Construcción de una Data Mesh basada en el Lakehouse de Databricks, Parte 2
por Bernhard Walter, Sharon Richardson, Guillermo Schiava D'Albano, Pawarit Laosunthara, Amr Ali y Fran Medina Castro
En el último blog "Databricks Lakehouse y Data Mesh", presentamos el Data Mesh basado en el Databricks Lakehouse. Este blog explorará cómo las capacidades de Databricks Lakehouse soportan el Data Mesh desde un punto de vista arquitectónico.
Data Mesh es un paradigma arquitectónico y organizativo, no una tecnología o solución que se compra. Sin embargo, para implementar un Data Mesh de manera efectiva, necesitas una plataforma flexible que garantice la colaboración entre las personas que trabajan con datos, ofrezca calidad de datos y facilite la interoperabilidad y la productividad en todas las cargas de trabajo de datos e IA.
Veamos cómo las capacidades de la Plataforma Databricks Lakehouse abordan estas necesidades.
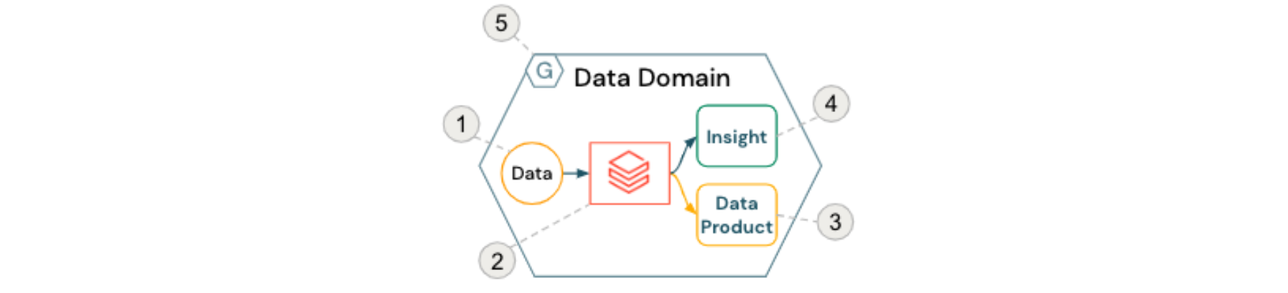
El bloque de construcción básico de un data mesh es el dominio de datos, que generalmente se compone de los siguientes componentes:
- Datos de origen (propiedad del dominio)
- Recursos de cómputo y orquestación autoservicio (dentro de los Databricks Workspaces)
- Productos de datos orientados al dominio servidos a otros equipos y dominios
- Información lista para ser consumida por los usuarios de negocio
- Cumplimiento de las políticas de gobernanza computacional federada
Esto se representa en la siguiente figura:
Para facilitar la colaboración entre dominios y el análisis autoservicio, a menudo se proporcionan centralmente servicios comunes en torno a mecanismos de control de acceso y catalogación de datos. Por ejemplo, Databricks Unity Catalog proporciona no solo capacidades de catalogación informativas como el descubrimiento de datos y el linaje, sino también la aplicación de controles de acceso detallados y auditoría deseados por muchas organizaciones hoy en día.
Data Mesh se puede implementar en una variedad de topologías. Fuera de las empresas nativas digitales modernas, un Data Mesh altamente descentralizado con dominios completamente independientes generalmente no se recomienda, ya que conduce a complejidad y sobrecarga en los equipos de dominio en lugar de permitirles centrarse en la lógica de negocio y datos de alta calidad. Dos ejemplos populares que se ven a menudo en las empresas son el Data Mesh Armonizado y el Data Mesh Hub & Spoke.
1) Enfoque para un Data Mesh armonizado
Un data mesh armonizado enfatiza la autonomía dentro de los dominios:
- Los dominios de datos crean y publican productos de datos específicos del dominio
- El descubrimiento de datos se habilita automáticamente mediante Unity Catalog
- Los productos de datos se consumen de forma peer-to-peer
- La infraestructura del dominio se armoniza a través de
- plantillas de plataforma, asegurando la seguridad y el cumplimiento
- servicios de plataforma autoservicio (automatización de aprovisionamiento de dominios, catalogación de datos, publicación de metadatos, políticas sobre datos y recursos de cómputo)
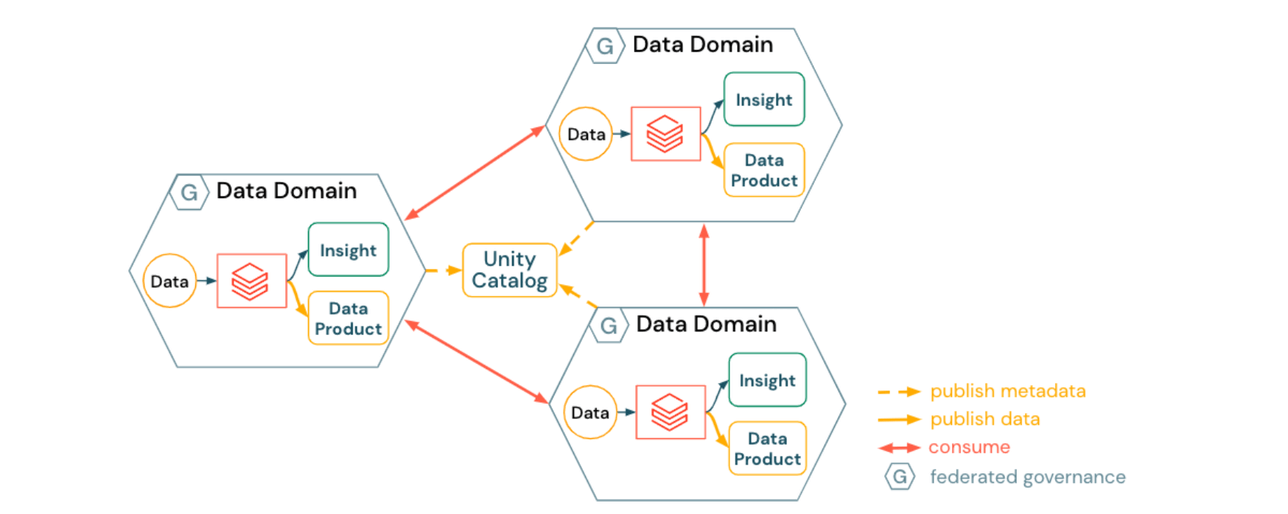
Las implicaciones de un enfoque armonizado pueden incluir:
- Cada Dominio de Datos necesita adherirse a estándares y mejores prácticas para la interoperabilidad y la gestión de la infraestructura
- Cada Dominio de Datos invierte independientemente más tiempo y esfuerzo en temas como controles de acceso, cuentas de almacenamiento subyacentes o incluso infraestructura (por ejemplo, brokers de eventos para productos de datos de streaming)
Este enfoque puede ser desafiante en organizaciones globales donde los diferentes equipos tienen diferente amplitud y profundidad de habilidades y pueden tener dificultades para mantenerse completamente sincronizados con las últimas prácticas y políticas.
2) Enfoque para un Data Mesh Hub & Spoke
Un Data Mesh Hub & Spoke incorpora una ubicación centralizada para gestionar activos de datos compartibles y datos que no pertenecen lógicamente a ningún dominio individual:
- Los dominios de datos (spokes) crean productos de datos específicos del dominio
- Los productos de datos se publican en el data hub, que posee y gestiona la mayoría de los activos registrados en Unity Catalog
- El data hub proporciona servicios genéricos de operaciones de plataforma para dominios de datos, tales como:
- publicación de datos autoservicio en ubicaciones gestionadas
- catalogación de datos, linaje, auditoría y control de acceso a través de Unity Catalog
- servicios de gestión de datos como viajes en el tiempo y procesos de GDPR en todos los dominios (por ejemplo, solicitudes de derecho al olvido)
- El data hub también puede actuar como un dominio de datos. Por ejemplo, pipelines o herramientas para conjuntos de datos genéricos o adquiridos externamente como el clima, investigación de mercado o datos macroeconómicos estándar.
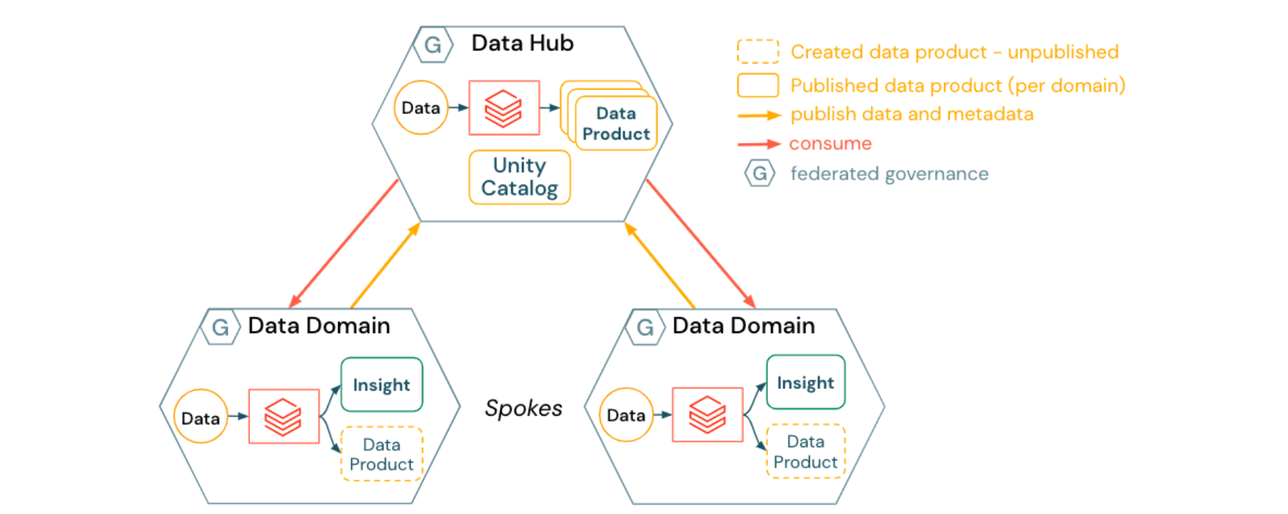
Las implicaciones para un Data Mesh Hub and Spoke incluyen:
- Los dominios de datos pueden beneficiarse de servicios de datos desarrollados y desplegados centralmente, lo que les permite centrarse más en la lógica de negocio y transformación de datos
- La automatización de la infraestructura y el cómputo autoservicio pueden ayudar a evitar que el equipo del data hub se convierta en un cuello de botella para la publicación de productos de datos
En ambos enfoques, los dominios también pueden tener necesidades comunes y repetibles como:
- Herramientas y conectores de ingesta de datos
- Marcos de trabajo, plantillas o mejores prácticas de MLOps
- Pipelines para CI/CD, calidad de datos y monitoreo
Tener un grupo centralizado de habilidades y experiencia, como un centro de excelencia, puede ser beneficioso tanto para actividades repetibles comunes en todos los dominios como para actividades infrecuentes que requieren experiencia especializada que puede no estar disponible en cada dominio.
También es perfectamente factible tener alguna variación entre un data mesh completamente armonizado y un modelo hub-and-spoke. Por ejemplo, tener un data hub global mínimo para alojar solo activos de datos que no se encuentran lógicamente en un solo dominio y para gestionar datos adquiridos externamente que se utilizan en múltiples dominios. Unity Catalog juega un papel fundamental al proporcionar descubrimiento de datos autenticado dondequiera que se gestionen los datos dentro de una implementación de Databricks.
Escalando y evolucionando el Data Mesh
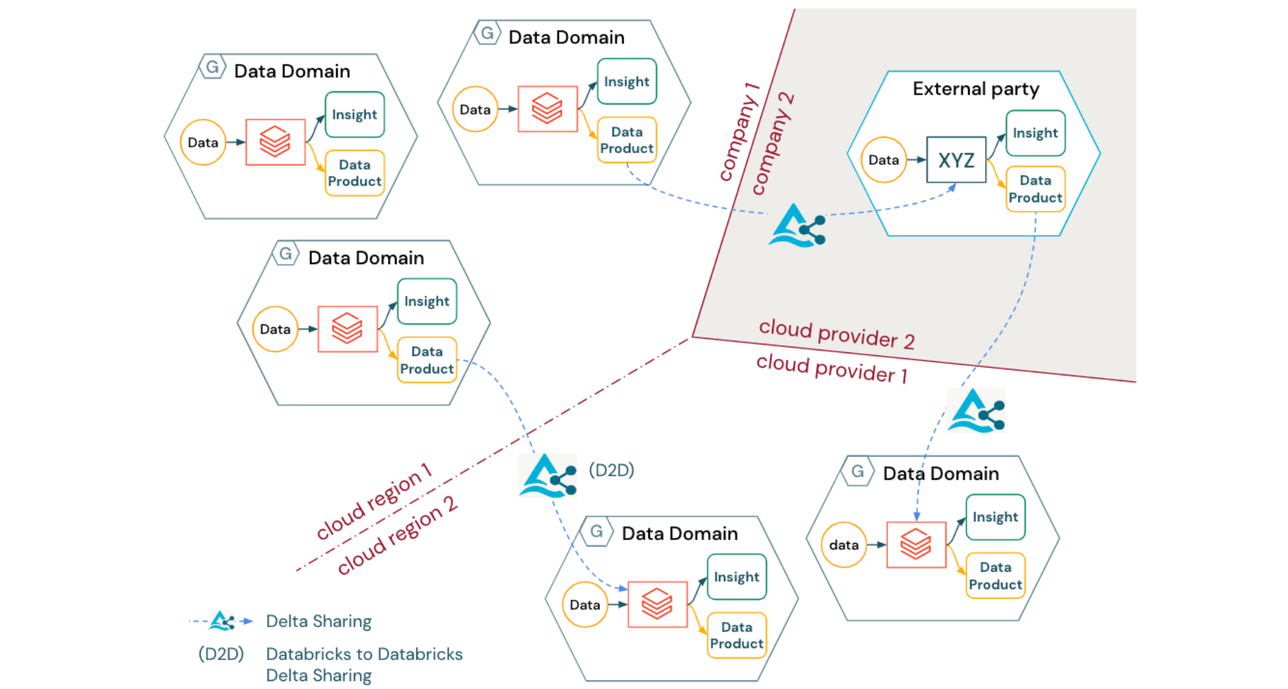
Independientemente del tipo de arquitectura lógica de Data Mesh implementada, muchas organizaciones se enfrentarán al desafío de crear un modelo operativo que abarque regiones en la nube, proveedores de nube e incluso entidades legales. Además, a medida que las organizaciones evolucionan hacia la productización (y potencialmente incluso la monetización) de activos de datos, el intercambio de datos interoperable a nivel empresarial sigue siendo primordial para la colaboración no solo entre dominios internos sino también entre empresas.
Delta Sharing ofrece una solución a este problema con los siguientes beneficios:
- Delta Sharing es un protocolo abierto para compartir de forma segura productos de datos entre dominios a través de límites organizacionales, regionales y técnicos
- El protocolo Delta Sharing es independiente del proveedor (incluyendo un amplio ecosistema de clientes), proporcionando un puente entre diferentes dominios o incluso diferentes empresas sin requerir que utilicen la misma pila tecnológica o proveedor de nube
Comentarios finales
Data Mesh y Lakehouse surgieron debido a puntos débiles y deficiencias comunes de los data warehouses empresariales y los lagos de datos tradicionales[1][2]. Data Mesh articula de manera integral la visión y las necesidades del negocio para mejorar la productividad y el valor de los datos, mientras que Databricks Lakehouse proporciona una base abierta y escalable para satisfacer esas necesidades con la máxima interoperabilidad, rentabilidad y simplicidad.
En este artículo, enfatizamos dos capacidades de ejemplo de la plataforma Databricks Lakehouse que mejoran la colaboración y la productividad al tiempo que respaldan la gobernanza federada, a saber:
- Unity Catalog como habilitador para la publicación de datos independiente, el descubrimiento central de datos y la gobernanza computacional federada en Data Mesh
- Delta Sharing para organizaciones grandes y distribuidas globalmente que tienen implementaciones en múltiples nubes y regiones. Delta Sharing comparte datos frescos y actualizados de manera eficiente y segura entre dominios en diferentes límites organizacionales sin duplicación
Sin embargo, existen una gran cantidad de otras características de Databricks que sirven como excelentes habilitadores en el viaje de Data Mesh para diferentes perfiles. Por ejemplo:
- Workflows y Delta Live Tables para canalizaciones de datos de alta calidad autoservicio que soportan cargas de trabajo tanto por lotes como de streaming
- Databricks SQL que permite consultas BI y SQL de alto rendimiento directamente en el lago, reduciendo la necesidad de que los equipos de dominio mantengan copias/almacenes de datos múltiples para sus productos de datos
- Databricks Feature Store que promueve el intercambio y la reutilización entre equipos de Data Science y Machine Learning
Para obtener más información sobre Lakehouse para Data Mesh:
- Matei Zaharia: Data Mesh y Lakehouse
- Zalando & Thoughtworks: Lakehouse de Datos y Data Mesh—Dos Caras de la Misma Moneda
- Databricks: Meshing About con Databricks
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.