Resumen del 2025: Databricks SQL, más rápido para cada carga de trabajo
Análisis y cargas de trabajo de IA más rápidos, incluso a medida que escalan los datos, la gobernanza y el uso
por Tad Rosenberg, Jeremy Lewallen, Mostafa Mokhtar, Chris Stevens y Ina Felsheim
- En 2025, Databricks SQL ofreció un rendimiento hasta un 40 % más rápido en las cargas de trabajo de producción, con mejoras que se aplican automáticamente.
- Se mejoraron las consultas en BI, ETL, análisis espacial e IA, incluso con datos gobernados y compartidos, y con una mayor concurrencia.
- Todas las mejoras están disponibles hoy en Databricks SQL Serverless, lo que mejora el rendimiento y la rentabilidad de las cargas de trabajo existentes sin necesidad de ajustes ni reescrituras.
Para la mayoría de los equipos de datos, el rendimiento ya no se trata de ajustes únicos. Se trata de que el análisis se vuelva más rápido a medida que los datos, los usuarios y la gobernanza escalan, sin aumentar los costos.
Con Databricks SQL (DBSQL), esa expectativa está integrada en la plataforma. En 2025, el rendimiento promedio en las cargas de trabajo de producción mejoró hasta en un 40 %, sin necesidad de ajustes, reescritura de consultas ni intervención manual.
El panorama general va más allá de un único benchmark. El rendimiento mejoró en toda la plataforma, desde cargas más rápidas de dashboards y pipelines más eficientes hasta consultas que se mantienen responsivas incluso con la gobernanza y los datos compartidos implementados, mientras que el análisis geoespacial y las funciones de IA continúan escalando sin mayor complejidad.
El objetivo sigue siendo simple: acelerar las cargas de trabajo y reducir el costo total de forma predeterminada. Con DBSQL Serverless, las tablas administradas de Unity Catalog y la optimización predictiva, las mejoras se aplican automáticamente en todo su entorno para que las cargas de trabajo existentes se beneficien a medida que el motor evoluciona.
En esta publicación, se desglosan las mejoras de rendimiento logradas en 2025 en el motor de consultas, Unity Catalog, Delta Sharing, el almacenamiento, SQL espacial y las funciones de IA.
Rendimiento rápido de las consultas en todas las cargas de trabajo
Databricks SQL mide el rendimiento utilizando millones de consultas reales de clientes que se ejecutan repetidamente en producción. Al hacer un seguimiento de cómo cambian estas cargas de trabajo con el tiempo, medimos el impacto real de las mejoras y optimizaciones de la plataforma en lugar de pruebas de rendimiento aisladas.
En 2025, Databricks SQL ofreció mejoras de rendimiento consistentes en todos los principales tipos de cargas de trabajo. Estas mejoras se aplican de forma predeterminada a través de optimizaciones a nivel de motor, como Predictive Query Execution y Photon Vectorized Shuffle, sin necesidad de realizar cambios en la configuración.
- Las cargas de trabajo exploratorias obtuvieron las mayores ganancias, ejecutándose en promedio un 40 % más rápido y permitiendo a los analistas y científicos de datos iterar más rápidamente en grandes datasets.
- Inteligencia de negocios Las cargas de trabajo mejoraron aproximadamente un 20 %, lo que dio como resultado dashboards más receptivos y un análisis interactivo más fluido bajo concurrencia.
- Las cargas de trabajo de ETL también se beneficiaron, ejecutándose aproximadamente un 10 % más rápido y acortando los tiempos de ejecución de los pipelines sin retrabajo.
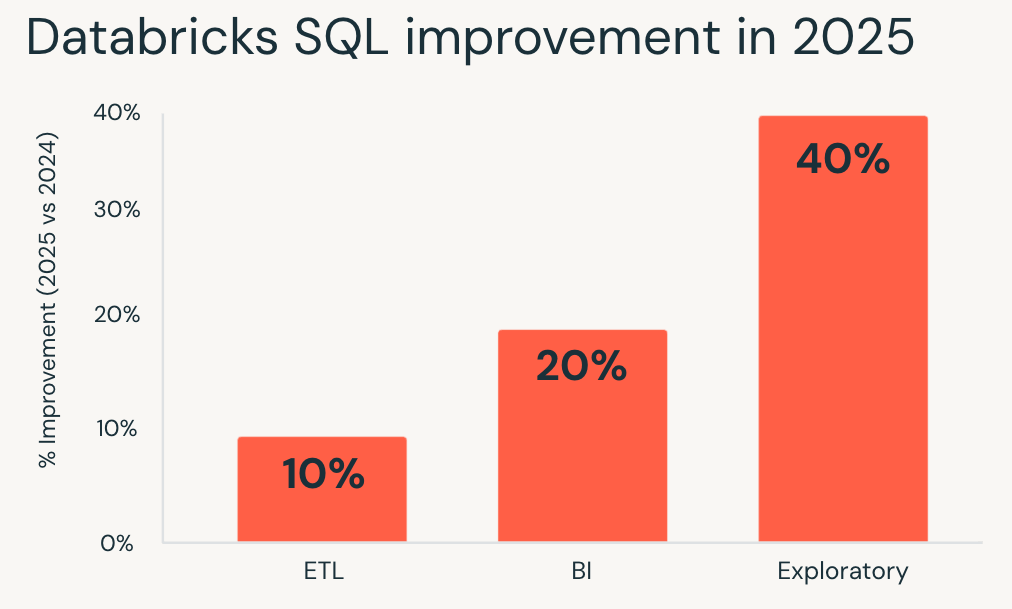
Si evaluó Databricks SQL por última vez hace un año, sus cargas de trabajo existentes ya se ejecutan más rápido hoy.
Analítica que se mantiene rápida a medida que la gobernanza escala con Unity Catalog
A medida que los entornos de datos crecen, la gobernanza a menudo se convierte en una fuente oculta de latencia. Las comprobaciones de permisos, el acceso a metadatos y las búsquedas de linaje pueden ralentizar las consultas, especialmente en entornos interactivos y de alta concurrencia.
En 2025, Unity Catalog redujo significativamente esta sobrecarga. La latencia del catálogo de extremo a extremo mejoró hasta 10 veces, impulsada por optimizaciones en el servicio de catálogo, la pila de red, el cliente de Databricks Runtime y los servicios dependientes.
El resultado es visible donde más importa:
- Los dashboards siguen siendo responsivos incluso con controles de acceso granulares.
- Cargas de trabajo de alta simultaneidad escalan sin cuellos de botella por el acceso a los metadatos.
- Análisis interactivos se sienten más rápidos a medida que los usuarios exploran datos gobernados a escala.
Los equipos ya no tienen que elegir entre una gobernanza sólida y el rendimiento. Con Unity Catalog, el análisis sigue siendo rápido a medida que la gobernanza se expande a más datos y más usuarios.
Delta Sharing, datos compartidos que funcionan como datos nativos
Compartir datos entre equipos u organizaciones tradicionalmente ha tenido un costo. Las consultas en tablas compartidas a menudo se ejecutaban más lentamente y las optimizaciones se aplicaban de manera desigual en comparación con los datos nativos.
En 2025, Databricks SQL cerró esa brecha. Mediante mejoras en la ejecución de consultas y la propagación de estadísticas, las consultas en tablas compartidas a través de Delta Sharing se ejecutaron hasta un 30 % más rápido, lo que alinea el rendimiento de los datos compartidos con el de las tablas nativas.

Este cambio es más importante en los escenarios en los que los datos externos deben comportarse como datos internos. Los mercados de datos, la analítica interorganizacional y los informes impulsados por socios ahora pueden ejecutarse en conjuntos de datos compartidos sin sacrificar la interactividad ni la previsibilidad.
Con Delta Sharing, los equipos pueden compartir datos gobernados de forma amplia y, a la vez, mantener las expectativas de rendimiento para el análisis moderno.
Menor costo de almacenamiento, optimizaciones automáticas incorporadas
A medida que los volúmenes de datos aumentan, la eficiencia del almacenamiento se convierte en una parte más importante del costo total. La compresión desempeña un papel fundamental, pero la elección de formatos y la gestión de migraciones tradicionalmente ha añadido una sobrecarga operativa.
En 2025, Databricks estableció la compresión Zstandard como predeterminada para todas las nuevas tablas administradas de Unity Catalog. Zstandard es un formato de compresión de código abierto que ofrece un ahorro de hasta el 40 % en los costos de almacenamiento en comparación con los formatos más antiguos, sin degradar el rendimiento de las consultas.

Estos beneficios se aplican automáticamente a las tablas nuevas y las tablas existentes también se pueden migrar a Zstandard, con herramientas de migración sencillas que estarán disponibles próximamente. Las tablas de hechos grandes, los datasets de retención a largo plazo y los dominios de rápido crecimiento ven reducciones de costos inmediatas sin cambios en la forma en que se escriben o ejecutan las consultas.
El resultado es un menor costo de almacenamiento por defecto, logrado sin sacrificar el rendimiento ni agregar nuevos pasos de ajuste.
Análisis geoespacial sin sistemas especializados
El análisis geoespacial exige mucho a la ejecución de consultas. Las uniones espaciales, las consultas de rango y los cálculos geométricos requieren un uso intensivo de la computación y, a escala, a menudo requieren sistemas especializados o un ajuste cuidadoso.
En 2025, Databricks SQL mejoró significativamente el rendimiento para estas cargas de trabajo. Las consultas SQL espaciales se ejecutaron hasta 17 veces más rápido, impulsado por optimizaciones a nivel de motor como la indexación de árbol R, las uniones espaciales optimizadas en Photon y la optimización inteligente de uniones de rango.
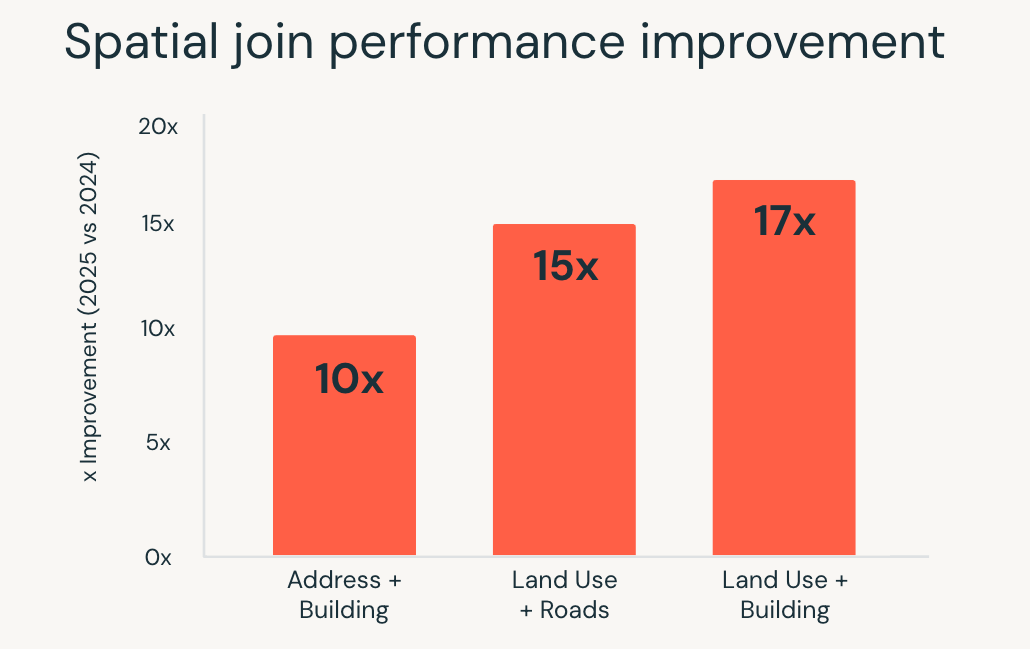
Estas mejoras permiten a los equipos trabajar con datos de ubicación utilizando SQL estándar, mientras que el motor maneja la complejidad de la ejecución automáticamente. Los casos de uso como el análisis de ubicación en tiempo real, el geofencing a gran escala y el enriquecimiento geográfico se ejecutan de forma más rápida y consistente a medida que aumentan los volúmenes de datos.
El análisis espacial ya no requiere herramientas independientes ni optimización manual. Las cargas de trabajo geoespaciales complejas se escalan directamente dentro de Databricks SQL.
Funciones de IA, IA escalable directamente en SQL
La aplicación de la IA a los datos ha requerido tradicionalmente trabajo fuera del almacén de datos. La clasificación de texto, el análisis de documentos y la traducción a menudo implicaban la creación de pipelines separados, la gestión de la infraestructura de los modelos y la reincorporación de los resultados a los flujos de trabajo de análisis.
Las funciones de IA simplifican ese modelo al llevar la IA directamente a SQL. En 2025, Databricks SQL amplió significativamente la escala y el rendimiento de estas capacidades. La nueva infraestructura optimizada para lotes ofreció un rendimiento hasta 85 veces más rápido para funciones como ai_classify, ai_summarize y ai_translate, lo que permite que los trabajos por lotes grandes que antes tardaban horas se completen en minutos.
Databricks también introdujo ai_parse_document y lo optimizó rápidamente para escalar. Los modelos especialmente diseñados para la comprensión de documentos, alojados en Databricks Model Serving, ofrecieron un rendimiento hasta 30 veces más rápido en comparación con las alternativas de uso general, lo que hace que sea práctico procesar grandes volúmenes de contenido no estructurado directamente dentro de los flujos de trabajo de análisis.
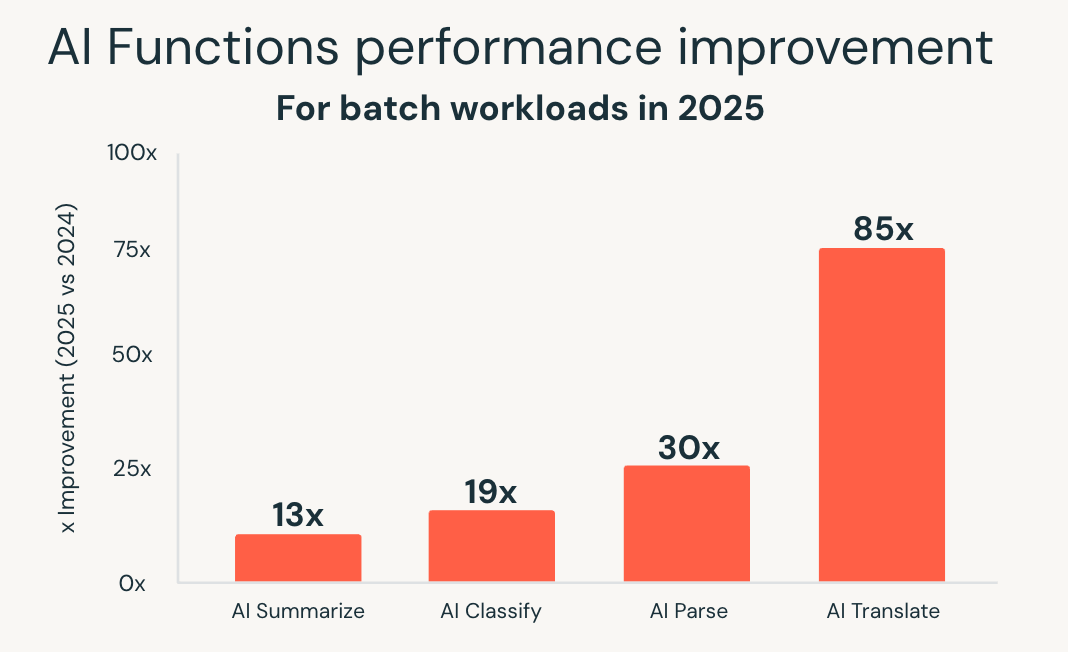
Estas mejoras permiten el procesamiento inteligente de documentos, la extracción de información a partir de datos no estructurados y el análisis predictivo mediante interfaces SQL conocidas. Las cargas de trabajo de IA se escalan junto con las cargas de trabajo de análisis, sin necesidad de sistemas separados o canalizaciones personalizadas.
Con las funciones de IA, Databricks SQL se extiende más allá del análisis hacia cargas de trabajo impulsadas por IA, mientras preserva la simplicidad y las expectativas de rendimiento del warehouse.
Comenzar
Todas estas mejoras ya están disponibles en Databricks SQL Serverless, sin necesidad de activación ni de configuración.
Si no ha probado DBSQL Serverless, cree un warehouse sin servidor y comience a consultar. Las cargas de trabajo existentes se benefician de inmediato, con mejoras de rendimiento y costos aplicadas automáticamente a medida que la plataforma continúa evolucionando.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.