Almacenamiento de datos inteligente en Databricks - Clonado
Esta arquitectura de referencia muestra cómo Databricks Data Intelligence Platform permite el data warehousing y BI modernos combinando ingesta de streaming y batch, almacenamiento gobernado, analítica SQL escalable y AI integrada en un lakehouse.
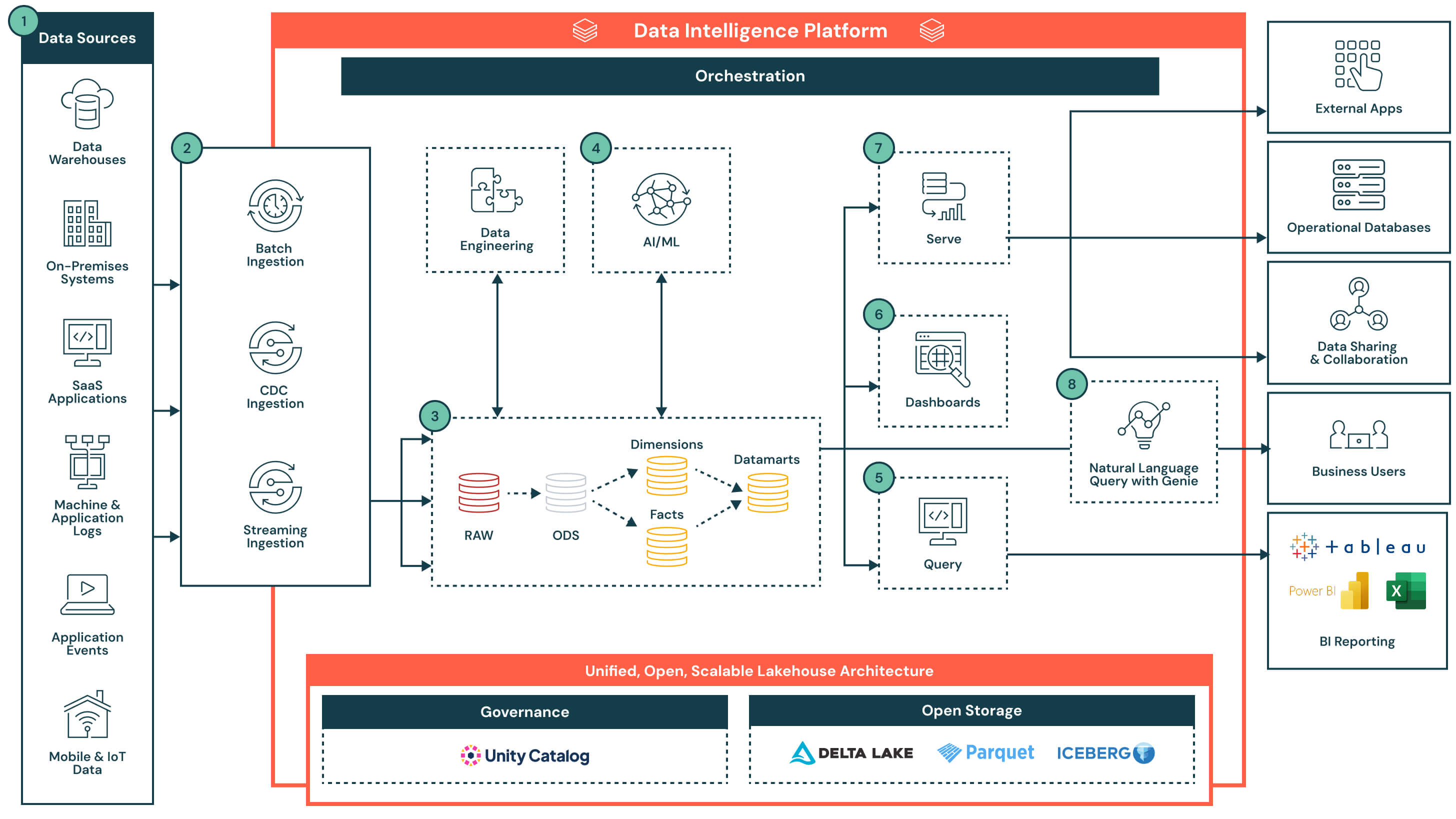
Resumen de la arquitectura
La arquitectura admite informes tradicionales, paneles en tiempo real, modelado predictivo y análisis de autoservicio, todo ello cumpliendo con los estándares empresariales de seguridad, gobernanza y rendimiento.
Esta solución demuestra cómo Databricks Data Intelligence Platform, con la tecnología de Databricks Lakehouse, ayuda a las organizaciones a modernizar su estrategia de almacenamiento de datos al tiempo que satisface las necesidades tanto de los equipos de datos como de las partes interesadas del negocio.
La arquitectura comienza con un lakehouse abierto y gobernado, administrado por Unity Catalog. Los datos se ingieren desde una variedad de sistemas (incluidas bases de datos operativas, aplicaciones SaaS, flujos de eventos y sistemas de archivos) y se depositan en una capa de almacenamiento central. La inteligencia de datos de la plataforma impulsa todo, desde análisis ETL y SQL hasta paneles y casos de uso de AI. Al admitir un acceso flexible a través de SQL, herramientas de BI y consultas en lenguaje natural, la plataforma acelera la entrega de productos de datos y hace que la información sea accesible en toda la organización.
Casos de uso
Casos de uso técnicos
- Ingesta de datos estructurados, no estructurados, por lotes y en streaming desde diversas fuentes
- Creación de canalizaciones ETL declarativas y robustas
- Modelado de hechos, dimensiones y data marts mediante una arquitectura de medallón
- Ejecución de consultas SQL de alta concurrencia para informes y paneles
- Integración de los resultados de ML directamente en el almacén de datos para su uso posterior
Casos de uso empresarial
- Entrega de paneles en tiempo real sobre métricas de ventas, operaciones o clientes
- Facilitación de la exploración ad hoc a través de interfaces de lenguaje natural como Genie
- Soporte para casos de uso predictivos como el pronóstico de la demanda y el modelado de abandono
- Uso compartido de productos de datos gobernados entre departamentos o con socios
- Provisión de información rápida y confiable para los equipos de finanzas, marketing y producto
Capacidades clave con inteligencia de datos
El componente de inteligencia de datos de esta arquitectura hace que la plataforma sea más inteligente, adaptable y fácil de usar para diferentes perfiles y cargas de trabajo. Aplica AI y reconocimiento de metadatos en todo el sistema para simplificar las experiencias y automatizar la toma de decisiones:
- Interfaz de lenguaje natural (Genie): Comprende el contexto empresarial y permite a los usuarios hacer preguntas sobre los datos en un lenguaje sencillo
- Reconocimiento semántico: Reconoce las relaciones entre tablas, columnas y patrones de uso para sugerir uniones (joins), filtros o cálculos
- Optimización predictiva: Ajusta continuamente el rendimiento de las consultas y la asignación de cómputo en función de las cargas de trabajo históricas
- Gobernanza unificada: Etiqueta, clasifica y realiza un seguimiento del uso de los activos de datos, lo que hace que el descubrimiento sea más intuitivo y seguro
- Capacidad clave: Una plataforma autooptimizada que se adapta a sus datos y usuarios
- Diferenciador: La inteligencia de datos está integrada en la ingesta, la consulta, la gobernanza y la visualización, no añadida de forma externa
Flujo de datos con capacidades clave y diferenciadores
- Fuentes de datos: Los datos se almacenan en una amplia variedad de sistemas, incluidas aplicaciones empresariales (por ejemplo, SAP, Salesforce), bases de datos, dispositivos IoT, registros de aplicaciones y API externas. Estas fuentes pueden producir datos estructurados, semiestructurados o no estructurados.
- Ingesta de datos: Introduce datos a través de trabajos por lotes, captura de datos modificados (CDC) o streaming. Estas canalizaciones alimentan la arquitectura de lakehouse casi en tiempo real o en intervalos programados, según el sistema de origen y el caso de uso.
- Diferenciador clave: Ingesta unificada para todas las modalidades (por lotes, streaming y CDC) sin necesidad de infraestructura o canalizaciones independientes
- Transformación de datos, ETL, canalizaciones declarativas: Una vez ingeridos, los datos se transforman a través de la arquitectura de medallón y se perfeccionan progresivamente desde datos brutos hasta datos depurados.
- De la zona Raw a la zona Bronze: Datos ingeridos desde sistemas de origen externos donde las estructuras de esta capa corresponden a las estructuras de las tablas del sistema de origen "tal cual", sin transformación ni actualizaciones de los datos
- De la zona Bronze a la zona Silver: Estandarizar y limpiar los datos entrantes
- De la zona Silver a la zona Gold: Aplicar lógica empresarial para crear modelos reutilizables
- Hechos y dimensiones → data marts: Agregar y depurar datos para análisis posteriores
- Diferenciador clave: Canalizaciones declarativas de nivel de producción con linaje, observabilidad y evolución de esquemas integrados
- Datos depurados para casos de uso de AI: Los datos depurados de los data marts se pueden utilizar para entrenar o aplicar modelos de aprendizaje automático. Estos modelos admiten casos de uso como el pronóstico de la demanda, la detección de anomalías y la puntuación de clientes.
- Los resultados del modelo se almacenan junto con los datos tradicionales del almacén para un fácil acceso a través de SQL o paneles
- Los resultados se pueden actualizar de forma programada o puntuar en tiempo real, según los requisitos
- Diferenciador clave: Cargas de trabajo de análisis y AI ubicadas en la misma plataforma, sin necesidad de mover datos. Los resultados del modelo se tratan como activos gobernados nativos y consultables.
- Herramientas de informes de BI basadas en consultas: Databricks Lakehouse admite consultas de alta concurrencia y baja latencia mediante computación serverless, y se conecta fácilmente con las herramientas de BI más populares.
- Editor de consultas integrado e historial de consultas
- Las consultas devuelven resultados gobernados y actualizados desde data marts o salidas de modelos enriquecidos
- Diferenciador clave: Databricks Lakehouse permite que las herramientas de BI consulten los datos directamente, sin replicación, lo que reduce la complejidad, evita costos de licencia adicionales y disminuye el TCO general. Combinado con la computación serverless y la optimización inteligente, ofrece un rendimiento de nivel de data warehouse con un ajuste mínimo.
- Dashboards: Se pueden crear directamente en Databricks o en herramientas externas de BI como Power BI o Tableau. Los usuarios pueden describir los elementos visuales en lenguaje natural y el Databricks Assistant generará los gráficos correspondientes, que luego se pueden perfeccionar mediante una interfaz de apuntar y hacer clic.
- Crear visualizaciones utilizando entradas de lenguaje natural
- Modificar y explorar dashboards de forma interactiva con filtros y desgloses
- Publicar y compartir de forma segura dashboards en toda la organización, incluso con usuarios fuera del espacio de trabajo de Databricks
- Diferenciador clave: Ofrece una experiencia low-code y asistida por IA para crear y explorar dashboards con datos gobernados en tiempo real
- Servicio de datos curados: Una vez refinados, los datos se pueden servir más allá de los dashboards:
- Compartidos con aplicaciones descendentes o bases de datos operativas para la toma de decisiones transaccionales
- Utilizados en notebooks colaborativos para análisis
- Distribuidos a través de Delta Sharing a socios, equipos o consumidores externos con una gobernanza unificada
- Consulta en lenguaje natural (NLQ): Los usuarios de negocios pueden acceder a datos gobernados utilizando lenguaje natural. Esta experiencia conversacional, impulsada por IA generativa, permite a los equipos ir más allá de los dashboards estáticos y obtener información de autoservicio en tiempo real. NLQ traduce la intención del usuario a SQL aprovechando la semántica y los metadatos de la organización de Unity Catalog.
- Admite preguntas ad hoc, interactivas y en tiempo real que no están predefinidas en los dashboards
- Se adapta de forma inteligente a la evolución de la terminología y el contexto empresarial a lo largo del tiempo
- Aprovecha la gobernanza de datos y los controles de acceso existentes a través de Unity Catalog
- Proporciona auditabilidad y trazabilidad de las consultas en lenguaje natural para el cumplimiento y la transparencia
- Diferenciador clave: Se adapta continuamente a la evolución de los conceptos empresariales, ofreciendo respuestas precisas y conscientes del contexto sin necesidad de tener experiencia en SQL
- Capacidades de la plataforma: Gobernanza, rendimiento, orquestación y almacenamiento abierto: La arquitectura se sustenta en un conjunto de capacidades nativas de la plataforma que admiten la seguridad, la optimización, la automatización y la interoperabilidad a lo largo de todo el ciclo de vida de los datos. Capacidades clave:
- Gobernanza: Unity Catalog proporciona control de acceso centralizado, linaje, auditoría y clasificación de datos en todas las cargas de trabajo
- Rendimiento: El motor Photon, el almacenamiento en caché inteligente y la optimización adaptada a la carga de trabajo ofrecen consultas rápidas sin necesidad de realizar ajustes manuales
- Orquestación: La orquestación integrada administra canalizaciones de datos, flujos de trabajo de IA y trabajos programados en cargas de trabajo por lotes y de streaming, con soporte nativo para la gestión de dependencias y el manejo de errores
- Almacenamiento abierto: Los datos se almacenan en formatos abiertos (Delta Lake, Parquet, Iceberg), lo que permite la interoperabilidad entre herramientas, la portabilidad entre plataformas y la durabilidad a largo plazo sin dependencia de un proveedor
- Monitoreo y auditabilidad: Visibilidad de extremo a extremo del rendimiento de las consultas, la ejecución de canalizaciones y el acceso de los usuarios para un mejor control y gestión de costos
- Diferenciador clave: Los servicios a nivel de plataforma están integrados, no superpuestos, lo que garantiza que la gobernanza, la automatización y el rendimiento sean consistentes en todos los flujos de trabajo de datos, nubes y equipos
Recomendado

Arquitectura de referencia

Arquitectura de referencia

Arquitectura de la industria