Lakeflow: A new era of agentic data engineering
The unified, real-time data foundation your enterprise can trust
by Bilal Aslam, Ray Zhu, Manish Dalwadi, Saad Ansari and Giselle Goicochea
- Unified foundation for agentic AI: Lakeflow unifies ingestion, transformation, and orchestration under Unity Catalog, eliminating the gap caused by tool sprawl and giving AI agents a single source of trusted, real-time context.
- High-performance ingestion and streaming: Connect to 100+ enterprise data sources with Lakeflow Connect, stream high-volume event data via multiple interfaces on Zerobus Ingest, and millisecond latency with Real-Time Mode for Spark Declarative Pipelines.
- Agentic development and operations: Build pipelines visually with Lakeflow Designer, accelerate authoring with Genie Code, and reduce operational toil with Genie ZeroOps, and consolidate legacy orchestrators with Lakeflow Jobs.
All analytics, AI, and applications start with data. Over the past few decades, data engineering tools have proliferated across a range of use cases and user personas. The result is that most enterprises end up with a very complex and fragmented data stack that is hard to integrate, maintain, or govern. With AI powering all data and AI practitioners, even more pressure will be placed on these brittle data stacks.
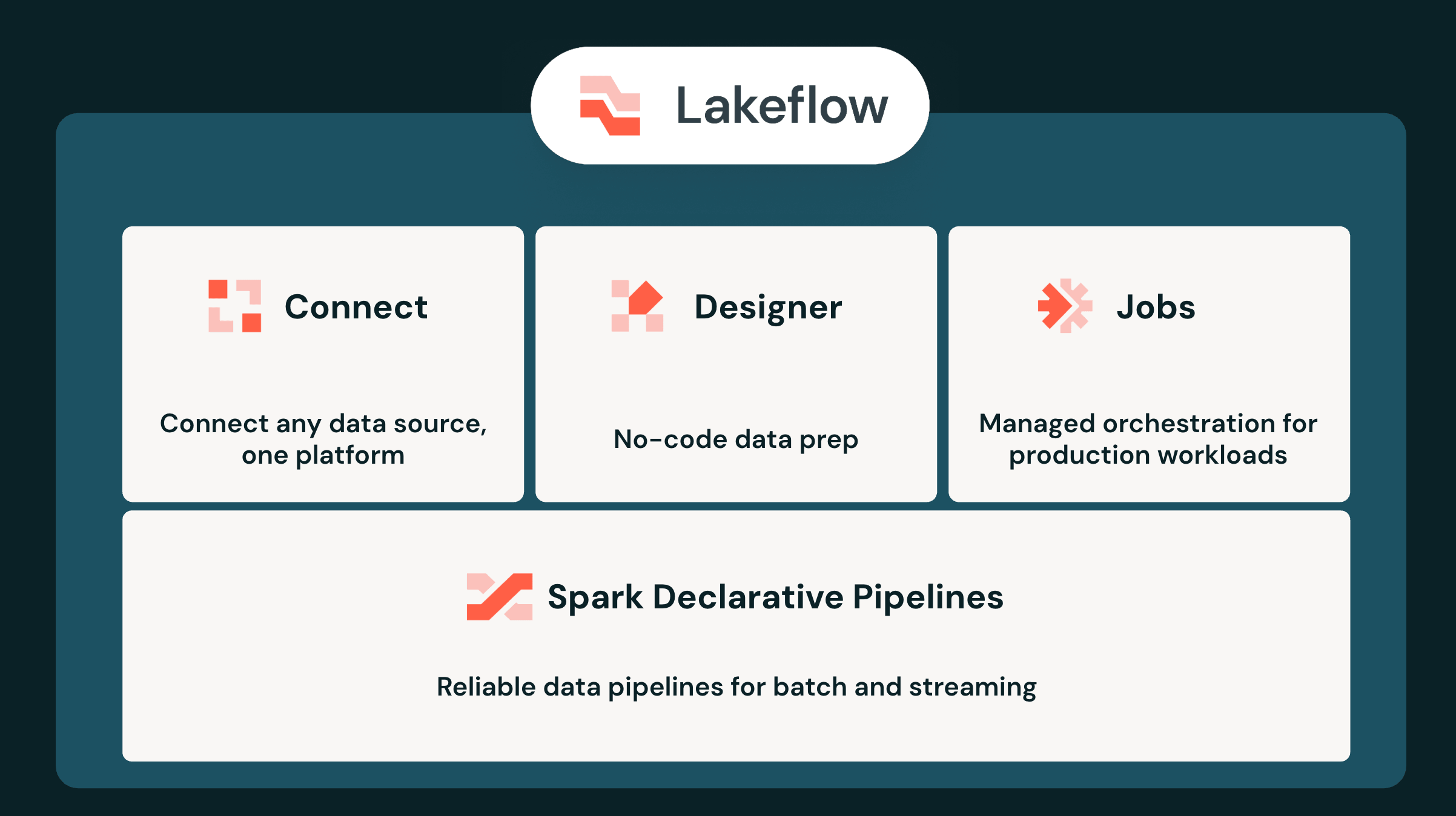
This is why we set out to build Databricks Lakeflow, a unified platform for all of data engineering from ingestion, to transformation and orchestration. All Lakeflow capabilities are fully integrated and centrally governed by Unity Catalog. In the agentic era, this unified architecture offers significant advantages, enabling agents not only to build but also to operate your data pipelines. Today, at the Data + AI Summit, we’re announcing the next major evolution of Databricks Lakeflow.
Genie Code and Lakeflow Designer: agentic pipeline development
Genie Code is now deeply integrated into every aspect of the Lakeflow user experience. You can use Genie Code to create ingestion connectors, build pipelines in Python and SQL and develop jobs with tasks, triggers and dependencies. All of this is made possible by the unified data engineering stack, which provides Genie Code with full end-to-end context across your ingestion, transformation, and orchestration workloads.
Now generally available, Lakeflow Designer democratizes data engineering across the enterprise. This visual, AI-powered, no-code interface empowers teams to build pipelines using a drag-and-drop canvas and natural-language prompts. Business analysts and non-technical users can build production-ready ETL pipelines without writing code. Every visual Flow built in Designer natively runs on a production-ready Spark Declarative Pipeline, ensuring zero translation loss without complex handoffs. Data engineers can easily review and refine this code directly in place without switching context or rewriting logic.
Genie ZeroOps: Put data and AI operations on autopilot
Announced today, Genie ZeroOps helps data teams operate data and AI assets in production. Genie ZeroOps is a purpose-built background AI agent that monitors and manages data and AI assets. ZeroOps detects failures and performs root-cause analysis to identify what went wrong using data quality metrics, error logs, and lineage data from Unity Catalog. Furthermore, it generates proposed fixes and validates them in a safe and isolated sandbox environment governed by Unity Catalog. Applying a fix is done with human-in-the-loop, so Genie ZeroOps does the heavy lifting, and you stay in control. Similar to agentic development, the functionality of Genie ZeroOps is only possible because of the full context awareness and end-to-end governance enabled by a unified data stack with Lakeflow.
Lakeflow Connect: Fast-growing ecosystem with 100+ built-in connectors
Automated pipelines are only as valuable as the data flowing through them. To build a complete "enterprise memory" and ground AI agents like Databricks Genie, you need seamless access to the latest governed context spanning every area of your business. Lakeflow Connect simplifies this process by incrementally ingesting fresh data from an ever-growing list of enterprise systems directly into Unity Catalog-governed Delta tables.
Today, we’re announcing that Lakeflow Connect is expanding to support more than 100 native, managed connectors across enterprise applications, databases, file sources and cloud storage. You can now eliminate brittle third-party tools and run optimized ingestion pipelines for the use cases that customers need most:
- Enterprise Knowledge Management: Unify business data from Jira (Beta), GitHub (Beta), and Confluence (GA) alongside unstructured documents, contracts, and PDFs from SharePoint (Beta), Google Drive (Beta), and Outlook (Beta). Power context-aware AI applications, support agents, and intelligent document processing on a single foundation.
- MarTech: Ingest campaign and customer data directly from Meta Ads (Beta), TikTok Ads (Beta), Google Ads (Beta), and HubSpot (GA) to drive real-time personalization.
- IT & Security Operations: Centralize logs and telemetry for robust SIEM analysis.
- Query-based capture for all database connectors and Lakehouse Federation sources (GA): Query the database directly for change capture without the need for log parsing.
For organizations with specialized or proprietary systems, Community Connectors (Beta) provide an open source solution built on Databricks. Deploy a pre-built connector from the community or build your own to share across your organization or the broader ecosystem.
Panasonic used Lakeflow Connect to unify data from SAP, Workday, and SharePoint, replacing brittle, legacy ETL with a single platform for real-time, governed intelligence.
“By moving from a rigid legacy ETL stack to the Databricks Platform, our BI teams can now easily discover and access critical data, cutting Power BI refresh times by 50%. We’re turning external, inconsistent data into trusted, production-grade assets that unlock new business insights and strengthen Panasonic’s competitive edge.”—Jerry Deng, BI Director, Panasonic
We’re also making it easier for organizations to permanently lower the TCO of high-volume ingestion with the Lakeflow Connect Free Tier. Customers automatically receive 100 free DBUs per day, supporting up to 100 million records daily across popular managed SaaS and database connectors.
Zerobus Ingest: Kafka-free ingestion for your data producers
Zerobus Ingest is changing how organizations handle high-volume event data, no message bus required. Near real-time writes in under 5 seconds and high throughput up to 100MB/s (over 10GB/s per table), Zerobus delivers data directly to your platform at scale.
However, performance only matters if your producers can connect without friction. A migration should be as simple as a config change. Since reaching General Availability earlier this year, Zerobus has expanded to meet your data producers where they already operate:
- Kafka-Compatible APIs (Beta - coming soon): Your existing Kafka producers push data straight to Databricks—no code changes required.
- gRPC & REST APIs (GA): Persistent gRPC streams for high-performance applications, or stateless REST APIs for webhooks and serverless functions.
- SDK Ecosystem (GA): Production-ready SDKs for Python, Java, Rust, Go, and TypeScript make it easy to embed Zerobus directly into your custom applications.
- OpenTelemetry (Public Preview): Send metrics, traces, and logs directly to the lakehouse with just a configuration change.
This multi-interface flexibility provides a direct, low-latency bridge to the cloud for global enterprises. For example, Meta has been using Zerobus Ingest to bridge its on-premises data centers to the cloud, enabling rapid development of data-driven solutions at scale.
“We cut our end-to-end pipeline latency to under a minute with Zerobus Ingest and Spark Declarative Pipelines, enabling faster time to value.”—Srikanth Sakhamuri, Data Engineering Leader, Meta
Once data lands in Unity Catalog-governed Delta tables, it’s instantly accessible to downstream AI and BI tools like Databricks Genie. As part of an end-to-end real-time analytic stack, Zerobus ingests the data and processes it using Real-Time Mode in Apache Spark™Declarative Pipelines (SDP) transforms it, and Lakehouse//RT, a new data warehouse type running on a fully native real-time engine, serves it at millisecond-scale performance.
Spark Declarative Pipelines: Batch and streaming, SQL and Python, and now real-time
Achieving ultra-low-latency streaming has traditionally forced data teams to manage complex, fragmented architectures, often requiring the maintenance of a second specialized engine, such as Apache Flink, alongside Spark. Databricks initially solved this dual-engine complexity by introducing Real-Time Mode (RTM) for Spark Structured Streaming. By shifting from periodic microbatching to continuous stream processing, RTM currently powers pipelines for global brands including Coinbase, DraftKings, and MakeMyTrip.
Now, we are bringing that same power to our unified ETL product: Real-Time Mode (RTM) for Spark Declarative Pipelines is now in Public Preview. RTM for SDP achieves end-to-end latencies as low as 5 milliseconds without the complexity and cost of managing separate engines. Available on both classic and serverless compute, it delivers ultra-low-latency streaming alongside the operational benefits of Spark Declarative Pipelines: versionless execution, automated infrastructure upgrades, and low-to-zero downtime maintenance.
Next, we are making the declarative APIs from Spark Declarative Pipelines—including Append, Auto CDC, incremental Replace Where, and Materialized View—available everywhere on the Databricks Platform. This means users can take advantage of incremental data processing directly from the product, compute type, and user interface they already know. All of these APIs are now available in Databricks SQL and will be available in serverless Notebooks and Lakeflow Designer in the next few weeks.
Lakeflow Jobs: Now with 50+ integrations
Orchestration shouldn’t be the most challenging part of managing your data pipeline. Whether you are running complex production DAGs, scheduling, or firing AI agents, Lakeflow Jobs is Databricks' native orchestration engine that handles all of these tasks. By bringing managed orchestration and end-to-end observability into every layer of the data lifecycle, data teams are consolidating legacy orchestrators, such as Apache Airflow, onto a single, unified platform.
Data and context-aware orchestration
Every cron schedule is a guess at when data is ready. Lakeflow Jobs lets you stop guessing and start triggering pipelines based on actual data readiness. By using plain English, you can ask Genie to write the SQL triggers that define what “ready” means in your data. Your job fires as soon as conditions are met, respecting your data contracts and ensuring you never process stale data.
“With Lakeflow Jobs, we were able to tap into data that legacy technologies could not access, empowering us to generate deeper, more reliable business insights."—Sachin Wadhwa, Director of Data Architecture and Platforms, The Rank Group
Universal orchestration for anything, anywhere
For customers with data workflows outside Databricks, Lakeflow Jobs provides External Orchestration to natively extend your reach to external systems without requiring you to rebuild integrations from scratch. By using an open operator framework, you can seamlessly trigger Snowflake jobs, fire custom REST APIs, or manage Slack and PagerDuty alerts. Compute is intelligently suspended while waiting for external conditions that may be hours away. We're publishing 40+ operator examples on GitHub and adding dozens of managed integrations in the coming quarters. In addition, every credential flows through Unity Catalog and has a full audit trail.
Getting started with Lakeflow
Lakeflow provides the unified data foundation you need to build reliable, agentic AI applications. To dive deeper into the technical configurations and see these new features in action, explore our hands-on tutorials or review our technical documentation to get started on your next project.
Ready to build? Try Databricks for free to experience Lakeflow today.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.