Escalabilidade de Memória para Agentes de IA
O dimensionamento de inferência trouxe os LLMs a um ponto em que podem raciocinar sobre a maioria das situações práticas, desde que tenham o contexto certo. Para muitos agentes do mundo real, o gargalo não é mais a capacidade de raciocínio, mas sim a ancoragem do agente nas informações corretas: dar ao modelo o que ele precisa para a tarefa em questão.
Isso sugere um novo eixo para o design de agentes. Em vez de focar apenas em modelos mais fortes ou melhores prompts, podemos perguntar: o agente melhora à medida que acumula mais informações? Chamamos isso de dimensionamento de memória: a propriedade de que o desempenho do agente melhora com a quantidade de conversas passadas, feedback do usuário, trajetórias de interação (bem-sucedidas e falhas) e contexto de negócios armazenados em sua memória. O efeito é especialmente pronunciado em ambientes corporativos, onde o conhecimento tribal é abundante e um único agente atende a muitos usuários.
Mas isso não é óbvio a priori. Mais memória não torna um agente melhor automaticamente: rastros de baixa qualidade podem ensinar lições erradas, e a recuperação se torna mais difícil à medida que o armazenamento cresce. A questão central é se os agentes podem usar memórias maiores produtivamente, em vez de simplesmente acumulá-las.
Demos os primeiros passos nessa direção na Databricks por meio de ALHF e MemAlign, que ajustam o comportamento do agente com base no feedback humano, e o Instructed Retriever, que permite que agentes de busca traduzam instruções complexas de linguagem natural e esquemas de fontes de conhecimento em consultas de busca precisas e estruturadas. Juntos, esses sistemas demonstram que os agentes podem ser mais úteis por meio de memória persistente. Este post apresenta resultados experimentais que demonstram o comportamento de dimensionamento de memória, discute a infraestrutura necessária para suportá-lo em produção e fornece uma visão prospectiva de agentes baseados em memória.
O que é Dimensionamento de Memória?
Dimensionamento de memória é a propriedade de que o desempenho de um agente melhora à medida que sua memória externa cresce. Aqui, "memória" se refere a um armazenamento persistente de informações com o qual o agente pode interagir no momento da inferência, distinto dos pesos do modelo ou da janela de contexto atual.
Isso torna o dimensionamento de memória um eixo distinto e complementar ao dimensionamento paramétrico e ao dimensionamento no momento da inferência, abordando lacunas no conhecimento de domínio e na ancoragem que nem o tamanho do modelo nem a capacidade de raciocínio podem fechar por si só. As melhorias devido ao dimensionamento de memória não se limitam à qualidade da resposta. Quando um agente memorizou os esquemas relevantes, regras de domínio ou ações passadas bem-sucedidas para um ambiente, ele pode pular a exploração redundante e resolver consultas mais rapidamente. Em nossos experimentos, observamos dimensionamento tanto em precisão quanto em eficiência.
Relação com aprendizado contínuo
O aprendizado contínuo geralmente se concentra na atualização dos parâmetros do modelo ao longo do tempo, o que funciona bem em ambientes limitados, mas se torna computacionalmente caro e frágil com muitos usuários concorrentes, agentes e projetos em rápida mudança. O dimensionamento de memória faz uma pergunta diferente: um agente com milhares de usuários tem um desempenho melhor do que um com um único usuário? Ao expandir o estado externo compartilhado de um agente enquanto mantém os pesos do LLM congelados, a resposta pode ser sim — um padrão de fluxo de trabalho aprendido com um usuário pode ser recuperado e aplicado a outro imediatamente, sem nenhum retreinamento. Esta é uma propriedade que o aprendizado contínuo, focado como está nas atualizações de parâmetros do modelo de um único usuário, nunca foi projetado para fornecer.
Relação com contexto longo
Grandes janelas de contexto podem parecer um substituto para a memória, mas elas abordam problemas diferentes. Empacotar milhões de tokens brutos em um prompt aumenta a latência, eleva os custos de computação e degrada a qualidade do raciocínio, pois tokens irrelevantes competem pela atenção. O dimensionamento de memória depende, em vez disso, de recuperação seletiva — decidindo não apenas quanta informação incluir, mas o que incluir, apresentando apenas as informações de alto sinal relevantes para a tarefa atual.
Tipos de Memória
Nem todas as memórias servem ao mesmo propósito. Duas distinções importam na prática:
Episódica vs. semântica. Memórias episódicas são registros brutos de interações passadas — logs de conversas, trajetórias de chamadas de ferramentas, feedback do usuário. Memórias semânticas são habilidades e fatos generalizados extraídos dessas interações (por exemplo, "usuários neste espaço sempre significam trimestre fiscal quando dizem 'trimestre'"). Cada tipo requer diferentes estratégias de armazenamento, processamento e recuperação: memórias episódicas para recuperação direta e memórias semânticas extraídas por um LLM para correspondência de padrões mais ampla.
Pessoal vs. organizacional. Algumas memórias são específicas das preferências e fluxos de trabalho de um único usuário; outras representam conhecimento organizacional compartilhado — convenções de nomenclatura, consultas comuns, regras de negócios. O sistema de memória deve escopar a recuperação e as atualizações apropriadamente: apresentar o conhecimento organizacional amplamente, mantendo o contexto individual privado, respeitando permissões e ACLs.
Experimentos: MemAlign no Genie Space
MemAlign é nossa exploração sobre como pode ser uma estrutura de memória simples para agentes de IA. Ele armazena interações passadas como memórias episódicas, usa um LLM para extrair regras e padrões generalizados (memórias semânticas) e recupera as entradas mais relevantes no momento da inferência para guiar o agente. Para detalhes sobre a estrutura, consulte nosso post anterior do blog.
Testamos o MemAlign no Databricks Genie Spaces, uma interface de linguagem natural onde usuários de negócios fazem perguntas sobre dados em inglês simples e recebem respostas baseadas em SQL. Um exemplo da consulta e resposta da tarefa é fornecido abaixo
Nosso objetivo é medir como o desempenho do agente escala à medida que o alimentamos com mais memória, usando duas fontes de dados: exemplos curados (rotulados) e logs de conversas de usuários brutos (não rotulados).
Dimensionamento com dados rotulados
Avaliamos o MemAlign em perguntas não vistas distribuídas por 10 espaços Genie, adicionando incrementalmente fragmentos de exemplos de treinamento anotados à memória do agente. Nossa linha de base é um agente que usa instruções Genie curadas por especialistas (esquemas de tabelas escritos manualmente, regras de domínio e exemplos de few-shot).
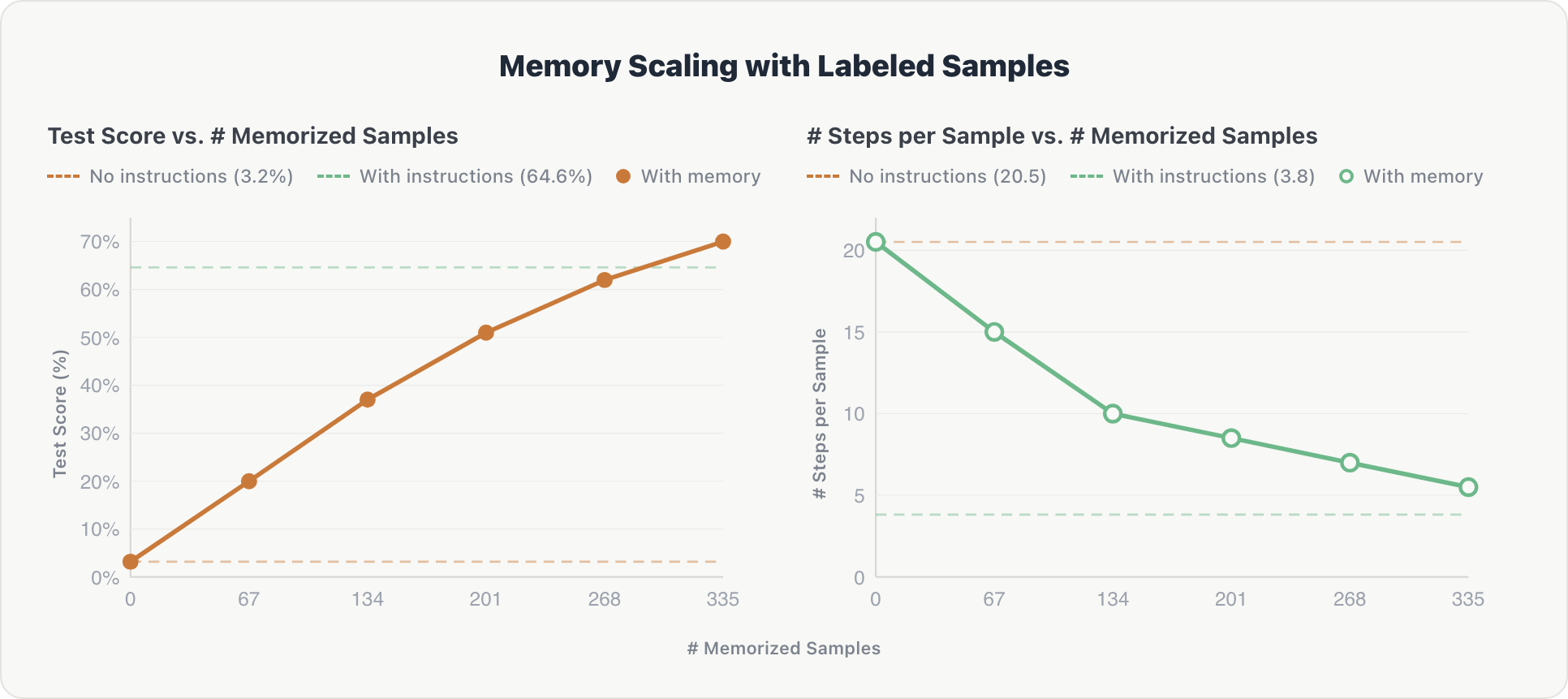
Os resultados mostram um dimensionamento consistente em ambas as dimensões:
Precisão. As pontuações de teste aumentaram constantemente com cada fragmento de memória adicional, subindo de perto de zero para 70%, superando finalmente a linha de base curada por especialistas em ~5%. Após inspeção, os dados rotulados por humanos provaram ser mais abrangentes e, portanto, mais úteis do que esquemas de tabelas e regras de domínio escritos manualmente.
Eficiência. O número médio de etapas de raciocínio por exemplo caiu de ~20 para ~5 à medida que a memória crescia. O agente aprendeu a recuperar o contexto relevante diretamente em vez de explorar o banco de dados do zero, aproximando-se da eficiência das instruções codificadas (~3,8 etapas).
O efeito é cumulativo: como as amostras memorizadas abrangem 10 espaços Genie diferentes, cada fragmento contribui com informações interdomínio que se baseiam no conhecimento prévio.
Dimensionamento com logs de usuários não rotulados
A memória pode escalar com dados ruidosos do mundo real? Para descobrir, executamos o MemAlign em um espaço Genie ativo e o alimentamos com logs de conversas de usuários históricos sem respostas ideais. Um juiz LLM filtrou esses logs quanto à utilidade, e apenas os de alta qualidade foram memorizados.
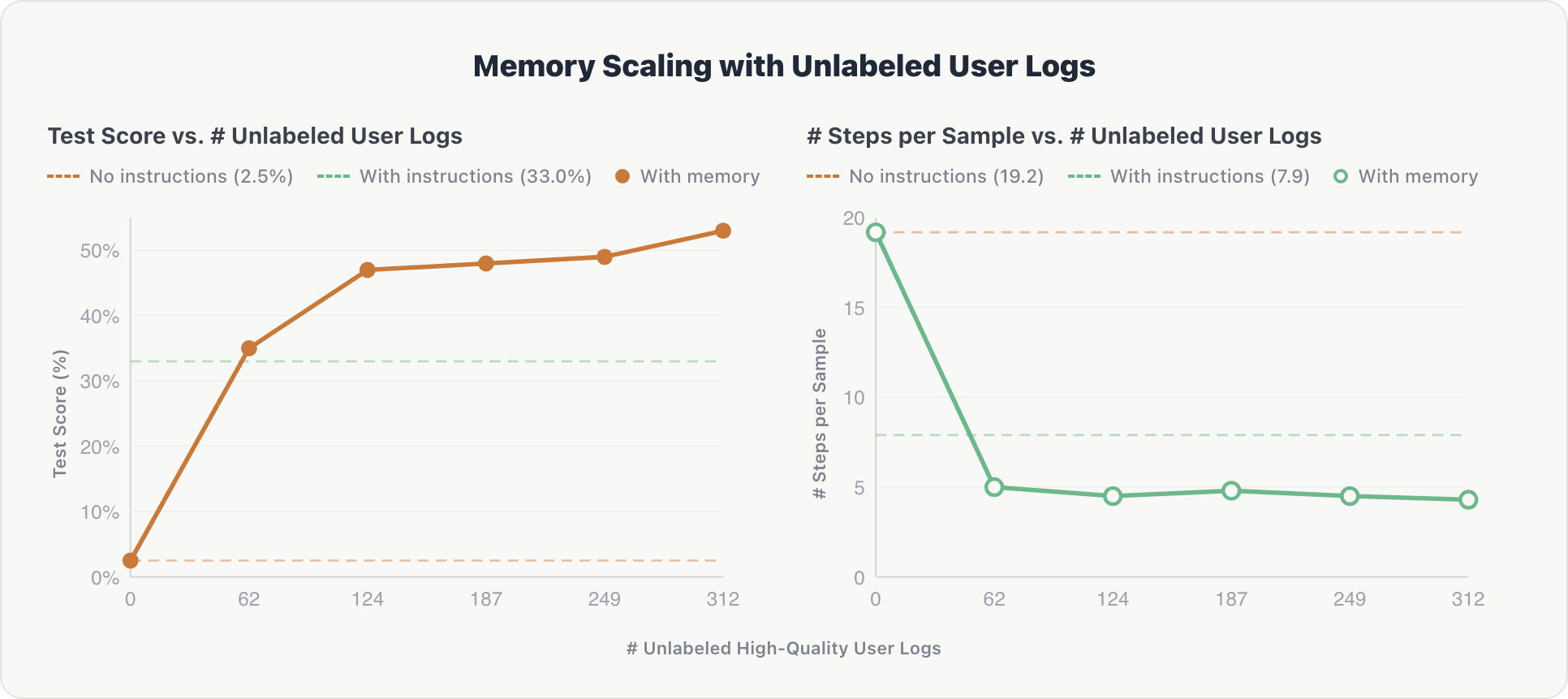
A curva de dimensionamento segue um padrão semelhante e é mais acentuada no início:
Precisão. O agente mostrou um ganho inicial acentuado. Após o primeiro fragmento de log, ele extraiu informações-chave sobre tabelas relevantes e preferências implícitas do usuário. O desempenho subiu de 2,5% para mais de 50%, superando a linha de base curada por especialistas (33,0%) após apenas 62 registros de log.
Eficiência. As etapas de raciocínio caíram de ~19 para ~4,3 após o primeiro fragmento e permaneceram estáveis. O agente internalizou o esquema do espaço precocemente e evitou exploração redundante em consultas subsequentes.
A conclusão: interações de usuários não curadas, filtradas apenas por um juiz automatizado e sem referência, podem substituir as instruções de domínio de engenharia manual, caras e demoradas. Isso também aponta para agentes que melhoram continuamente com o uso normal e podem escalar além das limitações da anotação humana.
Experimentos: Armazenamento de Conhecimento Organizacional
Os experimentos acima mostram como a escalabilidade da memória ocorre com as interações do usuário. Mas as empresas também possuem conhecimento existente que antecede qualquer interação do usuário: esquemas de tabelas, consultas de painéis, glossários de negócios e documentação interna. Testamos se pré-computar esse conhecimento organizacional em um repositório de memória estruturado poderia melhorar o desempenho do agente.
Avaliamos esse repositório de conhecimento em um benchmark interno de pesquisa de dados e no PMBench, que testa a busca exaustiva de fatos em documentos internos mistos, como notas de reuniões de gerentes de produto e materiais de planejamento.
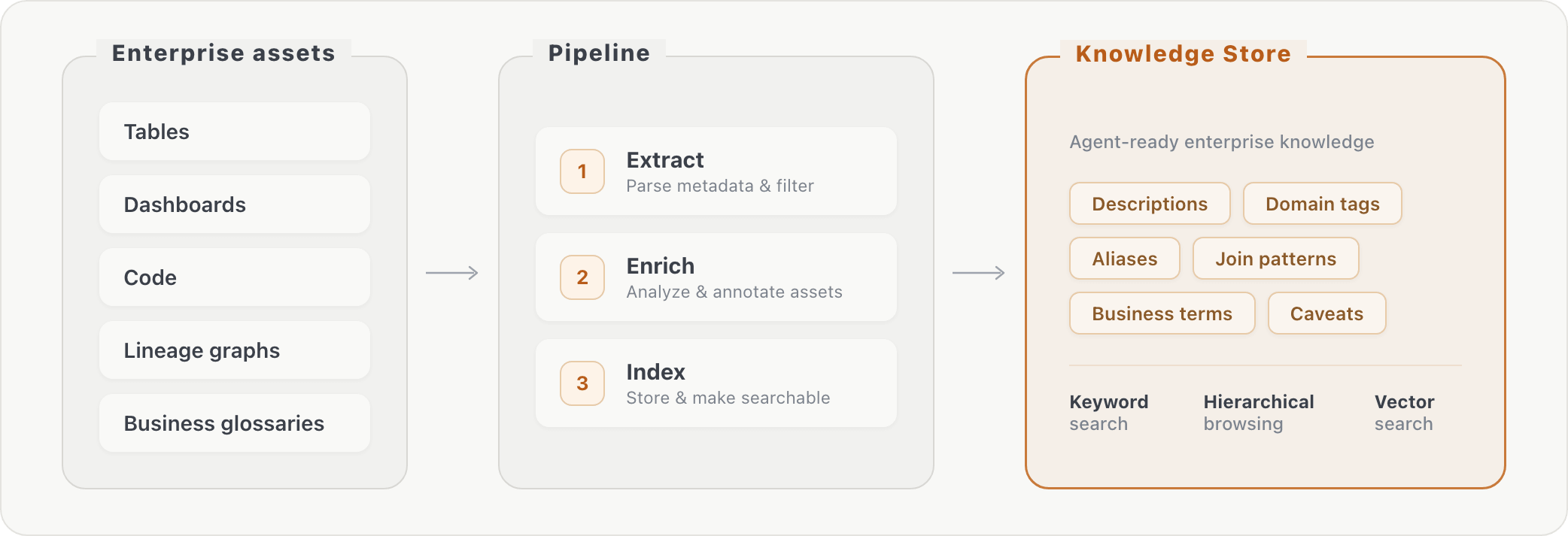
Nosso pipeline processa metadados brutos de banco de dados em conhecimento recuperável em três estágios: (1) extração de informações sobre ativos, (2) enriquecimento de ativos por meio de transformações adicionais e (3) indexação do conteúdo enriquecido. No momento da consulta, o agente pode consultar o contexto empresarial por meio de pesquisa por palavra-chave ou navegação hierárquica. Isso preenche a lacuna entre como os usuários de negócios formulam perguntas ("consumo de IA") e como os dados são realmente armazenados (nomes de colunas específicos em tabelas específicas).
A adição do repositório de conhecimento melhorou a precisão em aproximadamente 10% em ambos os benchmarks avaliados. Os ganhos foram concentrados em perguntas que exigiam correspondência de vocabulário, junções de tabelas e conhecimento em nível de coluna, ou seja, informações que o agente não poderia ter descoberto apenas pela exploração do esquema.
Infraestrutura para Escalabilidade de Memória
A escalabilidade da memória em implantações empresariais requer uma infraestrutura robusta além de um simples repositório vetorial. Nas próximas seções, discutiremos três desafios chave que essa infraestrutura precisa abordar: armazenamento escalável, gerenciamento de memória e governança.
Armazenamento Escalável
O armazenamento de memória mais simples é o sistema de arquivos: arquivos markdown em pastas hierárquicas, navegados e pesquisados com ferramentas de shell padrão. A memória baseada em arquivos funciona bem em pequena escala e para usuários individuais, mas carece de indexação, consultas estruturadas e pesquisa de similaridade eficiente. À medida que a memória cresce para milhares de entradas em muitos usuários, a recuperação degrada e a governança se tornam difíceis de impor.
Repositórios de dados dedicados são o próximo passo natural. Bancos de dados vetoriais independentes lidam bem com a pesquisa semântica, mas carecem de capacidades relacionais como junções e filtragem. Sistemas modernos baseados em PostgreSQL oferecem uma alternativa mais unificada: eles suportam nativamente consultas estruturadas, pesquisa de texto completo e pesquisa de similaridade vetorial em um único motor.
Variantes serverless dessa arquitetura que separam o armazenamento da computação e fornecem armazenamento durável e de baixo custo são uma opção natural. Temos usado o Lakebase, construído sobre o motor PostgreSQL serverless da Neon, graças ao seu custo escalável a zero e suporte para pesquisa vetorial e exata. O ramificação de banco de dados integrada também simplifica o ciclo de desenvolvimento — engenheiros podem criar forks do estado de memória do agente para testes sem afetar a produção.
Gerenciamento de Memória
Armazenamento escalável por si só não é suficiente. Um sistema de memória também deve gerenciar seu conteúdo:
- Inicialização. Novos agentes são conhecidos por sofrerem problemas de cold-start. A ingestão de ativos empresariais existentes (wikis, documentação, guias internos) por meio de análise e extração de documentos fornece uma base de memória inicial que pode aliviar alguns desses problemas, como demonstrado por nossos experimentos com repositórios de conhecimento organizacional.
- Destilação. Memórias episódicas brutas são úteis para recuperação direta, mas se tornam caras para armazenar e pesquisar em escala. Destilá-las periodicamente em memórias semânticas (regras e padrões compactados) mantém o repositório de memória tratável e fornece insights generalizáveis ao agente, que podem não ser evidentes apenas pela memória episódica.
- Consolidação. À medida que a memória cresce, é importante manter o sistema consistente, compacto e atualizado. Isso requer pipelines que removam duplicatas, podam informações desatualizadas e resolvam conflitos entre entradas antigas e novas.
Segurança
A memória introduz requisitos de governança que não existem para agentes sem estado. À medida que os agentes acumulam conhecimento profundamente contextual, incluindo preferências do usuário, fluxos de trabalho proprietários e padrões de dados internos, os mesmos princípios de governança que se aplicam aos dados empresariais devem se estender à memória do agente.
Os controles de acesso devem ser cientes da identidade: memórias individuais devem permanecer privadas, enquanto o conhecimento organizacional pode ser compartilhado dentro de limites controlados por acesso. Isso se alinha naturalmente com o tipo de permissões granulares que plataformas como o Unity Catalog já aplicam a ativos de dados, como segurança em nível de linha, mascaramento de colunas e controle de acesso baseado em atributos.
Estender esses controles às entradas de memória significa que um agente que recupera contexto para um usuário não pode inadvertidamente expor as interações privadas de outro usuário.
Além do controle de acesso, a linhagem de dados e a auditabilidade são importantes. Quando o comportamento de um agente é moldado por sua memória, as equipes precisam rastrear quais memórias influenciaram uma determinada resposta e quando essas memórias foram criadas ou atualizadas. Requisitos de conformidade e regulatórios, especialmente em setores regulamentados, exigem que os repositórios de memória suportem as mesmas garantias de observabilidade que os dados subjacentes: rastreamento completo de linhagem, políticas de retenção e a capacidade de excluir entradas específicas mediante solicitação.
Garantir que a memória certa chegue ao usuário certo, e apenas a esse usuário, é um problema central de design em escala.
O Que Atrapalha
Todo eixo de escalabilidade eventualmente encontra seu próprio gargalo. A escalabilidade paramétrica é limitada pelo fornecimento de dados de treinamento de alta qualidade. A escalabilidade no tempo de inferência pode se degenerar em excesso de pensamento, onde cadeias de raciocínio mais longas adicionam custo sem adicionar sinal, degradando o desempenho à medida que o comprimento da sequência aumenta. A escalabilidade da memória tem limites análogos: problemas de qualidade, escopo e acesso.
A qualidade da memória é difícil de manter. Algumas memórias estão erradas desde o início; outras se tornam erradas com o tempo. Um agente sem estado comete erros isolados, mas um agente com memória pode transformar um erro em um erro recorrente, armazenando-o e recuperando-o posteriormente como evidência. Vimos agentes citarem notebooks de execuções anteriores que estavam errados, e então reutilizarem esses resultados com ainda mais confiança. A desatualização é mais sutil: um agente que aprendeu o esquema do último trimestre pode continuar consultando tabelas que desde então foram renomeadas ou excluídas. A filtragem na ingestão ajuda, mas os sistemas de produção precisam de mais do que filtragem. Eles precisam de proveniência, estimativas de confiança, sinais de atualização e revalidação periódica.
A governança deve se estender à destilação. Escalar a memória em uma organização requer a destilação de interações repetidas em memórias semânticas reutilizáveis. Mas a abstração não remove a sensibilidade. Uma memória como "para a empresa Y, junte as tabelas CRM, inteligência de mercado e parcerias" pode parecer inofensiva, mas ainda revelar interesse confidencial em aquisições. O desafio é tornar a memória amplamente útil sem transformar padrões privados em conhecimento compartilhado. Controles de acesso e rótulos de sensibilidade devem sobreviver à destilação, não apenas à ingestão.
Memórias úteis podem permanecer inacessíveis. Mesmo que a memória esteja correta e atualizada, o agente ainda precisa descobrir que ela existe. A recuperação é inerentemente metacognitiva: o agente deve decidir o que perguntar ao seu repositório de memória antes de saber o que há nele. Quando ele falha em antecipar que uma memória relevante pode ajudar, ele nunca emite a consulta correta e recorre à exploração lenta e redundante. Na prática, a lacuna entre o conhecimento armazenado e o conhecimento acessível pode ser o principal limitador da escalabilidade da memória.
Esses não são argumentos contra a escalabilidade da memória. São os problemas de pesquisa que ainda precisam ser resolvidos para tornar a escalabilidade da memória robusta. O problema central não é apenas armazenar mais histórico; é ensinar o agente a encontrar a memória certa, como usá-la apropriadamente e como mantê-la atualizada e com o escopo correto.
Olhando para o Futuro: O Agente como Memória
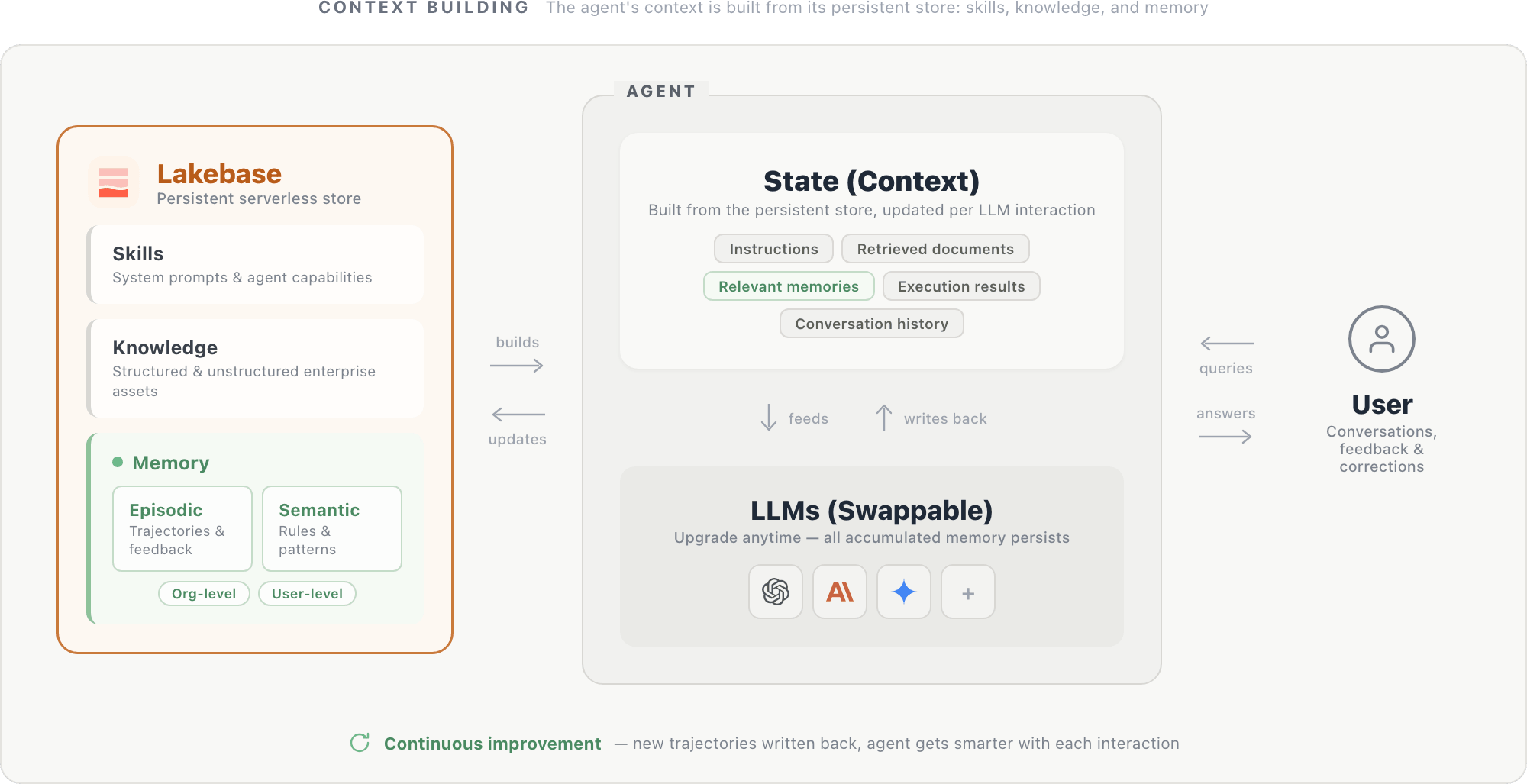
Os experimentos e a infraestrutura acima apontam para um padrão de design natural: um agente cuja identidade reside em sua memória, não em seus pesos de modelo.
Neste design, o contexto de um agente é construído a partir de um repositório persistente hospedado em um banco de dados serverless como o Lakebase. O repositório contém três componentes: prompts do sistema e capacidades do agente (habilidades), ativos empresariais estruturados e não estruturados (conhecimento) e memórias episódicas e semânticas com escopo no nível da organização e do usuário. Juntos, esses componentes formam o estado do agente: instruções, documentos recuperados, memórias relevantes, resultados de execução (de consultas SQL, chamadas de API e outras ferramentas) e histórico de conversas. Esse estado é alimentado ao LLM a cada etapa e atualizado após cada interação.
O próprio LLM é um motor de raciocínio substituível: a atualização para um modelo mais novo é simples, pois o novo modelo lê do mesmo repositório persistente e se beneficia imediatamente de todo o contexto acumulado.
À medida que os modelos de fundação convergem em capacidade, o diferencial para agentes empresariais será cada vez mais a memória que eles acumularam, em vez de qual modelo eles chamam. Hipoteticamente, um modelo menor com um rico repositório de memória pode superar um modelo maior com menos memória — se for o caso, investir em infraestrutura de memória pode render maiores retornos do que escalar parâmetros do modelo. Conhecimento de domínio, preferências do usuário e padrões operacionais específicos da sua organização não estão em nenhum modelo de fundação. Eles só podem ser construídos através do uso e, ao contrário das capacidades do modelo, são exclusivos de cada implantação.
Conclusão
Propomos a Escala de Memória, onde o desempenho de um agente melhora à medida que ele acumula mais experiência através da interação do usuário e do contexto de negócios na memória. Nossos experimentos iniciais mostram que tanto a precisão quanto a eficiência escalam com a quantidade de informação armazenada na memória externa.
A realização disso em produção requer sistemas de armazenamento que unifiquem a busca estruturada e não estruturada, pipelines de gerenciamento que mantenham a memória consistente e controles de governança que definam o escopo de acesso apropriadamente. Estes são problemas solucionáveis com a tecnologia atual. O benefício é ter agentes que genuinamente melhoram com o uso contínuo.
O trabalho restante é substancial: a memória tem que permanecer precisa, atualizada e acessível à medida que cresce. Mas é exatamente por isso que a escala de memória é interessante. Ela abre uma agenda concreta de sistemas e pesquisa para construir agentes que melhoram com o uso contínuo de maneiras que são específicas para cada organização e problema.
Autores: Wenhao Zhan, Veronica Lyu, Jialu Liu, Michael Bendersky, Matei Zaharia, Xing Chen
Gostaríamos de agradecer a Kenneth Choi, Sam Havens, Andy Zhang, Ziyi Yang, Ashutosh Baheti, Sean Kulinski, Alexander Trott, Will Tipton, Gavin Peng, Rishabh Singh e Patrick Wendell por seus valiosos feedbacks ao longo do projeto.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.