Creación de productos de datos geoespaciales
por Milos Colic
Este blog está desactualizado. Consulte este blog de Spatial SQL para conocer enfoques actualizados sobre el almacenamiento y procesamiento de datos geoespaciales dentro de su Databricks Lakehouse.
Los datos geoespaciales han impulsado la innovación durante siglos, a través del uso de mapas, cartografía y, más recientemente, de contenido digital. Por ejemplo, el mapa más antiguo se encontró grabado en un trozo de colmillo de mamut y data de aproximadamente 25000 a.C.. Esto convierte a los datos geoespaciales en una de las fuentes de datos más antiguas utilizadas por la sociedad para tomar decisiones. Un ejemplo más reciente, etiquetado como el nacimiento del análisis espacial, es el de Charles Picquet en 1832, quien utilizó datos geoespaciales para analizar brote de cólera en París; un par de décadas después, John Snow en 1854 siguió el mismo enfoque para brote de cólera en Londres. Estas dos personas utilizaron datos geoespaciales para resolver uno de los problemas más difíciles de su tiempo y, en efecto, salvar innumerables vidas. Avanzando rápidamente hasta el siglo XX, el concepto de Sistemas de Información Geográfica (SIG) se introdujo por primera vez en 1967 en Ottawa, Canadá, por el Departamento de Silvicultura y Desarrollo Rural.
Hoy nos encontramos en medio de la revolución de la industria de la computación en la nube: escala de supercomputación disponible para cualquier organización, virtualmente escalable infinitamente tanto para almacenamiento como para cómputo. Conceptos como data mesh y data marketplace están surgiendo dentro de la comunidad de datos para abordar preguntas como la federación de plataformas y la interoperabilidad. ¿Cómo podemos adoptar estos conceptos para datos geoespaciales, análisis espacial y sistemas SIG? Adoptando el concepto de productos de datos y abordando el diseño de datos geoespaciales como un producto.
En este blog, proporcionaremos un punto de vista sobre cómo diseñar productos de datos geoespaciales escalables que sean modernos y robustos. Discutiremos cómo la Plataforma Databricks Lakehouse puede utilizarse para desbloquear todo el potencial de los productos geoespaciales, que son uno de los activos más valiosos para resolver los problemas más difíciles de hoy y del futuro.
¿Qué es un producto de datos? ¿Y cómo diseñar uno?
La definición más amplia y concisa de "producto de datos" fue acuñada por DJ Patil (el primer científico de datos jefe de EE. UU.) en Data Jujitsu: The Art of Turning Data into Product: "un producto que facilita un objetivo final a través del uso de datos". La complejidad de esta definición (como admitió el propio Patil) es necesaria para encapsular la amplitud de los productos posibles, para incluir paneles, informes, hojas de cálculo de Excel e incluso extractos de CSV compartidos por correo electrónico. Es posible que observe que los ejemplos proporcionados se deterioran rápidamente en calidad, robustez y gobernanza.
¿Cuáles son los conceptos que diferencian un producto exitoso de uno no exitoso? ¿Es el empaque? ¿Es el contenido? ¿Es la calidad del contenido? ¿O es solo la adopción del producto en el mercado? Forbes define los 10 requisitos de un producto exitoso. Un buen marco para resumir esto es a través de la pirámide de valor.
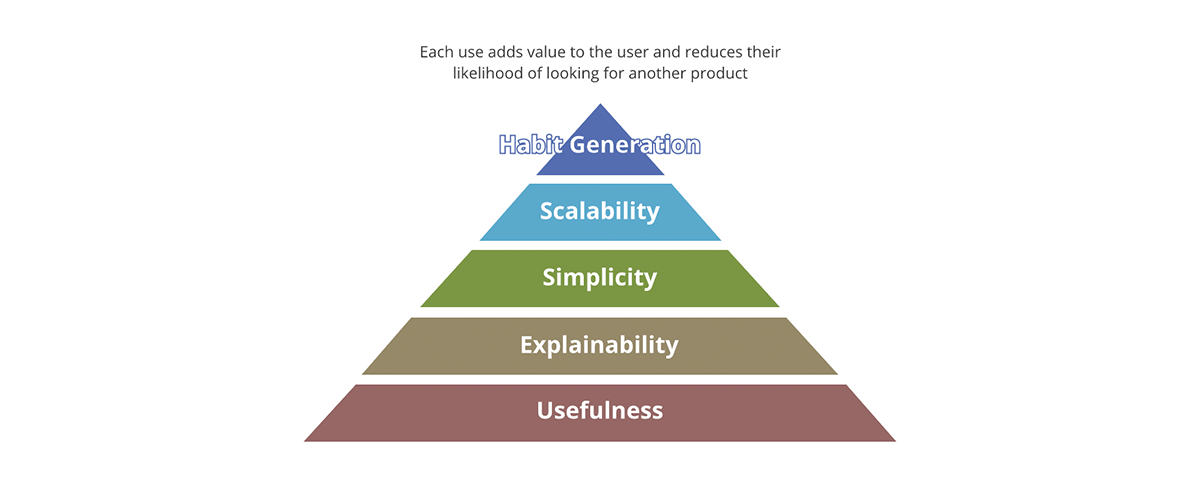
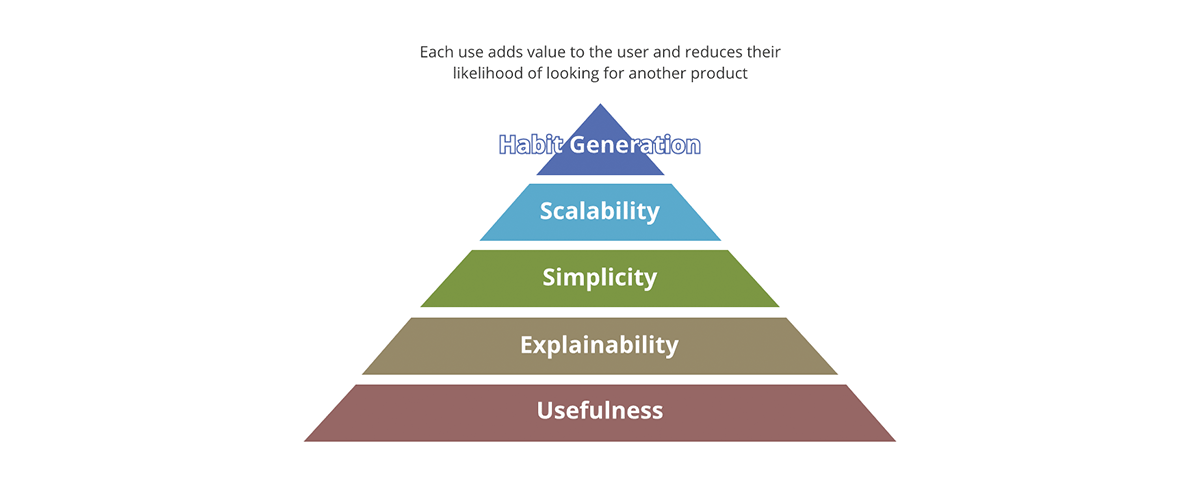{kind=link}
La pirámide de valor proporciona una prioridad a cada aspecto del producto. No todas las preguntas de valor que hacemos sobre el producto tienen el mismo peso. Si el resultado no es útil, ninguno de los otros aspectos importa: el resultado no es realmente un producto, sino que se convierte más en un contaminante de datos para el conjunto de resultados útiles. Del mismo modo, la escalabilidad solo importa después de abordar la simplicidad y la explicabilidad.
¿Cómo se relaciona la pirámide de valor con los productos de datos? Cada salida de datos, para ser un producto de datos:
- Debe tener una utilidad clara. La cantidad de datos que genera la sociedad solo es rivalizada por la cantidad de contaminantes de datos que generamos. Estas son salidas que carecen de valor y uso claros, y mucho menos de una estrategia sobre qué hacer con ellas.
- Debe ser explicable. Con el surgimiento de la IA/ML, la explicabilidad se ha vuelto aún más importante para la toma de decisiones basada en datos. Los datos son tan buenos como los metadatos que los describen. Piénselo en términos de alimentos: el sabor importa, pero un factor más importante es el valor nutricional de los ingredientes.
- Debe ser simple. Un ejemplo de uso indebido del producto es usar un tenedor para comer cereal en lugar de una cuchara. Además, la simplicidad es esencial pero no suficiente; más allá de la simplicidad, los productos deben ser intuitivos. Siempre que sea posible, tanto los usos previstos como los no previstos de los datos deben ser obvios.
- Debe ser escalable. Los datos son uno de los pocos recursos que crecen con el uso. Cuantos más datos procese, más datos tendrá. Si tanto las entradas como las salidas del sistema no tienen límites y crecen constantemente, el sistema debe ser escalable en potencia de cómputo, capacidad de almacenamiento y poder expresivo de cómputo. Las plataformas de datos en la nube como Databricks están en una posición única para responder a los tres aspectos.
- Debe generar hábitos. En el dominio de los datos, no nos preocupamos por la retención de clientes como es el caso de los productos minoristas. Sin embargo, el valor de la generación de hábitos es obvio si se aplica a las mejores prácticas. Los sistemas y las salidas de datos deben exhibir las mejores prácticas y promoverlas : debe ser más fácil usar los datos y el sistema de la manera prevista que lo contrario.
Los datos geoespaciales deben cumplir con todos los aspectos mencionados; cualquier producto de datos debe hacerlo. Además de esta difícil tarea, los datos geoespaciales tienen algunas necesidades específicas.
Estándares de datos geoespaciales
Los estándares de datos geoespaciales se utilizan para garantizar que los datos geográficos se recopilen, organicen y compartan de manera consistente y confiable. Estos estándares pueden incluir pautas para cosas como el formato de datos, sistemas de coordenadas, proyecciones de mapas y metadatos. Cumplir con los estándares facilita el intercambio de datos entre diferentes organizaciones, lo que permite una mayor colaboración y un acceso más amplio a la información geográfica.
La Comisión Geoespacial (Gobierno del Reino Unido) ha definido el Registro de Estándares de Datos Geoespaciales del Reino Unido como un repositorio central para los estándares de datos que se aplicarán en el caso de datos geoespaciales. Además, la misión de este registro es:
- "Garantizar que los datos geoespaciales del Reino Unido sean más consistentes, coherentes y utilizables en una gama más amplia de sistemas." - Estos conceptos son una llamada a la importancia de la explicabilidad, la utilidad y la generación de hábitos (posiblemente otros aspectos de la pirámide de valor).
- "Capacitar a la comunidad geoespacial del Reino Unido para que participe más activamente en los estándares y organismos de estándares relevantes." - La generación de hábitos dentro de la comunidad es tan importante como el diseño robusto y crítico del estándar. Si no se adoptan, los estándares son inútiles.
- "Abogar por la comprensión y el uso de los estándares de datos geoespaciales dentro de otros sectores del gobierno." - La pirámide de valor también se aplica a los estándares: conceptos como la facilidad de cumplimiento (utilidad/simplicidad), el propósito del estándar (explicabilidad/utilidad), la adopción (generación de hábitos) son críticos para la generación de valor de un estándar.
Una herramienta crítica para lograr la misión de los estándares de datos son los principios de datos FAIR:
- Findable (Encontrable) - El primer paso para (re)utilizar datos es encontrarlos. Los metadatos y los datos deben ser fáciles de encontrar tanto para humanos como para computadoras. Los metadatos legibles por máquina son esenciales para el descubrimiento automático de conjuntos de datos y servicios.
- Accessible (Accesible) - Una vez que el usuario encuentra los datos requeridos, él/ella/ellos necesitan saber cómo se pueden acceder, incluyendo posiblemente autenticación y autorización.
- Interoperable - Los datos generalmente deben integrarse con otros datos. Además, los datos deben interoperar con aplicaciones o flujos de trabajo para análisis, almacenamiento y procesamiento.
- Reusable - El objetivo final de FAIR es optimizar la reutilización de los datos. Para lograr esto, los metadatos y los datos deben estar bien descritos para que puedan replicarse y/o combinarse en diferentes entornos.
Compartimos la creencia de que los principios FAIR son cruciales para el diseño de productos de datos escalables en los que podamos confiar. Para ser justos, FAIR se basa en el sentido común, entonces, ¿por qué es clave para nuestras consideraciones? "Lo que veo en FAIR no es nuevo en sí mismo, pero lo que hace bien es articular, de una manera accesible, la necesidad de un enfoque holístico para la mejora de los datos. Esta facilidad de comunicación es la razón por la que FAIR se está utilizando cada vez más como un paraguas para la mejora de los datos, y no solo en la comunidad geoespacial." - A FAIR wind sets our course for data improvement.
Para apoyar aún más este enfoque, el Federal Geographic Data Committee ha desarrollado el National Spatial Data Infrastructure (NSDI) Strategic Plan que cubre los años 2021-2024 y fue aprobado en noviembre de 2020. Los objetivos de NSDI son, en esencia, los principios FAIR y transmiten el mismo mensaje de diseñar sistemas que promuevan la economía circular de los datos: productos de datos que fluyen entre organizaciones siguiendo estándares comunes y en cada paso a través de la cadena de suministro de datos desbloquean nuevo valor y nuevas oportunidades. El hecho de que estos principios estén permeando diferentes jurisdicciones y sean adoptados por diferentes reguladores es un testimonio de la robustez y solidez del enfoque.

{kind=link}
Los conceptos FAIR se entrelazan muy bien con el diseño de productos de datos. De hecho, FAIR atraviesa toda la pirámide de valor del producto y forma un ciclo de valor. Al adoptar tanto la pirámide de valor como los principios FAIR, diseñamos productos de datos con una perspectiva interna y externa. Esto promueve la reutilización de datos en lugar de la acumulación de datos.
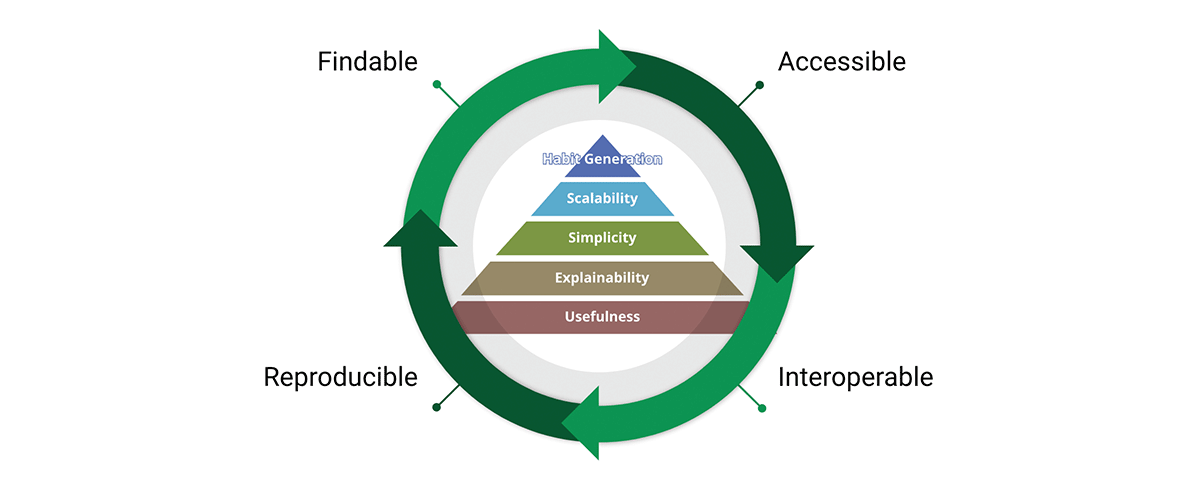
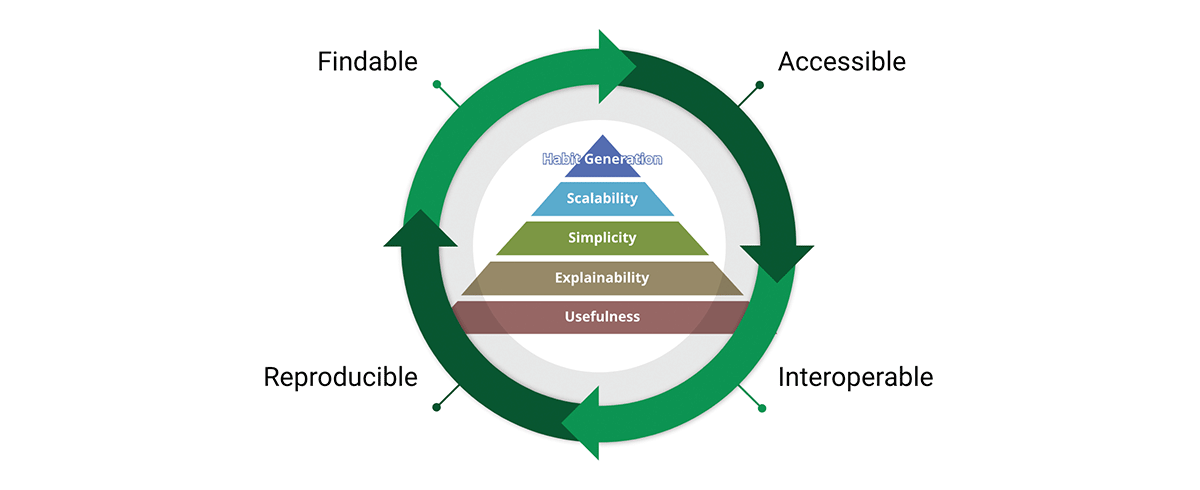{kind=link}
¿Por qué los principios FAIR son importantes para los datos geoespaciales y los productos de datos geoespaciales? FAIR es trascendente a los datos geoespaciales, es en realidad trascendente a los datos, es un sistema simple pero coherente de principios rectores para un buen diseño, y ese buen diseño se puede aplicar a cualquier cosa, incluidos los datos geoespaciales y los sistemas geoespaciales.
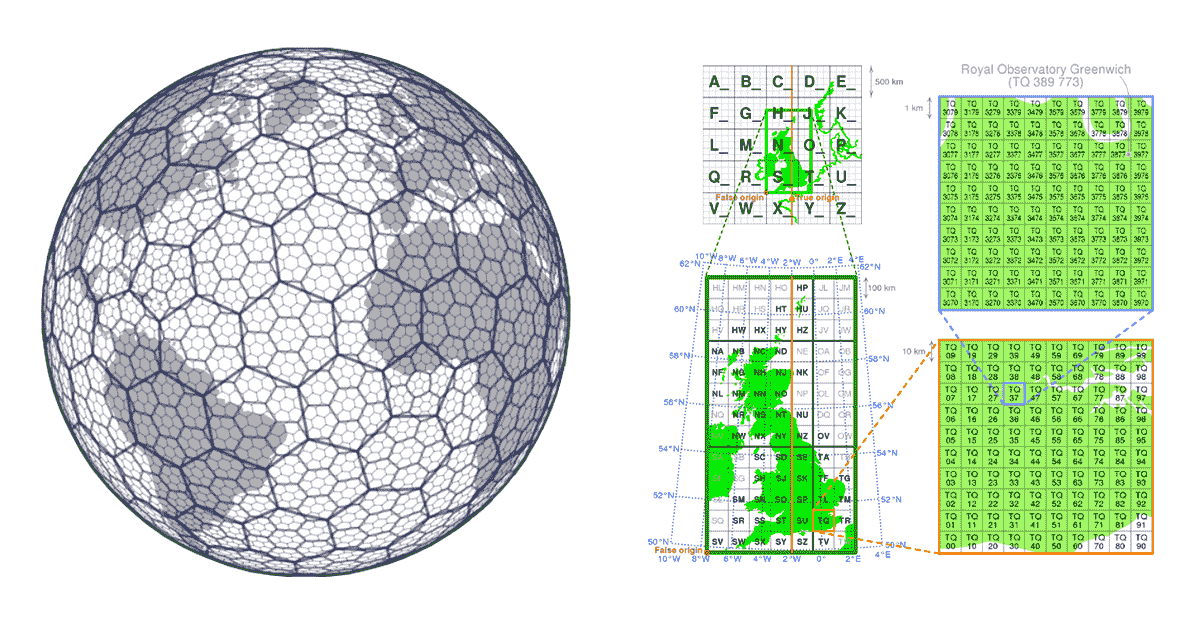
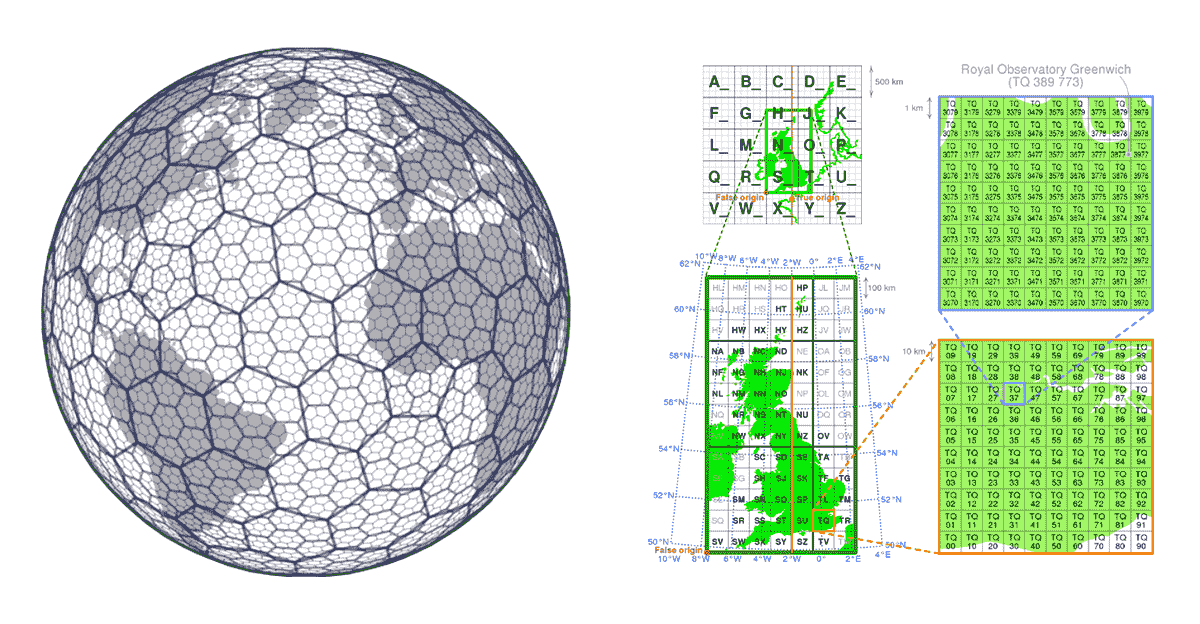
Sistemas de índices de cuadrícula
En las soluciones GIS tradicionales, el rendimiento de las operaciones espaciales se logra generalmente construyendo estructuras de árbol (KD trees, ball trees, Quad trees, etc.). El problema con los enfoques de árbol es que eventualmente rompen el principio de escalabilidad: cuando los datos son demasiado grandes para ser procesados para construir el árbol y el cálculo requerido para construir el árbol es demasiado largo y va en contra del propósito. Esto también afecta negativamente la accesibilidad de los datos; si no podemos construir el árbol, no podemos acceder a todos los datos y, en efecto, no podemos reproducir los resultados. En este caso, los sistemas de índices de cuadrícula proporcionan una solución.
Los sistemas de índices de cuadrícula se construyen desde el principio teniendo en cuenta los aspectos de escalabilidad de los datos geoespaciales. En lugar de construir los árboles, definen una serie de cuadrículas que cubren el área de interés. En el caso de H3 (pionero de Uber), la cuadrícula cubre el área de la Tierra; en el caso de los sistemas de índices de cuadrícula locales (por ejemplo, British National Grid), pueden cubrir solo el área de interés específica. Estas cuadrículas están compuestas por celdas que tienen identificadores únicos. Existe una relación matemática entre la ubicación y la celda en la cuadrícula. Esto hace que los sistemas de índices de cuadrícula sean muy escalables y de naturaleza paralela.
{kind=link}
Otro aspecto importante de los sistemas de índices de cuadrícula es que son de código abierto, lo que permite que los valores de índice sean aprovechados universalmente tanto por los productores como por los consumidores de datos. Los datos se pueden enriquecer con la información del índice de cuadrícula en cualquier etapa de su recorrido por la cadena de suministro de datos. Esto convierte a los sistemas de índices de cuadrícula en un ejemplo de estándares de datos impulsados por la comunidad. Los estándares de datos impulsados por la comunidad, por naturaleza, no requieren imposición, lo que se adhiere completamente al aspecto de generación de hábitos de la pirámide de valor y aborda significativamente los principios de interoperabilidad y accesibilidad de FAIR.
{kind=link}
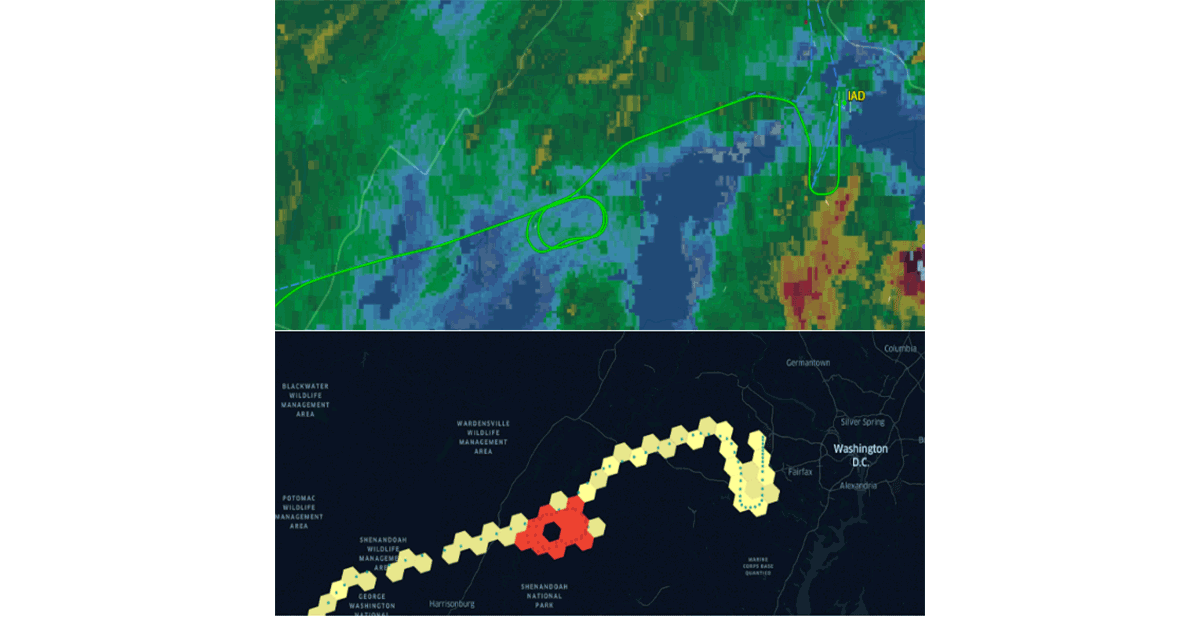
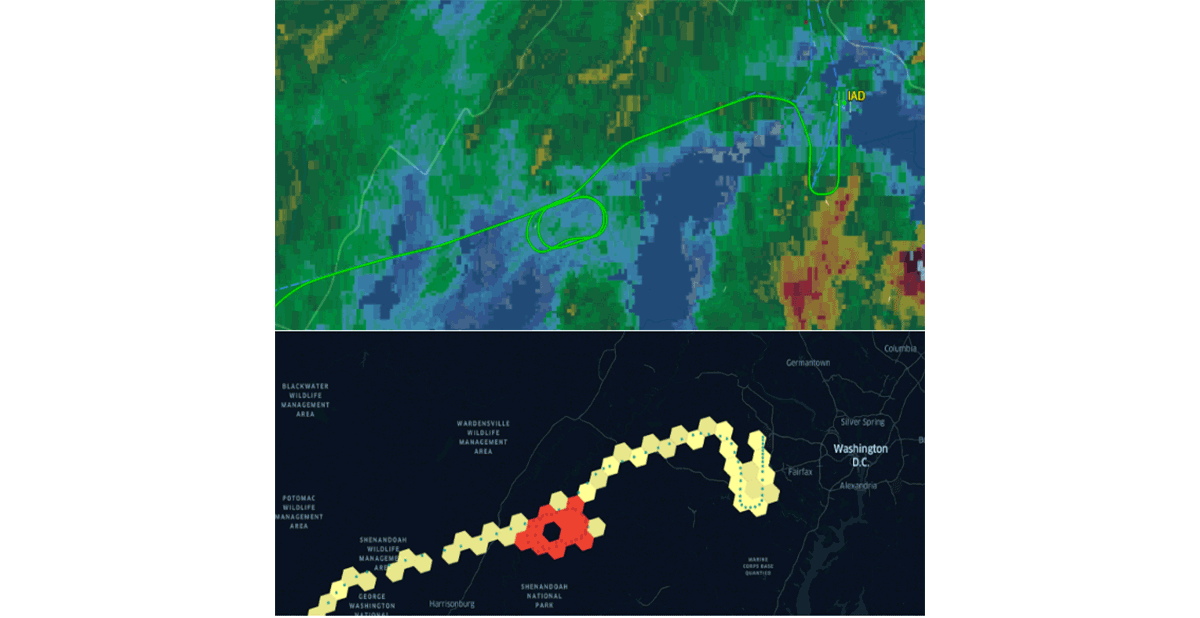
Databricks anunció recientemente soporte nativo para el sistema de índices de cuadrícula H3 siguiendo la misma propuesta de valor. Adoptar estándares comunes de la industria impulsados por la comunidad es la única forma de impulsar adecuadamente la generación de hábitos y la interoperabilidad. Para reforzar esta afirmación, organizaciones como CARTO, ESRI y Google han estado promoviendo el uso de sistemas de índices de cuadrícula para el diseño de sistemas GIS escalables. Además, el proyecto Mosaic de Databricks Labs admite el British National Grid como el sistema de índices de cuadrícula estándar que se usa ampliamente en el gobierno del Reino Unido. Los sistemas de índices de cuadrícula son clave para la escalabilidad del procesamiento de datos geoespaciales y para diseñar adecuadamente soluciones para problemas complejos (por ejemplo, figura 5: patrones de espera de vuelo usando H3).
Diversidad de datos geoespaciales
Los estándares de datos geoespaciales dedican una parte considerable de esfuerzo a la estandarización de formatos de datos, y el formato, para el caso, es una de las consideraciones más importantes cuando se trata de interoperabilidad y reproducibilidad. Además, si la lectura de sus datos es compleja, ¿cómo podemos hablar de simplicidad? Desafortunadamente, los formatos de datos geoespaciales suelen ser complejos, ya que los datos se pueden producir en varios formatos, incluidos formatos de código abierto y específicos del proveedor. Considerando solo datos vectoriales, podemos esperar que los datos lleguen en WKT, WKB, GeoJSON, web CSV, CSV, Shape File, GeoPackage y muchos otros. Por otro lado, si consideramos datos ráster, podemos esperar que los datos lleguen en cualquier número de formatos como GeoTiff, netCDF, GRIB o GeoDatabase; para una lista completa de formatos, consulte este blog.
El dominio de los datos geoespaciales es muy diverso y ha crecido orgánicamente a lo largo de los años en torno a los casos de uso que abordaba. La unificación de un ecosistema tan diverso es un desafío enorme. Un esfuerzo reciente del Open Geospatial Consortium (OGC) para estandarizar a Apache Parquet y su especificación de esquema geoespacial GeoParquet es un paso en la dirección correcta. La simplicidad es uno de los aspectos clave del diseño de un buen producto escalable y robusto: la unificación conduce a la simplicidad y aborda una de las principales fuentes de fricción en el ecosistema: la ingesta de datos. La estandarización a GeoParquet aporta mucho valor que aborda todos los aspectos de los datos FAIR y la pirámide de valor.
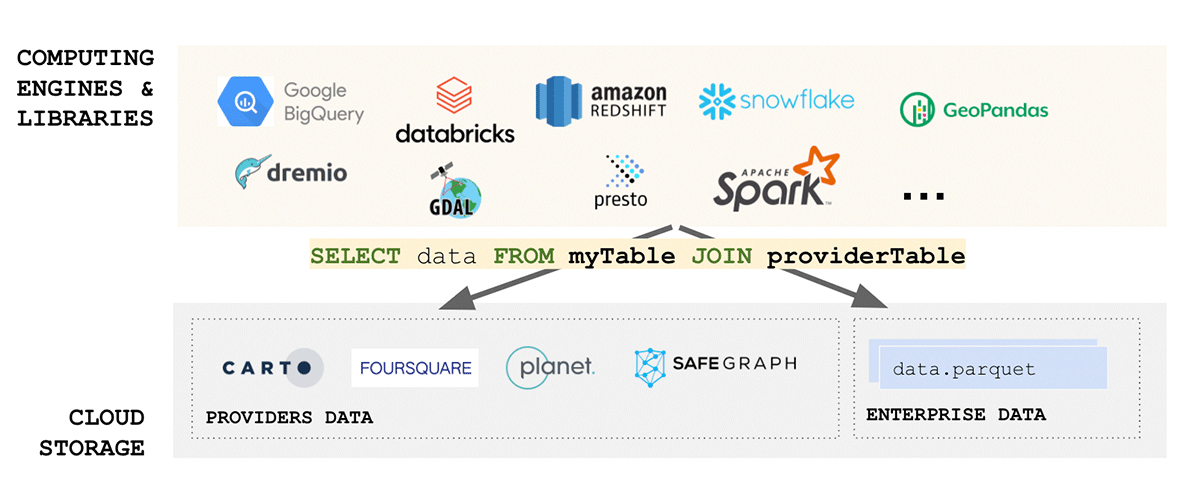
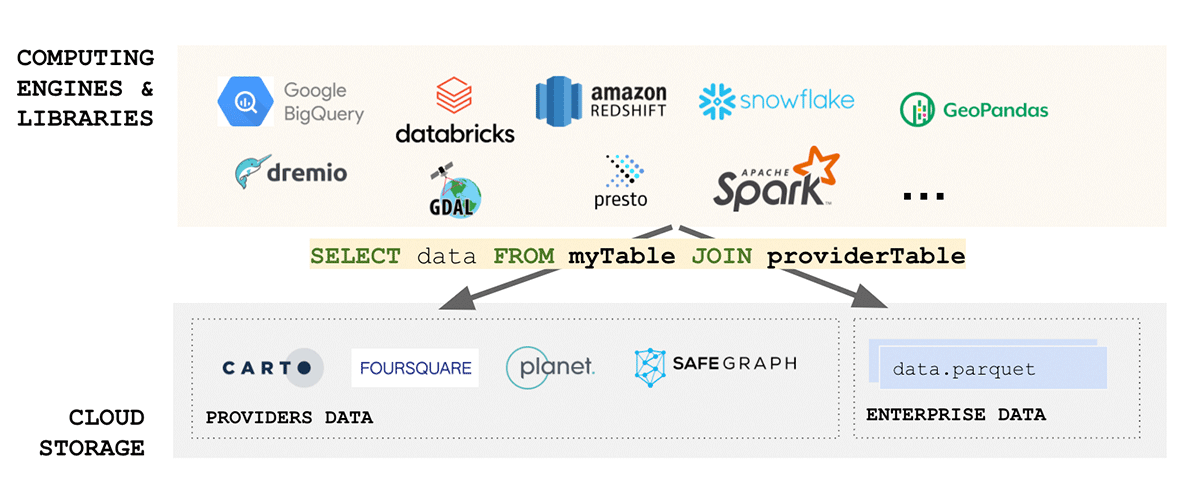{kind=link}
¿Por qué introducir otro formato en un ecosistema ya complejo? GeoParquet no es un formato nuevo: es una especificación de esquema para el formato Apache Parquet, que ya está ampliamente adoptado y utilizado por la industria y la comunidad. Parquet, como formato base, admite columnas binarias y permite el almacenamiento de cargas útiles de datos arbitrarias; al mismo tiempo, el formato admite columnas de datos estructurados que pueden almacenar metadatos junto con la carga útil de datos. Esto lo convierte en una opción que promueve la interoperabilidad y la reproducibilidad. Finalmente, Delta Lake se ha construido sobre parquet y aporta propiedades ACID a la tabla. Las propiedades ACID de un formato son cruciales para la reproducibilidad y para obtener resultados confiables. Además, delta es el formato utilizado por la solución de intercambio de datos escalable Delta Sharing. Delta Sharing permite el intercambio de datos a escala empresarial entre cualquier nube pública que utilice Databricks (hay opciones de bricolaje para la nube privada disponibles utilizando bloques de construcción de código abierto). Delta Sharing abstrae por completo la necesidad de API REST personalizadas para exponer datos a terceros. Cualquier activo de datos almacenado en delta (utilizando el esquema GeoParquet) se convierte automáticamente en un producto de datos que puede exponerse a partes externas de manera controlada y gobernada. Delta Sharing se ha diseñado desde cero teniendo en cuenta las mejores prácticas de seguridad.
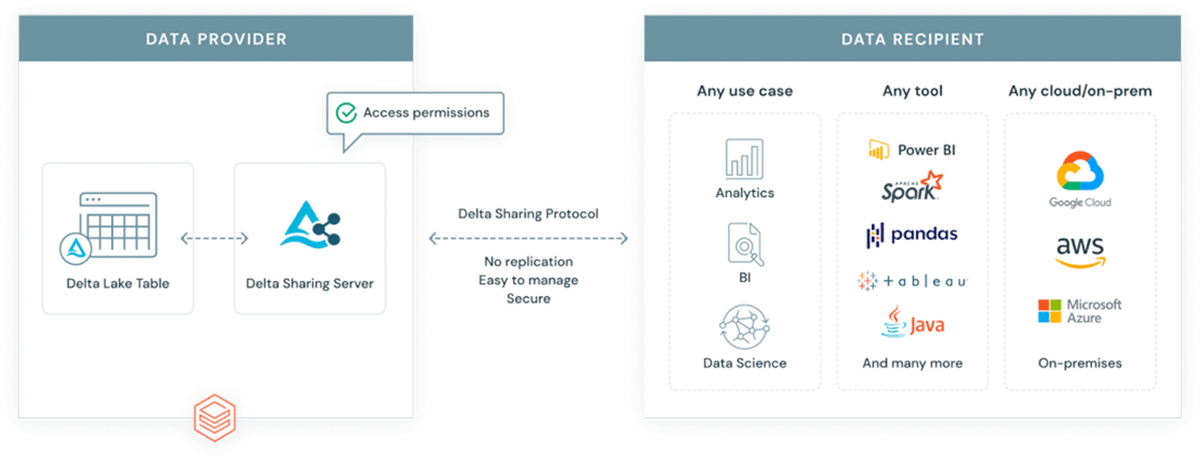
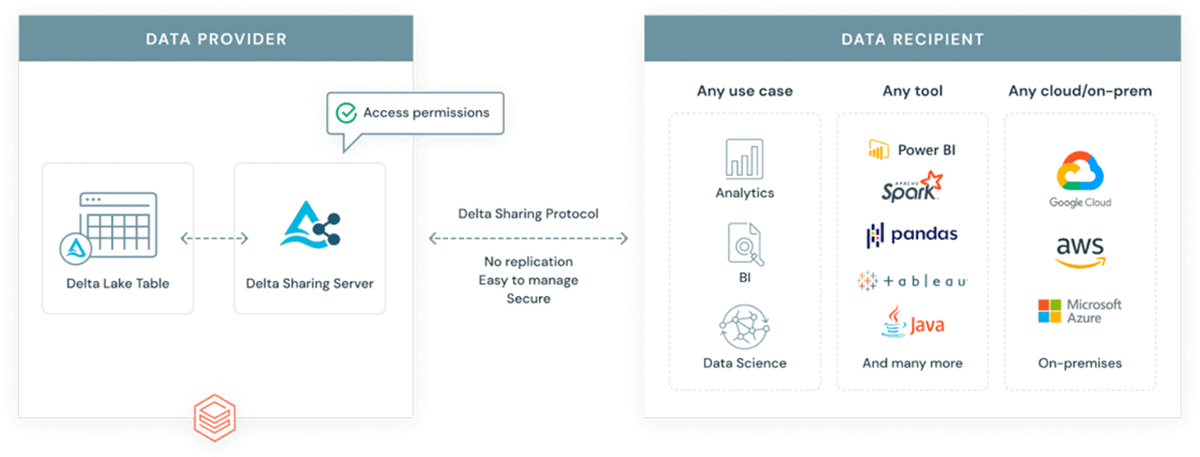{kind=link}
Economía circular de datos
Tomando prestados los conceptos del dominio de la sostenibilidad, podemos definir una economía circular de datos como un sistema en el que los datos se recopilan, comparten y utilizan de manera que se maximice su valor y se minimicen los residuos y los impactos negativos, como el tiempo de cómputo innecesario, las perspectivas poco confiables o las acciones sesgadas basadas en contaminantes de datos. La reutilización es el concepto clave en esta consideración, ¿cómo podemos minimizar el "reinvento de la rueda"? Hay innumerables activos de datos en la naturaleza que representan la misma área, los mismos conceptos con solo ligeras alteraciones para adaptarse mejor a un caso de uso específico. ¿Se debe esto a las optimizaciones reales o al hecho de que era más fácil crear una nueva copia de los activos que reutilizar los existentes? ¿O era demasiado difícil encontrar los activos de datos existentes, o tal vez era demasiado complejo definir los patrones de acceso a los datos?
La duplicación de activos de datos tiene muchos aspectos negativos tanto en las consideraciones FAIR como en las consideraciones de la pirámide de valor de los datos: tener muchos activos de datos similares (pero diferentes) y dispares que representan la misma área y los mismos conceptos puede deteriorar las consideraciones de simplicidad del dominio de datos; se vuelve difícil identificar el activo de datos en el que realmente podemos confiar. También puede tener implicaciones muy negativas para la generación de hábitos: surgirán innumerables comunidades de nicho que se estandarizarán a sí mismas, ignorando las mejores prácticas del ecosistema más amplio, o peor aún, no se estandarizarán en absoluto.
En una economía circular de datos, los datos se tratan como un recurso valioso que se puede utilizar para crear nuevos productos y servicios, así como para mejorar los existentes. Este enfoque fomenta la reutilización y el reciclaje de datos, en lugar de tratarlos como una materia prima desechable. Una vez más, utilizamos la analogía de la sostenibilidad en un sentido literal: argumentamos que esta es la forma correcta de abordar el problema. Los contaminantes de datos son un desafío real para las organizaciones, tanto interna como externamente. Un artículo de The Guardian afirma que menos del 1% de los datos recopilados se analiza realmente. Hay demasiada duplicación de datos, la mayoría de los datos son de difícil acceso y derivar valor real es demasiado engorroso. La economía circular de datos promueve las mejores prácticas y la reutilización de los activos de datos existentes, lo que permite una interpretación y unas perspectivas más coherentes en todo el ecosistema de datos.
{kind=link}
La interoperabilidad es un componente clave de los principios de datos FAIR, y a partir de la interoperabilidad surge la cuestión de la circularidad. ¿Cómo podemos diseñar un ecosistema que maximice la utilización y la reutilización de los datos? Una vez más, FAIR junto con la pirámide de valor tienen las respuestas. La capacidad de encontrar datos es clave para la reutilización de datos y para resolver la contaminación de datos. Con activos de datos que se pueden descubrir fácilmente, podemos evitar la recreación de los mismos activos de datos en múltiples lugares con solo ligeras alteraciones; en cambio, obtenemos un ecosistema de datos coherente con datos que se pueden combinar y reutilizar fácilmente. Databricks anunció recientemente el Databricks Marketplace. La idea detrás del marketplace está en línea con la definición original de producto de datos de DJ Patel. El marketplace admitirá el intercambio de conjuntos de datos, notebooks, paneles y modelos de machine learning. El bloque de construcción crítico para un marketplace de este tipo es el concepto de delta sharing: el canal escalable, flexible y robusto para compartir cualquier dato, incluidos los datos geoespaciales.
Diseñar productos de datos escalables que vivan en el Marketplace es crucial. Para maximizar el valor añadido de cada producto de datos, se deben considerar seriamente los principios FAIR y la pirámide de valor del producto. Sin estos principios rectores, solo aumentaremos los problemas que ya están presentes en los sistemas actuales. Cada producto de datos debe resolver un problema único y debe hacerlo de manera simple, reproducible y robusta.
Puede leer más sobre cómo la Plataforma Databricks Lakehouse puede ayudarle a acelerar el tiempo de obtención de valor de sus productos de datos en el eBook: Un nuevo enfoque para compartir datos.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.