Busca 3x mais rápida: Escalonamento paralelo em tempo de teste com o Instructed-Retriever-1
Hoje estamos anunciando uma grande atualização que torna o Agent Bricks Knowledge Assistant mais rápido e com maior qualidade. O tempo de geração de respostas caiu 2x e o tempo de busca caiu mais de 3x, reduzindo o Time To First Token (TTFT) para cerca de dois segundos.¹ Assim, os usuários do Knowledge Assistant obterão respostas visivelmente mais rápidas em seus casos de uso, sem a necessidade de reconfiguração e sem perda de qualidade.
Esses ganhos são impulsionados pelo Instructed-Retriever-1, um modelo especializado em recuperação criado para escala paralela em tempo de teste. Ao contrário da recuperação agêntica padrão, na qual um agente trabalha sequencialmente e raciocina sobre cada resultado antes de decidir o próximo passo, nossa abordagem distribui esse trabalho em paralelo. O Instructed-Retriever-1 é um modelo único treinado para ambas as etapas de recuperação: geração de consultas para aumentar a revocação e reclassificação para aumentar a precisão, executadas em paralelo para manter a latência baixa. Neste post, descrevemos como essa abordagem resulta em um desempenho Pareto-otimizado, como treinamos um único modelo para dar suporte a todo o pipeline de recuperação e como validamos o desempenho em cargas de trabalho empresariais realistas.
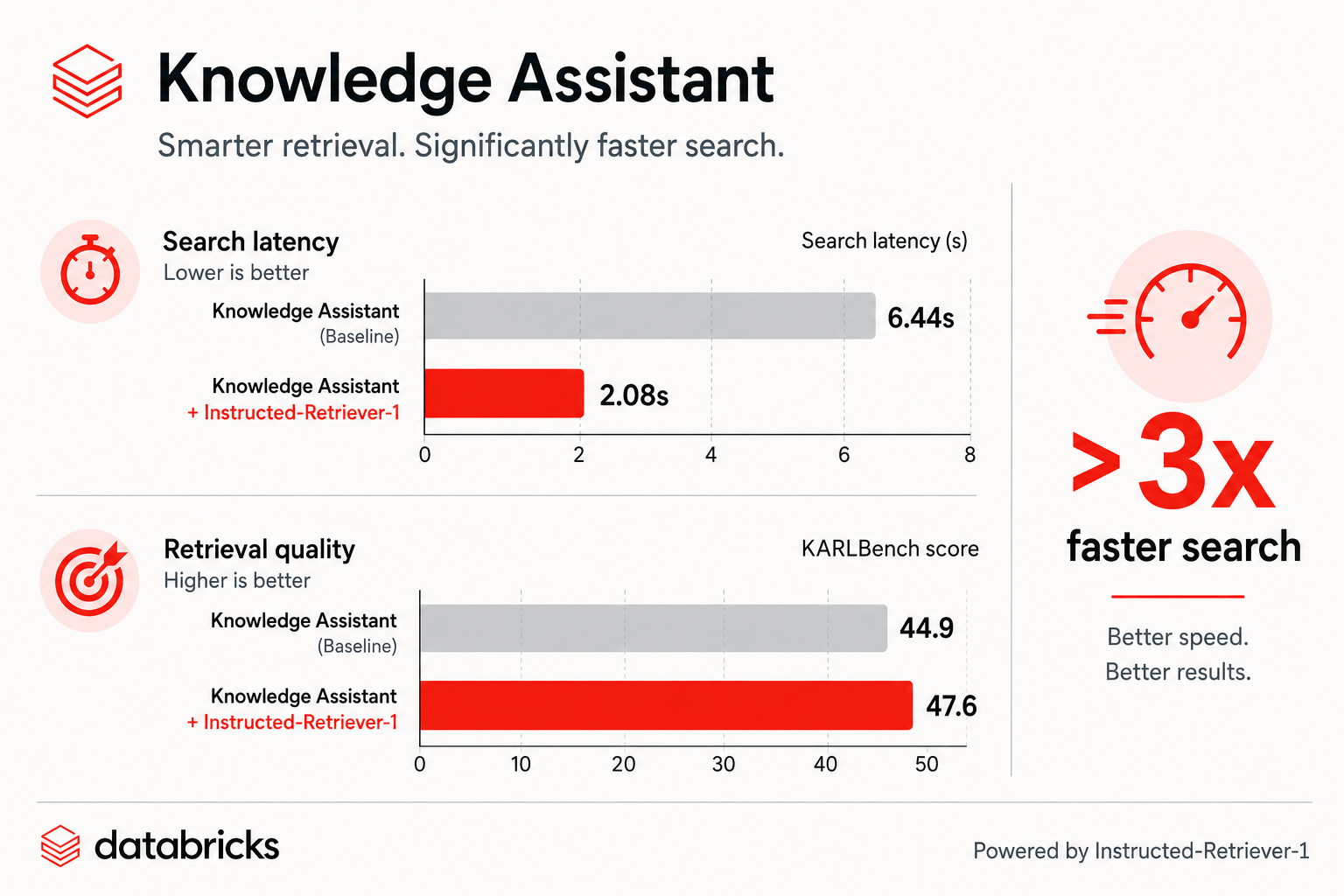
Figura: No KARLBench, o Knowledge Assistant com Instructed-Retriever-1 melhora tanto a latência de busca quanto a qualidade de recuperação.
1. Escala paralela em tempo de teste para busca
Nossa pesquisa anterior demonstrou que a qualidade pode melhorar com computação adicional em tempo de teste. No entanto, a maioria dos sistemas de busca agêntica hoje gasta essa computação em operações sequenciais, como chamadas de ferramentas, loops de raciocínio-ação e raciocínio em cadeia de pensamento (chain-of-thought). Esses métodos de fato melhoram a qualidade da busca, mas à custa de uma latência e de um custo substancialmente mais altos. Para o treinamento do Instructed-Retriever-1, adotamos um caminho diferente: em vez de escalar a computação sequencialmente, nós a paralelizamos durante a fase de busca inicial. Ao ampliar o leque de evidências recuperadas e selecionar o contexto mais relevante logo de início, alcançamos uma busca altamente eficaz com uma latência significativamente menor.
A melhoria da busca inicial depende muito da infraestrutura de treinamento. Nossa infraestrutura fornece ao modelo as instruções do usuário e o esquema preciso do índice de recuperação subjacente, propagando-os para todas as etapas subsequentes de geração de consultas e filtros, reclassificação e geração de respostas. Descrevemos como isso pode ser alcançado em nosso blog anterior sobre o Instructed Retriever, e usamos a mesma infraestrutura de busca no treinamento do nosso modelo Instructed-Retriever-1. Essa abordagem é especialmente importante para perguntas corporativas, que frequentemente envolvem restrições específicas do domínio, como período de tempo, organização, tipo de documento ou área de produto.
A geração paralela de consultas e filtros melhora a revocação do conjunto de candidatos ao explorar simultaneamente múltiplas formulações e aspectos da mesma solicitação. Isso permite que o sistema faça buscas de forma mais ampla, mantendo a latência baixa. Uma busca mais ampla cria um desafio de agregação. Diferentes formulações podem retornar fragmentos (chunks) sobrepostos ou apenas parcialmente relevantes. Para selecionar o contexto mais útil a partir do conjunto de candidatos mesclado, usamos um reclassificador em grupo (groupwise reranker) multi-pivô. Os candidatos são classificados em grupos paralelos, cada um ancorado por um ou mais fragmentos pivô, e as classificações dos grupos são mescladas em uma ordenação final. Isso captura os principais benefícios de comparar evidências no contexto, mantendo a reclassificação eficiente.
Juntas, essas etapas fornecem dois controles de escala em tempo de teste: aumentar o número de formulações de consultas e filtros melhora a revocação, enquanto aumentar o número de pivôs melhora a precisão. Como ambas as etapas podem usar o paralelismo, o sistema pode trocar computação adicional em tempo de teste por um contexto de maior qualidade, preservando a baixa latência.
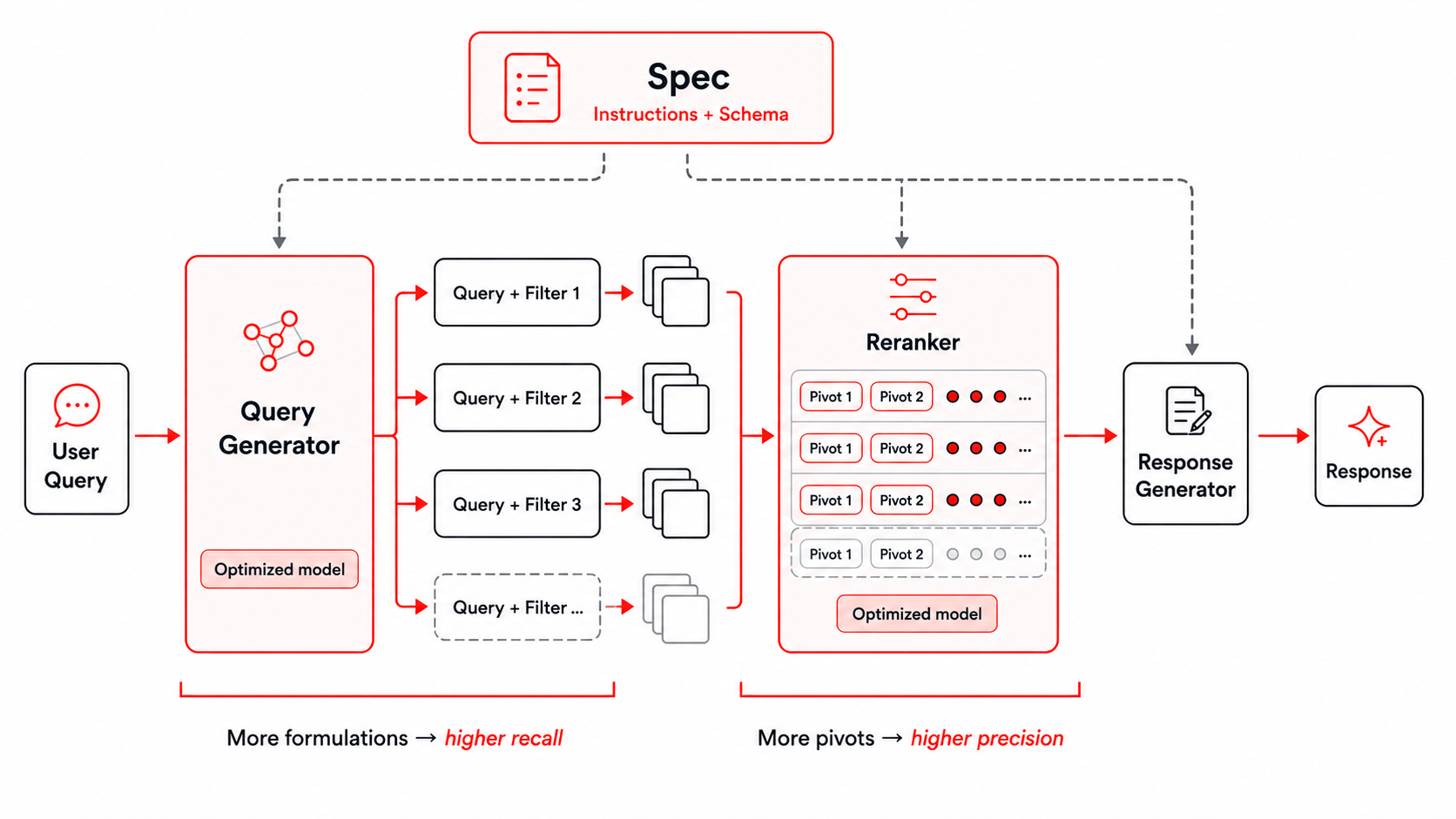
Figura: A infraestrutura de busca usada para o Instructed-Retriever-1.
2. Treinamento do Instructed-Retriever-1
A escala paralela em tempo de teste para busca exige um modelo que possa fazer duas coisas bem: gerar buscas eficazes e julgar as evidências recuperadas. Treinamos o Instructed-Retriever-1 como um único modelo especializado em recuperação que suporta geração paralela de consultas e reclassificação. O resultado é um modelo que se equipara à qualidade de recuperação do Claude Sonnet 4.5 no KARLBench, mantendo uma latência baixa.
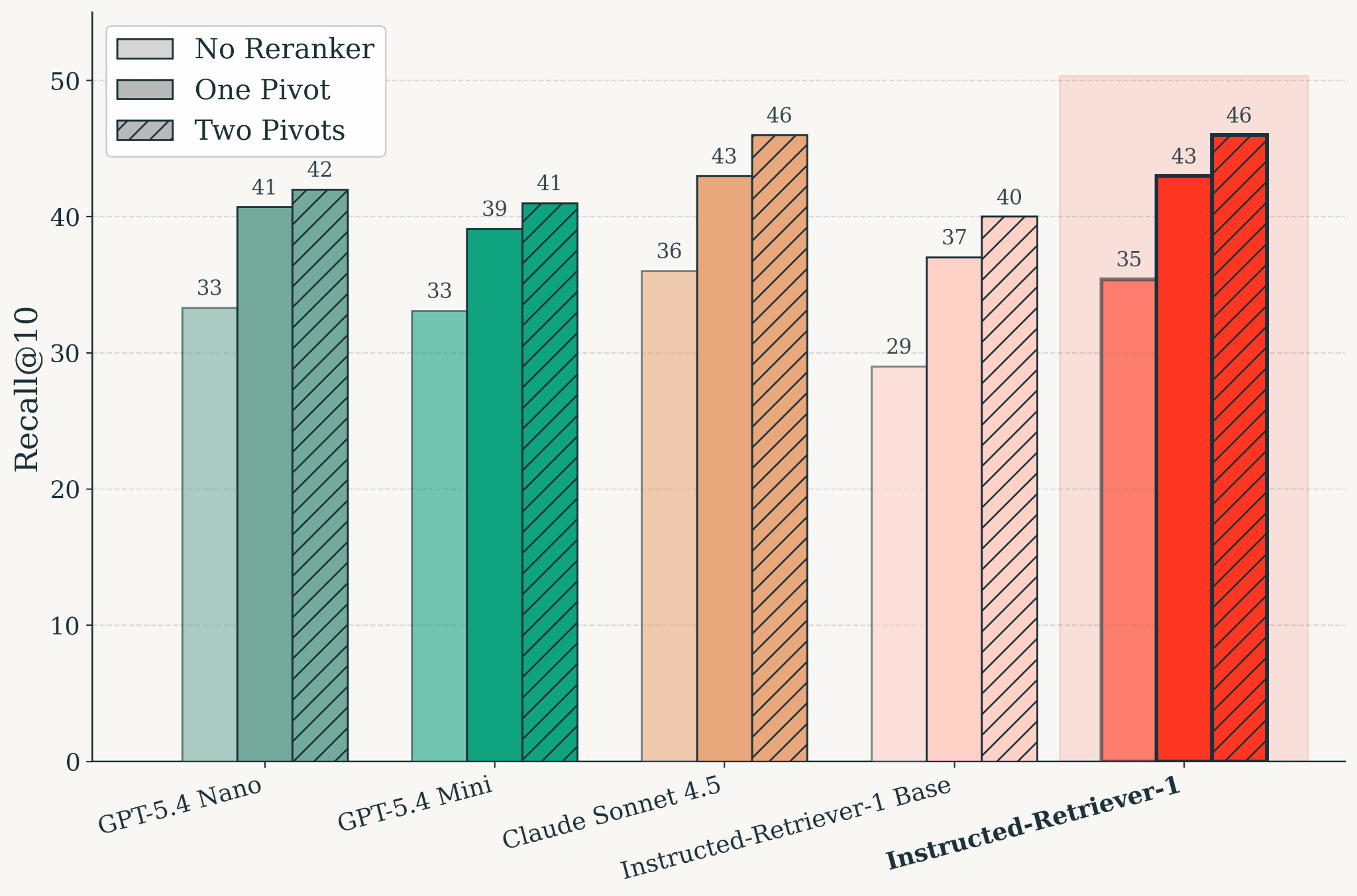
Figura: Qualidade de recuperação no KARLBench após o treinamento, avaliada em várias configurações de reclassificação. O Instructed-Retriever-1 se equipara à qualidade de recuperação do Claude Sonnet 4.5. Entre os modelos, a reclassificação baseada em pivô melhora o Recall@10 em relação à configuração sem reclassificador, e dois pivôs melhoram ainda mais a qualidade em comparação com um único pivô.
Para preparar os dados para o treinamento, criamos ambientes de recuperação sintéticos de estilo corporativo a partir de um amplo corpus de pré-treinamento, de forma independente do nosso benchmark de avaliação. Nós os criamos usando a abordagem de síntese de dados agêntica descrita no relatório KARL. Os ambientes resultantes refletem os tipos de tarefas que o Knowledge Assistant deve lidar, incluindo busca factual, sumarização, recomendação, resolução de problemas e suporte à decisão sobre corpora que combinam documentos não estruturados com metadados estruturados.
O modelo é treinado em duas etapas para capturar múltiplas capacidades de busca. O modelo resultante suporta tanto a geração de consultas e filtros quanto capacidades de recuperação no estilo de verificação, viabilizando as duas etapas que tornam a escala paralela em tempo de teste útil na prática.
3. Validando o Instructed-Retriever-1 em Produção
Melhorar a recuperação só importa se funcionar em cargas de trabalho realistas e se ajustar às restrições de latência de produção. Avaliamos o Instructed-Retriever-1 em um conjunto de dados interno de grande escala representativo do uso do Knowledge Assistant, medindo se os dois mecanismos de escala apresentados acima melhoram a qualidade da recuperação: geração paralela de consultas e filtros para revocação, e reclassificação multi-pivô para precisão.
Figura: Demonstração do Knowledge Assistant impulsionado pelo Instructed-Retriever-1.
Qualidade de recuperação em cargas de trabalho realistas
Nosso conjunto de dados de avaliação é baseado em cargas de trabalho reais do Knowledge Assistant, onde respostas úteis frequentemente exigem múltiplas evidências de apoio em vez de um único documento de referência. Avaliamos a recuperação em duas etapas. Primeiro, medimos a latência e a qualidade da geração de consultas em todos os sistemas candidatos. Para a qualidade, usamos pontuações de rubrica de avaliação por LLM (LLM-judge) para especificidade, amplitude e relevância. Essas métricas capturam se as consultas geradas são direcionadas, cobrem os aspectos importantes da solicitação e continuam úteis para responder à pergunta.
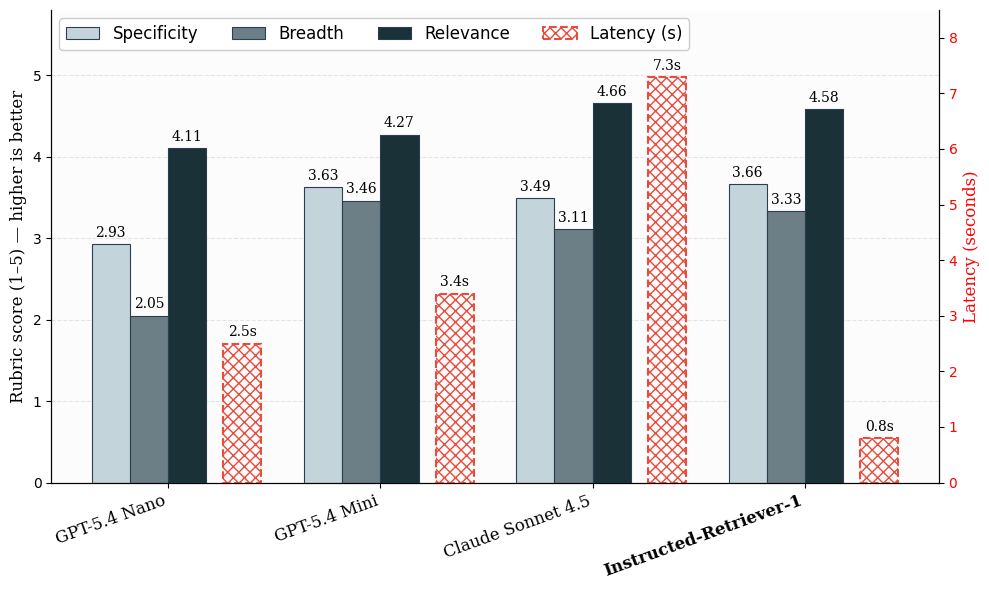
Figura: Qualidade e latência da geração de consultas em exemplos internos semelhantes aos de produção. As pontuações médias das rubricas avaliam a qualidade da geração de consultas em termos de especificidade, amplitude e relevância em uma escala de 1 a 5. A latência é calculada para uma etapa de geração de consultas.
Para o re-ranqueamento, mantemos o conjunto de candidatos recuperados fixo e avaliamos a eficácia de cada re-ranqueador em destacar as evidências mais úteis. Para obter rótulos de relevância densos, usamos um juiz LLM para pontuar cada fragmento em uma escala de relevância de 0 a 3 estilo TREC e, em seguida, calculamos o nDCG@10 a partir dos rankings resultantes. O Claude Sonnet 4.5 e o Instructed-Retriever-1 pontuam 80,1 e 81,0 nDCG@10, respectivamente. Esses são ganhos de +12,8% e +14,1% em comparação com um cenário sem re-ranqueamento, demonstrando a eficácia do nosso re-ranqueador groupwise multi-pivô.
No geral, em cargas de trabalho realistas, o Instructed-Retriever-1 apresenta um forte desempenho em todas as métricas da rubrica de geração de consultas e continua competitivo em relação à linha de base mais forte em re-ranqueamento. Isso apoia o uso de um único modelo especializado em recuperação tanto para a geração de consultas quanto para a seleção de candidatos.
Desempenho de serving
O escalonamento paralelo em tempo de teste só é útil se a computação adicional puder ser servida de maneira eficiente e escalada com o número de buscas. Para isso, o Instructed-Retriever-1 usa uma arquitetura Mixture-of-Experts e otimizações de serving, incluindo quantização FP8,2 decodificação especulativa e ajustes adicionais de infraestrutura para todo o pipeline de recuperação. Em nossas avaliações, o FP8 não apresenta degradação de qualidade, ao mesmo tempo em que melhora a velocidade de inferência e o throughput em comparação com o BF16.3 A decodificação especulativa adiciona outra aceleração de mais de 30% para o caminho combinado de geração de consultas e re-ranqueamento.
Conclusão
Esta atualização traz o Escalonamento Paralelo em Tempo de Teste para a pilha de busca em produção. O sistema realiza a recuperação de forma ampla por meio da geração paralela de consultas e filtros e, em seguida, faz o re-ranqueamento de forma precisa com a comparação de evidências multi-pivô. O Instructed-Retriever-1 potencializa ambas as etapas com um único modelo especializado em recuperação, treinado para geração de busca e ranqueamento de evidências. O resultado é um Knowledge Assistant melhor e mais rápido: o tempo de busca cai mais de 3x, o tempo de geração de respostas cai 2x, o TTFT fica em torno de 2s e a latência de ponta a ponta fica consistentemente abaixo de 10s em nossa configuração de avaliação offline.¹ Os primeiros usuários, como a Baylor University e outros, já estão percebendo a diferença.
"(A nova experiência é) mais concisa, com uma sensação mais ágil que traz as informações essenciais mais rapidamente — uma melhoria notável de UX para nossos casos de uso.” —Kyle Van Pelt, Diretor de Processos e Governança de Gestão de Matrículas na Baylor University.
Comece a exigir mais do seu Knowledge Assistant hoje mesmo. O Instructed-Retriever-1 começou a ser disponibilizado para todos os clientes, ajudando as equipes a recuperar contextos de maior qualidade com menos tempo de espera; você pode fazer mais perguntas, descobrir mais conhecimento e ir da pergunta à resposta mais rapidamente. Experimente agora.
1 Estimativas de latência medidas como a média das avaliações offline, com comprimento médio de cerca de 256 tokens de saída. A latência real pode variar com base nos formatos de dados em instâncias e consultas específicas do Knowledge Assistant.
2 Usamos a biblioteca ModelOpt da NVIDIA para quantização FP8.
3 Avaliamos os modelos BF16 e FP8 no KARLBench ao longo de 10 testes. O FP8 não mostrou degradação de qualidade estatisticamente significativa em relação ao BF16: a diferença média de pontuação foi de +0,33 pontos, com erro padrão de 1,69 pontos e intervalo de confiança de 95% de [-2,99, 3,65].
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.