Procesamiento de datos geoespaciales a escala con Databricks
por Nima Razavi y Michael Johns
Este blog está desactualizado. Consulte este blog de Spatial SQL para conocer los enfoques más recientes sobre el almacenamiento y procesamiento de datos geoespaciales en su Databricks Lakehouse.
La evolución y convergencia de la tecnología han impulsado un mercado vibrante de datos geoespaciales precisos y oportunos. Cada día, miles de millones de dispositivos portátiles y de IoT, junto con miles de plataformas de teledetección aéreas y satelitales, generan cientos de exabytes de datos con información de ubicación. Este auge de los macrodatos geoespaciales, combinado con los avances en machine learning, está permitiendo a las organizaciones de todas las industrias crear nuevos productos y capacidades.
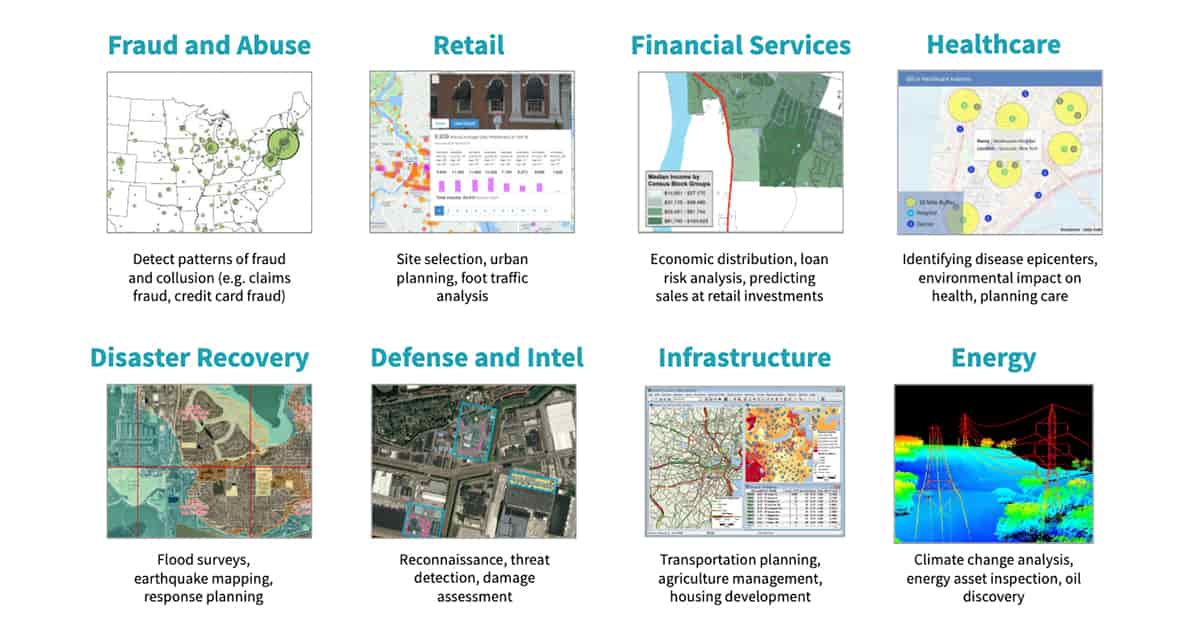
Por ejemplo, numerosas empresas ofrecen servicios localizados basados en drones, como mapeo e inspección de sitios (consulte Desarrollo para la Nube Inteligente y el Edge Inteligente). Otra industria de rápido crecimiento para los datos geoespaciales son los vehículos autónomos. Tanto las startups como las empresas establecidas están acumulando grandes corpus de geodatos altamente contextualizados de sensores de vehículos para ofrecer la próxima innovación en coches autónomos (consulte Databricks impulsa la ambición de wejo de crear un ecosistema de datos de movilidad). Los minoristas y las agencias gubernamentales también buscan aprovechar sus datos geoespaciales. Por ejemplo, el análisis del tráfico peatonal (consulte Creación de un conjunto de datos de información sobre tráfico peatonal) puede ayudar a determinar la mejor ubicación para abrir una nueva tienda o, en el Sector Público, mejorar la planificación urbana. A pesar de todas estas inversiones en datos geoespaciales, existen varios desafíos.
Desafíos en el Análisis Geoespacial a Escala
El primer desafío implica lidiar con la escala en aplicaciones de streaming y batch. La gran proliferación de datos geoespaciales y los SLA requeridos por las aplicaciones abruman los sistemas tradicionales de almacenamiento y procesamiento. Los datos de los clientes han estado saliendo de las bases de datos geoespaciales existentes escaladas verticalmente hacia los data lakes durante muchos años debido a presiones como el volumen de datos, la velocidad, el costo de almacenamiento y la estricta aplicación del esquema en la escritura. Si bien las empresas han invertido en datos geoespaciales, pocas tienen la arquitectura tecnológica adecuada para preparar estos conjuntos de datos grandes y complejos para análisis posteriores. Además, dado que los datos escalados a menudo son necesarios para casos de uso avanzados, la mayoría de las iniciativas impulsadas por IA no logran pasar de la fase piloto a la producción.
La compatibilidad con varios formatos espaciales presenta el segundo desafío. Existen muchos formatos geoespaciales especializados establecidos durante décadas, así como fuentes de datos incidentales en las que se puede recopilar información de ubicación:
- Formatos vectoriales como GeoJSON, KML, Shapefile y WKT
- Formatos ráster como ESRI Grid, GeoTIFF, JPEG 2000 y NITF
- Estándares de navegación como los utilizados por dispositivos AIS y GPS
- Bases de datos geoespaciales accesibles a través de conexiones JDBC / ODBC como PostgreSQL / PostGIS
- Formatos de sensores remotos de plataformas hiperespectrales, multiespectrales, Lidar y Radar
- Estándares web OGC como WCS, WFS, WMS y WMTS
- Registros, imágenes, videos y redes sociales con geotags
- Datos no estructurados con referencias de ubicación
En esta entrada de blog, ofrecemos una descripción general de los enfoques generales para abordar los dos desafíos principales mencionados anteriormente utilizando la Plataforma Unificada de Análisis de Datos de Databricks. Esta es la primera parte de una serie de entradas de blog sobre el trabajo con grandes volúmenes de datos geoespaciales.
Escalando Cargas de Trabajo Geoespaciales con Databricks
Databricks ofrece una plataforma unificada de análisis de datos para análisis de big data y machine learning utilizada por miles de clientes en todo el mundo. Está impulsada por Apache Spark™, Delta Lake y MLflow, con un amplio ecosistema de integraciones de bibliotecas de terceros y disponibles. Databricks UDAP ofrece seguridad, soporte, confiabilidad y rendimiento de nivel empresarial a escala para cargas de trabajo de producción. Las cargas de trabajo geoespaciales suelen ser complejas y no existe una única biblioteca que se adapte a todos los casos de uso. Si bien Apache Spark no ofrece tipos de datos espaciales de forma nativa, la comunidad de código abierto, así como las empresas, han dedicado muchos esfuerzos a desarrollar bibliotecas espaciales, lo que resulta en una gran cantidad de opciones entre las que elegir.
Generalmente, existen tres patrones para escalar operaciones geoespaciales como uniones espaciales o vecinos más cercanos:
- Uso de bibliotecas especializadas que extienden Apache Spark para análisis geoespaciales. GeoSpark, GeoMesa, GeoTrellis y Rasterframes son algunas de estas bibliotecas utilizadas por nuestros clientes. Estos frameworks a menudo ofrecen múltiples enlaces de lenguaje, tienen una escala y un rendimiento mucho mejores que los enfoques no formalizados, pero también pueden implicar una curva de aprendizaje.
- Envolver bibliotecas de un solo nodo como GeoPandas, Geospatial Data Abstraction Library (GDAL) o Java Topology Service (JTS) en funciones definidas por el usuario (UDF) ad hoc para el procesamiento distribuido con DataFrames de Spark. Este es el enfoque más simple para escalar cargas de trabajo existentes sin mucha reescritura de código; sin embargo, puede introducir inconvenientes de rendimiento, ya que es más de tipo "lift-and-shift".
- Indexar los datos con sistemas de cuadrícula y aprovechar el índice generado para realizar operaciones espaciales es un enfoque común para tratar con cargas de trabajo a muy gran escala o computacionalmente restringidas. S2, GeoHex y H3 de Uber son ejemplos de tales sistemas de cuadrícula. Las cuadrículas aproximan características geográficas como polígonos o puntos con un conjunto fijo de celdas identificables, evitando así operaciones geoespaciales costosas y ofreciendo un comportamiento de escalado mucho mejor. Los implementadores pueden elegir entre cuadrículas fijas a una sola precisión que pueden ser algo imprecisas pero más eficientes, o cuadrículas con múltiples precisiones que pueden ser menos eficientes pero mitigan la imprecisión.
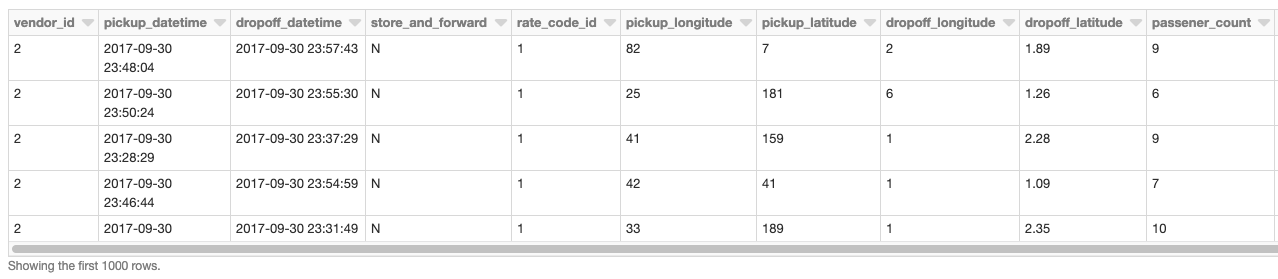
Los ejemplos que siguen están generalmente orientados a un conjunto de datos de recogida/entrega de taxis de Nueva York que se encuentra aquí. También se utilizarán datos de zonas de taxi de Nueva York con geometrías como conjunto de polígonos. Estos datos contienen polígonos para los cinco distritos de Nueva York, así como los barrios. Este notebook le guiará a través de las preparaciones y limpiezas realizadas para convertir los archivos CSV iniciales en Tablas de Delta Lake como una fuente de datos confiable y de alto rendimiento.
Nuestro DataFrame base son los datos de recogida/entrega de taxis leídos de una Tabla de Delta Lake utilizando Databricks.
Operaciones geoespaciales usando bibliotecas geoespaciales para Apache Spark
En los últimos años, se han desarrollado varias bibliotecas para extender las capacidades de Apache Spark para el análisis geoespacial. Estos frameworks se encargan de registrar tipos de usuario definidos (UDT) y funciones (UDF) aplicadas comúnmente de manera consistente, aliviando la carga que de otro modo recae sobre los usuarios y equipos para escribir lógica espacial ad hoc. Tenga en cuenta que en esta entrada de blog utilizamos varios frameworks espaciales diferentes elegidos para resaltar diversas capacidades. Entendemos que existen otros frameworks más allá de los destacados que también podría querer usar con Databricks para procesar sus cargas de trabajo espaciales.
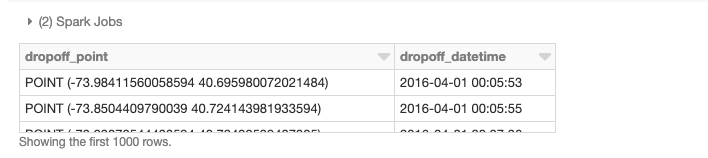
Anteriormente, cargamos nuestros datos base en un DataFrame. Ahora necesitamos convertir los atributos de latitud/longitud en geometrías de puntos. Para lograr esto, usaremos UDFs para realizar operaciones en DataFrames de manera distribuida. Consulte los cuadernos proporcionados al final del blog para obtener detalles sobre cómo agregar estos frameworks a un clúster y las llamadas de inicialización para registrar UDFs y UDTs. Para empezar, hemos agregado GeoMesa a nuestro clúster, un framework especialmente experto en el manejo de datos vectoriales. Para la ingesta, estamos aprovechando principalmente su integración de JTS con Spark SQL, lo que nos permite convertir y usar fácilmente clases JTS de geometría registradas. Usaremos la función st_makePoint que, dada una latitud y una longitud, crea un objeto de geometría Point. Dado que la función es una UDF, podemos aplicarla directamente a las columnas.
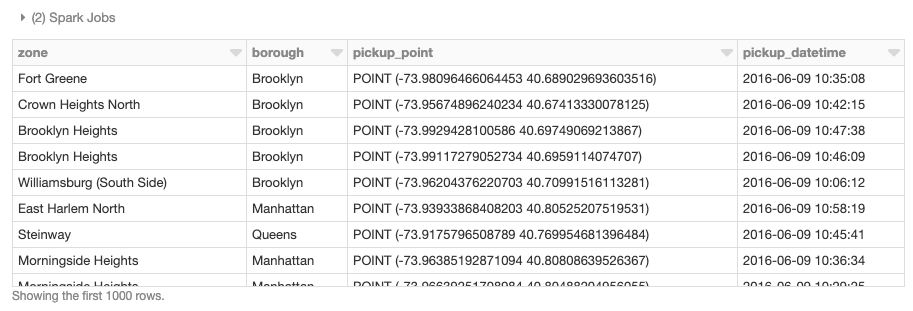
También podemos realizar uniones espaciales distribuidas, en este caso usando la UDF st_contains proporcionada por GeoMesa para producir la unión resultante de todos los polígonos contra los puntos de recogida.
Envolviendo bibliotecas de un solo nodo en UDFs
Además de usar frameworks espaciales distribuidos diseñados específicamente, las bibliotecas existentes de un solo nodo también se pueden envolver en UDFs ad hoc para realizar operaciones geoespaciales en DataFrames de manera distribuida. Este patrón está disponible para todos los enlaces de idiomas de Spark: Scala, Java, Python, R y SQL, y es un enfoque simple para aprovechar las cargas de trabajo existentes con cambios mínimos en el código. Para demostrar un ejemplo de un solo nodo, carguemos los datos de los distritos de Nueva York y definamos la UDF find_borough(...) para la operación punto en polígono para asignar cada ubicación GPS a un distrito usando geopandas. Esto también podría haberse logrado con una UDF vectorizada para un rendimiento aún mejor.
Ahora podemos aplicar la UDF para agregar una columna a nuestro DataFrame de Spark que asigna un nombre de distrito a cada punto de recogida.
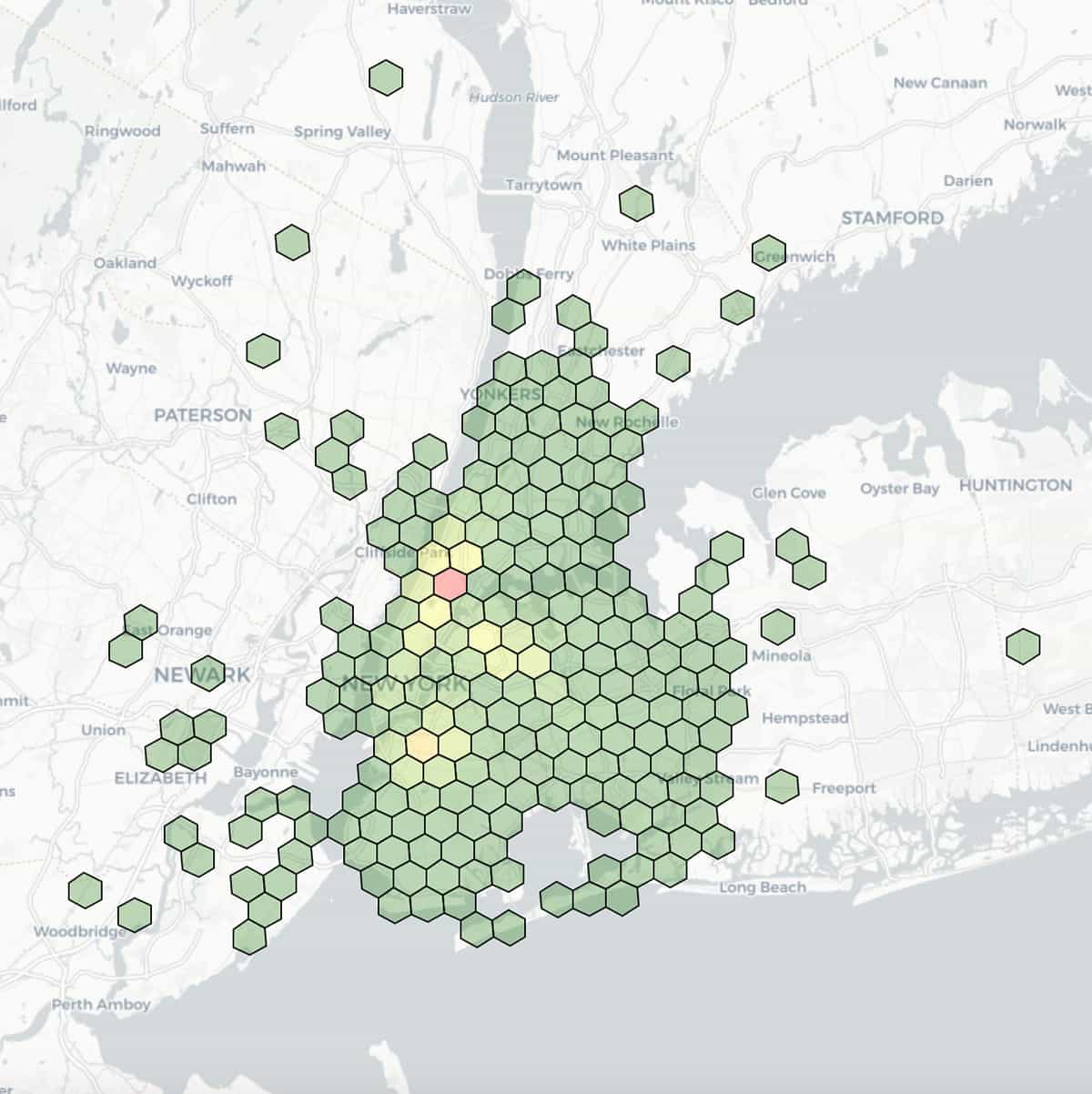
Sistemas de cuadrícula para indexación espacial
Las operaciones geoespaciales son inherentemente costosas computacionalmente. Punto en polígono, uniones espaciales, vecinos más cercanos o ajuste a rutas implican operaciones complejas. Al indexar con sistemas de cuadrícula, el objetivo es evitar por completo las operaciones geoespaciales. Este enfoque conduce a las implementaciones más escalables con la advertencia de operaciones aproximadas. Aquí hay un breve ejemplo con H3.
Escalar operaciones espaciales con H3 es esencialmente un proceso de dos pasos. El primer paso es calcular un índice H3 para cada característica (puntos, polígonos, ...) definida como la UDF geoToH3(...). El segundo paso es usar estos índices para operaciones espaciales como la unión espacial (punto en polígono, k-vecinos más cercanos, etc.), en este caso definida como la UDF multiPolygonToH3(...).
Ahora podemos aplicar estas dos UDFs a los datos de taxis de Nueva York, así como al conjunto de polígonos de distritos para generar el índice H3.
Dado un conjunto de puntos de latitud/longitud y un conjunto de geometrías de polígonos, ahora es posible realizar la unión espacial utilizando el campo h3index como condición de unión. Estas asignaciones se pueden usar para agregar, por ejemplo, el número de puntos que caen dentro de cada polígono. Por lo general, hay millones o miles de millones de puntos que deben coincidir con miles o millones de polígonos, lo que requiere un enfoque escalable. Existen otras técnicas no cubiertas en este blog que se pueden utilizar para la indexación en soporte de operaciones espaciales cuando una aproximación no es suficiente.

Aquí tienes una visualización de las ubicaciones de entrega de taxis, con latitud y longitud agrupadas en una resolución de 7 (longitud de borde de 1,22 km) y coloreadas por recuentos agregados dentro de cada grupo.
Manejo de formatos espaciales con Databricks
Los datos geoespaciales implican puntos de referencia, como latitud y longitud, a ubicaciones físicas o extensiones en la Tierra, junto con características descritas por atributos. Si bien hay muchos formatos de archivo para elegir, hemos seleccionado un puñado de formatos vectoriales y rasterizados representativos para demostrar la lectura con Databricks.
Datos vectoriales
Los datos vectoriales son una representación del mundo almacenada en coordenadas x (longitud), y (latitud) en grados, también z (altitud en metros) si se considera la elevación. Los tres tipos de símbolos básicos para datos vectoriales son puntos, líneas y polígonos. Well-known-text (WKT), GeoJSON y Shapefile son algunos formatos populares para almacenar datos vectoriales que destacamos a continuación.
Leamos los datos de zonas de taxi de Nueva York con geometrías almacenadas como WKT. La estructura de datos que queremos obtener es un DataFrame, lo que nos permitirá estandarizar con otras API y fuentes de datos disponibles, como las utilizadas en otras partes del blog. Podemos convertir fácilmente el contenido de texto WKT que se encuentra en el campo the_geom a su clase JTS Geometry correspondiente a través de la llamada UDF st_geomFromWKT(...).
GeoJSON es utilizado por muchos paquetes GIS de código abierto para codificar una variedad de estructuras de datos geográficos, incluidas sus características, propiedades y extensiones espaciales. Para este ejemplo, leeremos los límites de los distritos de Nueva York con el enfoque que se tome dependiendo del flujo de trabajo. Dado que los datos cumplen con el formato JSON, podríamos usar el lector JSON integrado de Databricks con .option("multiline","true") para cargar los datos con el esquema anidado.

A partir de ahí, podríamos optar por elevar cualquiera de los campos a columnas de nivel superior utilizando la función explode integrada de Spark. Por ejemplo, podríamos querer extraer la geometría, las propiedades y el tipo, y luego convertir la geometría a su clase JTS correspondiente, como se mostró en el ejemplo WKT.

También podemos visualizar los datos de zonas de taxi de Nueva York dentro de un notebook utilizando un DataFrame existente o renderizando directamente los datos con una biblioteca como Folium, una biblioteca de Python para renderizar datos espaciales. Databricks File System (DBFS) se ejecuta sobre una capa de almacenamiento distribuido que permite que el código funcione con formatos de datos utilizando estándares familiares del sistema de archivos. DBFS tiene un montaje FUSE para permitir llamadas API locales que realizan operaciones de lectura y escritura de archivos, lo que facilita mucho la carga de datos con API no distribuidas para la renderización interactiva. En el comando Python open(...) a continuación, el prefijo "/dbfs/..." habilita el uso de FUSE Mount.
Shapefile es un formato vectorial popular desarrollado por ESRI que almacena la ubicación geométrica y la información de atributos de las características geográficas. El formato consta de una colección de archivos con un prefijo de nombre de archivo común (*.shp, *.shx y *.dbf son obligatorios) almacenados en el mismo directorio. Una alternativa a shapefile es KML, también utilizado por nuestros clientes pero no mostrado por brevedad. Para este ejemplo, usemos los shapefiles de edificios de Nueva York. Si bien hay muchas maneras de demostrar la lectura de shapefiles, daremos un ejemplo usando GeoSpark. El ShapefileReader integrado se utiliza para generar el DataFrame rawSpatialDf.
Al registrar rawSpatialDf como una vista temporal, podemos recurrir fácilmente a la sintaxis pura de Spark SQL para trabajar con el DataFrame, incluido la aplicación de una UDF para convertir el WKT del shapefile en Geometría.
Además, podemos usar la visualización integrada de Databricks para análisis en línea, como la creación de gráficos de los edificios más altos de Nueva York.

Datos ráster
Los datos ráster almacenan información de características en una matriz de celdas (o píxeles) organizadas en filas y columnas (discretas o continuas). Las imágenes satelitales, la fotogrametría y los mapas escaneados son tipos de datos de Observación de la Tierra (EO) basados en ráster.
El siguiente ejemplo de Python utiliza RasterFrames, un framework de análisis espacial centrado en DataFrames, para leer dos bandas de imágenes GeoTIFF Landsat-8 (rojo e infrarrojo cercano) y combinarlas en el Índice de Vegetación de Diferencia Normalizada. Podemos usar estos datos para evaluar la salud de las plantas alrededor de Nueva York. El módulo rf_ipython se utiliza para manipular el contenido de RasterFrame en una variedad de formas visualmente útiles, como se muestra a continuación, donde las columnas de mosaicos rojo, NIR y NDVI se representan con rampas de color, utilizando el comando integrado displayHTML(...) de Databricks para mostrar los resultados dentro del notebook.
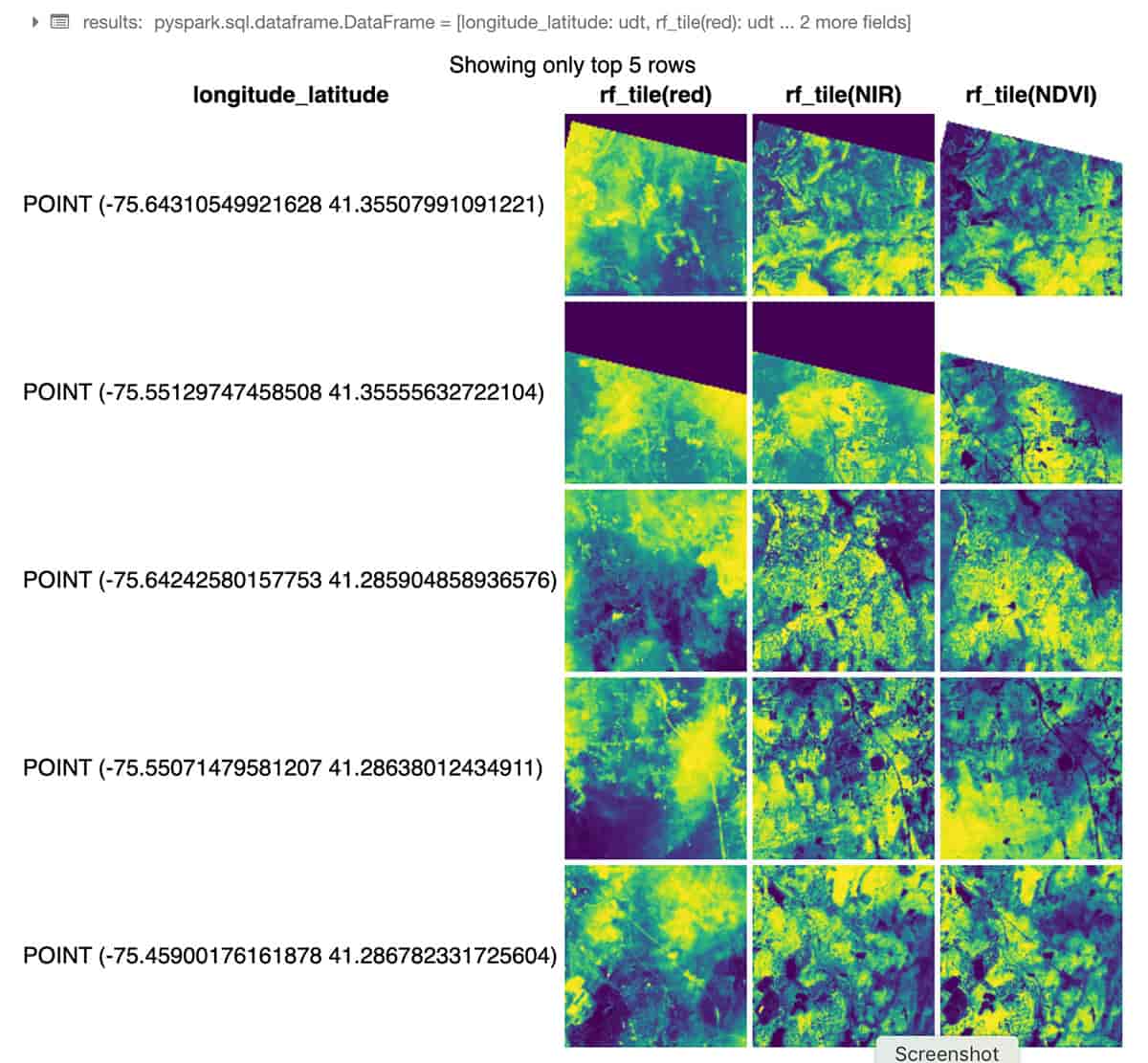
A través de su Spark DataSource personalizado, RasterFrames puede leer varios formatos ráster, incluyendo GeoTIFF, JP2000, MRF y HDF, desde un conjunto de servicios. También admite la lectura de los formatos vectoriales GeoJSON y WKT/WKB. El contenido de RasterFrame se puede filtrar, transformar, resumir, remuestrear y rasterizar a través de más de 200 funciones ráster y vectoriales, como st_reproject(...) y st_centroid(...) utilizadas en el ejemplo anterior. Proporciona API para Python, SQL y Scala, así como interoperabilidad con Spark ML.
GeoDatabases
Las GeoDatabases pueden basarse en archivos para datos a menor escala o ser accesibles a través de conexiones JDBC / ODBC para datos a escala media. Puede usar Databricks para consultar muchas bases de datos SQL con el JDBC / ODBC Data Source integrado. La conexión a PostgreSQL se muestra a continuación, que se usa comúnmente para cargas de trabajo a menor escala aplicando extensiones PostGIS. Este patrón de conectividad permite a los clientes mantener el acceso tal cual a las bases de datos existentes.
Comenzar con el análisis geoespacial en Databricks
Las empresas y las agencias gubernamentales buscan utilizar datos referenciados espacialmente junto con fuentes de datos empresariales para obtener información procesable y ofrecer una amplia gama de casos de uso innovadores. En este blog, demostramos cómo la Plataforma Unificada de Análisis de Datos de Databricks puede escalar fácilmente las cargas de trabajo geoespaciales, lo que permite a nuestros clientes aprovechar el poder de la nube para capturar, almacenar y analizar datos de tamaño masivo.
En un próximo blog, profundizaremos en temas más avanzados para el procesamiento geoespacial a escala con Databricks. Encontrará detalles adicionales sobre los formatos espaciales y los frameworks destacados revisando el Notebook de Preparación de Datos, el Notebook GeoMesa + H3, el Notebook GeoSpark, el Notebook GeoPandas y el Notebook Rasterframes. Además, manténgase atento a una nueva sección en nuestra documentación específicamente para temas geoespaciales de interés.
Próximos pasos
- Únase a nuestro próximo webinar Análisis Geoespacial e IA en el Sector Público para ver una demostración en vivo que cubre varios casos de uso populares
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.