10 billones de muestras al día: Escalando más allá de la infraestructura de monitoreo tradicional en Databricks
Cómo construimos una plataforma de monitoreo diseñada para el crecimiento exponencial de Databricks
por David Yuan, Yi Jin, Karan Bavishi, HC Zhu y Joey Beyda
- Los sistemas de monitoreo de Databricks administran más de 5 mil millones de series temporales activas en tiempo real en AWS, Azure y GCP.
- Para mantener estos sistemas confiables y de bajo mantenimiento a pesar de la rápida escalada, rediseñamos nuestras capas de TSDB y agregación personalizando soluciones de monitoreo de código abierto.
- Ante el fuerte crecimiento de métricas de solución de problemas de alta cardinalidad, desarrollamos una plataforma novedosa basada en Lakehouse llamada Hydra. Este enfoque ha desbloqueado capacidades de depuración enriquecidas a escala masiva y con un almacenamiento 50 veces más barato que nuestra pila existente.
La infraestructura de monitoreo de Databricks ha crecido más del triple en el último año, rastreando ahora 5 mil millones de series temporales activas en tiempo real e ingiriendo más de 10 billones de muestras por día. A esta escala masiva, descubrimos que las soluciones listas para usar eran ineficientes o difíciles de adaptar a nuestros requisitos. Esta publicación comparte lo que construimos en su lugar: una plataforma escalable que aprovecha lo mejor del ecosistema de monitoreo de código abierto, al tiempo que incorpora personalizaciones para nuestras necesidades únicas.
Los ingenieros de Databricks dependen de sistemas de monitoreo que nos alertan rápidamente sobre problemas, automatizan el escalado y las reversiones, y permiten la resolución de problemas inteligente. Estos sistemas deben ser altamente confiables para que podamos estar seguros de que no operaremos a ciegas durante un incidente potencial. Sin embargo, desarrollar esta infraestructura a la escala de Databricks demostró no ser tarea fácil:
- Además de los requisitos de escalabilidad, confiabilidad y eficiencia, operamos nuestros sistemas a nivel mundial en aproximadamente 70 regiones en la nube en cada una de las 3 principales nubes. Necesitamos admitir un rendimiento equivalente a pesar de las diferencias entre nubes, e incluso entre regiones individuales.
- Ante esta amplitud y variedad, operar infraestructura a gran escala puede volverse rápidamente insostenible. El sistema debe ser lo más "automático" posible, auto-reparable y auto-escalable, en lugar de que nuestro personal de guardia gestione directamente cada pila regional, y aún así proporcionar interfaces sencillas para los usuarios.
- Con el crecimiento de las cargas de trabajo serverless y de IA en Databricks, la rotación en nuestra infraestructura se ha disparado, causando rápidos aumentos en la cardinalidad de las métricas. Ya no podíamos procesar y almacenar datos de monitoreo de alta cardinalidad como lo habíamos hecho siempre, pero aún así nuestro objetivo era mantener los flujos de trabajo de depuración en los que confían los ingenieros.
Frente a estos desafíos, la antigua pila de monitoreo de Databricks sufría problemas de confiabilidad. Nos propusimos desarrollar una plataforma nueva y confiable que cumpliera con las expectativas de nuestros ingenieros. Desde entonces, hemos abordado 3 problemas clave:
- Arquitectura de una base de datos de series temporales (TSDB) confiable y eficiente
- Introducción de la agregación de métricas para proteger las TSDB de la cardinalidad
- Habilitación de la resolución de problemas altamente dimensional con el lakehouse de Databricks
Bases de datos de series temporales Thanos
¿Qué son las TSDB?
Las TSDB son un componente central de las arquitecturas de sistemas de monitoreo tradicionales. Estas bases de datos especializadas están diseñadas para ingerir grandes cantidades de datos de métricas de series temporales y servir lecturas en tiempo real de alta QPS y baja latencia. Son especialmente óptimas para patrones de consulta de monitoreo como alertas y actualizaciones de paneles, que requieren emitir el mismo conjunto de consultas repetidamente y obtener resultados ultrarrápidos basados en los datos más recientes.
Las antiguas TSDB de Databricks se habían construido para una escala de magnitud inferior y se convirtieron en un cuello de botella importante para nosotros en los últimos años. De hecho, el problema de confiabilidad número 1 para toda la infraestructura de monitoreo fue la dificultad de escalar nuestras TSDB. Esta es una operación infrecuente para muchas otras empresas, pero algo que necesitábamos hacer casi a diario dado el crecimiento exponencial de Databricks.
Así que desarrollamos una nueva TSDB con el nombre en clave Pantheon, que es una bifurcación del proyecto de código abierto CNCF Thanos. Hemos escalado con éxito a más de 160 instancias de Thanos en todas las regiones en tres proveedores de nube, con un total de alrededor de 5 mil millones de series temporales activas en memoria y más de 10 billones de muestras ingeridas diariamente. Nuestra instancia más grande alberga alrededor de 300 millones de series temporales en memoria y admite casi 1000 consultas PromQL por segundo; también ejecutamos pequeñas implementaciones de 3 nodos y todo lo intermedio. Debido a la amplitud, escala y variedad de nuestras implementaciones, a menudo descubrimos casos extremos y optimizaciones de rendimiento de Thanos y los contribuimos a la comunidad de código abierto.
Migrar a Pantheon nos ha permitido ahorrar millones de dólares en costos anuales de nube, al tiempo que reducimos el tiempo de inactividad de la infraestructura de monitoreo en ~5 veces y eliminamos muchas fuentes de trabajo manual. La arquitectura de Pantheon se muestra a continuación, y las siguientes secciones explican varias decisiones clave de diseño que hicieron posibles estos logros.
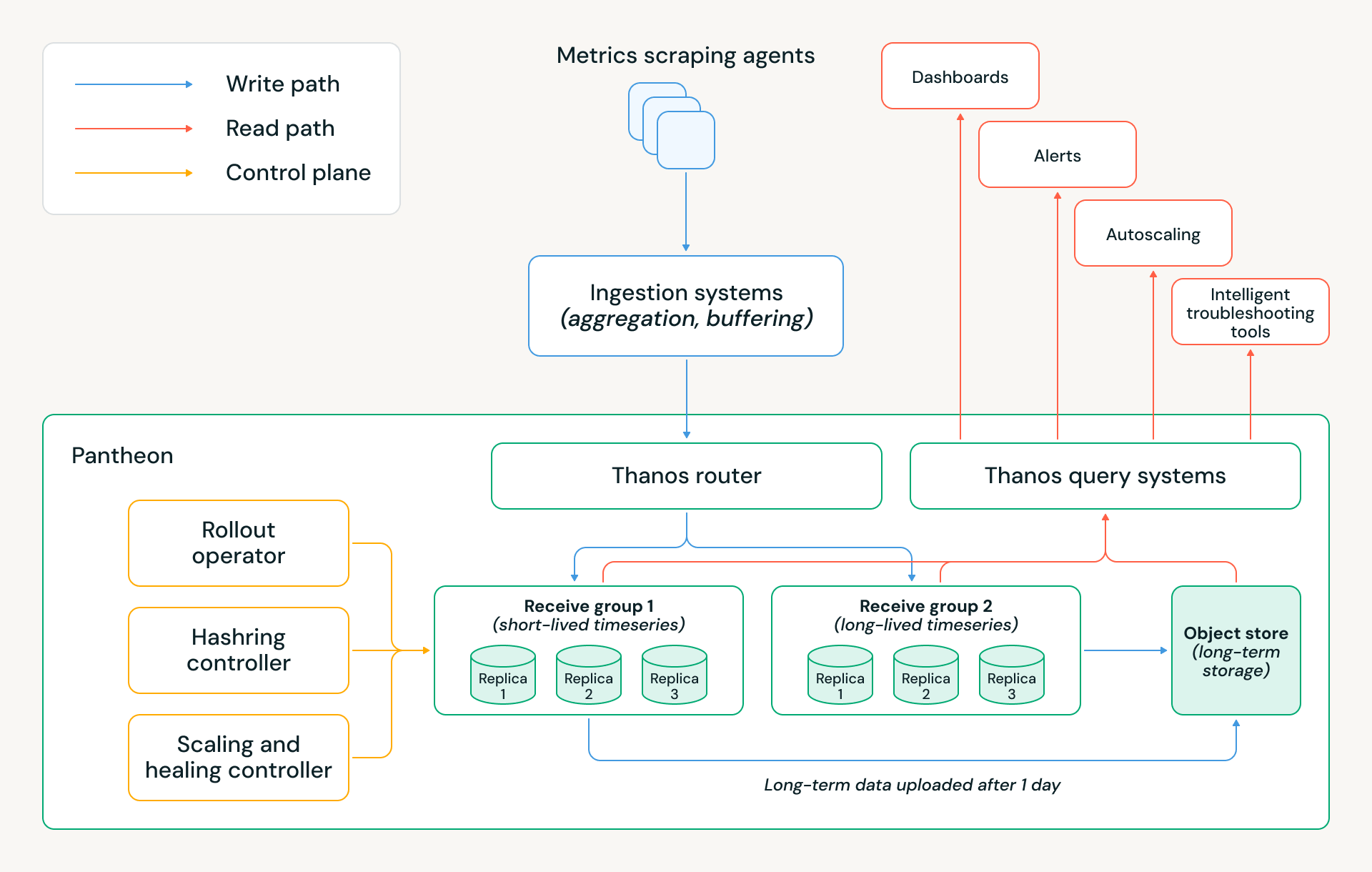
Arquitectura de almacenamiento
Un elemento clave de Thanos es su arquitectura de almacenamiento por niveles. Las series temporales más recientes se mantienen en memoria, las series temporales de las últimas 24 horas se mantienen en disco y todos los datos más antiguos se mantienen en almacenamiento de objetos. Esto significa que las alertas y otras consultas en tiempo real pueden cumplir requisitos de rendimiento estrictos, ya que generalmente dependen de los datos más recientes. Al mismo tiempo, el uso de almacenamiento de objetos permite que el sistema desacople esencialmente el cómputo del almacenamiento; un clúster puede escalar sin necesidad de reequilibrar todos sus datos históricos en los nodos de la base de datos.
Esta arquitectura abordó nuestro cuello de botella clave (escalados) y sentó las bases para los ahorros de costos de Pantheon. Hemos aplicado varias optimizaciones adicionales:
- Retención de memoria: Implementamos dos grupos de recepción con políticas de retención de memoria distintas: uno optimizado para series temporales de larga duración de servicios persistentes, que mantiene dos horas de muestras en memoria, y otro optimizado para series temporales de corta duración de las cargas de trabajo efímeras de Databricks, que mantiene solo 30 minutos en memoria. Esta división refleja la vida útil que observamos para las cargas de trabajo serverless en Databricks y reduce significativamente la huella de memoria y el costo de la nube, al tiempo que preserva la corrección.
- Estructura del grupo de recepción: Cada grupo se implementa intencionalmente como tres StatefulSets aislados de Kubernetes, correspondientes a tres réplicas, en lugar de un único anillo hash grande. Este diseño preserva la replicación triple con escrituras de quórum, al tiempo que proporciona un aislamiento operativo y de datos más sólido. Esta configuración nos permite actualizar o reiniciar un StatefulSet completo en paralelo durante lanzamientos o rotaciones de nodos sin violar el quórum o afectar la disponibilidad de escritura, lo que simplifica materialmente las operaciones diarias.
- Multitenencia: Pantheon utiliza la multitenencia de Thanos para alojar conjuntos de inquilinos disjuntos en los grupos de recepción. En la capa del enrutador, aplicamos la atribución de inquilinos basada en reglas, infiriendo el inquilino para cada muestra de datos inspeccionando el nombre de la métrica y las etiquetas seleccionadas. Esto permite que las muestras dentro del mismo lote de escritura se enruten a diferentes inquilinos, y por lo tanto a diferentes grupos de recepción, sin requerir cambios en el cliente upstream.
- Cargas al menos una vez: Para optimizar aún más el costo y preservar la corrección, solo dos de los tres StatefulSets cargan bloques en el almacenamiento de objetos. Esto reduce el tráfico de carga redundante y los costos de almacenamiento en la nube, al tiempo que mantiene las garantías de durabilidad y consistencia de los datos a través de la replicación y la semántica de quórum.
Plano de control de Pantheon
A nuestra escala global, las operaciones manuales, la automatización de Kubernetes de "mejor esfuerzo" o los comportamientos genéricos de Thanos son insuficientes. Cada lanzamiento, evento de escalado o falla de host debe manejarse de manera segura, automática y con mínima intervención humana, preservando el quórum y la disponibilidad de los datos. Para lograr esto, Pantheon introduce un plano de control especialmente diseñado, responsable de orquestar el ciclo de vida y las decisiones de capacidad de los componentes de Thanos. Consta de tres controladores clave:
- Operador de Lanzamiento: Coordina los lanzamientos y el escalado en tres StatefulSets de recepción aislados, garantizando el quórum tanto para lecturas como para escrituras. Permite lanzamientos más rápidos a través de actualizaciones paralelas de StatefulSet, asegurando que como máximo una réplica esté no disponible en un momento dado.
- Controlador de Hashring: Gestiona qué puntos de conexión de recepción son visibles para el enrutador. Solo se agregan al hashring los pods sanos y completamente listos, y las eliminaciones se preparan durante la reducción de escala o el mantenimiento. Esto desacopla la gestión del tráfico del ciclo de vida del pod y previene violaciones accidentales del quórum o enrutamiento parcial durante cambios dinámicos del clúster.
- Controlador de Autoscaling y Auto-reparación: Escala los clústeres basándose en la presión de ingesta y recursos específica de Pantheon en lugar de señales genéricas de Kubernetes. Un sistema de reparación incorporado detecta y remedia continuamente modos de falla comunes, como hosts defectuosos, pods sobrecargados o un WAL corrupto, lo que permite que el sistema se recupere automáticamente sin intervención del operador. A nuestra escala, estas automatizaciones se activan docenas de veces por semana.
Cardinalidad y agregación
¿Qué es la cardinalidad y por qué es importante?
Los propietarios de métricas a menudo agregan etiquetas como el ID del nodo o el ID del pod para ayudarles a depurar problemas en dimensiones específicas y mitigar incidentes más rápido. Sin embargo, esto conduce a un desafío clásico de observabilidad: la gestión de la cardinalidad. La cardinalidad de una métrica es el número de combinaciones únicas de sus etiquetas. Si el número de pods que estás monitoreando aumenta 10 veces, también lo hace la cardinalidad de cualquier métrica con una etiqueta de ID de pod. La cardinalidad es el principal factor de escalado para una TSDB, y el crecimiento de la cardinalidad de las métricas existentes aumenta los costos y la presión de escalado en Pantheon.
El rápido crecimiento de la infraestructura es un desafío que tenemos en Databricks. Al mismo tiempo que nuestra base de clientes y el uso de productos han crecido significativamente, muchos clientes han adoptado recientemente nuestra arquitectura de computación serverless, y nuestra plataforma de cómputo serverless lanza decenas de millones de VMs diariamente. A medida que más cargas de trabajo se trasladan a serverless, la infraestructura que monitoreamos se vuelve de mayor rotación, y la vida útil de estas etiquetas identificadoras se acorta cada vez más.
Esto ha provocado que la cardinalidad se dispare, mermando las ventajas de escalabilidad y costo de Pantheon. Por lo tanto, tuvimos que ser mucho más inteligentes sobre qué datos de métricas almacenábamos. Aquí es donde entró la “agregación”: descartar etiquetas costosas de los sistemas serverless durante la ingesta, al tiempo que se proporciona una vista agregada de toda la flota a los propietarios del servicio. Una estrategia de agregación automatizada para métricas nos ha permitido “doblar la curva” del crecimiento de la cardinalidad, asegurando que la infraestructura de monitoreo no necesite escalar más rápido que el resto de Databricks.
Arquitectura de agregación
Construir una infraestructura de agregación confiable a escala es difícil porque es stateful. Los agregadores que gestionan millones de contadores de entrada deben ser capaces de manejar reinicios correctamente: si una serie temporal de entrada desaparece, el valor de salida agregado debe seguir aumentando monótonamente en lugar de disminuir. Con las métricas particionadas entre agregadores, también debes manejar escenarios como reinicios de pods y desequilibrio de carga.
Estos problemas a menudo se resuelven utilizando un sistema de mensajería como Kafka para las asignaciones de partición y el mantenimiento de datos anteriores; esto es costoso a nuestra escala y agrega un retraso en la ingesta que impacta los casos de uso en tiempo real. El enfoque alternativo es almacenar el estado en memoria en los agregadores y redirigir las métricas entre agregadores para honrar la asignación. Sin embargo, esto conduce a la pérdida de datos cuando se redespliega un agregador; en una versión inicial de nuestra infraestructura de agregación, este comportamiento hizo que las métricas agregadas fueran casi ininteligibles para nuestros usuarios.
Para que esto funcione sin problemas, desarrollamos nuestro propio sistema de agregación utilizando Telegraf y el servicio “auto-sharder” de Databricks Dicer. Esta arquitectura utiliza enrutamiento inteligente y pegajoso en lugar de redirigir métricas entre agregadores, lo que abordó los modos de falla de redespliegue. Con otras optimizaciones que hemos agregado sobre Telegraf, hemos podido escalar el pipeline a más de 1 GB/s en nuestra región más grande y miles de reglas de agregación.
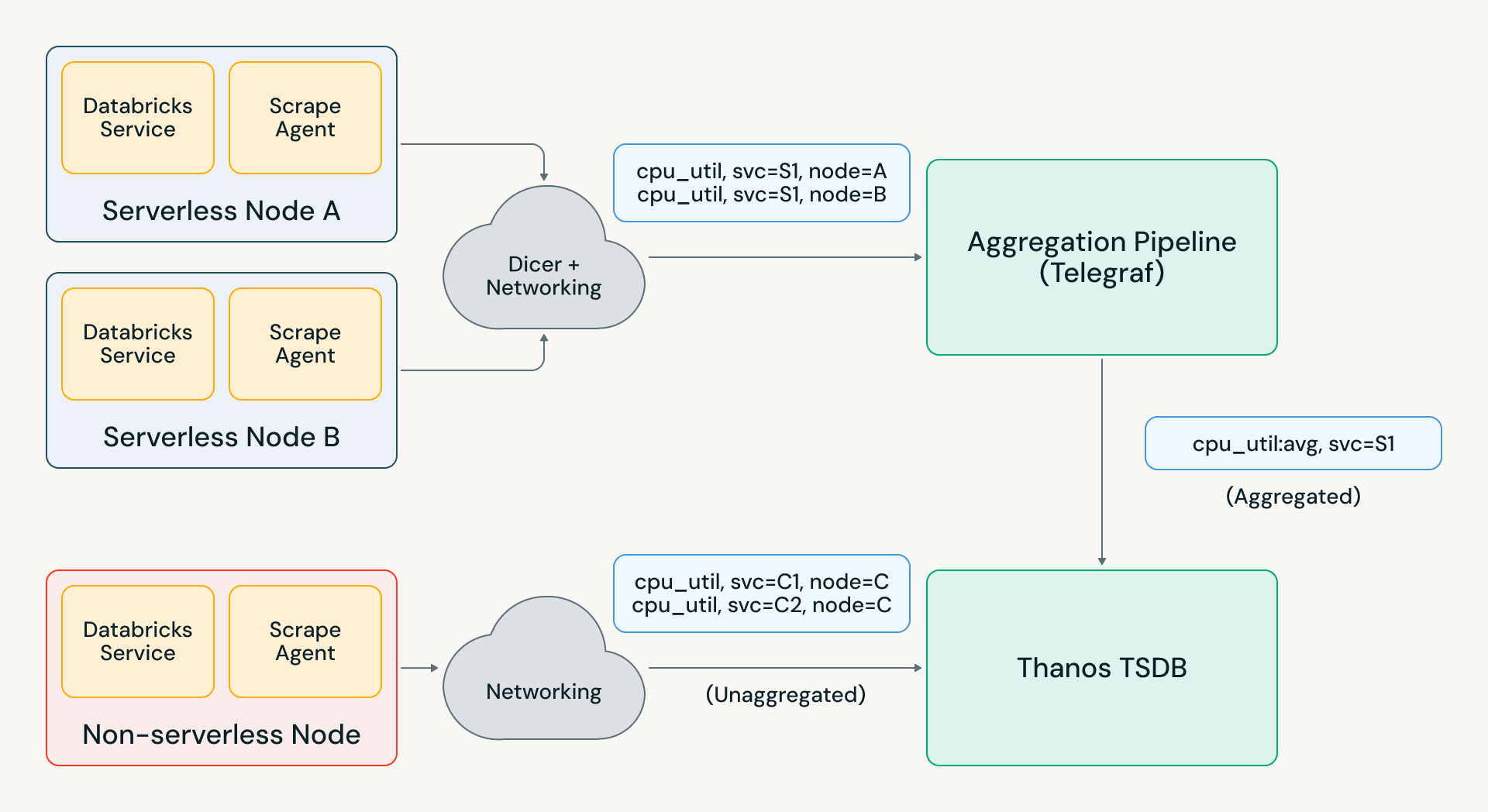
Este nuevo pipeline de agregación se convirtió efectivamente en el escudo que protege nuestras TSDBs del crecimiento de cardinalidad a largo plazo, así como de los picos inesperados de métricas. Por ejemplo, un incidente reciente en la infraestructura de Databricks resultó en un aumento de 2 a 5 veces en la carga de métricas en varias regiones. Telegraf absorbió la mayor parte de esta carga, y Pantheon solo vio un aumento del 20%, lo que permitió a los ingenieros de toda la empresa ejecutar consultas de depuración y alerta sin ningún impacto.
Datos de alta cardinalidad en el lakehouse
El problema con la agregación
Nuestra infraestructura de agregación nos permite proteger a Pantheon del crecimiento exponencial de la cardinalidad, pero esto tiene un costo: elimina las dimensiones exactas que los ingenieros necesitan durante los incidentes. Considere una flota global con:
- Millones de nodos activos en las últimas 2 horas
- Múltiples inquilinos por nodo
- Cargas de trabajo de corta duración
- Autoscaling rápido
Las métricas agregadas te dicen:
- El uso de CPU a nivel de región está elevado
- La latencia a nivel de servicio está aumentando
Pero no te dicen:
- Qué inquilino está causando presión de swap
- Qué nodo se bloqueó
- Qué shard está aislado
- Qué carga de trabajo es ruidosa
Los ingenieros de Databricks todavía necesitaban una solución para solucionar problemas de flujos de trabajo que dependieran de estas etiquetas de alta cardinalidad. Estos escenarios de “buscar una aguja en un pajar” requerían almacenar y procesar eficientemente grandes cantidades de datos sin procesar, lo que Pantheon no podía hacer. Para soportar estos casos de uso, buscamos una arquitectura de almacenamiento diferente que no estuviera limitada por el crecimiento de la cardinalidad.
¡Ingrese al lakehouse!
Nuestra idea clave: ¡el lakehouse de Databricks es un ajuste perfecto! Desacopla el almacenamiento (almacenamiento de objetos económico + Delta Lake) del cómputo (streaming + clústeres de consulta) y es masivamente escalable en ambas dimensiones.
Utilizando lo mejor de las capacidades de Databricks, desarrollamos una nueva plataforma para datos de solución de problemas sin procesar llamada Hydra, que ha hecho que la depuración de alta cardinalidad sea práctica a escala masiva. Hydra ingiere 20 mil millones de series temporales activas y sin agregar de millones de nodos en todo el mundo, al tiempo que logra una frescura de datos de extremo a extremo de 5 minutos y un almacenamiento de datos 50 veces más económico que Thanos.
Estas victorias fueron posibles gracias al diseño nativo del lakehouse de Hydra:

- Usamos Apache Spark™ Structured Streaming en Databricks para ejecutar trabajos de ingesta continuos que procesan incrementalmente los datos de métricas a medida que llegan, escribiéndolos en Delta Lake. Structured Streaming te permite expresar cálculos de streaming de la misma manera que escribes trabajos por lotes, pero con procesamiento continuo e incremental y semántica de una sola vez para una ingesta confiable.
- Para descubrir e ingerir eficientemente millones de archivos de almacenamiento de objetos, aprovechamos Databricks Auto Loader, una fuente de Structured Streaming de alto rendimiento que rastrea y procesa incrementalmente nuevos archivos sin requerir listado manual o gestión de estado. Auto Loader persiste automáticamente metadatos sobre los archivos descubiertos y escala para manejar patrones de llegada casi en tiempo real.
- También particionamos la ingesta por región, implementando trabajos de streaming independientes en diferentes geografías. Esto permite que cada pipeline escale automáticamente de forma independiente, minimiza la latencia entre regiones y reduce el radio de explosión en caso de fallos. En conjunto, estas opciones de diseño permiten que los datos de métricas sin procesar sean consultables a los pocos minutos de su emisión, incluso con un volumen de miles de millones de series, manteniendo al mismo tiempo el rendimiento de los sistemas de panel.
Unificación de interfaces
Construir Hydra no fue solo un desafío de infraestructura; fue un desafío de diseño de interfaz. Desde el principio, diseñamos Hydra en torno a los Viajes Críticos del Usuario (CUJs) para nuestros ingenieros en lugar de en torno a las capas de almacenamiento o los pipelines de ingesta. Nuestro objetivo era simple: los ingenieros deberían poder trabajar con métricas de alta cardinalidad utilizando las mismas interfaces en las que ya confían.
Consultas a través de Grafana
La mayoría de los ingenieros comienzan su flujo de trabajo de depuración en Grafana. Esperan escribir PromQL, usar paneles existentes, profundizar en las etiquetas y pivotar rápidamente durante los incidentes.
Para preservar este flujo de trabajo, Hydra se integra directamente con Grafana al permitir que las consultas PromQL se ejecuten contra los datos almacenados en Databricks. Construimos una capa de conversión de PromQL a SQL que traduce las expresiones PromQL en consultas SQL ejecutadas en tablas Delta en el Lakehouse. Este enfoque permite a los ingenieros continuar utilizando la sintaxis y los paneles PromQL familiares sin modificaciones. Al mismo tiempo, las consultas subyacentes se ejecutan contra tablas Delta a gran escala en lugar de una TSDB en memoria.
Acceso SQL Directo en Databricks
Si bien Grafana es ideal para la depuración en vivo, algunas investigaciones requieren un análisis más profundo. Los ingenieros pueden necesitar unir métricas con metadatos de implementación, correlacionar métricas con registros, ejecutar escaneos de rangos de tiempo amplios, realizar detección de anomalías o exportar conjuntos de datos para análisis avanzados.
Hydra también expone las tablas de Delta subyacentes directamente dentro de Databricks. Los ingenieros pueden consultar estas tablas usando Databricks SQL o notebooks, lo que permite un análisis flexible que va más allá de los flujos de trabajo de monitoreo tradicionales.
Dado que los datos residen en el Lakehouse, se pueden unir con otros conjuntos de datos empresariales y se rigen bajo los mismos controles de seguridad y acceso. Esto convierte los datos de observabilidad en un activo analítico de primera clase en lugar de un silo de monitoreo aislado.
Semántica Unificada de Métricas
Un principio de diseño clave de Hydra es que los ingenieros no deben necesitar comprender nuestra arquitectura de ingesta. Ya sea que una métrica se acceda a través de la ruta agregada respaldada por TSDB o la ruta de métricas sin procesar respaldada por Lakehouse, la interfaz sigue siendo consistente.
Los nombres de las métricas, la semántica de las etiquetas y las dimensiones de los metadatos están unificados en todos los entornos. Los equipos de servicio emiten métricas una vez utilizando una interfaz estandarizada. La plataforma maneja la agregación, la preservación sin procesar, la ingesta, el almacenamiento y el enrutamiento de consultas. Este modelo unificado reduce la carga cognitiva y elimina la necesidad de que los equipos administren configuraciones separadas para diferentes backends de observabilidad.
En el futuro, estamos buscando mejorar el rendimiento de Hydra para que logre una frescura de datos similar a la de Pantheon y las dos experiencias converjan aún más.
Conclusiones
Para escalar la infraestructura de monitoreo de Databricks, hemos necesitado optimizar la confiabilidad, la eficiencia, la operabilidad y las experiencias de los desarrolladores. "Escalar" para nosotros ha significado más que solo aumentar nuestras implementaciones. Ha significado:
- Integrar la resiliencia y la automatización en nuestra arquitectura fundamental, para lograr operaciones "sin intervención manual" para estos sistemas globales y en constante cambio
- Repensar desde los principios fundamentales el tipo de sistemas que eran necesarios para diversos casos de uso de monitoreo, desde alertas hasta solución de problemas y análisis en fuentes de datos
- Evolucionar nuestra arquitectura a medida que el resto de la infraestructura de Databricks se ha transformado junto con nosotros
Estos serán viajes interminables para nosotros, y son ilustrativos de por qué la ingeniería de infraestructura es un espacio tan dinámico en Databricks. Si te gusta resolver problemas de ingeniería difíciles y te gustaría unirte a nosotros en el viaje, visita databricks.com/careers!
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.