MLOps: pipeline de extremo a extremo
Tipo de demostración
Tutorial del producto
Duración
A tu propio ritmo
Contenido relacionad
Lo que aprenderás
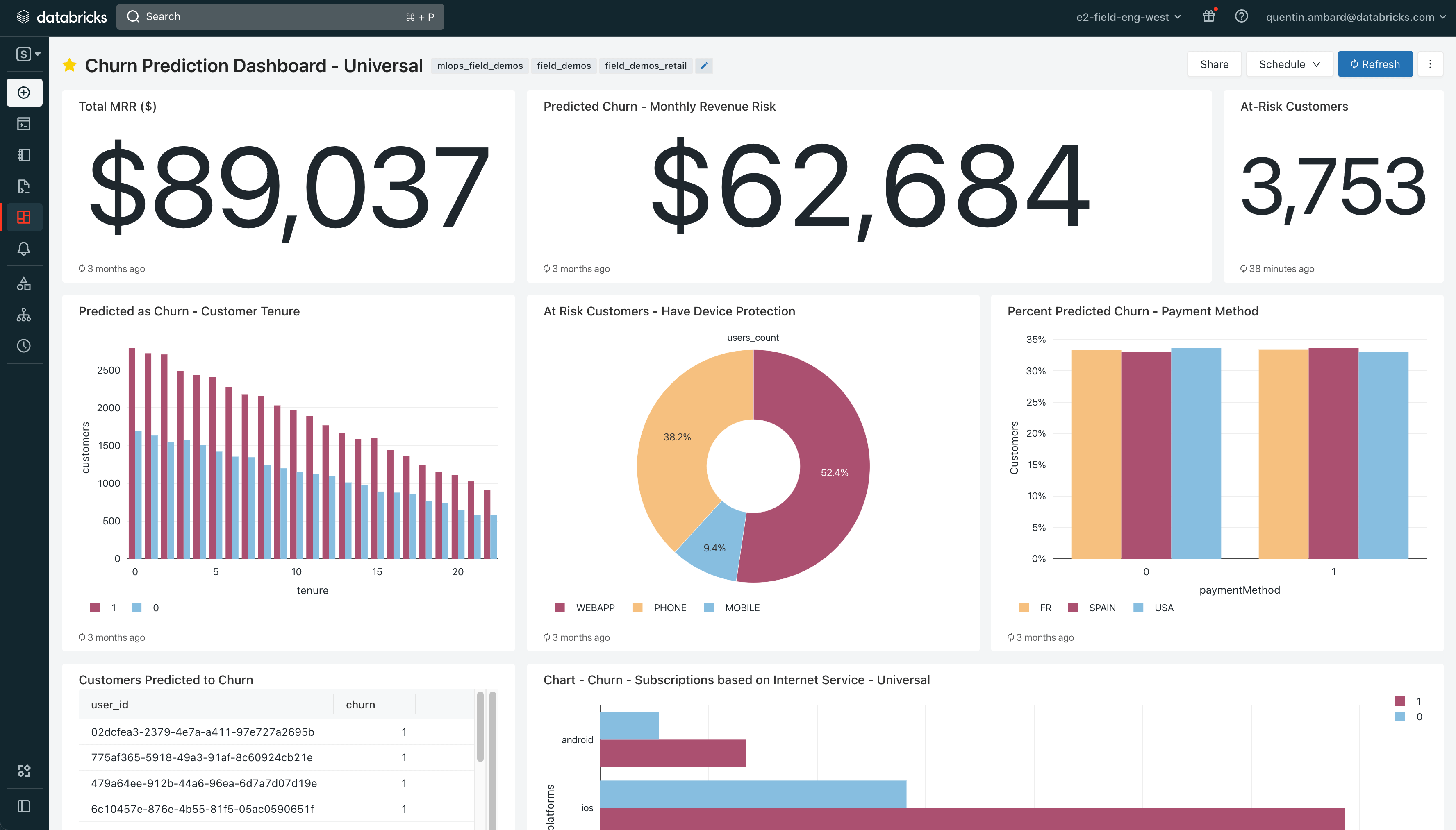
Esta demostración cubre un pipeline de MLOps completo. Le mostraremos cómo se puede aprovechar Databricks Lakehouse para orquestar e implementar modelos en producción, garantizando al mismo tiempo la gobernanza, la seguridad y la robustez.
- Ingerir datos y guardarlos en un feature store
- Cree modelos de ML con AutoML de Databricks
- Configura hooks de MLflow para probar automáticamente tus modelos
- Crear el trabajo de prueba del modelo
- Pase automáticamente los modelos a producción una vez que se validen las pruebas.
- Reentrene su modelo periódicamente para evitar la deriva
Ten en cuenta que esta es una demostración bastante avanzada. Si es nuevo en Databricks y solo quiere aprender sobre ML, le recomendamos que comience con una demostración de ML o una de las demostraciones de Lakehouse.
Para instalar el demo, obtén un espacio de trabajo de Databricks gratuito y ejecuta los siguientes dos comandos en un notebook de Python.
Dbdemos es una biblioteca de Python que instala demos completos de Databricks en sus áreas de trabajo. Dbdemos cargará e iniciará notebooks, canalizaciones de DLT, clústeres, paneles de Databricks SQL, modelos de almacén… Consulte cómo usar dbdemos
Dbdemos se distribuye como un proyecto de GitHub.
Para más detalles, consulte en GitHub el archivo README.md y siga la documentación.
Dbdemos se proporciona tal cual. Consulte la Licencia y el Aviso para obtener más información.
Databricks no ofrece soporte oficial para dbdemos y los recursos asociados.
Si tiene algún problema, abra un ticket y el equipo de la demostración lo revisará en la medida de lo posible.


Estos recursos se instalarán en esta demostración de Databricks: