Técnicas de Modelagem de Data Warehousing e Sua Implementação na Plataforma Lakehouse da Databricks
Usando Data Vaults e Star Schemas no Lakehouse
por Soham Bhatt e Deepak Sekar
O lakehouse é um novo paradigma de plataforma de dados que combina as melhores funcionalidades de data lakes e data warehouses. Ele foi projetado como uma plataforma de dados em larga escala, em nível empresarial, capaz de abrigar diversos casos de uso e produtos de dados. Pode servir como um único repositório de dados corporativo unificado para todos os seus:
- domínios de dados,
- casos de uso de streaming em tempo real,
- data marts,
- data warehouses díspares,
- feature stores e sandboxes de ciência de dados, e
- sandboxes de análise self-service departamentais.
Dada a variedade de casos de uso — diferentes princípios de organização de dados e técnicas de modelagem podem ser aplicados a diferentes projetos em um lakehouse. Tecnicamente, a Databricks Lakehouse Platform pode suportar muitos estilos diferentes de modelagem de dados. Neste artigo, nosso objetivo é explicar a implementação dos princípios de organização de dados Bronze/Silver/Gold do lakehouse e como diferentes técnicas de modelagem de dados se encaixam em cada camada.
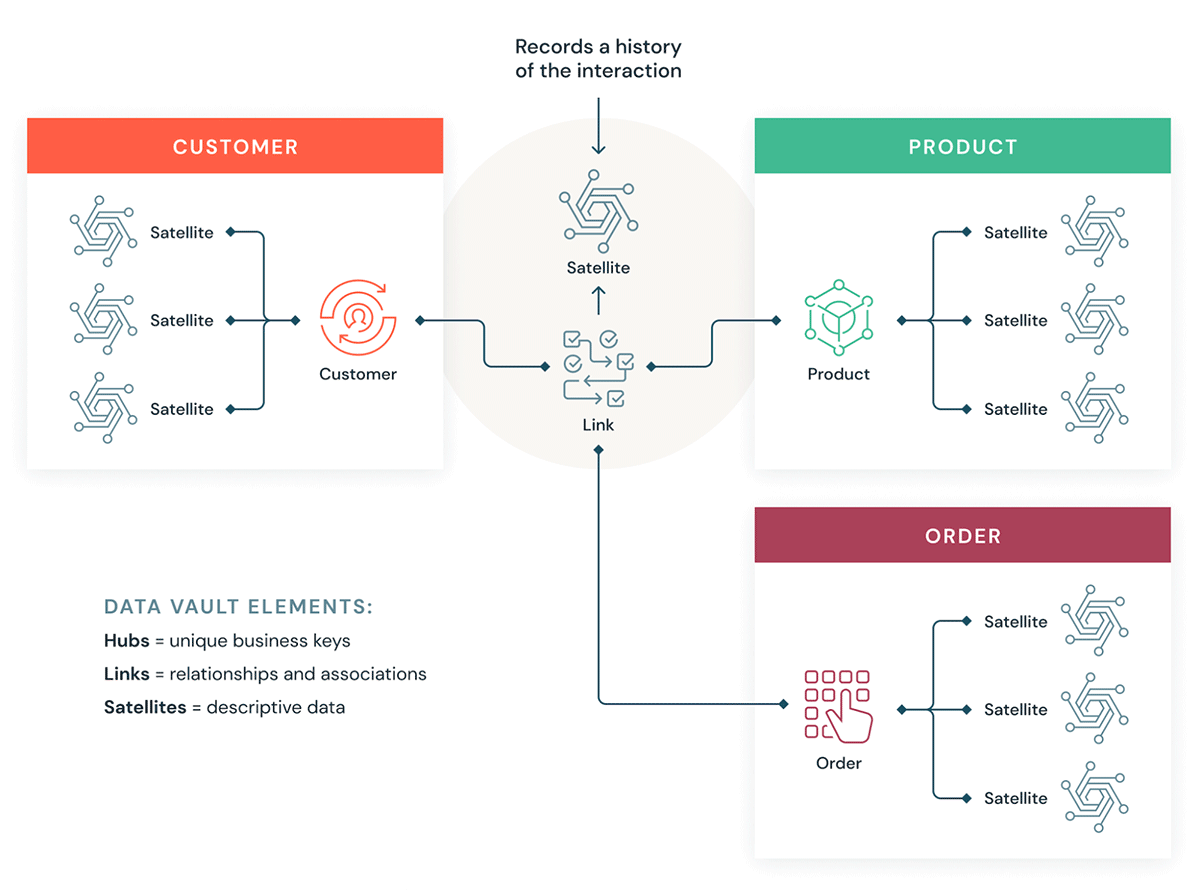
O que é um Data Vault?
Um Data Vault é um padrão de design de modelagem de dados mais recente, usado para construir data warehouses para análise em escala empresarial, em comparação com os métodos Kimball e Inmon.
Data Vaults organizam os dados em três tipos diferentes: hubs, links e satellites. Hubs representam entidades de negócios centrais, links representam relacionamentos entre hubs e satellites armazenam atributos sobre hubs ou links.
Data Vault foca no desenvolvimento ágil de data warehouses, onde escalabilidade, integração de dados/ETL e velocidade de desenvolvimento são importantes. A maioria dos clientes tem uma zona de pouso (landing zone), uma zona Vault e uma zona de data mart, que correspondem aos paradigmas organizacionais da Databricks de camadas Bronze, Silver e Gold. O estilo de modelagem Data Vault de tabelas hub, link e satellite geralmente se encaixa bem na camada Silver do Databricks Lakehouse.
Saiba mais sobre modelagem Data Vault em Data Vault Alliance.
O que é Modelagem Dimensional?
Modelagem dimensional é uma abordagem de baixo para cima para projetar data warehouses, a fim de otimizá-los para análise. Modelos dimensionais são usados para desnormalizar dados de negócios em dimensões (como tempo e produto) e fatos (como transações em valores e quantidades), e diferentes áreas de assunto são conectadas por meio de dimensões conformadas para navegar até diferentes tabelas de fatos.
A forma mais comum de modelagem dimensional é o star schema. Um star schema é um modelo de dados multidimensional usado para organizar dados de forma que seja fácil de entender e analisar, e muito fácil e intuitivo para gerar relatórios. Schemas em estrela no estilo Kimball ou modelos dimensionais são praticamente o padrão ouro para a camada de apresentação em data warehouses e data marts, e até mesmo para camadas semânticas e de relatórios. O design de star schema é otimizado para consultar grandes conjuntos de dados.
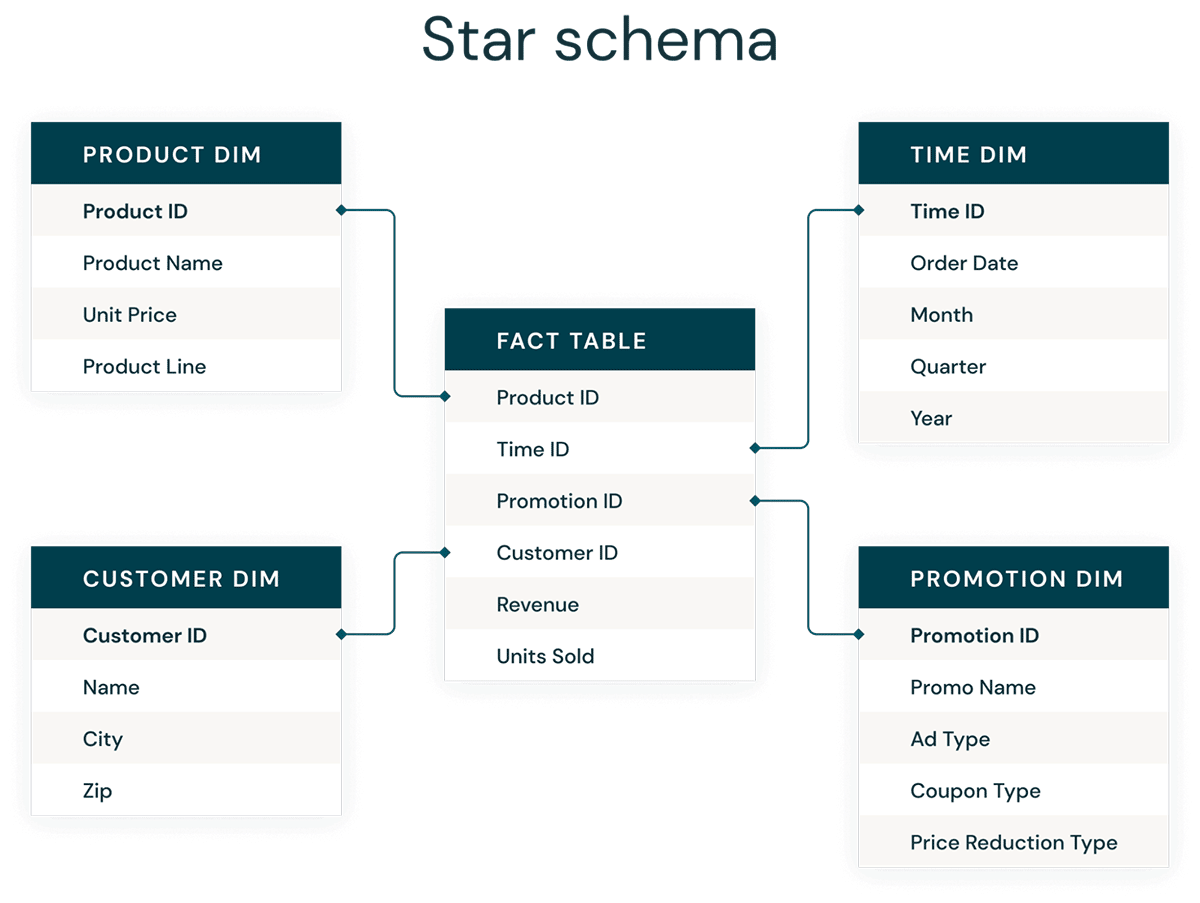
Tanto os modelos de dados Data Vault normalizados (otimizados para escrita) quanto os modelos dimensionais desnormalizados (otimizados para leitura) têm seu lugar no Databricks Lakehouse. Os hubs e satellites do Data Vault na camada Silver são usados para carregar as dimensões no star schema, e as tabelas de links do Data Vault se tornam as tabelas de controle chave para carregar as tabelas de fatos no modelo dimensional. Saiba mais sobre modelagem dimensional no Kimball Group.
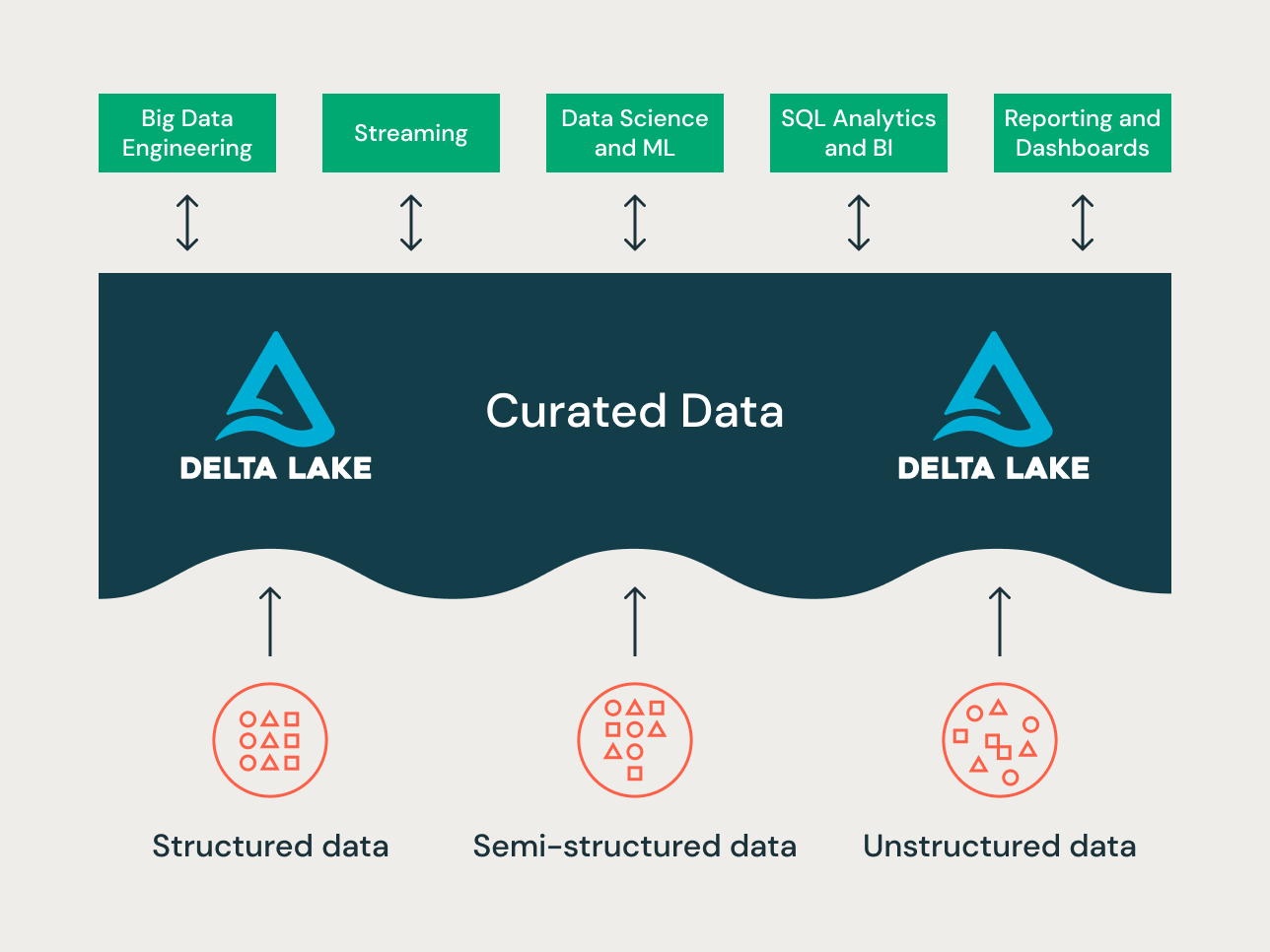
Princípios de organização de dados em cada camada do Lakehouse
Um lakehouse moderno é uma plataforma de dados corporativa abrangente. É altamente escalável e performático para todos os tipos de casos de uso, como ETL, BI, ciência de dados e streaming, que podem exigir diferentes abordagens de modelagem de dados. Vamos ver como um lakehouse típico é organizado:
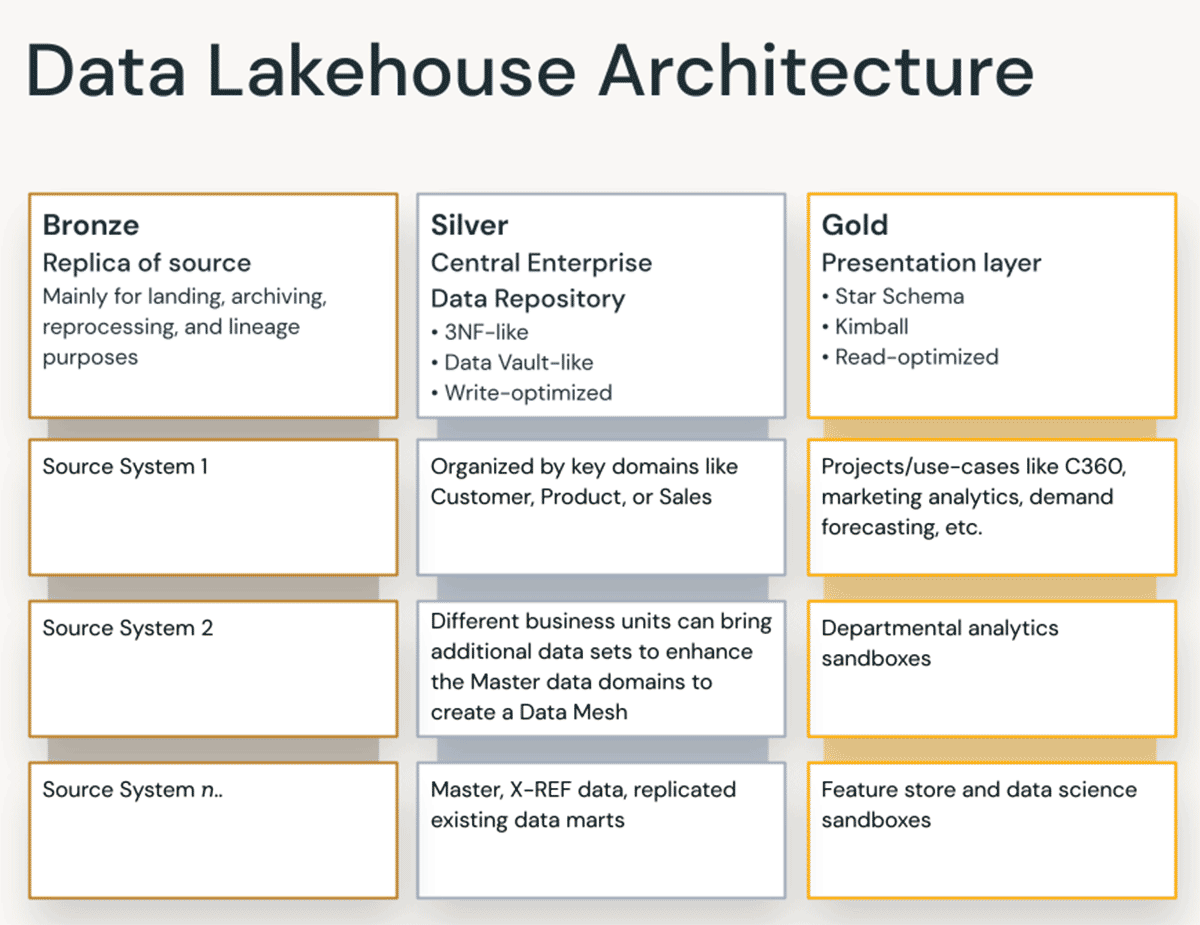
Camada Bronze — a Zona de Pouso
A camada Bronze é onde recebemos todos os dados dos sistemas de origem. As estruturas de tabela nesta camada correspondem às estruturas de tabela do sistema de origem "como estão", exceto por colunas de metadados opcionais que podem ser adicionadas para capturar a data/hora do carregamento, ID do processo, etc. O foco nesta camada é a captura de dados de alteração (CDC) e a capacidade de fornecer um arquivo histórico dos dados de origem (armazenamento a frio), linhagem de dados, auditabilidade e reprocessamento, se necessário — sem reler os dados do sistema de origem.
Na maioria dos casos, é uma boa ideia manter os dados na camada Bronze no formato Delta, para que as leituras subsequentes da camada Bronze para ETL sejam performáticas — e para que você possa fazer atualizações em Bronze para gravar alterações de CDC. Às vezes, quando os dados chegam em formatos JSON ou XML, vemos clientes os recebendo no formato de dados de origem original e, em seguida, os preparam alterando-os para o formato Delta. Assim, às vezes, vemos clientes manifestando a camada Bronze lógica em uma zona física de pouso e staging.
Armazenar dados brutos no formato de dados de origem original em uma zona de pouso também ajuda na consistência, onde você ingere dados por meio de ferramentas de ingestão que não suportam Delta como um destino nativo ou onde os sistemas de origem descarregam dados diretamente em armazenamentos de objetos. Esse padrão também se alinha bem com o framework de ingestão autoloader, onde as fontes depositam os dados na zona de pouso para arquivos brutos e, em seguida, o Databricks AutoLoader converte os dados para a camada de Staging em formato Delta.
Camada Silver — o Repositório Central Corporativo
Na camada Silver do Lakehouse, os dados da camada Bronze são combinados, mesclados, conformados e limpos ("apenas o suficiente") para que a camada Silver possa fornecer uma "visão corporativa" de todas as suas principais entidades de negócios, conceitos e transações. Isso é semelhante a um Enterprise Operational Data Store (ODS) ou um Repositório Central ou domínios de dados de um Data Mesh (por exemplo, clientes mestres, produtos, transações não duplicadas e tabelas de referência cruzada). Essa visão corporativa reúne dados de diferentes fontes e permite análises self-service para relatórios ad hoc, análise avançada e ML. Ela também serve como fonte para analistas departamentais, engenheiros de dados e cientistas de dados criarem projetos de dados e análises adicionais para responder a problemas de negócios por meio de projetos de dados corporativos e departamentais na camada Gold.
No paradigma de Data Engineering do Lakehouse, a metodologia ELT (Extract-Load-Transform) é tipicamente seguida em vez do tradicional ETL (Extract-Transform-Load). A abordagem ELT significa que apenas transformações mínimas ou "apenas o suficiente" e regras de limpeza de dados são aplicadas ao carregar a camada Silver. Todas as regras de "nível corporativo" são aplicadas na camada Silver, em vez das regras de transformação específicas do projeto, que são aplicadas na camada Gold. Velocidade e agilidade para ingerir e entregar os dados no Lakehouse são priorizadas aqui.
Do ponto de vista da modelagem de dados, a Camada Silver possui mais modelos de dados semelhantes à 3ª Forma Normal. Arquiteturas e modelos de dados Data Vault, otimizados para escrita, podem ser usados nesta camada. Se estiver usando a metodologia Data Vault, tanto o Data Vault bruto quanto o Business Vault se encaixarão na camada Silver lógica do lake — e as visualizações de apresentação Point-In-Time (PIT) ou visualizações materializadas serão apresentadas na Camada Gold.
Camada Gold — a Camada de Apresentação
Na camada Gold, múltiplos data marts ou data warehouses podem ser construídos de acordo com a metodologia de modelagem dimensional/Kimball. Como discutido anteriormente, a camada Gold é para relatórios e usa modelos de dados mais desnormalizados e otimizados para leitura, com menos junções em comparação com a camada Silver. Às vezes, as tabelas na Camada Gold podem ser completamente desnormalizadas, tipicamente se os cientistas de dados assim desejarem para alimentar seus algoritmos de engenharia de features.
Regras de ETL e qualidade de dados que são "específicas do projeto" são aplicadas ao transformar dados da camada Silver para a camada Gold. Camadas de apresentação final, como data warehouses, data marts ou produtos de dados como análise de clientes, análise de produtos/qualidade, análise de inventário, segmentação de clientes, recomendações de produtos, análise de marketing/vendas etc., são entregues nesta camada. Modelos de dados baseados em star-schema no estilo Kimball ou Data Marts no estilo Inmon se encaixam nesta Camada Gold do Lakehouse. Laboratórios de Ciência de Dados e Sandboxes Departamentais para autoatendimento analítico também pertencem à Camada Gold.
O Paradigma de Organização de Dados do Lakehouse
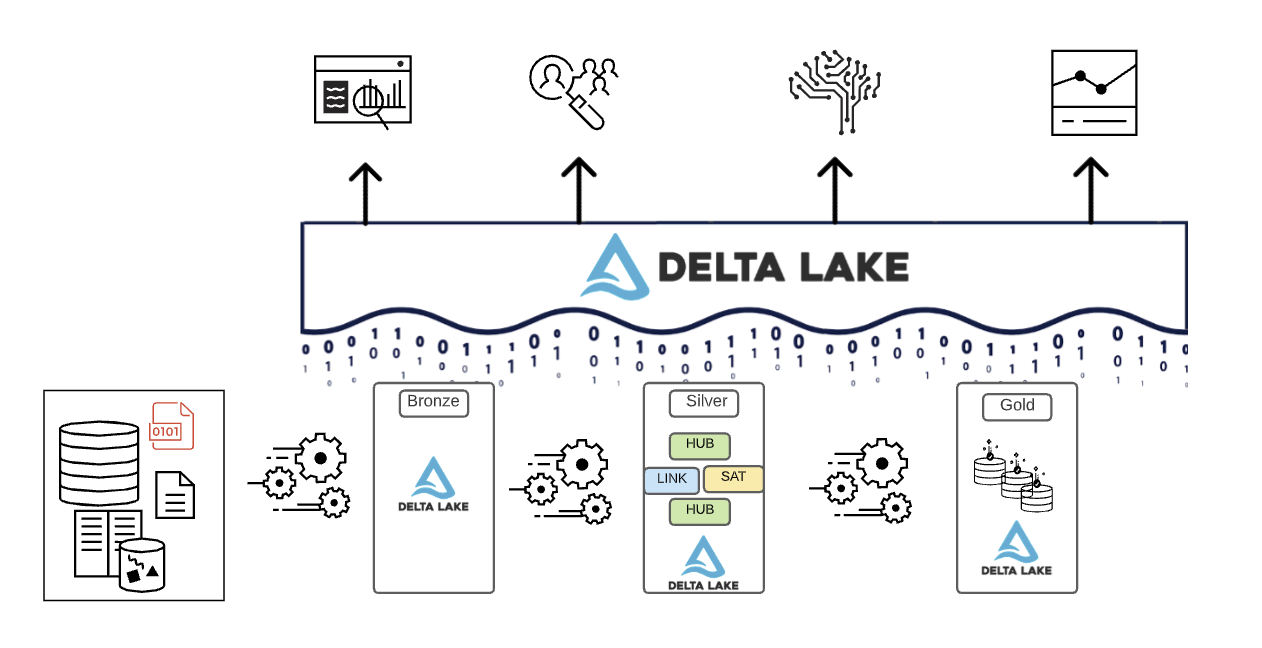
Para resumir, os dados são curados à medida que transitam pelas diferentes camadas de um Lakehouse.
- A camada Bronze utiliza os modelos de dados dos sistemas de origem. Se os dados são carregados em formatos brutos, eles são convertidos para o formato Delta Lake dentro desta camada.
- A camada Silver une os dados de diferentes fontes pela primeira vez e os conforma para criar uma visão corporativa dos dados — tipicamente usando modelos de dados mais normalizados e otimizados para escrita, que geralmente se assemelham à 3ª Forma Normal ou ao Data Vault.
- A camada Gold é a camada de apresentação com modelos de dados mais desnormalizados ou achatados do que a camada Silver, tipicamente usando modelos dimensionais no estilo Kimball ou star schemas. A camada Gold também abriga sandboxes departamentais e de ciência de dados para permitir autoatendimento analítico e ciência de dados em toda a empresa. Fornecer essas sandboxes e seus próprios clusters de computação separados impede que as equipes de Negócios criem suas próprias cópias de dados fora do Lakehouse.
Essa abordagem de organização de dados do Lakehouse visa quebrar silos de dados, unir equipes e capacitá-las a realizar ETL, streaming, BI e IA em uma única plataforma com governança adequada. As equipes centrais de dados devem ser facilitadoras da inovação na organização, acelerando a integração de novos usuários de autoatendimento, bem como o desenvolvimento de muitos projetos de dados em paralelo — em vez de o processo de modelagem de dados se tornar um gargalo. O Databricks Unity Catalog oferece busca e descoberta, governança e linhagem no Lakehouse para garantir uma boa cadência de governança de dados.
Crie seus Data Vaults e data warehouses com star schema com Databricks SQL hoje mesmo.
Leitura adicional:
- Cinco Passos Simples para Implementar um Star Schema no Databricks com Delta Lake
- Melhores práticas para implementar um modelo Data Vault na Databricks Lakehouse Platform
- Melhores práticas de modelagem dimensional e implementação no Lakehouse Moderno
- Colunas de Identidade para Gerar Chaves Substituto Agora Estão Disponíveis em um Lakehouse Perto de Você!
- Carregue um Modelo Dimensional EDW em Tempo Real com Databricks Lakehouse
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.