Lakeflow: Uma nova era de engenharia de dados agêntica
A fundação de dados unificada e em tempo real em que sua empresa pode confiar
por Bilal Aslam, Ray Zhu, Manish Dalwadi, Saad Ansari e Giselle Goicochea
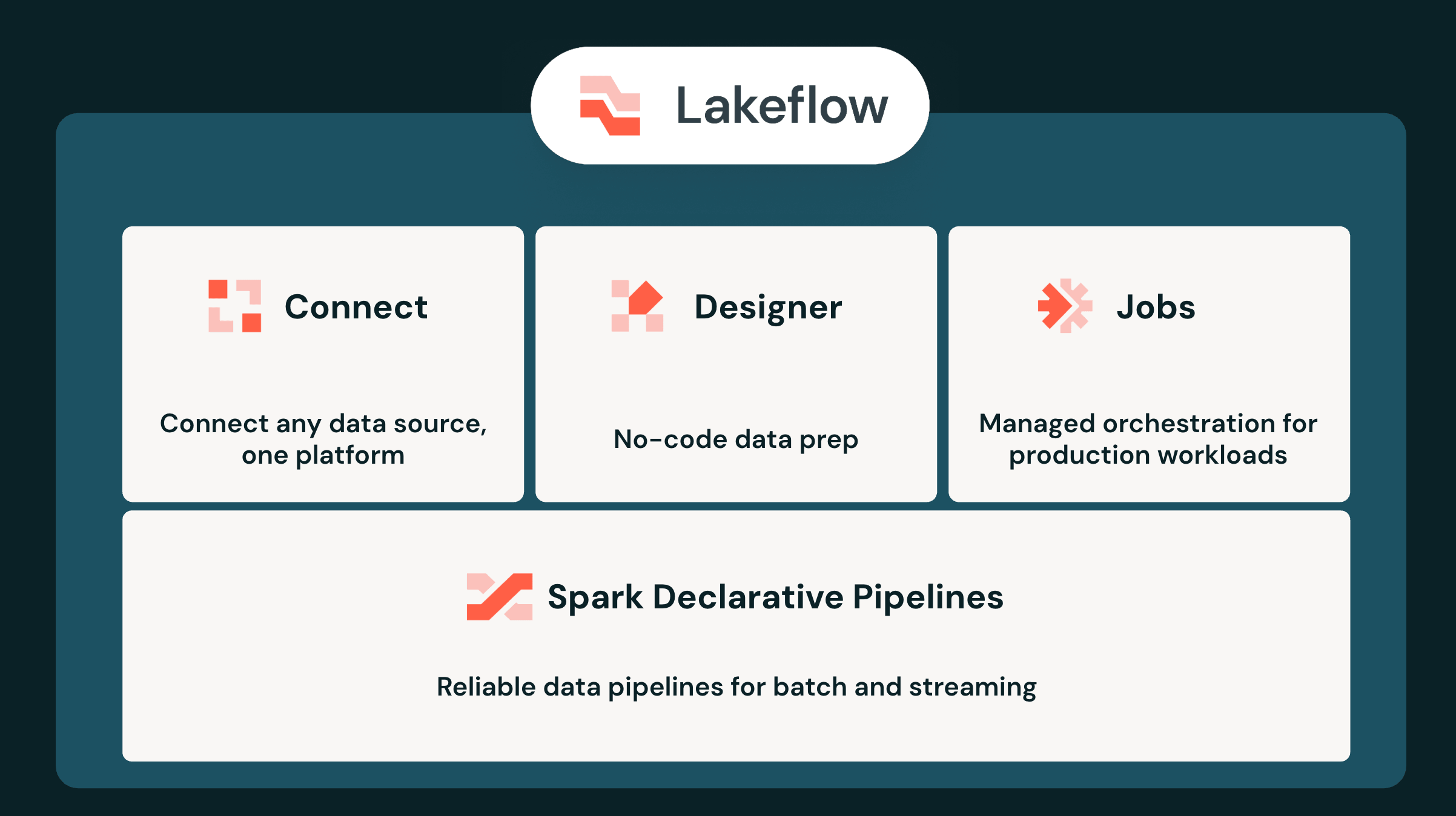
- Base unificada para AI agêntica: O Lakeflow unifica ingestão, transformação e orquestração sob o Unity Catalog, eliminando a lacuna causada pela proliferação de ferramentas e fornecendo aos agentes de AI uma única fonte de contexto confiável em tempo real.
- Ingestão e streaming de alto desempenho: Conecte-se a mais de 100 fontes de dados empresariais com o Lakeflow Connect, faça streaming de dados de eventos de alto volume por meio de várias interfaces no Zerobus Ingest e obtenha latência de milissegundos com o Real-Time Mode para pipelines declarativos do Spark.
- Desenvolvimento e operações agênticos: Crie pipelines visualmente com o Lakeflow Designer, acelere a criação com o Genie Code, reduza o esforço operacional com o Genie ZeroOps e consolide orquestradores legados com o Lakeflow Jobs.
Todas as análises, AI e aplicações começam com dados. Nas últimas décadas, as ferramentas de engenharia de dados se proliferaram em uma variedade de casos de uso e personas de usuários. O resultado é que a maioria das empresas acaba com uma pilha de dados muito complexa e fragmentada, difícil de integrar, manter ou governar. Com a AI impulsionando todos os dados e profissionais de AI, ainda mais pressão será colocada sobre essas pilhas de dados frágeis.
É por isso que decidimos criar o Databricks Lakeflow, uma plataforma unificada para toda a engenharia de dados, desde a ingestão até a transformação e orquestração. Todos os recursos do Lakeflow são totalmente integrados e controlados centralmente pelo Unity Catalog. Na era dos agentes, essa arquitetura unificada oferece vantagens significativas, permitindo que os agentes não apenas criem, mas também operem seus pipelines de dados. Hoje, no Data + AI Summit, estamos anunciando a próxima grande evolução do Databricks Lakeflow.
Genie Code e Lakeflow Designer: desenvolvimento de pipelines baseado em agentes
Genie Code agora está profundamente integrado a todos os aspectos da experiência do usuário do Lakeflow. Você pode usar o Genie Code para criar conectores de ingestão, criar pipelines em Python e SQL e desenvolver jobs com tarefas, gatilhos e dependências. Tudo isso é possível graças à pilha unificada de engenharia de dados, que fornece ao Genie Code um contexto completo de ponta a ponta em suas cargas de trabalho de ingestão, transformação e orquestração.
Agora disponível para o público geral, o Lakeflow Designer democratiza a engenharia de dados em toda a empresa. Esta interface visual, sem código e baseada em AI, capacita as equipes a criar pipelines usando uma tela de arrastar e soltar e prompts em linguagem natural. Analistas de negócios e usuários não técnicos podem criar pipelines de ETL prontos para produção sem escrever código. Cada Flow visual criado no Designer é executado nativamente em um Spark Declarative Pipeline pronto para produção, garantindo zero perda de tradução sem transferências complexas. Os engenheiros de dados podem revisar e refinar facilmente esse código diretamente no local, sem alternar de contexto ou reescrever a lógica.
Genie ZeroOps: coloque as operações de dados e AI no piloto automático
Anunciado hoje, o Genie ZeroOps ajuda as equipes de dados a operar ativos de dados e AI em produção. O Genie ZeroOps é um agente de AI em segundo plano desenvolvido sob medida que monitora e gerencia ativos de dados e AI. O ZeroOps detecta falhas e realiza análises de causa raiz para identificar o que deu errado usando métricas de qualidade de dados, logs de erros e dados de linhagem do Unity Catalog. Além disso, ele gera propostas de correção e as valida em um ambiente de sandbox seguro e isolado, controlado pelo Unity Catalog. A aplicação de uma correção é feita com supervisão humana (human-in-the-loop), de modo que o Genie ZeroOps faz o trabalho pesado e você mantém o controle. Semelhante ao desenvolvimento baseado em agentes, a funcionalidade do Genie ZeroOps só é possível devido à total percepção de contexto e governança de ponta a ponta proporcionadas por uma pilha de dados unificada com o Lakeflow.
Lakeflow Connect: ecossistema de rápido crescimento com mais de 100 conectores integrados
Os pipelines automatizados são tão valiosos quanto os dados que fluem por eles. Para criar uma "memória empresarial" completa e ancorar agentes de AI como o Databricks Genie, você precisa de acesso contínuo ao contexto governado mais recente que abrange todas as áreas do seu negócio. Lakeflow Connect simplifica esse processo ao ingerir incrementalmente dados novos de uma lista cada vez maior de sistemas empresariais diretamente em tabelas Delta controladas pelo Unity Catalog.
Hoje, estamos anunciando que o Lakeflow Connect está se expandindo para oferecer suporte a mais de 100 conectores nativos e gerenciados em aplicativos empresariais, bancos de dados, fontes de arquivos e armazenamento em nuvem. Agora você pode eliminar ferramentas de terceiros frágeis e executar pipelines de ingestão otimizados para os casos de uso que os clientes mais precisam:
- Gestão de Conhecimento Empresarial: Unifique dados de negócios do Jira (Beta), GitHub (Beta) e Confluence (GA) junto com documentos não estruturados, contratos e PDFs do SharePoint (GA), Google Drive (Beta) e Outlook (Beta). Potencialize aplicativos de AI sensíveis ao contexto, agentes de suporte e processamento inteligente de documentos em uma única base.
- MarTech: Ingerir dados de campanhas e clientes diretamente do Meta Ads (Beta), TikTok Ads (Beta), Google Ads (Beta) e HubSpot (GA) para impulsionar a personalização em tempo real.
- Operações de TI e Segurança: Centralize logs e telemetria para uma análise robusta de SIEM.
- Captura baseada em consultas para todos os conectores de banco de dados e fontes do Lakehouse Federation (GA): Consulte o banco de dados diretamente para captura de alterações sem a necessidade de análise de log.
Para organizações com sistemas especializados ou proprietários, os Community Connectors (Beta) fornecem uma solução de código aberto criada no Databricks. Implante um conector pré-construído da comunidade ou crie o seu próprio para compartilhar em sua organização ou no ecossistema mais amplo.
A Panasonic usou o Lakeflow Connect para unificar dados do SAP, Workday e SharePoint, substituindo o ETL legado e frágil por uma única plataforma para inteligência governada em tempo real.
“Ao mudar de uma pilha de ETL legada e rígida para a Databricks Platform, nossas equipes de BI agora podem descobrir e acessar facilmente dados críticos, reduzindo os tempos de atualização do Power BI em 50%. Estamos transformando dados externos e inconsistentes em ativos confiáveis e de nível de produção que revelam novos insights de negócios e fortalecem a vantagem competitiva da Panasonic.”—Jerry Deng, Diretor de BI, Panasonic
Também estamos facilitando para as organizações reduzirem permanentemente o TCO de ingestão de alto volume com o nível gratuito do Lakeflow Connect. Os clientes recebem automaticamente 100 DBUs gratuitas por dia, suportando até 100 milhões de registros diariamente em conectores populares de SaaS gerenciados e bancos de dados.
Zerobus Ingest: ingestão sem Kafka para seus produtores de dados
O Zerobus Ingest está mudando a forma como as organizações lidam com dados de eventos de alto volume, sem a necessidade de um barramento de mensagens. Com gravações quase em tempo real em menos de 5 segundos e alto rendimento de até 100 MB/s (mais de 10 GB/s por tabela), o Zerobus entrega dados diretamente para sua plataforma em escala.
No entanto, o desempenho só importa se seus produtores puderem se conectar sem atrito. Uma migração deve ser tão simples quanto uma alteração de configuração. Desde que alcançou a Disponibilidade Geral no início deste ano, o Zerobus se expandiu para atender aos seus produtores de dados onde eles já operam:
- APIs compatíveis com Kafka (Beta): Seus produtores existentes do Kafka enviam dados diretamente para o Databricks — sem a necessidade de alterações no código.
- APIs gRPC e REST (GA): Fluxos gRPC persistentes para aplicativos de alto desempenho ou APIs REST sem estado para webhooks e funções serverless.
- Ecossistema de SDKs (GA): SDKs prontos para produção para Python, Java, Rust, Go e TypeScript facilitam a incorporação do Zerobus diretamente em seus aplicativos personalizados.
- OpenTelemetry (Public Preview): Envie métricas, rastreamentos e logs diretamente para o lakehouse com apenas uma alteração de configuração.
Essa flexibilidade de múltiplas interfaces fornece uma ponte direta e de baixa latência para a nuvem para empresas globais. Por exemplo, a Meta tem usado o Zerobus Ingest para conectar seus data centers locais à nuvem, permitindo o desenvolvimento rápido de soluções orientadas a dados em escala.
“Reduzimos a latência do nosso pipeline de ponta a ponta para menos de um minuto com o Zerobus Ingest e o Spark Declarative Pipelines, acelerando a geração de valor.”—Srikanth Sakhamuri, Líder de Engenharia de Dados, Meta
Assim que os dados chegam às tabelas Delta governadas pelo Unity Catalog, eles ficam instantaneamente acessíveis para ferramentas de AI e BI downstream, como o Databricks Genie. Como parte de uma pilha analítica em tempo real de ponta a ponta, o Zerobus ingere os dados e os processa usando o Modo em Tempo Real nos Pipelines Declarativos do Apache Spark™ (SDP), transforma-os, e o Lakehouse//RT, um novo tipo de data warehouse executado em um mecanismo nativo em tempo real, os serve com desempenho na escala de milissegundos.
Spark Declarative Pipelines: lote e streaming, SQL e Python, e agora em tempo real
Tradicionalmente, alcançar streaming de ultrabaixa latência forçava as equipes de dados a gerenciar arquiteturas complexas e fragmentadas, muitas vezes exigindo a manutenção de um segundo mecanismo especializado, como o Apache Flink, junto com o Spark. A Databricks resolveu inicialmente essa complexidade de dois mecanismos ao introduzir o Modo em Tempo Real (RTM) para o Spark Structured Streaming. Ao mudar de micro-lotes periódicos para processamento de fluxo contínuo, o RTM atualmente alimenta pipelines de marcas globais, incluindo Coinbase, DraftKings e MakeMyTrip.
Agora, estamos trazendo esse mesmo poder para o nosso produto de ETL unificado: o Modo em Tempo Real (RTM) para Spark Declarative Pipelines agora está em Public Preview. O RTM para SDP alcança latências de ponta a ponta de até 5 milissegundos, sem a complexidade e o custo de gerenciar mecanismos separados. Disponível em computação clássica e serverless, ele oferece streaming de ultrabaixa latência junto com os benefícios operacionais do Spark Declarative Pipelines: execução sem versão, atualizações automatizadas de infraestrutura e manutenção com tempo de inatividade mínimo ou zero.
Em seguida, estamos disponibilizando as APIs declarativas do Spark Declarative Pipelines — incluindo Append, Auto CDC, Replace Where incremental, e Materialized View — em toda a plataforma Databricks. Isso significa que os usuários podem aproveitar o processamento incremental de dados diretamente do produto, tipo de computação e interface de usuário que já conhecem. Todas essas APIs já estão disponíveis no Databricks SQL e estarão disponíveis em Notebooks serverless e no Lakeflow Designer nas próximas semanas.
Lakeflow Jobs: agora com mais de 50 integrações
A orquestração não deveria ser a parte mais desafiadora do gerenciamento do seu pipeline de dados. Quer você esteja executando DAGs de produção complexos, agendando ou acionando agentes de AI, o Lakeflow Jobs é o mecanismo de orquestração nativo da Databricks que lida com todas essas tarefas. Ao trazer orquestração gerenciada e observabilidade de ponta a ponta para cada camada do ciclo de vida dos dados, as equipes de dados estão consolidando orquestradores legados, como o Apache Airflow, em uma única plataforma unificada.
Orquestração com reconhecimento de dados e contexto
Cada agendamento cron é apenas uma estimativa de quando os dados estarão prontos. O Lakeflow Jobs permite que você pare de adivinhar e comece a acionar pipelines com base na prontidão real dos dados. Usando linguagem natural, você pode pedir ao Genie para escrever os gatilhos SQL que definem o que “pronto” significa para os seus dados. Seu job é executado assim que as condições são atendidas, respeitando seus contratos de dados e garantindo que você nunca processe dados desatualizados.
“Com o Lakeflow Jobs, conseguimos acessar dados que as tecnologias legadas não conseguiam alcançar, o que nos permitiu gerar insights de negócios mais profundos e confiáveis.”—Sachin Wadhwa, Diretor de Arquitetura e Plataformas de Dados, The Rank Group
Orquestração universal para qualquer coisa, em qualquer lugar
Para clientes com fluxos de trabalho de dados fora do Databricks, o Lakeflow Jobs oferece a Orquestração Externa para estender nativamente seu alcance a sistemas externos, sem exigir que você reconstrua integrações do zero. Ao usar uma estrutura de operadores aberta, você pode acionar facilmente jobs do Snowflake, disparar APIs REST personalizadas ou gerenciar alertas do Slack e do PagerDuty. A computação é suspensa de forma inteligente enquanto aguarda condições externas que podem levar horas para ocorrer. Estamos publicando mais de 40 exemplos de operadores no GitHub e adicionando dezenas de integrações gerenciadas nos próximos trimestres. Além disso, todas as credenciais passam pelo Unity Catalog e possuem uma trilha de auditoria completa.
Como começar a usar o Lakeflow
Lakeflow oferece a base de dados unificada de que você precisa para criar aplicações de AI confiáveis e baseadas em agentes. Para se aprofundar nas configurações técnicas e ver esses novos recursos em ação, explore nossos tutoriais práticos ou revise nossa documentação técnica para começar seu próximo projeto.
Pronto para criar? Experimente o Databricks gratuitamente para testar o Lakeflow hoje mesmo.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.