Una implementación de red neuronal convolucional para la clasificación de automóviles
por Dr. Evan Eames y Henning Kropp
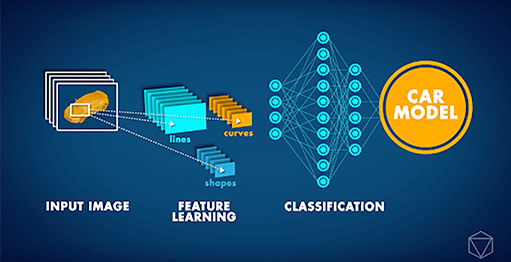
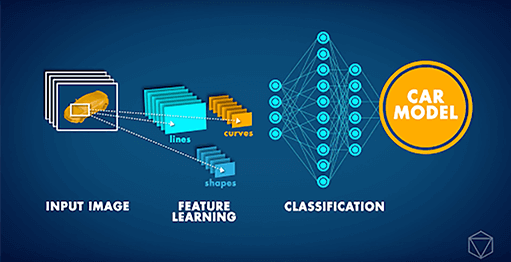
Las Redes Neuronales Convolucionales (CNN) son arquitecturas de Redes Neuronales de última generación que se utilizan principalmente para tareas de visión por computadora. Las CNN se pueden aplicar a diversas tareas, como el reconocimiento de imágenes, la localización de objetos y la detección de cambios. Recientemente, nuestro socio Data Insights recibió una solicitud desafiante de una importante empresa de automóviles: desarrollar una aplicación de Visión por Computadora que pudiera identificar el modelo del auto en una imagen determinada. Considerando que diferentes modelos de autos pueden parecer bastante similares y que cualquier auto puede verse muy diferente según su entorno y el ángulo en que se fotografía, tal tarea era, hasta hace muy poco, simplemente imposible.

Sin embargo, a partir de 2012 aproximadamente, la ‘Revolución del Aprendizaje Profundo’ hizo posible abordar tal problema. En lugar de que se les explicara el concepto de un auto, las computadoras podían, en cambio, estudiar repetidamente imágenes y aprender tales conceptos por sí mismas. En los últimos años, las innovaciones adicionales en las Redes Neuronales Artificiales han dado como resultado una IA que puede realizar tareas de clasificación de imágenes con una precisión a nivel humano. Aprovechando estos desarrollos, pudimos entrenar una CNN profunda para clasificar autos por su modelo. La Red Neuronal se entrenó con el conjunto de datos de autos de Stanford, que contiene más de 16 000 imágenes de autos y comprende 196 modelos diferentes. Con el tiempo, pudimos ver que la precisión de las predicciones comenzó a mejorar, a medida que la red neuronal aprendía el concepto de un auto y a distinguir entre diferentes modelos.
{kind=link}
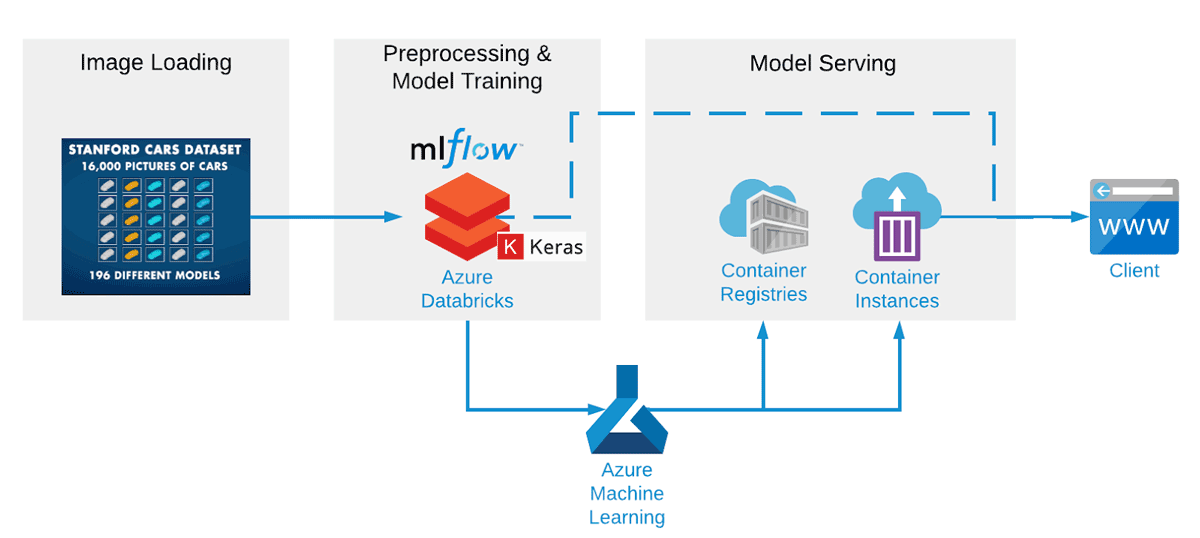
Junto con nuestro socio, construimos un pipeline de aprendizaje automático de extremo a extremo usando Apache Spark™ y Koalas para el preprocesamiento de datos, Keras con Tensorflow para el entrenamiento del modelo, MLflow para el seguimiento de modelos y resultados, y Azure ML para el despliegue de un servicio REST. Esta configuración dentro de Azure Databricks está optimizada para entrenar redes de forma rápida y eficiente, y también ayuda a probar muchas configuraciones diferentes de CNN mucho más rápidamente. Incluso después de solo unos pocos intentos de práctica, la precisión de la CNN alcanzó alrededor del 85 %.
Configuración de una Red Neuronal Artificial para clasificar imágenes
En este artículo, describimos algunas de las técnicas principales que se utilizan para poner en producción una red neuronal. Si quieres intentar ejecutar la red neuronal por tu cuenta, a continuación encontrarás los notebooks completos con una guía detallada paso a paso incluida.
Esta demostración utiliza el Stanford Cars Dataset disponible públicamente, que es uno de los conjuntos de datos públicos más completos, aunque un poco desactualizado, por lo que no encontrará modelos de automóviles posteriores a 2012 (aunque, una vez entrenado, el aprendizaje por transferencia podría permitir fácilmente la sustitución de un nuevo conjunto de datos). Los datos se proporcionan a través de una cuenta de almacenamiento de ADLS Gen2 que puede montar en su área de trabajo.

Para el primer paso del preprocesamiento de datos, las imágenes se comprimen en archivos hdf5 (uno para entrenamiento y otro para prueba). Luego, la red neuronal puede leer esto. Este paso puede omitirse por completo, si lo desea, ya que los archivos hdf5 son parte del almacenamiento ADLS Gen2 que se proporciona como parte de los notebooks aquí provistos.
- Cargar el conjunto de datos Stanford Cars en archivos HDF5
- Use Koalas para el aumento de imágenes.
- Entrenar la CNN con Keras
- Implementar el modelo como servicio REST en Azure ML
Aumento de imágenes con Koalas
La cantidad y diversidad de los datos recopilados tiene un gran impacto en los resultados que se pueden lograr con los modelos de aprendizaje profundo. El aumento de datos es una estrategia que puede mejorar significativamente los resultados del aprendizaje sin la necesidad de recopilar datos nuevos. Con diferentes técnicas como el recorte, el relleno y el volteo horizontal, que se utilizan comúnmente para entrenar grandes redes neuronales, los conjuntos de datos se pueden inflar artificialmente aumentando el número de imágenes para el entrenamiento y la prueba.
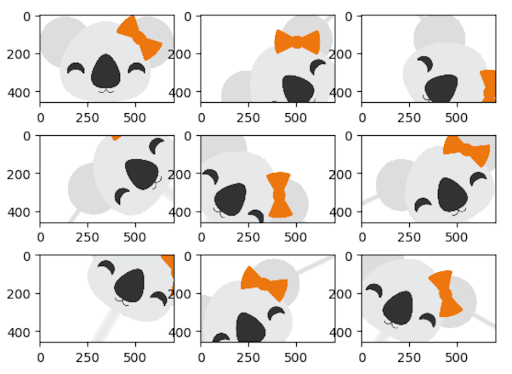
Aplicar la aumentación a un gran corpus de datos de entrenamiento puede ser muy costoso, especialmente al comparar los resultados de diferentes enfoques. Con Koalas, es fácil probar los frameworks existentes para la aumentación de imágenes en Python y escalar el proceso en un clúster con múltiples nodos utilizando la API de Pandas, familiar en la ciencia de datos.
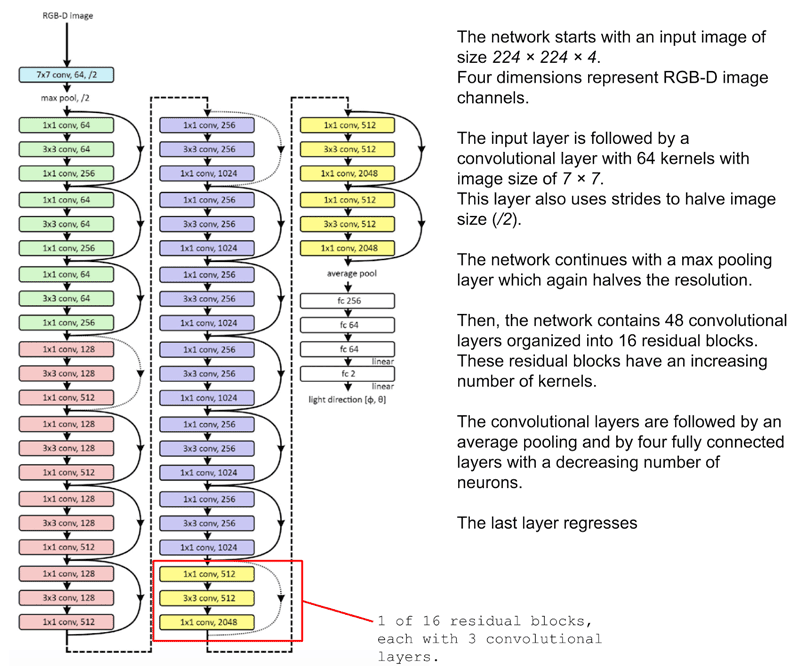
Codificación de una ResNet en Keras
Cuando descompones una CNN, esta se compone de diferentes 'bloques', y cada bloque simplemente representa un grupo de operaciones que se aplicarán a algunos datos de entrada. Estos bloques pueden clasificarse a grandes rasgos en:
- Bloque de identidad: una serie de operaciones que mantienen igual la forma de los datos.
- Bloque de convolución: una serie de operaciones que reducen la forma de los datos de entrada a una forma más pequeña.
Una CNN es una serie de Bloques de Identidad y Bloques de Convolución (o ConvBlocks) que reducen una imagen de entrada a un grupo compacto de números. Cada uno de estos números resultantes (si se entrena correctamente) debería eventualmente decirle algo útil para clasificar la imagen. Una CNN residual agrega un paso adicional para cada bloque. Los datos se guardan como una variable temporal antes de que se apliquen las operaciones que constituyen el bloque, y luego estos datos temporales se suman a los datos de salida. Generalmente, este paso adicional se aplica a cada bloque. Como ejemplo, la siguiente figura demuestra una CNN simplificada para detectar números escritos a mano:
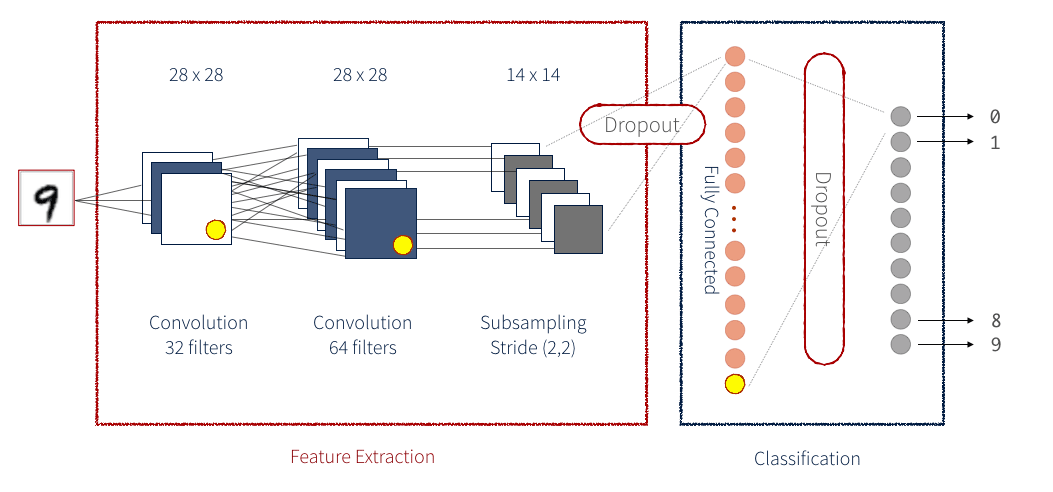
Existen muchos métodos diferentes para implementar una red neuronal. Una de las formas más intuitivas es a través de Keras. Keras proporciona una biblioteca de front-end simple para ejecutar los pasos individuales que componen una red neuronal. Keras se puede configurar para que funcione con un back-end de Tensorflow o un back-end de Theano. Aquí, usaremos un back-end de Tensorflow. Una red Keras se divide en múltiples capas, como se ve a continuación. Para nuestra red, también estamos definiendo nuestra implementación personalizada de una capa.
La capa de escala
Para cualquier operación personalizada que tenga pesos entrenables, Keras le permite implementar su propia capa. Al trabajar con grandes cantidades de datos de imágenes, pueden surgir problemas de memoria. Inicialmente, las imágenes RGB contienen datos enteros (0-255). Al ejecutar el descenso de gradiente como parte de la optimización durante la retropropagación, se encontrará que los gradientes enteros no permiten una precisión suficiente para ajustar correctamente los pesos de la red. Por lo tanto, es necesario cambiar a precisión de punto flotante. Aquí es donde pueden surgir problemas. Incluso cuando las imágenes se reducen a 224x224x3, si usamos diez mil imágenes de entrenamiento, estamos hablando de más de mil millones de entradas de punto flotante. En lugar de convertir todo un conjunto de datos a precisión de punto flotante, una mejor práctica es usar una 'Capa de Escala', que escala los datos de entrada una imagen a la vez y solo cuando es necesario. Esto debe aplicarse después de la Normalización por Lotes en el modelo. Los parámetros de esta Capa de Escala son también parámetros que se pueden aprender a través del entrenamiento.
Para usar esta capa personalizada también durante la puntuación, debemos empaquetar la clase junto con nuestro modelo. Con MLflow podemos lograr esto con un diccionario custom_objects de Keras que asigna nombres (cadenas) a clases o funciones personalizadas asociadas con el modelo de Keras. MLflow guarda estas capas personalizadas usando CloudPickle y las restaura automáticamente cuando el modelo se carga con mlflow.keras.load_model() y mlflow.pyfunc.load_model().
Seguimiento de resultados con MLflow y Azure Machine Learning
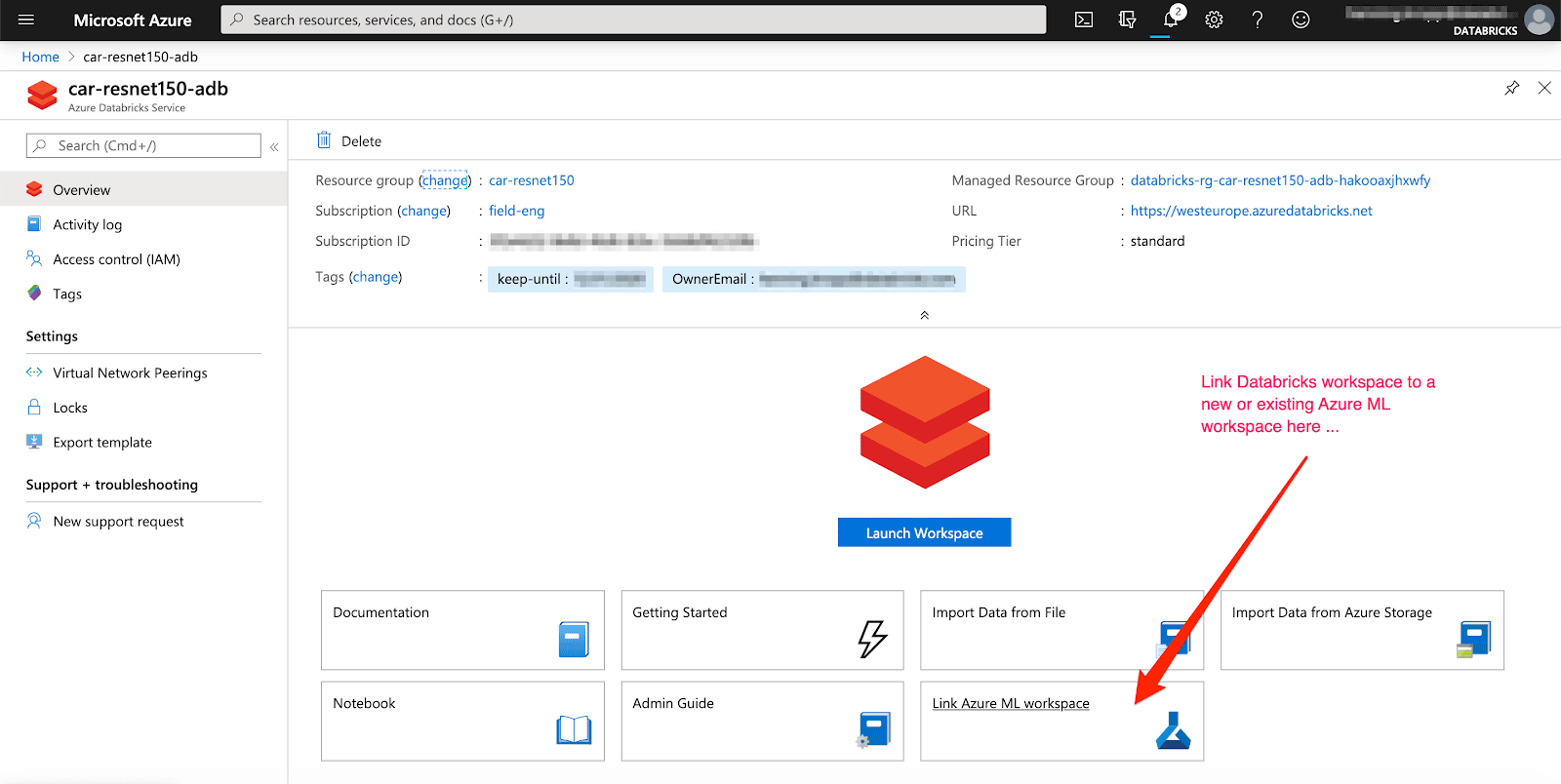
El desarrollo de aprendizaje automático implica complejidades adicionales más allá del desarrollo de software. El hecho de que haya una infinidad de herramientas y marcos de trabajo dificulta el seguimiento de los experimentos, la reproducción de los resultados y la implementación de los modelos de aprendizaje automático. Junto con Azure Machine Learning, se puede acelerar y gestionar el ciclo de vida del aprendizaje automático de punta a punta utilizando MLflow para crear, compartir e implementar de forma fiable aplicaciones de aprendizaje automático mediante Azure Databricks.
Para hacer un seguimiento automático de los resultados, se puede vincular un área de trabajo de Azure ML existente o nueva a tu área de trabajo de Azure Databricks. Además, MLflow admite el registro automático para los modelos Keras (mlflow.keras.autolog()), haciendo que la experiencia sea casi sin esfuerzo.
Si bien las utilidades de persistencia de modelos integradas de MLflow son convenientes para empaquetar modelos de varias bibliotecas de ML populares como Keras, no cubren todos los casos de uso. Por ejemplo, es posible que desee utilizar un modelo de una biblioteca de ML que no sea compatible explícitamente con los 'sabores' integrados de MLflow. Alternativamente, es posible que desee empaquetar código de inferencia y datos personalizados para crear un Modelo de MLflow. Afortunadamente, MLflow proporciona dos soluciones que se pueden utilizar para realizar estas tareas: Modelos personalizados de Python y Sabores personalizados.
En este escenario, queremos asegurarnos de que podemos usar un motor de inferencia de modelos que admita el servicio de solicitudes de un cliente de API de REST. Para esto, estamos usando un modelo personalizado basado en el modelo de Keras creado anteriormente para aceptar un objeto Dataframe JSON que tiene una imagen codificada en Base64 en su interior.
En el siguiente paso podemos usar este py_model y desplegarlo en un servidor de Azure Container Instances, lo que se puede lograr a través de la integración de Azure ML de MLflow.
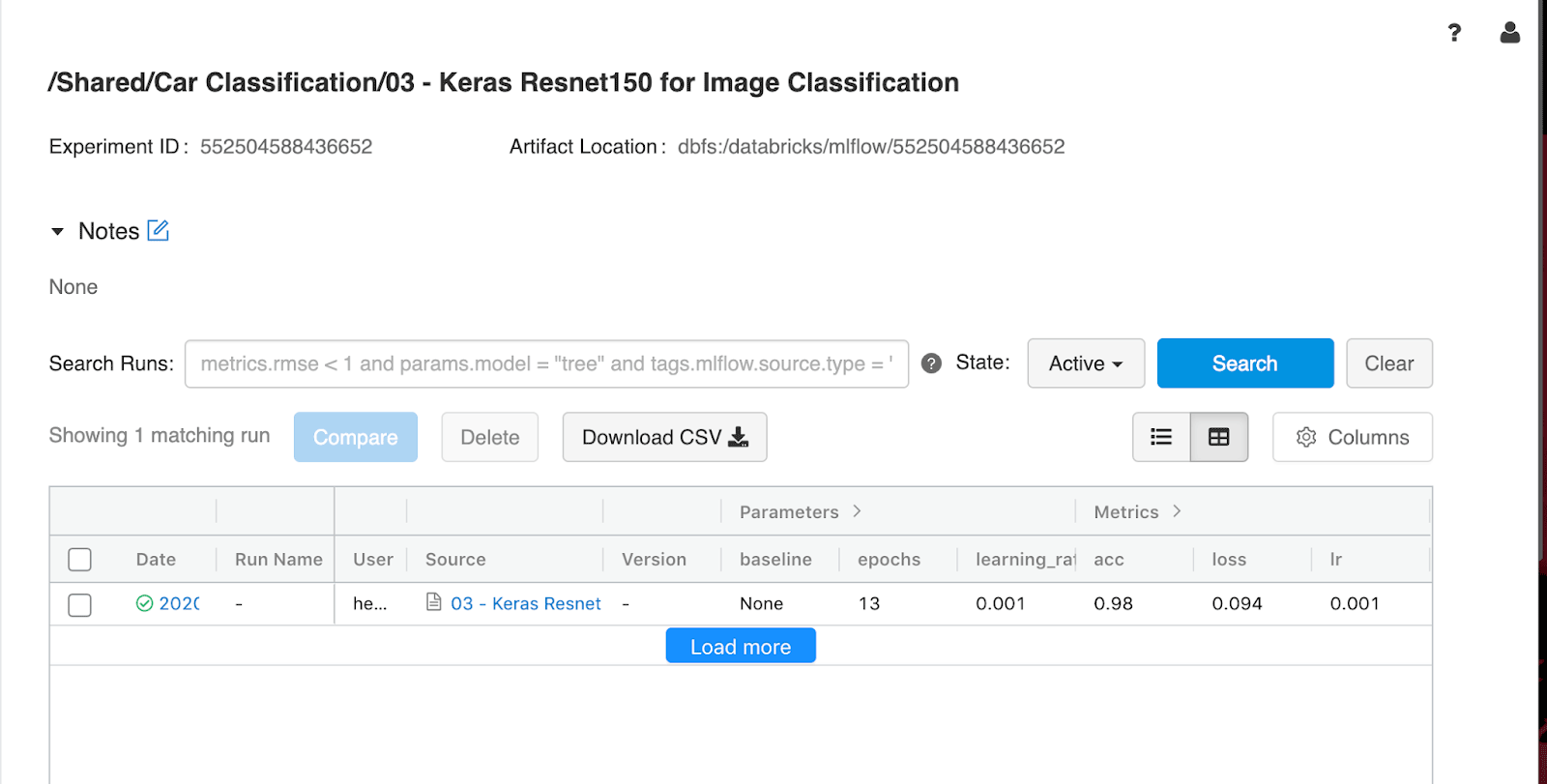
Implementar un modelo de clasificación de imágenes en Azure Container Instances
Ahora tenemos un modelo de aprendizaje automático entrenado y hemos registrado un modelo en nuestro espacio de trabajo con MLflow en la nube. Como paso final, nos gustaría implementar el modelo como un servicio web en Azure Container Instances.
Un servicio web es una imagen, en este caso, una imagen de Docker. Encapsula la lógica de puntuación y el propio modelo. En este caso, estamos usando nuestra representación de modelo MLflow personalizada, que nos da control sobre cómo la lógica de puntuación procesa las imágenes de un cliente de REST y cómo se da forma a la respuesta.
Las instancias de contenedor son una gran solución para probar y entender el flujo de trabajo. Para implementaciones de producción escalables, considere usar Azure Kubernetes Service. Para obtener más información, consulte cómo implementar y dónde.
Introducción a la clasificación de imágenes con CNN
Este artículo y los notebooks demuestran las principales técnicas utilizadas en la configuración de un flujo de trabajo de extremo a extremo para entrenar y desplegar una Red Neuronal en producción en Azure. Los ejercicios del notebook enlazado lo guiarán a través de los pasos necesarios para crear esto dentro de su propio entorno de Azure Databricks utilizando herramientas como Keras, Databricks Koalas, MLflow y Azure ML.
Recursos para desarrolladores
- Documentos interactivos
- Video: https://www.youtube.com/watch?v=mxEqcIbPqPs
- GitHub: https://github.com/EvanEames/Cars
- Diapositivas: https://www.slideshare.net/jonbros/deep-learning-with-databricks
- PDF: https://github.com/EvanEames/Cars/blob/master/CNN_howto.pdf
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.