Cómo los data lakehouses resuelven los problemas comunes de los data warehouses
por Ryan Boyd
Lea El ascenso del data lakehouse para explorar por qué los lakehouses son la arquitectura de datos del futuro con el padre del data warehouse, Bill Inmon.
Nota del editor: Esta es la primera de una serie de publicaciones basada en gran medida en el artículo de CIDR Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics, con el permiso de los autores.
Los analistas de datos, los científicos de datos y los expertos en inteligencia artificial suelen sentirse frustrados por la falta fundamental de datos de alta calidad, fiables y actualizados disponibles para su trabajo. Algunas de estas frustraciones se deben a las desventajas conocidas de la arquitectura de datos de dos niveles que prevalece hoy en la gran mayoría de las empresas de Fortune 500. La arquitectura abierta de lakehouse y la tecnología subyacente pueden mejorar drásticamente la productividad de los equipos de datos y, por lo tanto, la eficiencia de las empresas que los emplean.
Desafíos de la arquitectura de datos de dos niveles
En esta arquitectura popular, los datos de toda la organización se extraen de las bases de datos operativas y se cargan en un data lake sin procesar, a veces denominado pantano de datos, debido a la falta de cuidado para garantizar que estos datos sean utilizables y confiables. A continuación, se ejecuta de forma programada otro proceso ETL (extracción, transformación y carga) para mover subconjuntos importantes de los datos a un data warehouse para la inteligencia empresarial y la toma de decisiones.
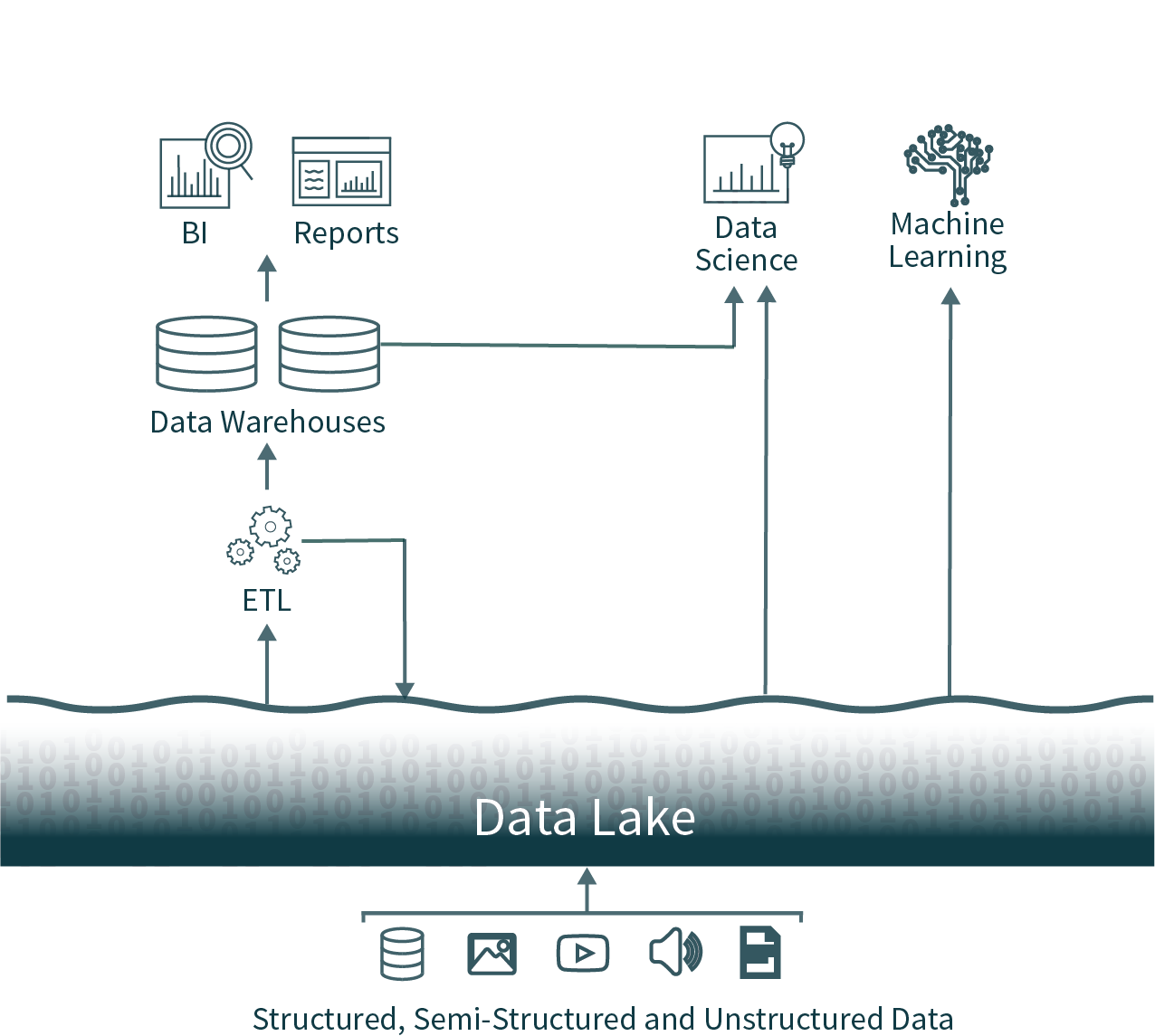
Esta arquitectura les da a los analistas de datos una opción casi imposible: usar datos oportunos y poco confiables del data lake o usar datos obsoletos y de alta calidad del data warehouse. Debido a los formatos cerrados de las soluciones de almacenamiento de datos (data warehousing) populares, también resulta muy difícil utilizar los frameworks de análisis de datos de código abierto (open-source) dominantes en fuentes de datos de alta calidad sin introducir otra operación de ETL y añadir obsolescencia adicional.
Podemos hacerlo mejor: presentamos el data lakehouse
Estas arquitecturas de datos de dos niveles, que son comunes en las empresas de hoy en día, son muy complejas tanto para los usuarios como para los ingenieros de datos que las construyen, independientemente de si están alojadas on-premise o en la nube.
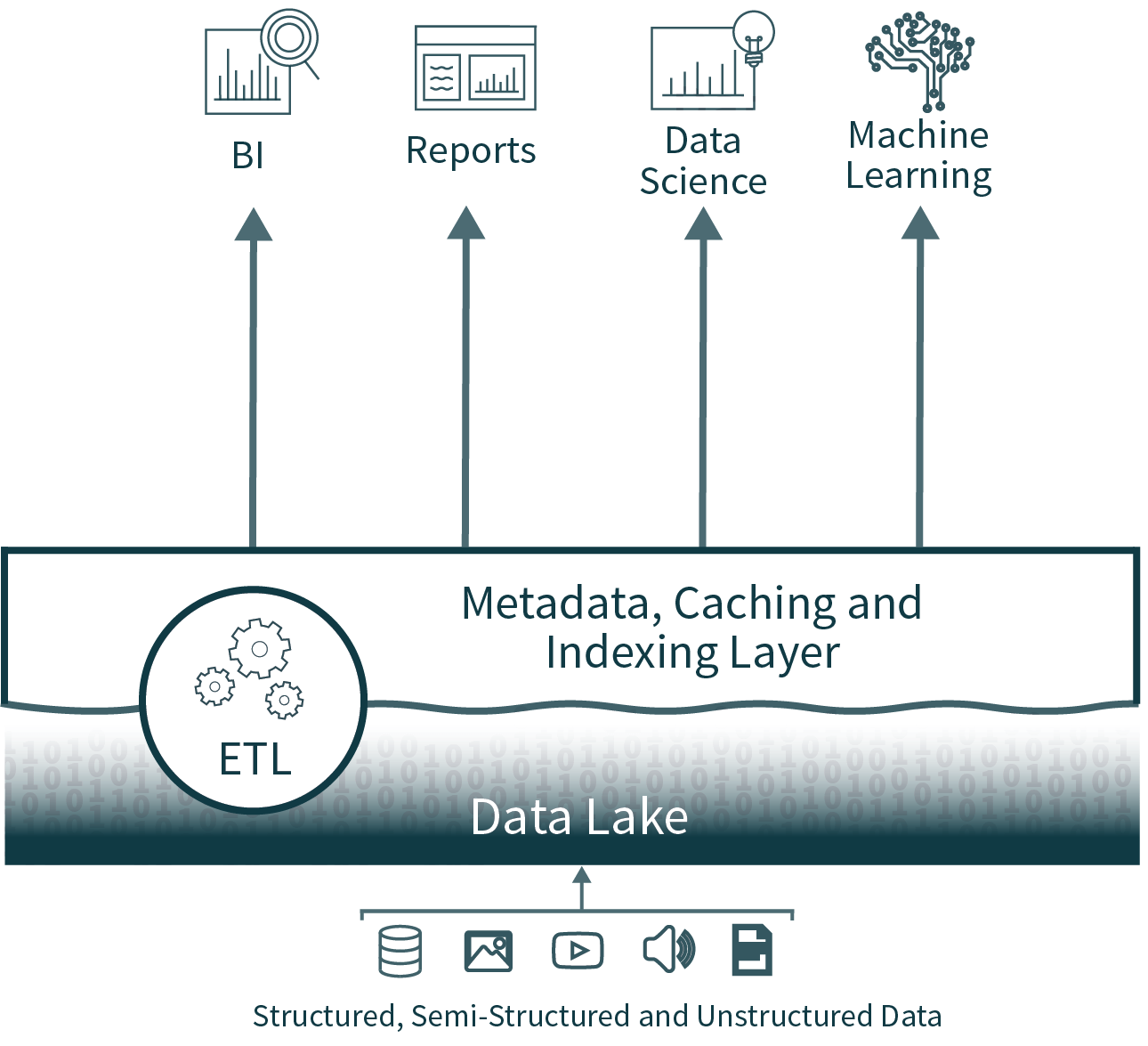
La arquitectura de lakehouse reduce la complejidad, el costo y la sobrecarga operativa al proporcionar muchas de las ventajas de fiabilidad y rendimiento de la capa del almacén de datos (data warehouse) directamente sobre el lago de datos (data lake), eliminando en última instancia la capa del almacén.
Confiabilidad de los datos
La consistencia de los datos es un reto increíble cuando se tienen múltiples copias de datos que mantener sincronizadas. Existen múltiples procesos de ETL, que mueven datos de las bases de datos operativas al data lake y nuevamente del data lake al data warehouse. Cada proceso adicional introduce complejidad, retrasos y modos de falla adicionales.
Al eliminar el segundo nivel, la arquitectura de data lakehouse quita uno de los procesos de ETL y, a la vez, agrega compatibilidad para la aplicación y evolución del esquema directamente sobre el data lake. También admite funciones como el viaje en el tiempo para permitir la validación histórica de la limpieza de los datos.
Desactualización de los datos
Como el data warehouse se puebla desde el data lake, a menudo está desactualizado. Esto obliga al 86 % de los analistas a usar datos desactualizados, según una encuesta reciente de Fivetran.

Aunque la eliminación de la capa del almacén de datos (data warehouse) resuelve este problema, un lakehouse también puede soportar la fusión eficiente, fácil y fiable de la transmisión en tiempo real (streaming) más el procesamiento por lotes (batch processing), para garantizar que los datos más actualizados se utilicen siempre para el análisis.
Soporte limitado para analítica avanzada
La analítica avanzada, incluido el aprendizaje automático (machine learning) y la analítica predictiva, suele requerir el procesamiento de conjuntos de datos muy grandes. Las herramientas comunes, como TensorFlow, PyTorch y XGBoost, facilitan la lectura de los lagos de datos (data lakes) sin procesar en formatos de datos abiertos. Sin embargo, estas herramientas no leen la mayoría de los formatos de datos propietarios utilizados por los datos sometidos a ETL en los almacenes de datos (data warehouses). Por lo tanto, los proveedores de almacenes recomiendan exportar estos datos a archivos para su procesamiento, lo que da lugar a un tercer paso de ETL, además de una mayor complejidad y obsolescencia.
Alternativamente, en la arquitectura de lakehouse abierta, estos conjuntos de herramientas comunes pueden operar directamente sobre datos oportunos y de alta calidad almacenados en el lago de datos (data lake).
Costo total de propiedad
Si bien los costos de almacenamiento en la nube están disminuyendo, esta arquitectura de dos niveles para el análisis de datos en realidad tiene tres copias en línea de gran parte de los datos empresariales: una en las bases de datos operativas, una en el data lake y una en el data warehouse.
El costo total de propiedad (TCO) se agrava aún más cuando a los costos de almacenamiento se suman los importantes costos de ingeniería asociados a mantener los datos sincronizados.
La arquitectura del data lakehouse elimina una de las copias más costosas de los datos, así como al menos un proceso de sincronización asociado.
¿Qué hay del rendimiento para la inteligencia de negocios?
La inteligencia empresarial y el soporte a la toma de decisiones requieren una ejecución de alto rendimiento de consultas de análisis exploratorio de datos (EDA), así como de las consultas que alimentan los dashboards, las visualizaciones de datos y otros sistemas críticos. Los problemas de rendimiento solían ser la razón por la que las empresas mantenían un almacén de datos (data warehouse) además de un lago de datos (data lake). La tecnología para optimizar consultas sobre los data lakes ha mejorado enormemente durante el último año, lo que vuelve irrelevante la mayoría de estas preocupaciones sobre el rendimiento.
Los lakehouses brindan soporte para la indexación, los controles de localidad, la optimización de consultas y el almacenamiento en caché de datos calientes para mejorar el rendimiento. Esto da como resultado un rendimiento de SQL del data lake que supera a los principales data warehouses en la nube en TPC-DS, y al mismo tiempo proporciona la flexibilidad y la gobernanza que se esperan de los data warehouses.
Conclusión y próximos pasos
Las empresas y los tecnólogos con visión de futuro han observado la arquitectura de dos niveles que se utiliza hoy en día y han dicho: “Tiene que haber una forma mejor”. Esta forma mejor es lo que llamamos el data lakehouse abierto, que combina la apertura y flexibilidad del data lake con la confiabilidad, el rendimiento, la baja latencia y la alta concurrencia de los data warehouses tradicionales.
Cubriré con más detalle las mejoras en el rendimiento de los lagos de datos (data lakes) en una próxima publicación de esta serie.
Por supuesto, puede hacer trampa y adelantarse leyendo el artículo completo de CIDR, o viendo una serie de videos que profundiza en la tecnología subyacente que soporta el lakehouse moderno.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.