3x Faster Search: Parallel Test-Time Scaling with Instructed-Retriever-1
Today we’re announcing a major update that makes Agent Bricks Knowledge Assistant both faster and higher quality. Answer generation time has dropped by 2x, and search time has dropped by more than 3x, bringing Time To First Token (TTFT) to around two seconds.¹ Thus, Knowledge Assistant users will get noticeably faster answers across their use cases, with no reconfiguration required and no tradeoff in quality.
These gains are powered by Instructed-Retriever-1, a retrieval-specialized model built for parallel test-time scaling. Unlike standard agentic retrieval, where an agent works sequentially and reasons over each result before deciding its next step, our approach fans this work out in parallel. Instructed-Retriever-1 is a single model trained for both retrieval stages: query generation to increase recall and reranking to increase precision, run in parallel to keep latency low. In this post, we describe how this approach results in a Pareto-optimal performance, how we train one model to support the full retrieval pipeline, and how we validate performance on realistic enterprise workloads.
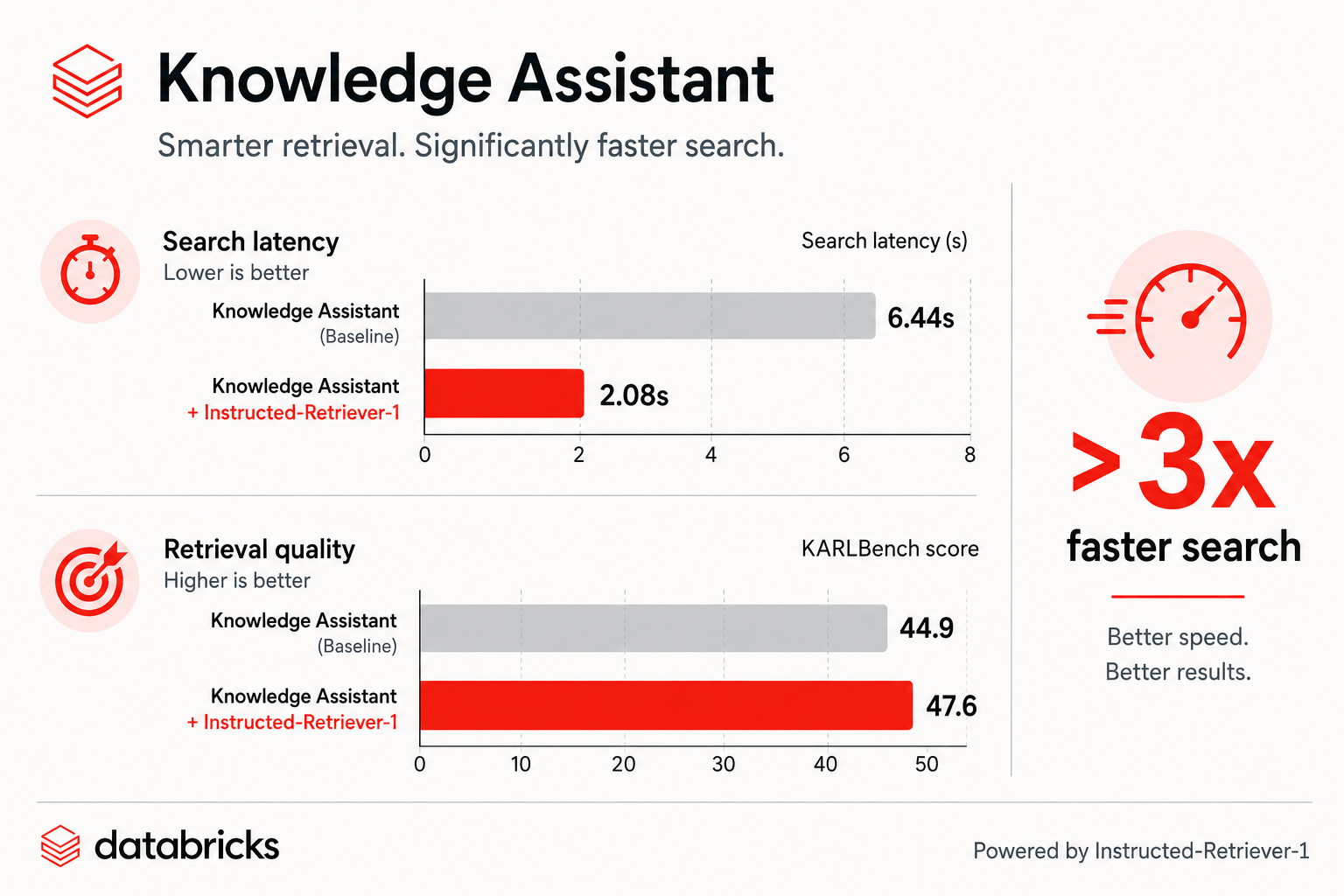
Figure: On KARLBench, Knowledge Assistant with Instructed-Retriever-1 improves both search latency and retrieval quality.
1. Parallel Test-Time Scaling for Search
Our previous research demonstrated that quality can improve with additional test-time compute. However, most agentic search systems today spend that compute on sequential operations, like tool calls, reason-act loops, and chain-of-thought reasoning. These methods do improve search quality, but they come at the expense of substantially higher latency and cost. For training Instructed-Retriever-1, we take a different route: rather than scaling compute sequentially, we parallelize it during the initial search phase. By broadening the range of retrieved evidence and selecting the most relevant context up front, we achieve highly effective search with significantly lower latency.
Improving the initial search depends heavily on the training harness. Our harness provides the model with user instructions and the precise schema of the underlying retrieval index, and it propagates them to all the subsequent stages of query and filter generation, reranking, and answer generation. We described how this can be achieved in our earlier Instructed Retriever blog, and we use the same search harness in training our Instructed-Retriever-1 model. This approach is especially important for enterprise questions, which often involve domain-specific constraints such as time period, organization, document type, or product area.
Parallel query and filter generation improves candidate-set recall by simultaneously exploring multiple formulations and aspects of the same request. This allows the system to search more broadly while keeping latency low. Broader search creates an aggregation challenge. Different formulations may return overlapping or only partially relevant chunks. To select the most useful context from the merged candidate set, we use a multi-pivot groupwise reranker. Candidates are ranked in parallel groups, each anchored by one or more pivot chunks, and the group rankings are merged into a final ordering. This captures the key benefits of comparing evidence in context while keeping reranking efficient.
Together, these stages provide two test-time scaling knobs: increasing the number of query and filter formulations improves recall, while increasing the number of pivots improves precision. Because both stages can use parallelism, the system can trade additional test-time compute for higher-quality context while preserving low latency.
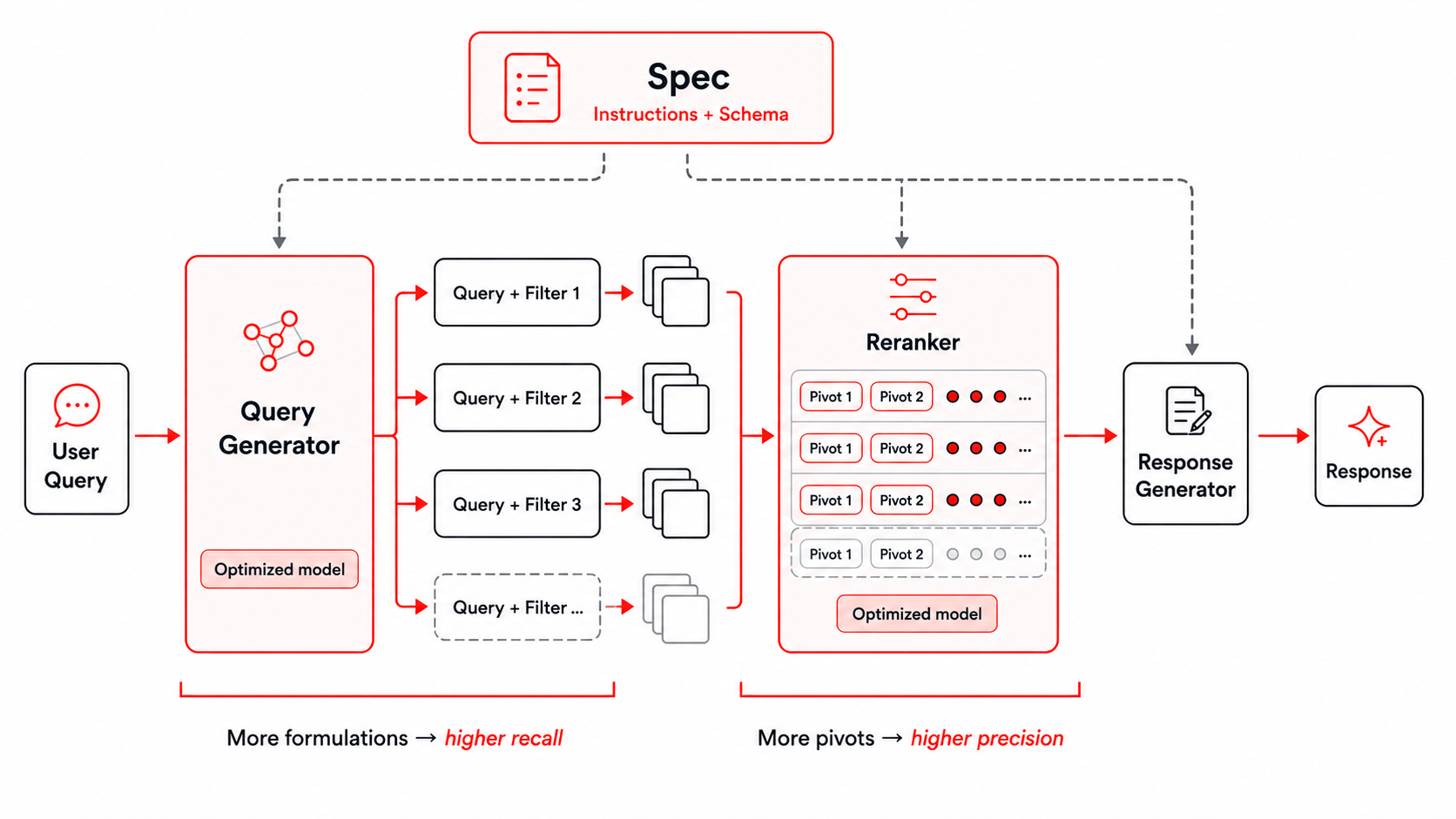
Figure: The search harness used for Instructed-Retriever-1.
2. Training Instructed-Retriever-1
Parallel test-time scaling for search requires a model that can do two things well: generate effective searches and judge retrieved evidence. We trained Instructed-Retriever-1 as a single retrieval-specialized model that supports parallel query generation and reranking. The result is a model that matches Claude Sonnet 4.5 retrieval quality on KARLBench while maintaining low latency.
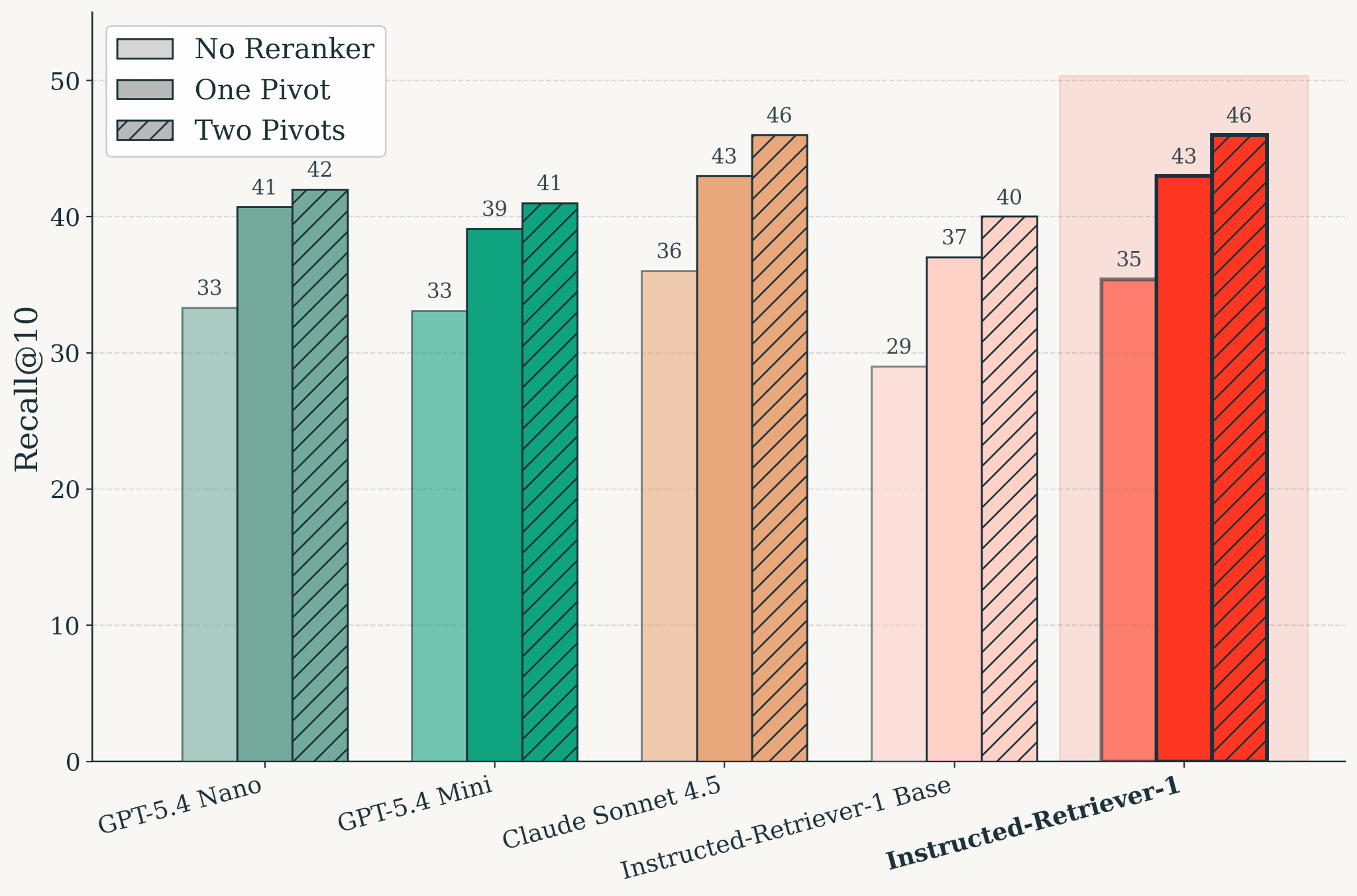
Figure: Retrieval quality on KARLBench after training, evaluated across reranking configurations. Instructed-Retriever-1 matches Claude Sonnet 4.5 retrieval quality. Across models, pivot-based reranking improves Recall@10 over the no-reranker setting, and two pivots further improve quality over one pivot.
To prepare the data for training, we build synthetic enterprise-style retrieval environments from a broad pretraining corpus, independently from our evaluation benchmark. We create them using the agentic data synthesis approach described in the KARL report. The resulting environments reflect the kinds of tasks Knowledge Assistant must handle, including factual lookup, summarization, recommendation, problem solving, and decision support over corpora that combine unstructured documents with structured metadata.
The model is trained in two stages to capture multiple search capabilities. The resulting model supports both query and filter generation, as well as verification-style retrieval capabilities, enabling the two stages that make parallel test-time scaling useful in practice.
3. Validating Instructed-Retriever-1 in Production
Improving retrieval only matters if it works on realistic workloads and fits within production latency constraints. We evaluate Instructed-Retriever-1 on a large-scale internal dataset representative of Knowledge Assistant usage, measuring whether the two scaling mechanisms introduced above improve retrieval quality: parallel query and filter generation for recall, and multi-pivot reranking for precision.
Figure: Demonstration of Knowledge Assistant powered by Instructed-Retriever-1.
Retrieval quality on realistic workloads
Our evaluation dataset is based on real-world Knowledge Assistant workloads, where useful answers often require multiple pieces of supporting evidence rather than a single ground-truth document. We evaluate retrieval in two stages. First, we measure query generation latency and quality across all candidate systems. For quality, we use LLM-judge rubric scores for specificity, breadth, and relevance. These metrics capture whether generated queries are targeted, cover the important aspects of the request, and remain useful for answering the question.
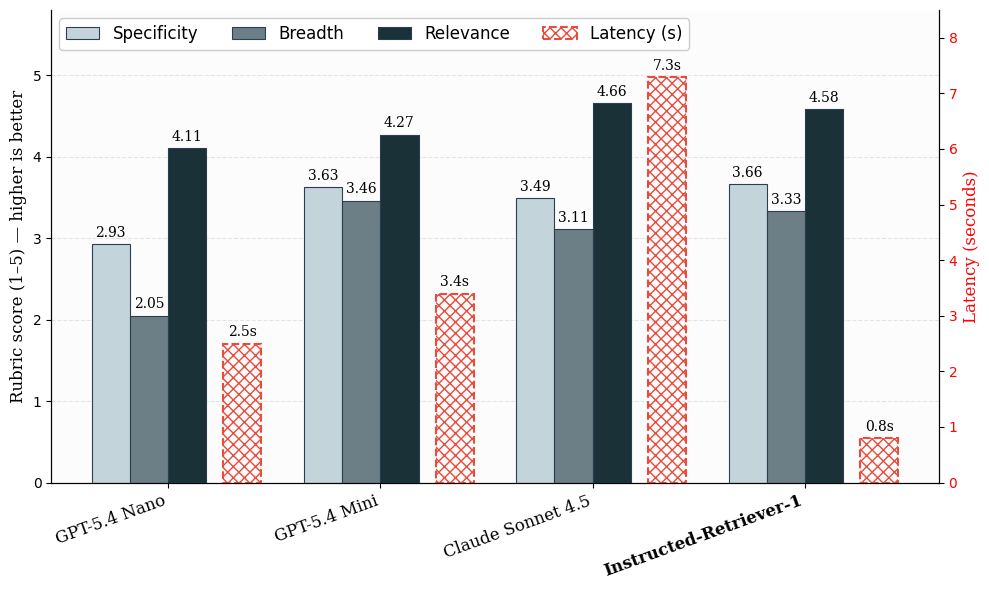
Figure: Query-generation quality and latency on production-like internal examples. Mean rubric scores assess query generation quality across specificity, breadth, and relevance on a 1–5 scale. Latency is computed for a query generation stage.
For reranking, we hold the retrieved candidate set fixed and evaluate how effectively each reranker surfaces the most useful evidence. To obtain dense relevance labels, we use an LLM judge to score each chunk on a 0-3 TREC-style relevance scale, then compute nDCG@10 from the resulting rankings. Claude Sonnet 4.5 and Instructed-Retriever-1 score 80.1 and 81.0 nDCG@10, respectively. These are gains of +12.8% and +14.1% compared to a setting with no reranking, demonstrating the effectiveness of our multi-pivot groupwise reranker.
Overall, on realistic workloads, Instructed-Retriever-1 performs strongly across the query-generation rubric metrics and remains competitive with the strongest baseline on reranking. This supports the use of a single retrieval-specialized model for both query generation and candidate selection.
Serving performance
Parallel test-time scaling is useful only if the additional compute can be served efficiently and scales with the number of searches. To this end, Instructed-Retriever-1 uses a Mixture-of-Experts architecture and serving optimizations including FP8 quantization,2 speculative decoding, and additional infrastructure tuning for the full retrieval pipeline. In our evals, FP8 shows no quality degradation while improving inference speed and throughput compared to BF16.3 Speculative decoding adds another 30%+ speed-up for the combined query-generation and reranking path.
Conclusion
This update brings Parallel Test-Time Scaling into the production search stack. The system retrieves broadly through parallel query and filter generation, then reranks precisely with multi-pivot evidence comparison. Instructed-Retriever-1 powers both stages with a single retrieval-specialized model trained for search generation and evidence ranking. The result is a Knowledge Assistant that is both better and faster: search time drops by more than 3x, answer generation time drops by 2x, TTFT is around 2s, and end-to-end latency is consistently below 10s on our offline eval setup.¹ Early users, like Baylor University and others, are already noticing the difference.
"(The new experience is) more concise, with a 'snappy' feel that surfaces key information sooner-a noticeable UX improvement for our use cases.” —Kyle Van Pelt, Director of Process and Governance, Enrollment Management at Baylor University.
Start asking more of your Knowledge Assistant today. Instructed-Retriever-1 has begun rolling out to all customers, helping teams retrieve higher-quality context with less waiting; you can ask more questions, uncover more knowledge, and move from question to answer faster. Try it now.
1 Latency estimates measured as the average across offline evaluations, with average length around 256 output tokens. Actual latency may vary based on data shapes in specific Knowledge Assistant instances and queries.
2 We use NVIDIA’s ModelOpt library for FP8 quantization.
3 We evaluated the BF16 and FP8 models on KARLBench across 10 trials. FP8 showed no statistically significant quality degradation relative to BF16: the mean score difference was +0.33 points, with standard error 1.69 points and 95% confidence interval [-2.99, 3.65].
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.