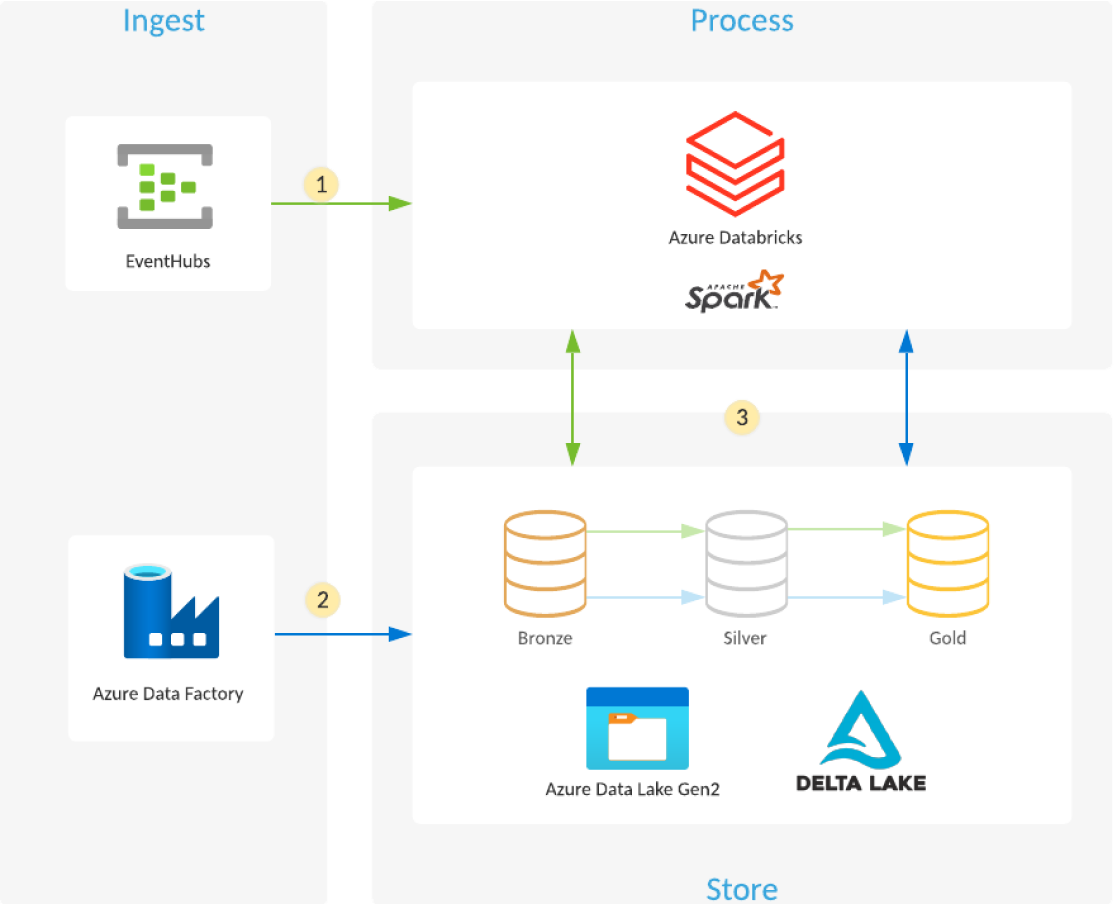
¿Cómo se construye un lago de datos usando Azure Databricks y Azure Data Lake Storage?
Delta Lake administrado en Azure Databricks ofrece una capa de confiabilidad que te permite gestionar, analizar y extraer valor de tu lago de datos en la nube.
- Azure Databricks lee datos de transmisión desde colas de eventos, como Azure Event Hubs, Azure IoT Hub o Kafka, y carga los eventos sin procesar en las tablas y carpetas optimizadas y comprimidas de Delta Lake (capa Bronce) que se almacenan en Azure Data Lake Storage.
- Los pipelines de Azure Data Factory, programados o activados, copian datos de diferentes fuentes en su formato sin procesar a Azure Data Lake Storage. Auto Loader en Azure Databricks procesa los archivos a medida que llegan y los carga en tablas y carpetas optimizadas y comprimidas de Delta Lake (capa Bronce) que se almacenan en Azure Data Lake Storage.
- Las tareas de Azure Databricks, ya sean de transmisión, programados o activados, leen las operaciones nuevas de la capa Bronce y luego las unen, limpian, transforman y agregan antes de usar operaciones ACID (INSERT, UPDATE, DELETE, MERGE) para cargarlas en conjuntos de datos seleccionados (capas Plata y Oro) que se almacenan en Delta Lake en Azure Data Lake Storage.
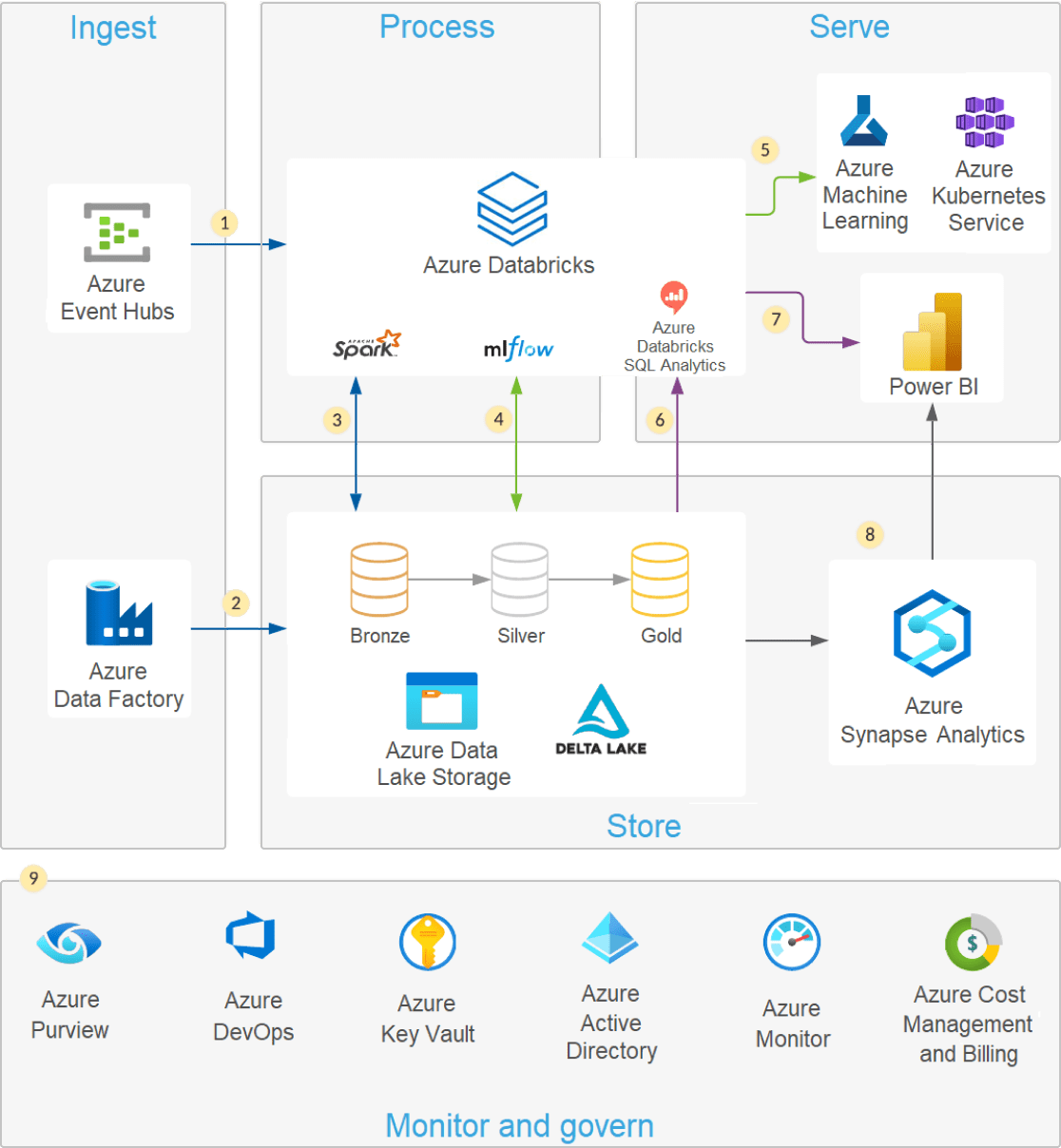
Arquitectura moderna de lagos de datos
Una arquitectura lakehouse moderna que combina el rendimiento, la confiabilidad y la integridad de los datos de un almacén con la flexibilidad, la escala y el soporte para datos no estructurados disponibles en un lago de datos.
Los lagos de datos modernos aprovechan la elasticidad de la nube para almacenar cantidades prácticamente ilimitadas de datos "tal cual están", sin necesidad de imponer un esquema o una estructura. El lenguaje de consulta estructurada (SQL) es un potente lenguaje de consulta para explorar tus datos y descubrir insights valiosos. Delta Lake es una capa de almacenamiento de código abierto que brinda confiabilidad a los lagos de datos con operaciones ACID, manejo escalable de metadatos y procesamiento unificado de datos de transmisión y por lotes. Delta Lake es totalmente compatible y aporta confiabilidad a tu lago de datos existente.
Puedes consultar fácilmente tu lago de datos usando SQL y Delta Lake con Azure Databricks. Delta Lake te permite ejecutar consultas SQL tanto en tus datos de transmisión como en tus datos por lotes sin moverlos ni copiarlos. Azure Databricks proporciona beneficios adicionales al trabajar con Delta Lake para proteger tu lago de datos a través de la integración nativa con servicios en la nube, ofrece un rendimiento óptimo y ayuda a auditar y solucionar problemas de pipelines de datos.
- Delta Lake se integra con almacenamiento escalable en la nube o HDFS para ayudar a eliminar los silos de datos.
- Explora tus datos mediante consultas SQL y una capa de operaciones compatible con ACID directamente en tu lago de datos.
- Aprovecha las "tablas Medallion" de las capas Oro, Plata y Bronce para consolidar y simplificar la calidad de los datos en tus pipelines de datos y flujos de trabajo de analítica.
- Usa la función de viaje en el tiempo de Delta Lake para ver cómo cambiaron tus datos con el paso del tiempo.
- Azure Databricks optimiza el rendimiento con funcionalidades como la caché de Delta, la compactación de archivos y la omisión de datos.