Administración de Databricks Workspace – Mejores prácticas para administradores de cuentas, espacios de trabajo y metastores
Un cuento de tres administradores
Este blog forma parte de nuestra serie Admin Essentials, donde analizamos temas relevantes para los administradores de Databricks. Otros blogs incluyen nuestras Mejores Prácticas de Gestión de Espacios de Trabajo, Estrategias de DR con Terraform, ¡y muchos más! Esté atento a más contenido próximamente. En blogs anteriores centrados en administradores, hemos discutido cómo establecer y mantener una organización sólida del espacio de trabajo a través de un diseño inicial y la automatización de aspectos como DR, CI/CD y comprobaciones de estado del sistema. Un aspecto igualmente importante de la administración es cómo se organiza dentro de sus espacios de trabajo, especialmente cuando se trata de los muchos tipos diferentes de roles de administrador que pueden existir dentro de un Lakehouse. En este blog hablaremos sobre las consideraciones administrativas de la gestión de un espacio de trabajo, como por ejemplo:
- Configurar políticas y directrices para preparar la incorporación de nuevos usuarios y casos de uso para el futuro
- Gobernar el uso de recursos
- Garantizar el acceso permitido a los datos
- Optimizar el uso de cómputo para aprovechar al máximo su inversión
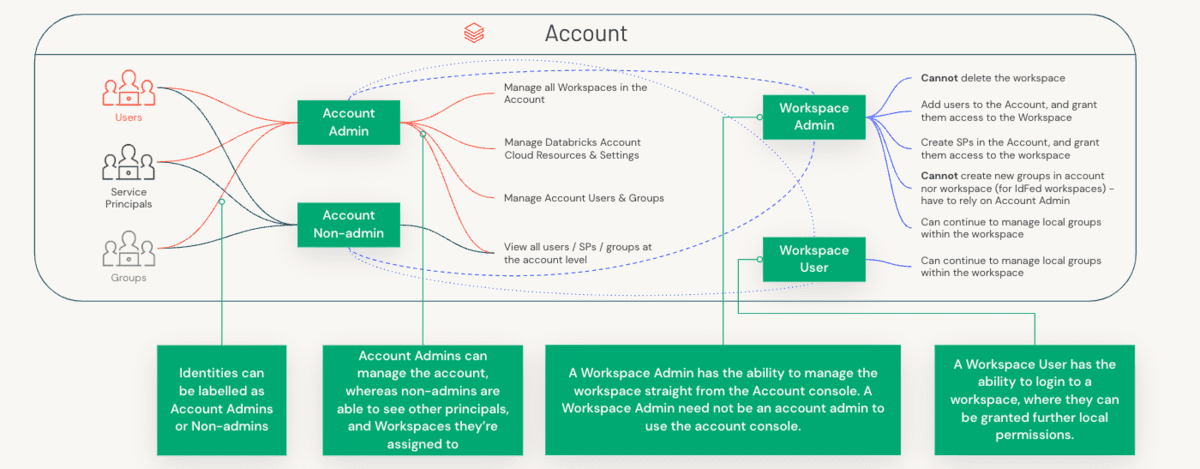
Para comprender la delimitación de roles, primero debemos entender la distinción entre un Administrador de Cuenta y un Administrador de Espacio de Trabajo, y los componentes específicos que cada uno de estos roles administra.
Administradores de Cuenta vs. Administradores de Espacio de Trabajo vs. Administradores de Metastore
Las preocupaciones administrativas se dividen entre cuentas (una construcción de alto nivel que a menudo se mapea 1:1 con su organización) y espacios de trabajo (un nivel de aislamiento más granular que se puede mapear de diversas maneras, por ejemplo, por LOB). Veamos la separación de funciones entre estos tres roles.
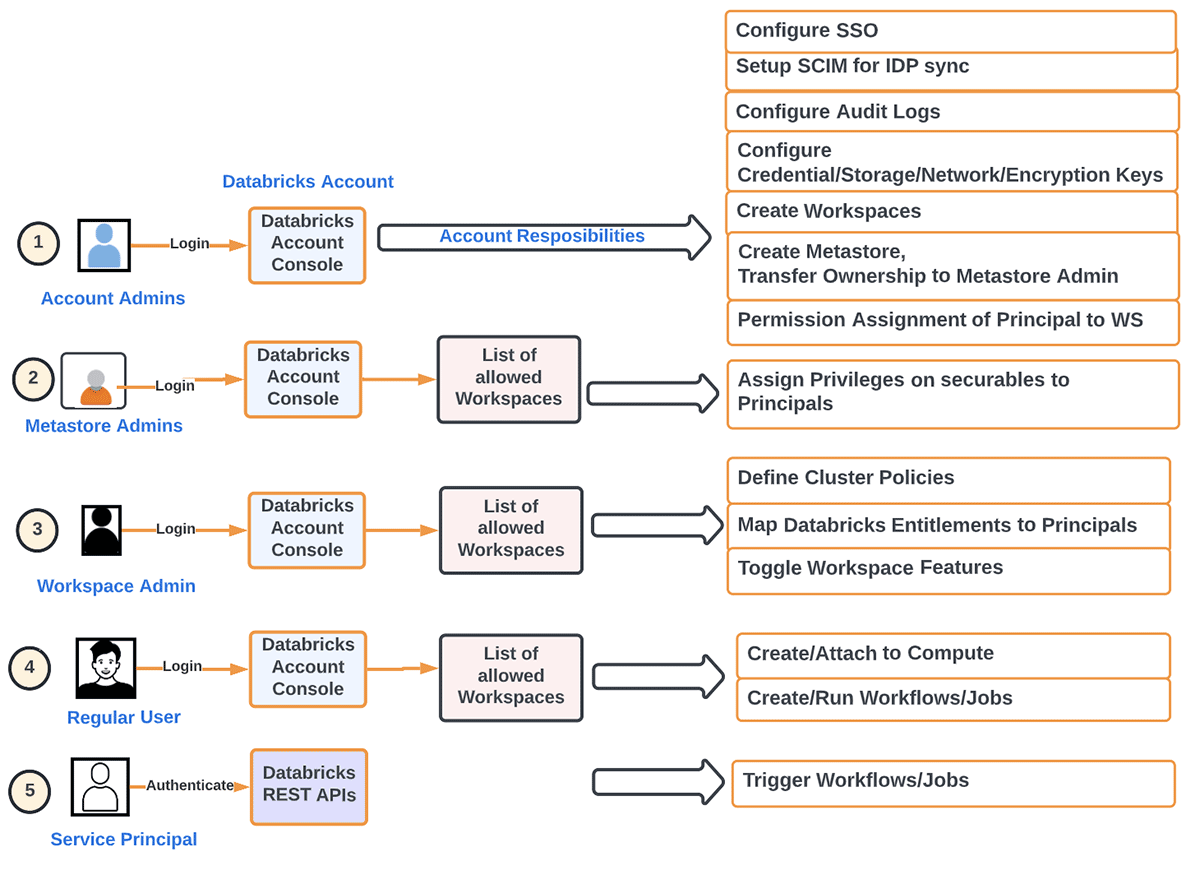
Para decirlo de otra manera, podemos desglosar las responsabilidades principales de un Administrador de Cuenta de la siguiente manera:
- Aprovisionamiento de Principales (Grupos/Usuarios/Servicio) y SSO a nivel de cuenta. Identity Federation se refiere a la asignación de identidades a nivel de cuenta acceso a espacios de trabajo directamente desde la cuenta.
- Configuración de Metastores
- Configuración del Registro de Auditoría
- Monitorización del uso a nivel de cuenta (DBU, Facturación)
- Creación de espacios de trabajo según el método de organización deseado
- Gestión de otros objetos a nivel de espacio de trabajo (almacenamiento, credenciales, red, etc.)
- Automatización de cargas de trabajo de desarrollo utilizando IaaC para eliminar el elemento humano en cargas de trabajo de producción
- Activación/desactivación de funciones a nivel de cuenta, como cargas de trabajo sin servidor, Delta sharing
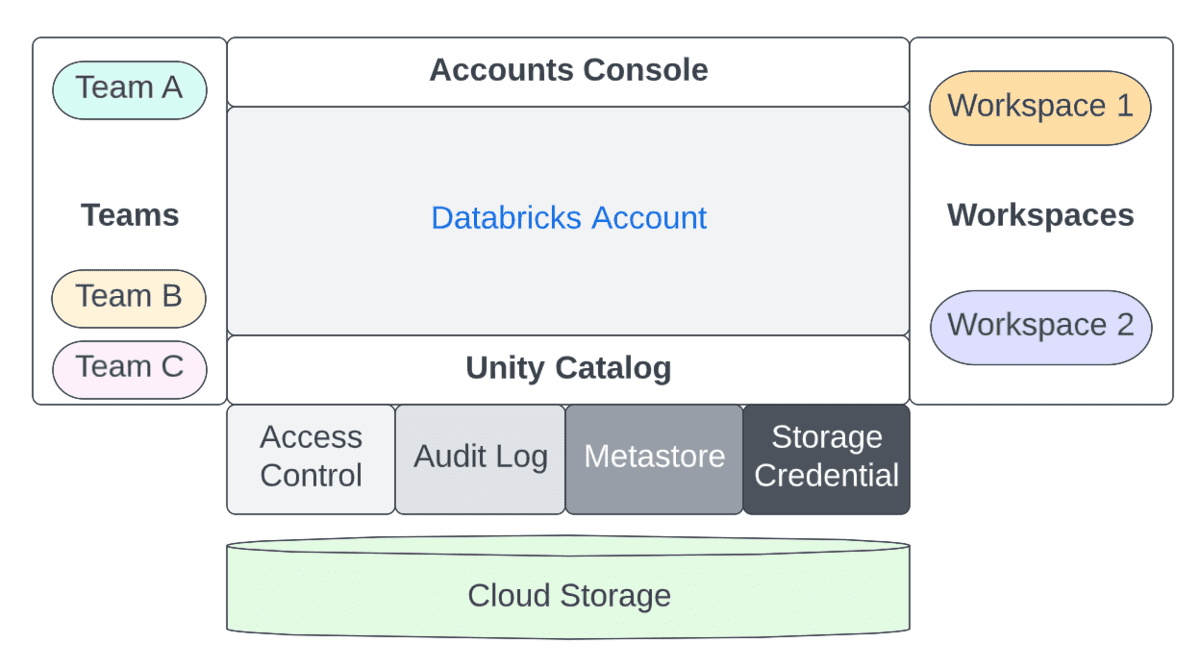
Por otro lado, las principales preocupaciones de un Administrador de Espacio de Trabajo son:
- Asignación de Roles apropiados (Usuario/Administrador) a nivel de espacio de trabajo a los Principales
- Asignación de Entitlements (ACLs) apropiados a nivel de espacio de trabajo a los Principales
- Configuración opcional de SSO a nivel de espacio de trabajo
- Definición de Políticas de Clúster para otorgar permisos a los Principales para que puedan
- Definir recursos de cómputo (Clústeres/Warehouses/Pools)
- Definir Orquestación (Jobs/Pipelines/Workflows)
- Activación/desactivación de funciones a nivel de Espacio de Trabajo
- Asignación de permisos a los Principales
- Acceso a Datos (al usar metastore interno/externo de Hive)
- Gestionar el acceso de los Principales a los recursos de cómputo
- Gestión de URLs externas para funciones como Repos (incluyendo listas de permitidos)
- Control de seguridad y protección de datos
- Desactivar/restringir DBFS para evitar la exposición accidental de datos entre equipos
- Evitar la descarga de datos de resultados (desde notebooks/DBSQL) para prevenir la exfiltración de datos
- Habilitar Control de Acceso (Objetos del Espacio de Trabajo, Clústeres, Pools, Trabajos, Tablas, etc.)
- Definición de la entrega de logs a nivel de clúster (es decir, configuración de almacenamiento para logs de clúster, idealmente a través de Políticas de Clúster)
Para resumir las diferencias entre el administrador de cuenta y el administrador de espacio de trabajo, la siguiente tabla captura la separación entre estos dos roles para algunas dimensiones clave:
| Administrador de Cuenta | Administrador de Metastore | Administrador de Espacio de Trabajo | |
|---|---|---|---|
| Gestión de Espacios de Trabajo | - Crear, Actualizar, Eliminar espacios de trabajo - Puede añadir otros administradores |
No Aplicable | - Solo gestiona activos dentro de un espacio de trabajo |
| Gestión de Usuarios | - Crear usuarios, grupos y principales de servicio o usar SCIM para sincronizar datos desde IDPs. - Otorgar permisos a Principales para Espacios de Trabajo con la API de Asignación de Permisos |
No Aplicable | - Recomendamos el uso de UC para la gobernanza centralizada de todos sus activos de datos (securables). Identity Federation estará activado para cualquier espacio de trabajo vinculado a un Metastore de Unity Catalog (UC). - Para espacios de trabajo habilitados en Identity Federation, configure SCIM a nivel de Cuenta para todos los Principales y detenga SCIM a nivel de Espacio de Trabajo. - Para Espacios de Trabajo que no sean UC, puede usar SCIM a nivel de espacio de trabajo (pero estos usuarios también serán promovidos a identidades a nivel de cuenta). - Los grupos creados a nivel de espacio de trabajo se considerarán grupos "locales" del espacio de trabajo y no tendrán acceso a Unity Catalog |
| Acceso y Gestión de Datos | - Crear Metastore(s) - Vincular Espacio(s) de Trabajo a Metastore - Transferir la propiedad del metastore al Administrador/grupo de Metastore |
Con Unity Catalog: - Gestionar privilegios sobre todos los securables (catálogo, esquema, tablas, vistas) del metastore - CONCEDER (Delegar) Acceso a Catálogo, Esquema (Base de Datos), Tabla, Vista, Ubicaciones Externas y Credenciales de Almacenamiento a Data Stewards/Owners |
- Hoy en día, con metastores de Hive, los clientes utilizan una variedad de constructos para proteger el acceso a los datos, como Instance Profiles en AWS, Service Principals en Azure, Table ACLs, Credential Passthrough, entre otros. - Con Unity Catalog, esto se define a nivel de cuenta y se utilizarán GRANTS ANSI para ACL todos los securables |
| Gestión de Clústeres | No Aplicable | No Aplicable | - Crear clústeres para varios roles/tamaños para roles de DE/ML/SQL para cargas de trabajo S/M/L - Eliminar el permiso de allow-cluster-create del grupo de usuarios predeterminado. - Crear Políticas de Clúster, otorgar acceso a las políticas a los grupos apropiados - Otorgar permiso Can_Use a los grupos para SQL Warehouses |
| Gestión de Flujos de Trabajo | No Aplicable | No Aplicable | - Asegurar que existan políticas de clústeres para trabajos/DLT/uso general y que los grupos tengan acceso a ellas - Pre-crear clústeres de propósito de aplicación que los usuarios puedan reiniciar |
| Gestión de Presupuestos | - Configurar presupuestos por espacio de trabajo/sku/etiquetas de clúster - Monitorizar el uso por etiquetas en la Consola de Cuentas (roadmap) - Tabla del sistema de uso facturable para consultar vía DBSQL (roadmap) |
No Aplicable | No Aplicable |
| Optimizar / Ajustar | No aplicable | No aplicable | - Maximizar cómputo; Usar DBR más reciente; Usar Photon - Trabajar junto con los equipos de Línea de Negocio/Centro de Excelencia para seguir las mejores prácticas y optimizaciones para aprovechar al máximo la inversión en infraestructura |
Dimensionamiento de un espacio de trabajo para satisfacer las necesidades de cómputo pico
El número máximo de nodos de clúster (indirectamente el trabajo más grande o el número máximo de trabajos concurrentes) está determinado por el número máximo de IPs disponibles en la VPC y, por lo tanto, el dimensionamiento correcto de la VPC es una consideración de diseño importante. Cada nodo ocupa 2 IPs (en Azure, AWS). Aquí están los detalles relevantes para la nube de su elección: AWS, Azure, GCP. Usaremos un ejemplo de Databricks en AWS para ilustrar esto. Use esto para mapear CIDR a IP. El rango CIDR de VPC permitido para un espacio de trabajo E2 es /25 - /16. Se deben configurar al menos 2 subredes privadas en 2 zonas de disponibilidad diferentes. Las máscaras de subred deben estar entre /16-/17. Las VPC son unidades de aislamiento lógicas y mientras 2 VPC no necesiten comunicarse, es decir, emparejarse entre sí, pueden tener el mismo rango. Sin embargo, si lo hacen, se debe tener cuidado para evitar la superposición de IP. Tomemos un ejemplo de una VPC con un rango CIDR /16:
| CIDR de VPC /16 | Máx. # de IPs para esta VPC: 65,536 | Clústeres de nodo único/múltiple se inician en una subred |
| 2 Zonas de Disponibilidad | Si cada Zona de Disponibilidad es /17: => 32,768 * 2 = 65,536 IPs, no es posible otra subred | 32,768 IPs => máximo de 16,384 nodos en cada subred |
| Si cada Zona de Disponibilidad es /23 en su lugar: => 512 * 2 = 1,024 IPs, quedan 65,536 - 1,024 = 64, 512 IPs | 512 IPs => máximo de 256 nodos en cada subred | |
| 4 Zonas de Disponibilidad | Si cada Zona de Disponibilidad es /18: 16,384 * 4 = 65,536 IPs, no es posible otra subred | 16,384 IPs => máximo de 8192 nodos en cada subred |
Equilibrio entre control y agilidad para administradores de espacios de trabajo
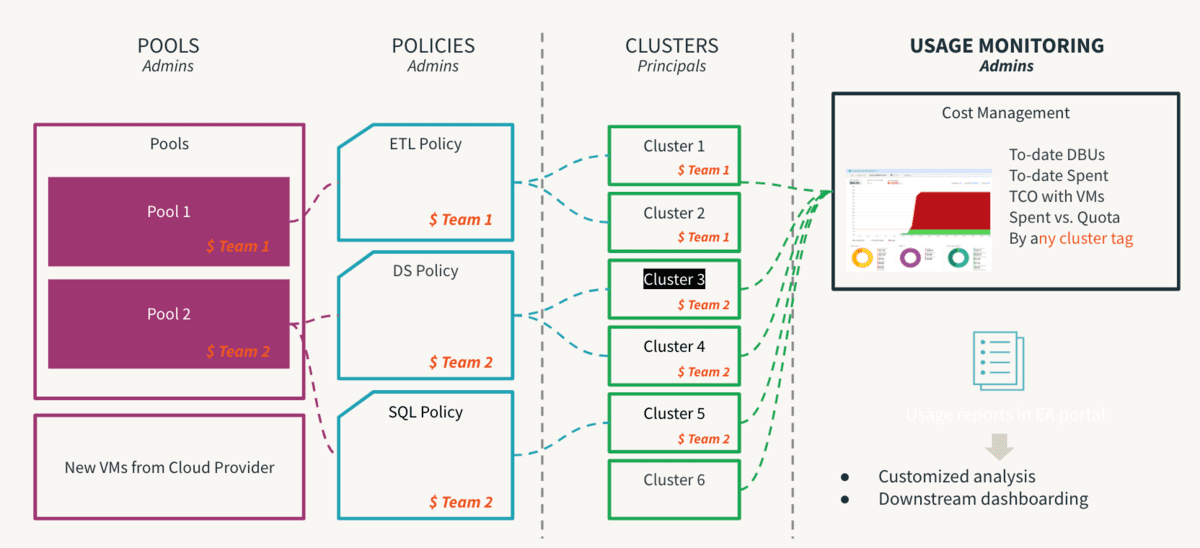
El cómputo es el componente más caro de cualquier inversión en infraestructura en la nube. La democratización de datos conduce a la innovación y facilitar el autoservicio es el primer paso para permitir una cultura impulsada por datos. Sin embargo, en un entorno multi-inquilino, un usuario inexperto o un error humano inadvertido podrían generar costos descontrolados o exposición inadvertida. Si los controles son demasiado estrictos, crearán cuellos de botella de acceso y sofocarán la innovación. Por lo tanto, los administradores deben establecer salvaguardas para permitir el autoservicio sin los riesgos inherentes. Además, deben poder monitorear el cumplimiento de estos controles. Aquí es donde las Políticas de Clúster resultan útiles, donde se definen las reglas y se mapean los permisos para que el usuario opere dentro de perímetros permitidos y su proceso de toma de decisiones se simplifique enormemente. Cabe señalar que las políticas deben estar respaldadas por procesos para ser verdaderamente efectivas, de modo que las excepciones puntuales puedan gestionarse mediante procesos para evitar un caos innecesario. Un paso crítico de este proceso es eliminar el permiso allow-cluster-create del grupo users predeterminado en un espacio de trabajo para que los usuarios solo puedan utilizar cómputo regido por Políticas de Clúster. Las siguientes son las principales recomendaciones de Mejores Prácticas de Políticas de Clúster y se pueden resumir a continuación:
- Usar tamaños de camiseta para proporcionar plantillas de clúster estándar
- Por tamaño de carga de trabajo (pequeño, mediano, grande)
- Por persona (DE/ ML/ BI)
- Por nivel de experiencia (ciudadano/ avanzado)
- Gestionar la Gobernanza aplicando el uso de
- Etiquetas: atribución por equipo, usuario, caso de uso
- la nomenclatura debe ser estandarizada
- hacer que algunos atributos sean obligatorios ayuda para la generación de informes coherente
- Etiquetas: atribución por equipo, usuario, caso de uso
- Controlar el Consumo limitando
- Tasa de consumo de DBU y propósito de la política
- Tiempo de espera de auto-terminación, tamaño mínimo/máximo de escalado
Consideraciones de cómputo
A diferencia de la infraestructura de cómputo fija local, la nube nos brinda elasticidad y flexibilidad para adaptar el cómputo adecuado a la carga de trabajo y al SLA en consideración. El siguiente diagrama muestra las diversas opciones. Las entradas son parámetros como el tipo de carga de trabajo o entorno y la salida es el tipo y tamaño de cómputo que mejor se adapta.
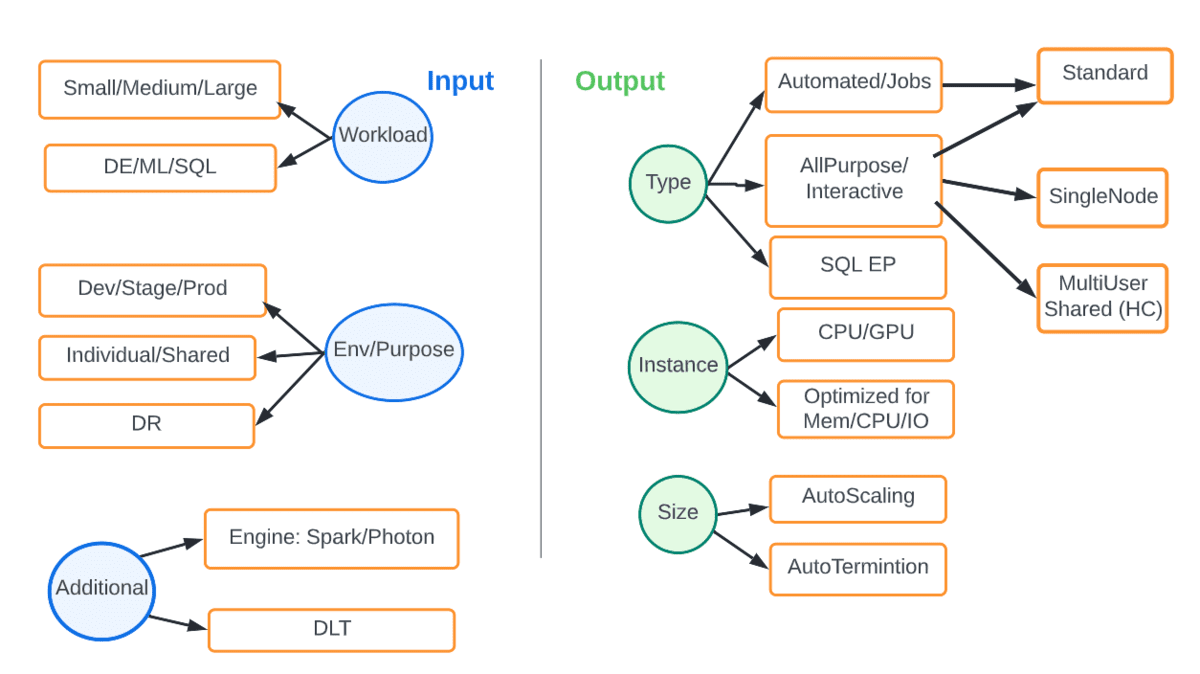
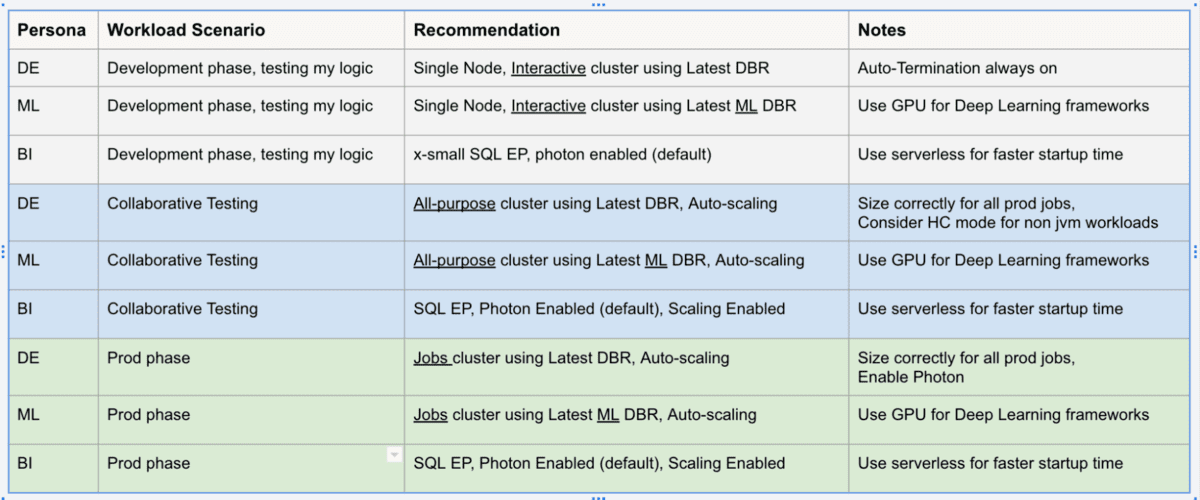
Por ejemplo, una carga de trabajo de ingeniería de datos (DE) de producción siempre debe estar en clústeres de trabajos automatizados, preferiblemente con el DBR más reciente, con escalado automático y utilizando el motor Photon. La siguiente tabla resume algunos escenarios comunes.
Consideraciones del flujo de trabajo
Ahora que los requisitos de cómputo se han formalizado, debemos considerar:
- Cómo se definirán y activarán los Flujos de Trabajo
- Cómo las Tareas pueden reutilizar cómputo entre sí
- Cómo se gestionarán las dependencias de Tareas
- Cómo se pueden reintentar las tareas fallidas
- Cómo se aplican las actualizaciones de versión (spark, librería) y los parches
Estas son consideraciones de Ingeniería de Datos y DevOps que se centran en el caso de uso y suelen ser una preocupación directa de un administrador. Hay algunas tareas de higiene que se pueden monitorear, como:
- Un espacio de trabajo tiene un límite máximo en el número total de trabajos configurados. Pero muchos de estos trabajos pueden no ser invocados y necesitan ser limpiados para dar espacio a los genuinos. Un administrador puede ejecutar verificaciones para determinar la lista de desalojo válida de trabajos inactivos.
- Todos los trabajos de producción deben ejecutarse como un principal de servicio y el acceso de los usuarios a un entorno de producción debe estar muy restringido. Revise los Permisos de Trabajos.
- Los trabajos pueden fallar, por lo que cada trabajo debe configurarse para alertas de fallos y opcionalmente para reintentos. Revise las propiedades email_notifications, max_retries y otras aquí
- Cada trabajo debe asociarse con políticas de clúster y etiquetarse adecuadamente para su atribución.
DLT: Ejemplo de un marco ideal para pipelines confiables a escala
Trabajando con miles de clientes, grandes y pequeños, en diferentes verticales de la industria, se hicieron evidentes los desafíos comunes de datos para el desarrollo y la operacionalización, por lo que Databricks creó Delta Live Tables (DLT). Es una plataforma administrada que ofrece simplificar el desarrollo y mantenimiento de cargas de trabajo ETL al permitir la creación de pipelines declarativos donde usted especifica el 'qué' y no el 'cómo'. Esto simplifica las tareas de un ingeniero de datos, lo que lleva a menos escenarios de soporte para los administradores.
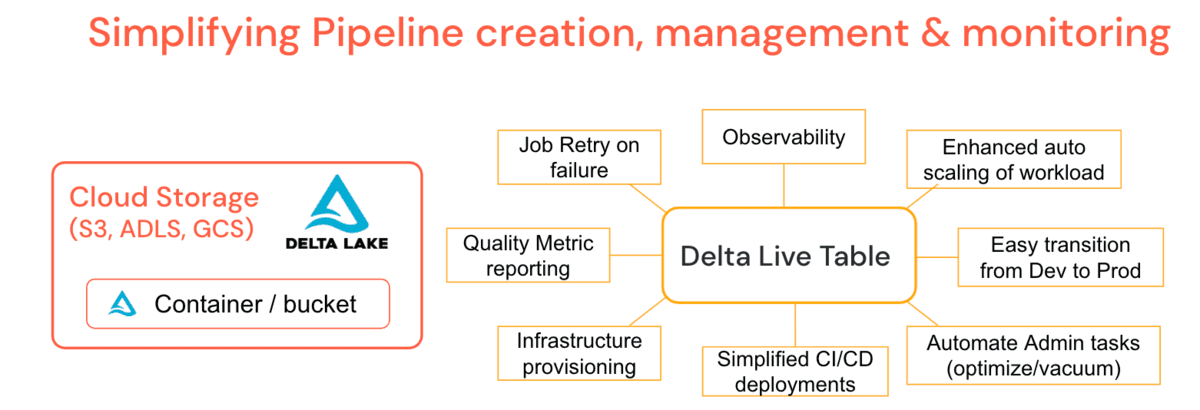
DLT incorpora funcionalidades comunes de administración como trabajos periódicos de optimize y vacuum directamente en la definición de la canalización con un trabajo de mantenimiento que garantiza que se ejecuten sin supervisión adicional. DLT ofrece una observabilidad profunda de las canalizaciones para operaciones simplificadas como linaje, monitoreo y verificaciones de calidad de datos. Por ejemplo, si el clúster se termina, la plataforma reintenta automáticamente (en modo de producción) en lugar de depender de que el ingeniero de datos lo haya aprovisionado explícitamente. El escalado automático mejorado puede manejar ráfagas de datos repentinas que requieren un aumento del clúster y una reducción gradual. En otras palabras, el escalado automático de clústeres y la tolerancia a fallos de la canalización son una característica de la plataforma. Las latencias de la mesa giratoria le permiten ejecutar canalizaciones en modo batch o streaming y mover canalizaciones de desarrollo a producción con relativa facilidad administrando la configuración en lugar del código. Puede controlar el costo de sus canalizaciones utilizando Políticas de clúster específicas de DLT. DLT también actualiza automáticamente su motor de tiempo de ejecución, eliminando así la responsabilidad de los administradores o ingenieros de datos, y permitiéndole centrarse únicamente en generar valor comercial.
UC: Ejemplo de un marco ideal de gobernanza de datos
Unity Catalog (UC) permite a las organizaciones adoptar un modelo de seguridad común para tablas y archivos para todos los espacios de trabajo bajo una sola cuenta, lo que antes no era posible a través de simples sentencias GRANT. Al otorgar y auditar todo el acceso a datos, tablas o archivos, desde un clúster DE/DS o un SQL Warehouse, las organizaciones pueden simplificar su estrategia de auditoría y monitoreo sin depender de primitivas por nube. Las capacidades principales que proporciona UC incluyen:
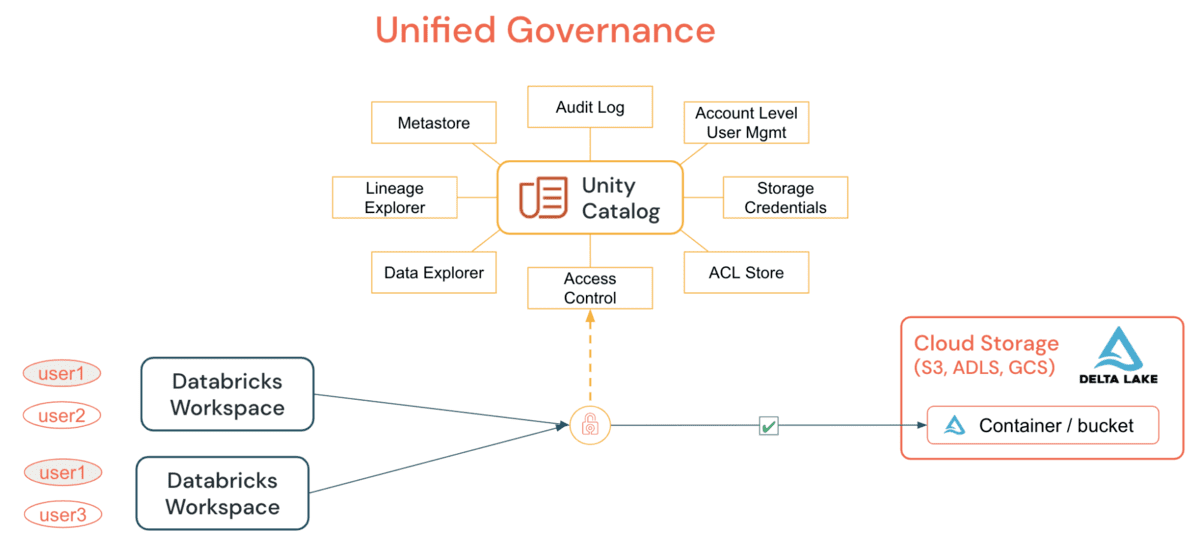
UC simplifica el trabajo de un administrador (tanto a nivel de cuenta como de espacio de trabajo) al centralizar las definiciones, el monitoreo y la detectabilidad de los datos en todo el metastore, y al facilitar el intercambio seguro de datos independientemente del número de espacios de trabajo que estén adjuntos a él. Utilizando el modelo Define Once, Secure Everywhere, esto tiene la ventaja adicional de evitar la exposición accidental de datos en el escenario de privilegios de un usuario representados inadvertidamente en un espacio de trabajo que podría darles una puerta trasera para acceder a datos que no estaban destinados a su consumo. Todo esto se puede lograr fácilmente utilizando Identidades a Nivel de Cuenta y Permisos de Datos. El Registro de Auditoría de UC permite una visibilidad completa de todas las acciones de todos los usuarios en todos los niveles sobre todos los objetos, y si configura el registro de auditoría detallado, se captura cada comando ejecutado, desde un notebook o Databricks SQL. El acceso a los elementos protegibles puede ser otorgado por un administrador del metastore, el propietario de un objeto, o el propietario del catálogo o esquema que contiene el objeto. Se recomienda que el administrador a nivel de cuenta delegue el rol de metastore nominando a un grupo para que sean los administradores del metastore cuyo único propósito es otorgar los privilegios de acceso correctos.
Recomendaciones y mejores prácticas
- Los roles y responsabilidades de los administradores de cuenta, administradores del metastore y administradores del espacio de trabajo están bien definidos y son complementarios. Los flujos de trabajo como la automatización, las solicitudes de cambio, las escalaciones, etc., deben dirigirse a los propietarios apropiados, ya sea que los espacios de trabajo sean configurados por LOB o administrados por un Centro de Excelencia central.
- Se deben habilitar las Identidades a Nivel de Cuenta, ya que esto permite la gestión centralizada de principios para todos los espacios de trabajo, simplificando así la administración. Recomendamos configurar funciones como SSO, SCIM y Registros de Auditoría a nivel de cuenta. El SSO a nivel de espacio de trabajo todavía es necesario, hasta que la función de Federación de SSO esté disponible.
- Las Políticas de Clúster son una palanca poderosa que proporciona barreras de protección para un autoservicio efectivo y simplifica enormemente el rol de un administrador de espacio de trabajo. Proporcionamos algunas políticas de ejemplo aquí. El administrador de la cuenta debe proporcionar políticas predeterminadas simples basadas en la persona principal/tamaño de camiseta, idealmente a través de automatización como Terraform. Los administradores del espacio de trabajo pueden agregar a esa lista para controles más granulares. Combinado con un proceso adecuado, todos los escenarios de excepción pueden acomodarse con gracia.
- El seguimiento del consumo continuo para todos los tipos de carga de trabajo en todos los espacios de trabajo es visible para los administradores de cuenta a través de la consola de cuentas. Recomendamos configurar la entrega de registros de uso facturable para que todo vaya a su almacenamiento en la nube central para la imputación de costos y el análisis. La API de Presupuesto (En vista previa) debe configurarse a nivel de cuenta, lo que permite a los administradores de cuenta crear umbrales a nivel de espacios de trabajo, SKU y etiquetas de clúster y recibir alertas sobre el consumo para que se puedan tomar medidas oportunas para mantenerse dentro de los presupuestos asignados. Utilice una herramienta como Overwatch para rastrear el uso a un nivel aún más granular para ayudar a identificar áreas de mejora en cuanto a la utilización de los recursos de cómputo.
- La plataforma Databricks continúa innovando y simplificando el trabajo de las diversas personas de datos al abstraer las funcionalidades comunes de administración en la plataforma. Nuestra recomendación es usar Delta Live Tables para nuevas canalizaciones y Unity Catalog para toda su gestión de usuarios y control de acceso a datos.
Finalmente, es importante tener en cuenta que para la mayoría de estas mejores prácticas, y de hecho, la mayoría de las cosas que mencionamos en este blog, la coordinación y el trabajo en equipo son primordiales para el éxito. Aunque teóricamente es posible que los administradores de Cuentas y Espacios de Trabajo existan de forma aislada, esto no solo va en contra de los principios generales de Lakehouse, sino que dificulta la vida de todos los involucrados. Quizás la sugerencia más importante que debes llevarte de este artículo es conectar a los administradores de Cuentas/Espacios de Trabajo + Líderes de Proyectos/Datos + Usuarios dentro de tu propia organización. Mecanismos como un canal de Teams/Slack, una lista de correo electrónico y/o una reunión semanal han demostrado ser exitosos. Las organizaciones más efectivas que vemos aquí en Databricks son aquellas que adoptan la apertura no solo en su tecnología, sino también en sus operaciones. Mantente atento a más blogs centrados en administradores próximamente, desde recomendaciones de registro y exfiltración hasta emocionantes resúmenes de las características de nuestra plataforma centradas en la gestión.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.