Memory scaling for AI agents
Inference scaling has brought LLMs to where they can reason through most practical situations, provided they have the right context. For many real-world agents, the bottleneck is no longer reasoning capacity, but grounding the agent in the correct information: giving the model what it needs for the task at hand.
This suggests a new axis for agent design. Rather than focusing solely on stronger models or better prompts, we can ask: does the agent get better as it accumulates more information? We call this memory scaling: the property that agent performance improves with the amount of past conversations, user feedback, interaction trajectories (both successful and failed), and business context stored in its memory. The effect is especially pronounced in enterprise settings, where tribal knowledge is abundant and a single agent serves many users.
But this is not obvious a priori. More memory does not automatically make an agent better: low-quality traces can teach the wrong lessons, and retrieval gets harder as the store grows. The central question is whether agents can use larger memories productively rather than simply accumulate them.
We've made early steps in this direction at Databricks through ALHF and MemAlign, which adjust agent behavior based on human feedback, and the Instructed Retriever, which enables search agents to translate complex natural-language instructions and knowledge-source schemas into precise, structured search queries. Together, these systems demonstrate that agents can be more helpful through persistent memory. This post presents experimental results demonstrating memory scaling behavior, discusses the infrastructure required to support it in production, and provides a forward looking vision of memory-based agents.
What Is Memory Scaling?
Memory scaling is the property that an agent's performance improves as its external memory grows. Here "memory" refers to a persistent store of information the agent can interact with at inference time, distinct from the model's weights or the current context window.
This makes memory scaling a distinct and complementary axis to both parametric scaling and inference-time scaling, addressing gaps in domain knowledge and grounding that neither model size nor reasoning capability can close on their own.The improvements due to memory scaling are not limited to answer quality. When an agent has memorized the relevant schemas, domain rules, or successful past actions for an environment, it can skip redundant exploration and resolve queries faster. In our experiments, we observe scaling in both accuracy and efficiency.
Relationship to continual learning
Continual learning typically focuses on updating model parameters over time, which works well in bounded settings but becomes computationally expensive and brittle with many concurrent users, agents, and rapidly shifting projects. Memory scaling asks a different question: does an agent with thousands of users perform better than one with a single user? By expanding an agent's shared external state while keeping LLM weights frozen, the answer can be yes — a workflow pattern learned from one user can be retrieved and applied for another immediately, without any retraining. This is a property that continual learning, focused as it is on a single user’s model parameter updates, was never designed to provide.
Relationship to long context
Large context windows might seem like a substitute for memory, but they address different problems. Packing millions of raw tokens into a prompt increases latency, raises compute costs, and degrades reasoning quality as irrelevant tokens compete for attention. Memory scaling relies instead on selective retrieval — deciding not just how much context to include, but what to include, surfacing only the high-signal information relevant to the current task.
Types of Memory
Not all memories serve the same purpose. Two distinctions matter in practice:
Episodic vs. semantic. Episodic memories are raw records of past interactions — conversation logs, tool-call trajectories, user feedback. Semantic memories are generalized skills and facts distilled from those interactions (e.g., "users in this space always mean fiscal quarter when they say 'quarter'"). Each type requires different storage, processing, and retrieval strategies: episodic memories for direct retrieval and semantic memories distilled by an LLM for broader pattern matching.
Personal vs. organizational. Some memories are specific to a single user's preferences and workflows; others represent shared organizational knowledge — naming conventions, common queries, business rules. The memory system must scope retrieval and updates appropriately: surface organizational knowledge broadly while keeping individual context private, respecting permissions and ACLs.
Experiments: MemAlign on Genie Space
MemAlign is our exploration into what a simple memory framework can look like for AI agents. It stores past interactions as episodic memories, uses an LLM to distill them into generalized rules and patterns (semantic memories), and retrieves the most relevant entries at inference time to guide the agent. For details on the framework, see our earlier blog post.
We tested MemAlign on Databricks Genie Spaces, a natural-language interface where business users ask data questions in plain English and receive SQL-based answers. An example of the task query and answer is provided below.
Our goal is to measure how agent performance scales as we feed it more memory, using two data sources: curated examples (labeled) and raw user conversation logs (unlabeled).
Scaling with labeled data
We evaluated MemAlign on unseen questions spread across 10 Genie spaces, incrementally adding shards of annotated training examples to the agent's memory. Our baseline is an agent using expert-curated Genie instructions (manually written table schemas, domain rules, and few-shot examples).
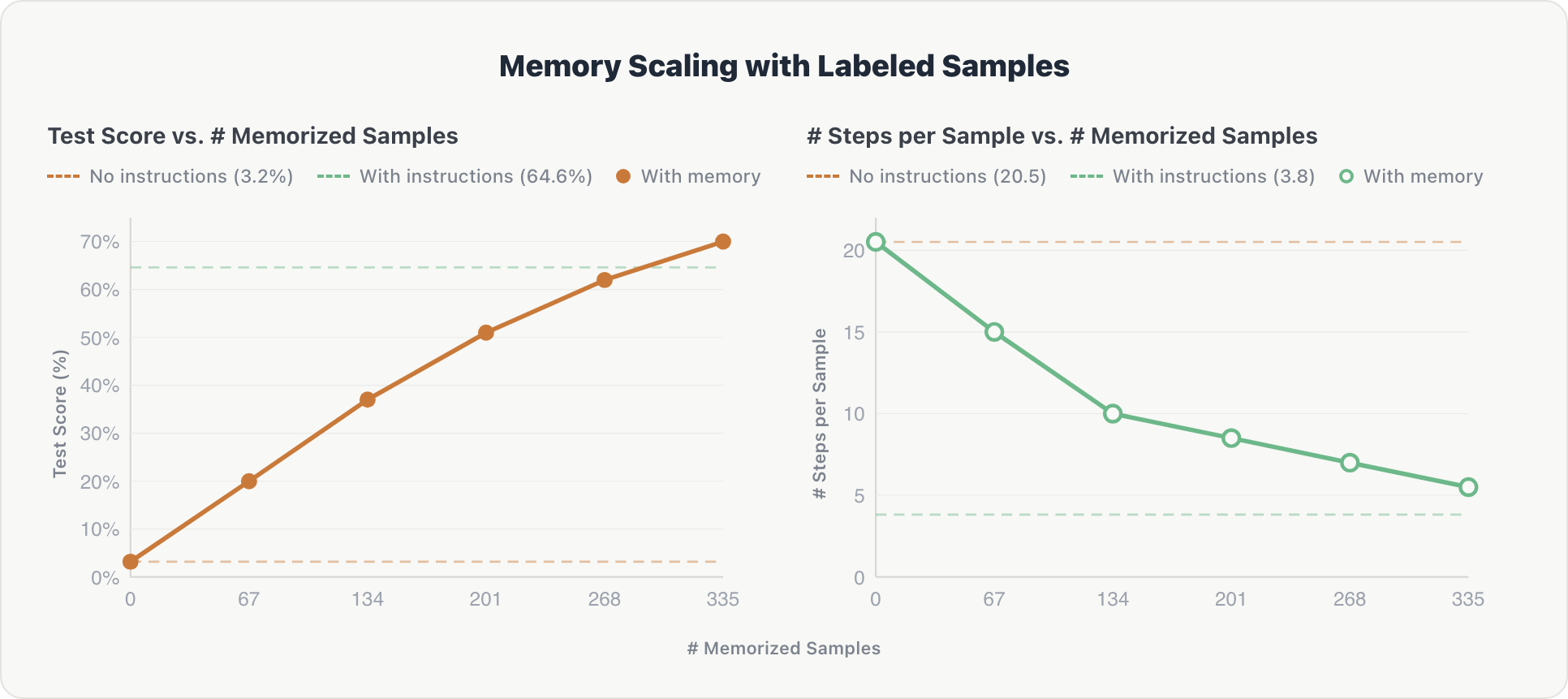
The results show consistent scaling along both dimensions:
Accuracy. Test scores increased steadily with each additional memory shard, rising from near zero to 70%, ultimately surpassing the expert-curated baseline by ~5%. Upon inspection, human-labeled data proved more comprehensive and therefore more useful than manually written table schemas and domain rules.
Efficiency. The average number of reasoning steps per example dropped from ~20 to ~5 as memory grew. The agent learned to retrieve relevant context directly rather than exploring the database from scratch, approaching the efficiency of hardcoded instructions (~3.8 steps).
The effect is cumulative: because the memorized samples span 10 different Genie spaces, each shard contributes cross-domain information that builds on prior knowledge.
Scaling with unlabeled user logs
Can memory scale with noisy, real-world data? To find out, we ran MemAlign in a live Genie space and fed it historical user conversation logs with no gold answers. An LLM judge filtered these logs for helpfulness, and only the high-quality ones were memorized.
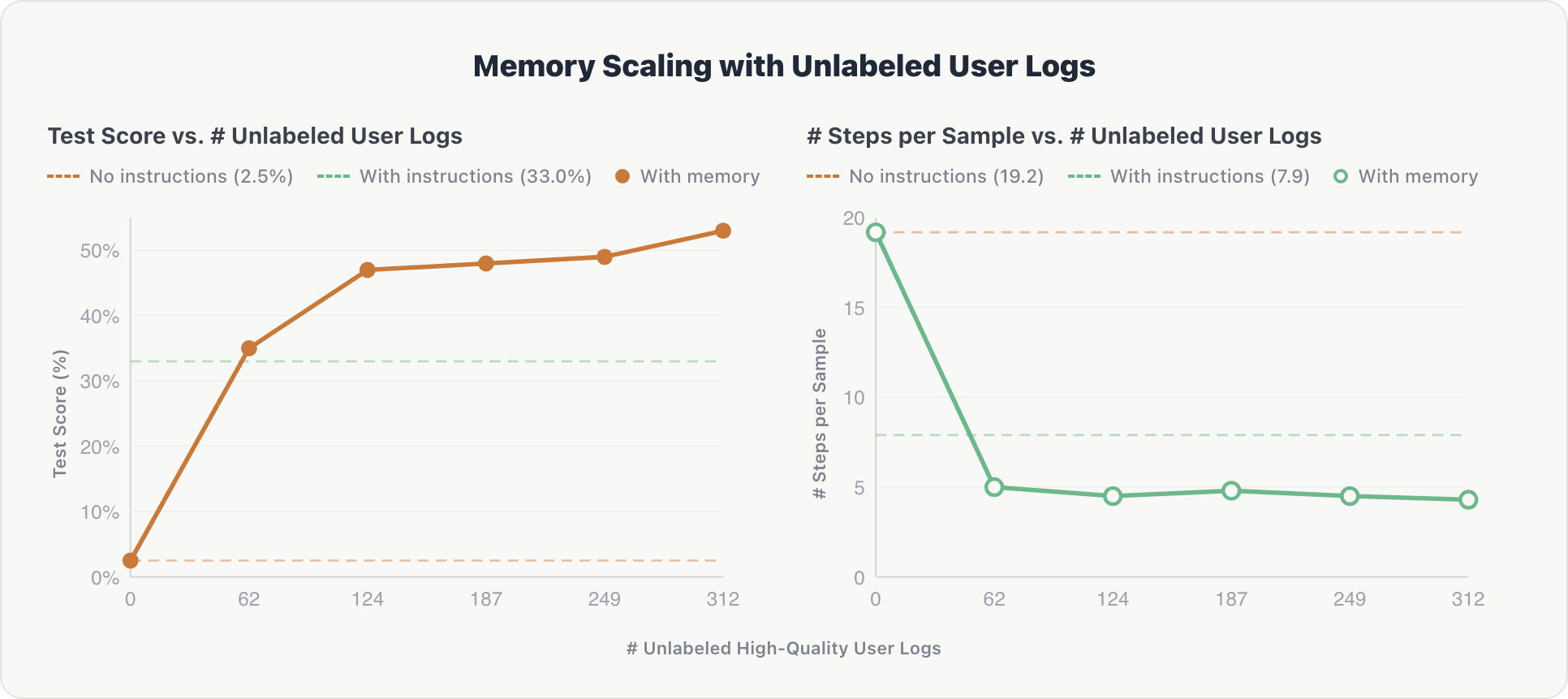
The scaling curve follows a similar pattern and is steeper at the beginning:
Accuracy. The agent showed a sharp initial gain. After the first log shard, it extracted key information about relevant tables and implicit user preferences. Performance rose from 2.5% to over 50%, surpassing the expert-curated baseline (33.0%) after just 62 log records.
Efficiency. Reasoning steps dropped from ~19 to ~4.3 after the first shard and remained stable. The agent internalized the space's schema early and avoided redundant exploration on subsequent queries.
The takeaway: uncurated user interactions, filtered only by an automated, reference-free judge, can substitute for the costly and time consuming hand-engineered domain instructions. This also points toward agents that improve continuously from normal usage and can scale beyond the limitations of human annotation.
Experiments: Organizational Knowledge Store
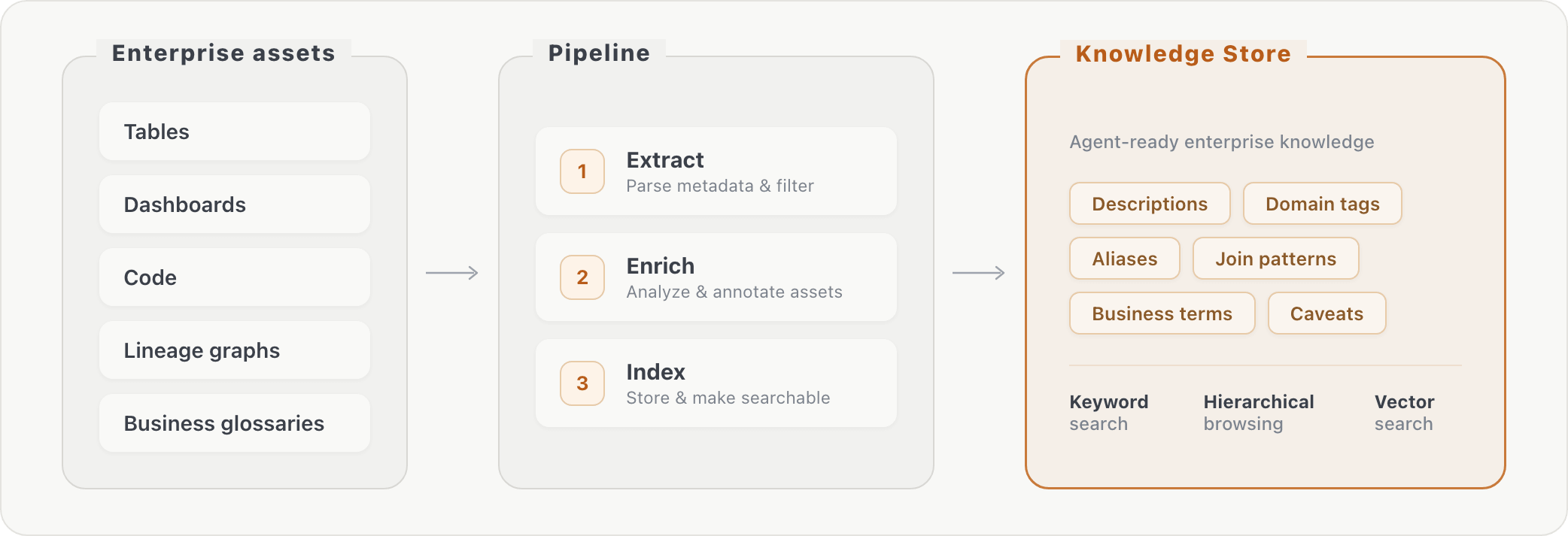
The experiments above show how memory scaling happens with user interactions. But enterprises also have existing knowledge that predates any user interaction: table schemas, dashboard queries, business glossaries, and internal documentation. We tested whether pre-computing this organizational knowledge into a structured memory store could improve agent performance.
We evaluated this knowledge store on an internal data research benchmark and on PMBench, which tests exhaustive fact search over mixed internal documents like product manager meeting notes and planning materials.
Our pipeline processes raw database metadata into retrievable knowledge in three stages: (1) extraction of information about assets, (2) asset enrichment via additional transformations, and (3) indexing of the enriched content. At query time, the agent can look up enterprise context via keyword search or hierarchical browsing. This bridges the gap between how business users phrase questions ("AI consumption") and how data is actually stored (specific column names in specific tables).
Adding the knowledge store improved accuracy by roughly 10% on both evaluated benchmarks. The gains were concentrated on questions that required vocabulary bridging, table joins, and column-level knowledge, i.e., information the agent could not have discovered through schema exploration alone.
Infrastructure for Memory Scaling
Memory scaling in enterprise deployments requires a robust infrastructure beyond a simple vector store. In what follows, we will discuss three key challenges that this infrastructure needs to address: scalable storage, memory management, and governance.
Scalable Storage
The simplest memory storage is the file system: markdown files in hierarchical folders, browsed and searched with standard shell tools. File-based memory works well at small scale and for individual users, but it lacks indexing, structured queries, and efficient similarity search. As memory grows to thousands of entries across many users, retrieval degrades and governance becomes difficult to enforce.
Dedicated data stores are the natural next step. Standalone vector databases handle semantic search well but lack relational capabilities like joins and filtering. Modern PostgreSQL-based systems offer a more unified alternative: they natively support structured queries, full-text search, and vector similarity search in a single engine.
Databricks users can already build stateful agents using serverless variants of this architecture that separate storage from compute, and provide low-cost, durable storage. We've been using Lakebase, built on Neon's serverless PostgreSQL engine, thanks to its scale-to-0 cost and support for both vector and exact search. Built-in database branching also simplifies the development cycle — engineers can fork the agent's memory state for testing without affecting production.
Memory Management
Scalable storage alone is not enough. A memory system must also manage its contents:
- Bootstrapping. New agents are known to suffer from cold-start problems. Ingesting existing enterprise assets (wikis, documentation, internal guides) through document parsing and extraction provides an initial memory base that can alleviate some of these problems, as demonstrated by our organizational knowledge store experiments.
- Distillation. Raw episodic memories are useful for direct retrieval but become expensive to store and search at scale. Periodically distilling them into semantic memories (compressed rules and patterns) keeps the memory store tractable, and provides generalizable insights to the agent, which may not be evident from episodic memory alone.
- Consolidation. As memory grows, it is important to keep the system consistent, compact, and up-to-date. This requires pipelines that remove duplicates, prune outdated information, and resolve conflicts between old and new entries.
Security
Memory introduces governance requirements that do not exist for stateless agents. As agents accumulate deeply contextual knowledge, including user preferences, proprietary workflows, and internal data patterns, the same governance principles that apply to enterprise data must extend to agent memory.
Access controls must be identity-aware: individual memories should remain private, while organizational knowledge can be shared within access-controlled bounds. This maps naturally to the kind of fine-grained permissions that platforms like Unity Catalog already enforce for data assets, such as row-level security, column masking, and attribute-based access control.
Extending these controls to memory entries means an agent retrieving context for one user cannot inadvertently surface another user's private interactions.
Beyond access control, data lineage and auditability matter. When an agent's behavior is shaped by its memory, teams need to trace which memories influenced a given response and when those memories were created or updated. Compliance and regulatory requirements, particularly in regulated industries, demand that memory stores support the same observability guarantees as the underlying data: full lineage tracking, retention policies, and the ability to purge specific entries on request.
Ensuring that the right memory reaches the right user, and only that user, is a central design problem at scale.
What Gets in the Way
Every scaling axis eventually runs into its own bottleneck. Parametric scaling is constrained by the supply of high-quality training data. Inference-time scaling can devolve into overthinking, where longer chains of reasoning add cost without adding signal, ultimately degrading performance as sequence length increases. Memory scaling has analogous limits: problems of quality, scope, and access.
Memory quality is hard to maintain. Some memories are wrong from the start; others become wrong over time. A stateless agent makes isolated mistakes, but a memory-equipped agent can turn one mistake into a recurring one by storing it and retrieving it later as evidence. We have seen agents cite notebooks from earlier runs that were themselves wrong, then reuse those results with even more confidence. Staleness is subtler: an agent that learned last quarter's schema may keep querying tables that have since been renamed or deleted. Filtering at ingestion helps, but production systems need more than filtering. They need provenance, confidence estimates, freshness signals, and periodic re-validation.
Governance must extend to distillation. Scaling memory across an organization requires distilling repeated interactions into reusable semantic memories. But abstraction does not remove sensitivity. A memory like "for company Y, join the CRM, market-intelligence, and partnership tables" may look harmless while still revealing confidential acquisition interest. The challenge is to make memory broadly useful without turning private patterns into shared knowledge. Access controls and sensitivity labels have to survive distillation, not just ingestion.
Useful memories may remain unreachable. Even if memory is accurate and current, the agent still has to discover that it exists. Retrieval is inherently meta-cognitive: the agent must decide what to ask its memory store before it knows what is in there. When it fails to anticipate that a relevant memory might help, it never issues the right query and falls back to slow, redundant exploration. In practice, the gap between stored knowledge and accessible knowledge may be the main limiter on memory scaling.
These are not arguments against memory scaling. They are the research problems that still need to be solved to make memory scaling robust. The central problem is not just storing more history; it is teaching the agent how to find the right memory, how to use it appropriately, and how to keep it current and properly scoped.
Looking Ahead: The Agent as Memory
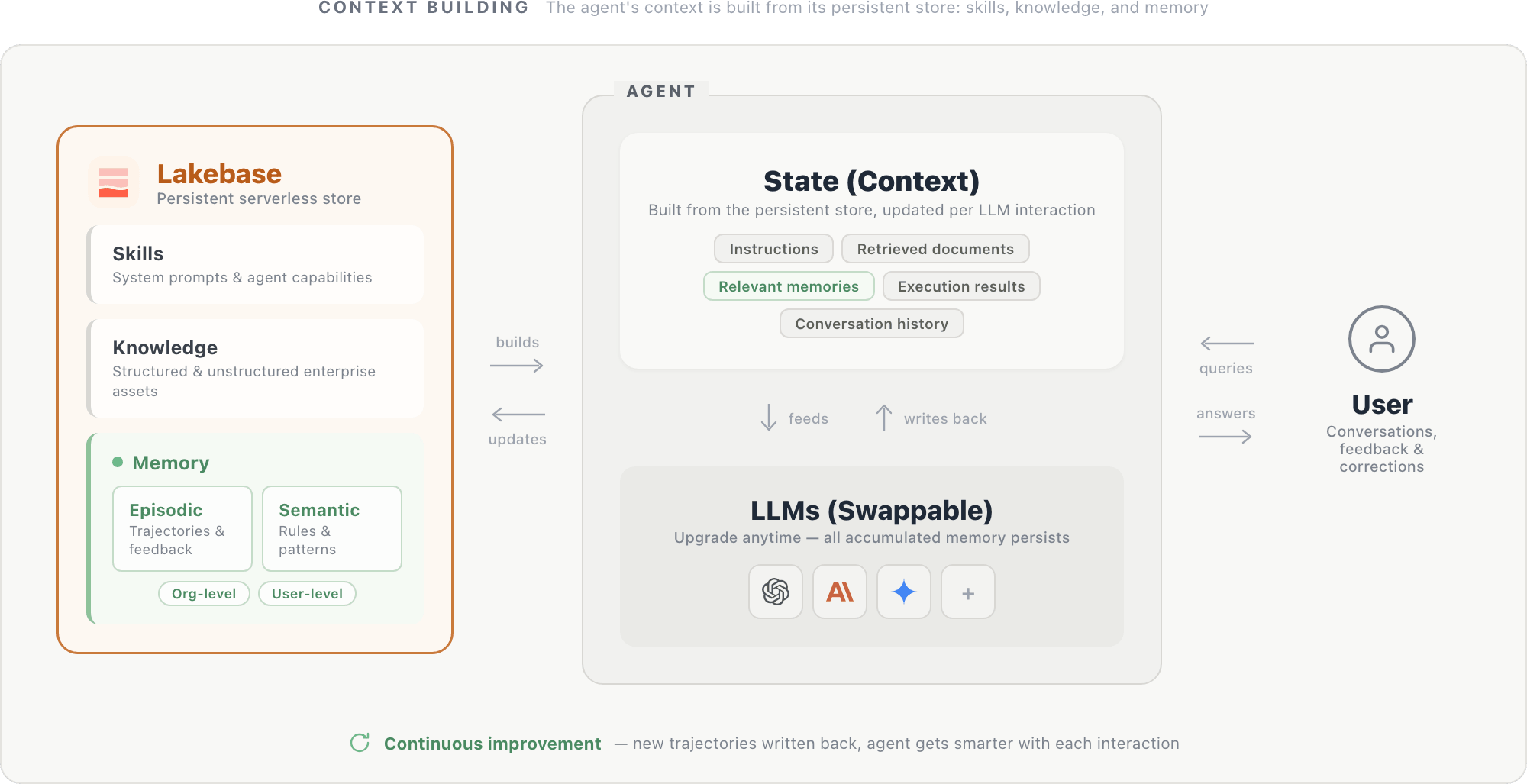
The experiments and infrastructure above point toward a natural design pattern: an agent whose identity lives in its memory, not its model weights.
In this design, an agent's context is built from a persistent store housed in a serverless database like Lakebase. The store holds three components: system prompts and agent capabilities (skills), structured and unstructured enterprise assets (knowledge), and episodic and semantic memories scoped at the organization and user level. Together, these components form the agent's state: instructions, retrieved documents, relevant memories, execution results (from SQL queries, API calls, and other tools), and conversation history. This state is fed to the LLM at each step and updated after each interaction.
The LLM itself is a swappable reasoning engine: upgrading to a newer model is straightforward, since the new model reads from the same persistent store and immediately benefits from all accumulated context.
As foundation models converge in capability, the differentiator for enterprise agents will increasingly be what memory they have accumulated rather than which model they call. Hypothetically, a smaller model with a rich memory store can outperform a larger model with less memory — if so, investing in memory infrastructure could yield greater returns than scaling model parameters. Domain knowledge, user preferences, and operational patterns specific to your organization are not in any foundation model. They can only be built up through use, and unlike model capabilities, they are unique to each deployment.
Conclusion
We propose Memory Scaling, where an agent’s performance improves as it accumulates more experience through user interaction and business context into memory. Our initial experiments show that both accuracy and efficiency scale with the amount of information stored in external memory.
Realizing this in production requires storage systems that unify structured and unstructured search, management pipelines that keep memory consistent, and governance controls that scope access appropriately. These are solvable problems with current technology. The payoff is agents that genuinely improve with continued use.
The remaining work is substantial: memory has to stay accurate, current, and accessible as it grows. But that is exactly why memory scaling is interesting. It opens a concrete systems and research agenda for building agents that get better with continued use in ways that are specific to each organization and problem.
Authors: Wenhao Zhan, Veronica Lyu, Jialu Liu, Michael Bendersky, Matei Zaharia, Xing Chen
We’d like to thank Kenneth Choi, Sam Havens, Andy Zhang, Ziyi Yang, Ashutosh Baheti, Sean Kulinski, Alexander Trott, Will Tipton, Gavin Peng, Rishabh Singh, Jenny Sun, Siddharth Murching, and Patrick Wendell for their valuable feedback throughout the project.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.