Mejores prácticas para la evaluación de aplicaciones RAG en LLM
Un caso de estudio sobre el bot de documentación de Databricks
Los chatbots son el caso de uso más adoptado para aprovechar las potentes capacidades de chat y razonamiento de los modelos de lenguaje grandes (LLM). La arquitectura de generación aumentada por recuperación (RAG) se está convirtiendo rápidamente en el estándar de la industria para desarrollar chatbots porque combina los beneficios de una base de conocimientos (a través de un almacén de vectores) y los modelos generativos (p. ej., GPT-3.5 y GPT-4) para reducir las alucinaciones, mantener la información actualizada y aprovechar el conocimiento específico del dominio. Sin embargo, evaluar la calidad de las respuestas de los chatbots sigue siendo un problema sin resolver en la actualidad. Sin estándares definidos en la industria, las organizaciones recurren a la calificación humana (etiquetado), lo cual consume mucho tiempo y es difícil de escalar.
Aplicamos la teoría a la práctica para ayudar a formar las mejores prácticas para la evaluación automatizada de LLM, de modo que pueda implementar aplicaciones RAG en producción de forma rápida y con confianza. Este blog representa la primera de una serie de investigaciones que estamos llevando a cabo en Databricks para proporcionar aprendizajes sobre la evaluación de LLM. Toda la investigación de esta publicación fue realizada por Quinn Leng, Ingeniero de Software Sénior en Databricks y creador del Asistente de IA para la Documentación de Databricks.
Desafíos de la autoevaluación en la práctica
Recientemente, la comunidad de LLM ha estado explorando el uso de “LLM como jueces” para la evaluación automatizada, y muchos utilizan LLM potentes como GPT-4 para evaluar los resultados de sus LLM. El artículo de investigación del grupo lmsys explora la viabilidad y los pros y contras de usar varios LLM (GPT-4, ClaudeV1, GPT-3.5) como jueces para tareas de escritura, matemáticas y conocimiento general.
A pesar de toda esta gran investigación, todavía hay muchas preguntas sin respuesta sobre cómo aplicar los jueces de LLM en la práctica:
- Alineación con la calificación humana: Específicamente para un chatbot de preguntas y respuestas de documentos, ¿qué tan bien refleja la calificación de un juez de LLM la preferencia humana real en términos de corrección, legibilidad y exhaustividad de las respuestas?
- Precisión a través de ejemplos: ¿Cuál es la eficacia de proporcionar algunos ejemplos de calificación al juez de LLM y cuánto aumenta la confiabilidad y la reutilización del juez de LLM en diferentes métricas?
- Escalas de calificación adecuadas: ¿Qué escala de calificación se recomienda, ya que los diferentes marcos utilizan distintas escalas de calificación (por ejemplo, AzureML utiliza del 0 al 100, mientras que langchain utiliza escalas binarias)?
- Aplicabilidad en todos los casos de uso: Con la misma métrica de evaluación (p. ej., exactitud), ¿hasta qué punto se puede reutilizar la métrica de evaluación en diferentes casos de uso (p. ej., chat informal, resumen de contenido, generación aumentada por recuperación)?
Aplicación de una autoevaluación eficaz para aplicaciones RAG
Exploramos las opciones posibles para las preguntas descritas anteriormente en el contexto de nuestra propia aplicación de chatbot en Databricks. Creemos que nuestros hallazgos se generalizan y, por lo tanto, pueden ayudar a su equipo a evaluar eficazmente los chatbots basados en RAG a un costo menor y con mayor rapidez:
- El LLM como juez coincide con la calificación humana en más del 80 % de las evaluaciones. Usar LLM como jueces para nuestra evaluación de chatbot basado en documentos fue tan eficaz como los jueces humanos, ya que coincidió con la puntuación exacta en más del 80 % de las evaluaciones y se mantuvo a una distancia de 1 punto en la puntuación (usando una escala de 0 a 3) en más del 95 % de las evaluaciones.
- Ahorre costos utilizando GPT-3.5 con ejemplos. GPT-3.5 se puede utilizar como un juez LLM si proporciona ejemplos para cada puntaje de calificación. Debido al límite del tamaño del contexto, solo es práctico usar una escala de calificación de baja precisión. El uso de GPT-3.5 con ejemplos en lugar de GPT-4 reduce el costo del juez LLM en 10 veces y mejora la velocidad en más de 3 veces.
- Utilice escalas de calificación de baja precisión para facilitar la interpretación. Descubrimos que las puntuaciones de calificación de menor precisión como 0, 1, 2, 3 o incluso binarias (0, 1) pueden conservar en gran medida la precisión en comparación con las escalas de mayor precisión como de 0 a 10.0 o de 0 a 100.0, a la vez que facilitan considerablemente la entrega de rúbricas de calificación tanto a los anotadores humanos como a los jueces de LLM. El uso de una escala de menor precisión también permite la coherencia de las escalas de calificación entre diferentes jueces de LLM (p. ej., entre GPT-4 y claude2).
- Las aplicaciones RAG requieren sus propios benchmarks. Un modelo puede tener un buen rendimiento en un benchmark especializado publicado (p. ej., chat informal, matemáticas o escritura creativa), pero eso no garantiza un buen rendimiento en otras tareas (p. ej., responder preguntas a partir de un contexto dado). Los benchmarks solo deben usarse si el caso de uso coincide, es decir, una aplicación RAG solo debe evaluarse con un benchmark de RAG.
Basándonos en nuestra investigación, recomendamos el siguiente procedimiento al utilizar un juez de LLM:
- Usar una escala de calificación de 1 a 5
- Usar GPT-4 como un juez LLM sin ejemplos para comprender las reglas de calificación
- Cambie su juez LLM a GPT-3.5 con un ejemplo por puntaje
Nuestra metodología para establecer las mejores prácticas
El resto de esta publicación recorrerá la serie de experimentos que realizamos para formular estas mejores prácticas.
Configuración del experimento
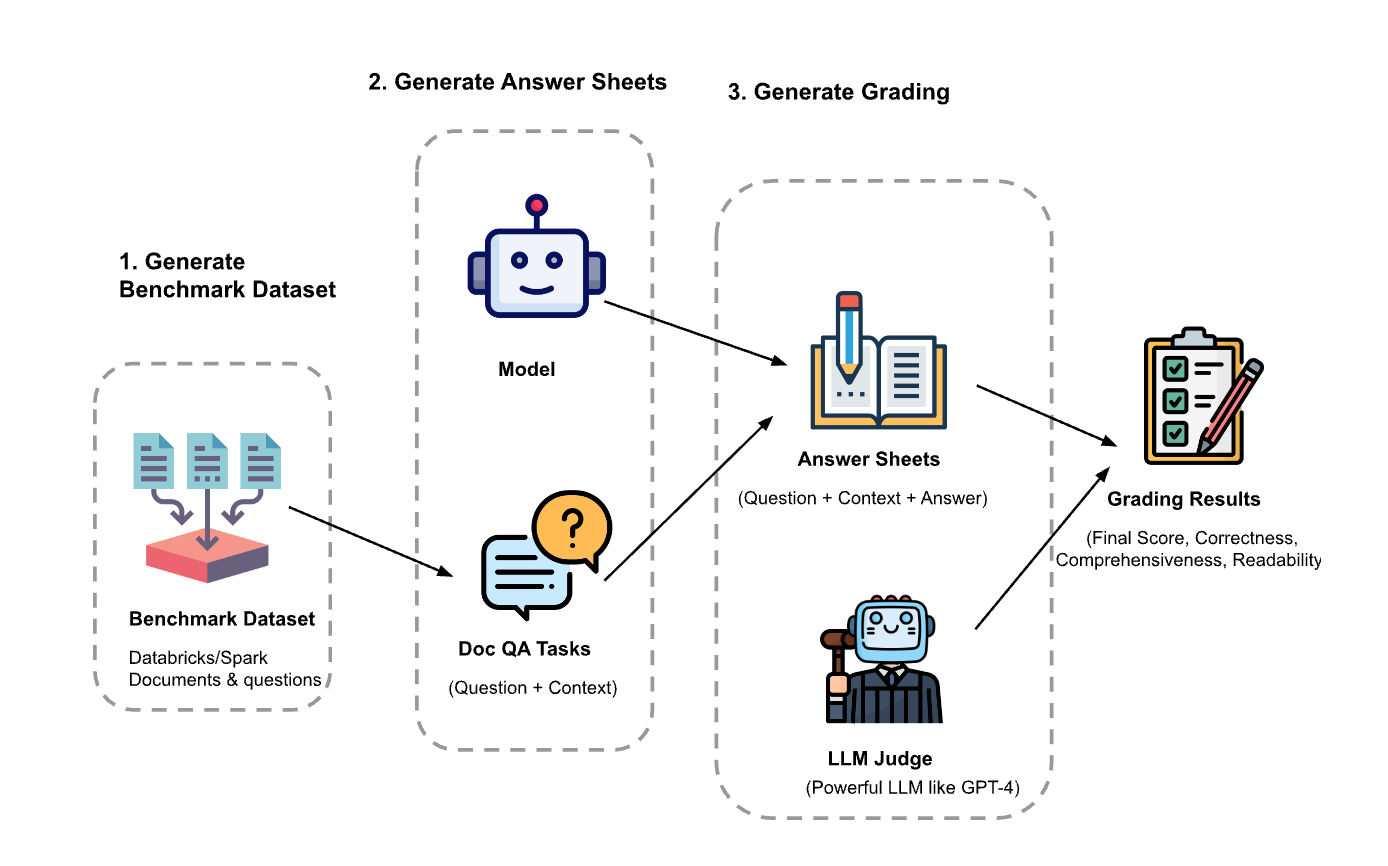
El experimento tuvo tres pasos:
Generar el conjunto de datos de evaluación: Creamos un conjunto de datos a partir de 100 preguntas y contexto de los documentos de Databricks. El contexto representa (fragmentos de) documentos que son relevantes para la pregunta.

- Generar hojas de respuestas: Con el conjunto de datos de evaluación, indicamos a diferentes modelos de lenguaje que generaran respuestas y almacenamos los pares pregunta-contexto-respuesta en un conjunto de datos llamado “hojas de respuestas”. En esta investigación, utilizamos GPT-4, GPT-3.5, Claude-v1, Llama2-70b-chat, Vicuna-33b y mpt-30b-chat.
- Generar calificaciones: dadas las hojas de respuestas, usamos varios LLM para generar las calificaciones y su respectivo razonamiento. Las calificaciones son una puntuación compuesta de Exactitud (ponderación: 60 %), Exhaustividad (ponderación: 20 %) y Legibilidad (ponderación: 20 %). Elegimos este esquema de ponderación para reflejar nuestra preferencia por la Exactitud en las respuestas generadas. Otras aplicaciones pueden ajustar estos pesos de manera diferente, pero esperamos que la corrección siga siendo un factor dominante.
Además, se utilizaron las siguientes técnicas para evitar el sesgo posicional y mejorar la fiabilidad:
- Temperatura baja (temperatura 0.1) para garantizar la reproducibilidad.
- Calificación de respuesta única en lugar de comparación por pares.
- Cadena de pensamientos para permitir que el LLM razone sobre el proceso de calificación antes de dar la puntuación final.
- Generación con pocos ejemplos (few-shots), en la que se le proporcionan al LLM varios ejemplos en la rúbrica de calificación para cada valor de puntuación en cada factor (Exactitud, Exhaustividad, Legibilidad).
Experimento 1: Alineación con la calificación humana
Para confirmar el nivel de coincidencia entre los anotadores humanos y los LLM jueces, enviamos las hojas de respuestas (escala de calificación de 0 a 3) de gpt-3.5-turbo y vicuna-33b a una empresa de etiquetado para recopilar etiquetas humanas y, luego, comparamos el resultado con la calificación de GPT-4. A continuación, se presentan los hallazgos:
Los jueces humanos y de GPT-4 pueden alcanzar un acuerdo superior al 80 % en la puntuación de corrección y legibilidad. Y si reducimos el requisito a una diferencia de puntuación menor o igual a 1, el nivel de acuerdo puede superar el 95 %.
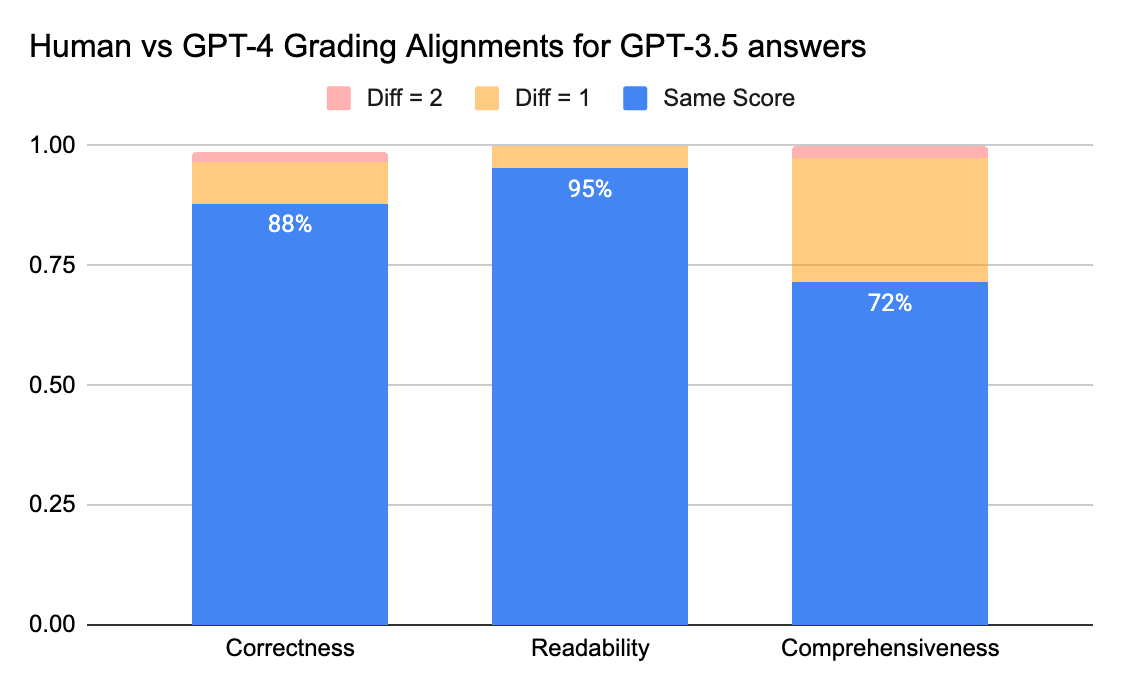
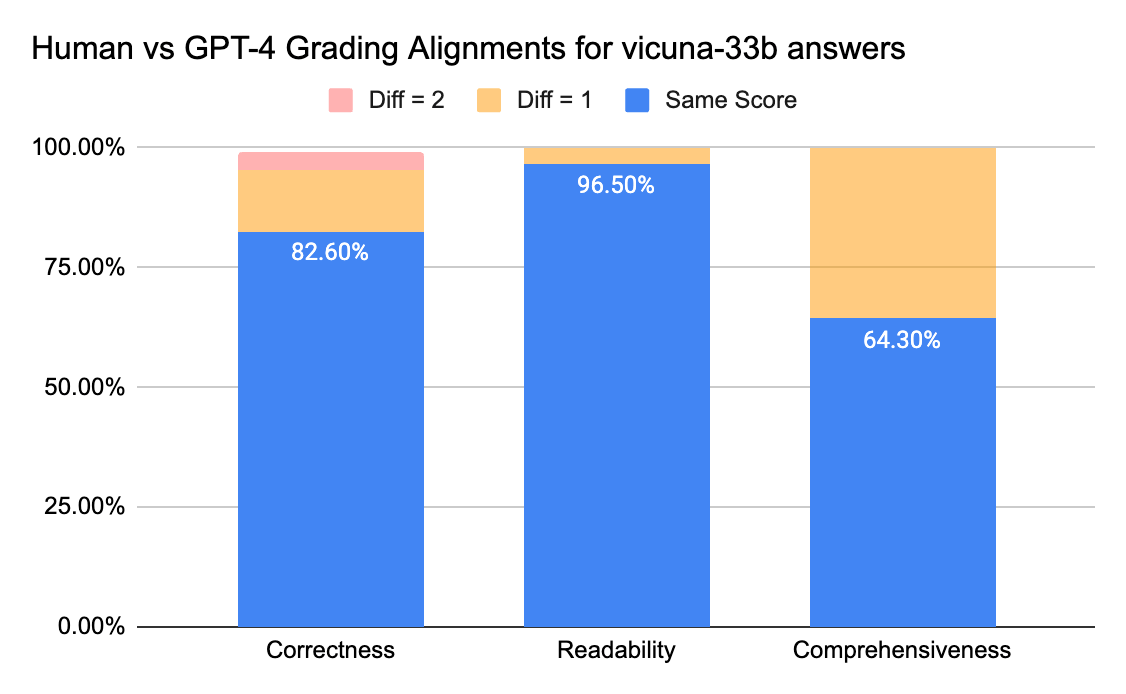
La métrica de Exhaustividad tiene menos alineación, lo que coincide con lo que hemos escuchado de las partes interesadas del negocio, quienes compartieron que “exhaustivo” parece más subjetivo que métricas como Exactitud o Legibilidad.
Experimento 2: Exactitud a través de ejemplos
El artículo de lmsys usa este prompt para instruir al juez de LLM para que evalúe en función de la utilidad, la relevancia, la precisión, la profundidad, la creatividad y el nivel de detalle de la respuesta. Sin embargo, el artículo no comparte detalles específicos sobre la rúbrica de calificación. De nuestra investigación, descubrimos que muchos factores pueden afectar significativamente la puntuación final, por ejemplo:
- La importancia de diferentes factores: Utilidad, Relevancia, Exactitud, Profundidad, Creatividad
- La interpretación de factores como la utilidad es ambigua
- Si diferentes factores entran en conflicto, donde una respuesta es útil pero no es precisa
Desarrollamos una rúbrica para instruir a un juez de LLM para una escala de calificación determinada, probando lo siguiente:
- Prompt original: A continuación se muestra el prompt original utilizado en el artículo de lmsys:
|
Adaptamos el prompt original del artículo de lmsys para emitir nuestras métricas sobre corrección, exhaustividad y legibilidad, y también para indicarle al juez que proporcione una justificación de una línea antes de dar cada puntaje (para beneficiarse del razonamiento de cadena de pensamiento). A continuación se presentan la versión zero-shot del prompt, que no proporciona ningún ejemplo, y la versión few-shot del prompt, que proporciona un ejemplo para cada puntaje. Luego, utilizamos las mismas hojas de respuestas como entrada y comparamos los resultados calificados de los dos tipos de indicaciones.
- Aprendizaje zero-shot: requerir que el juez de LLM emita nuestras métricas sobre corrección, exhaustividad y legibilidad, y también indicarle al juez que proporcione una justificación de una línea para cada puntuación.
- Aprendizaje few-shot: Adaptamos el prompt zero-shot para proporcionar ejemplos explícitos para cada puntaje en la escala. El nuevo prompt:
De este experimento, aprendimos varias cosas:
- Usar el prompt de pocos ejemplos con GPT-4 no marcó una diferencia obvia en la consistencia de los resultados. Cuando incluimos la rúbrica de calificación detallada con ejemplos, no vimos una mejora notable en los resultados de calificación de GPT-4 en los diferentes modelos de LLM. Curiosamente, causó una ligera variación en el rango de las puntuaciones.
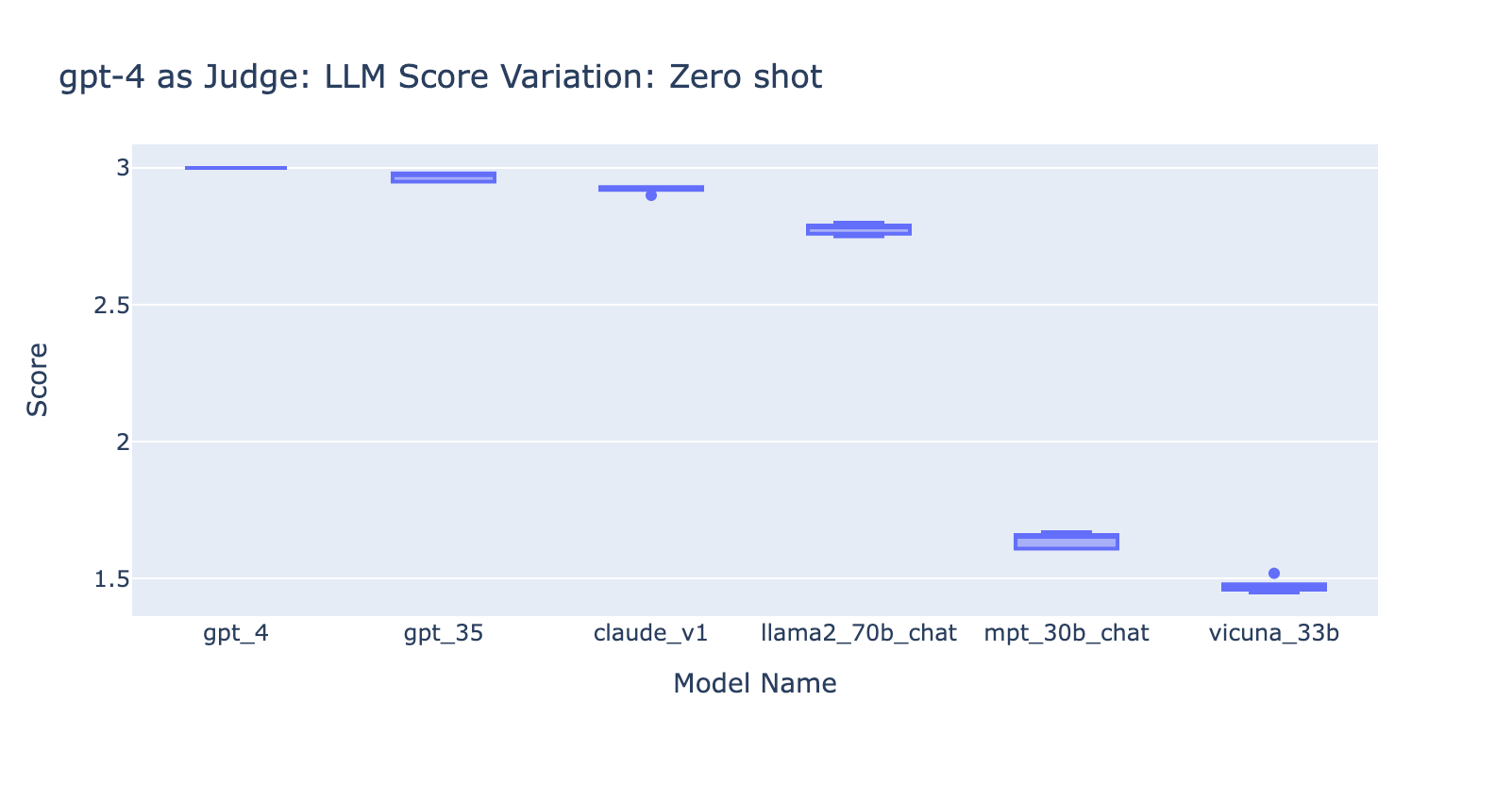
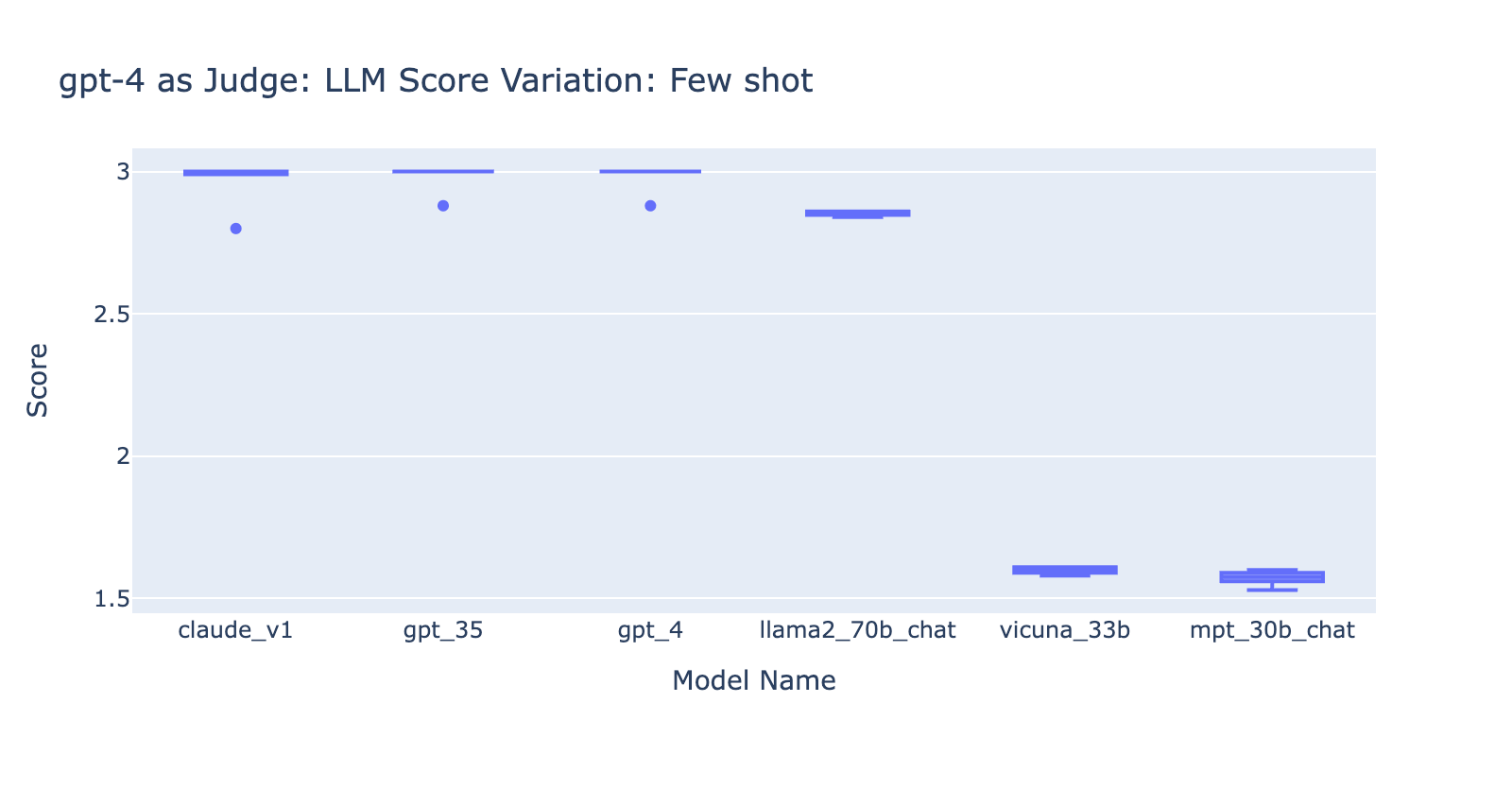
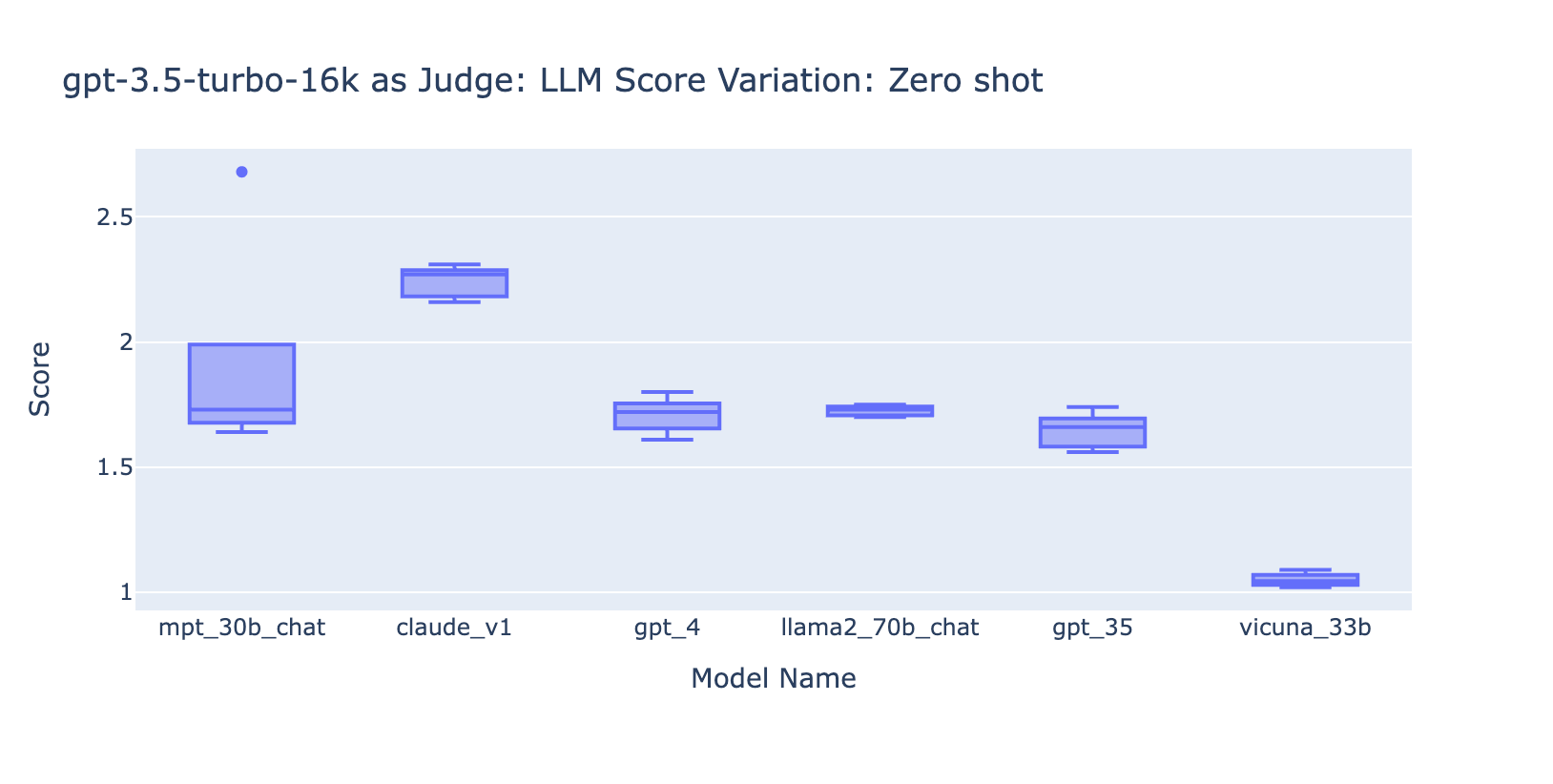
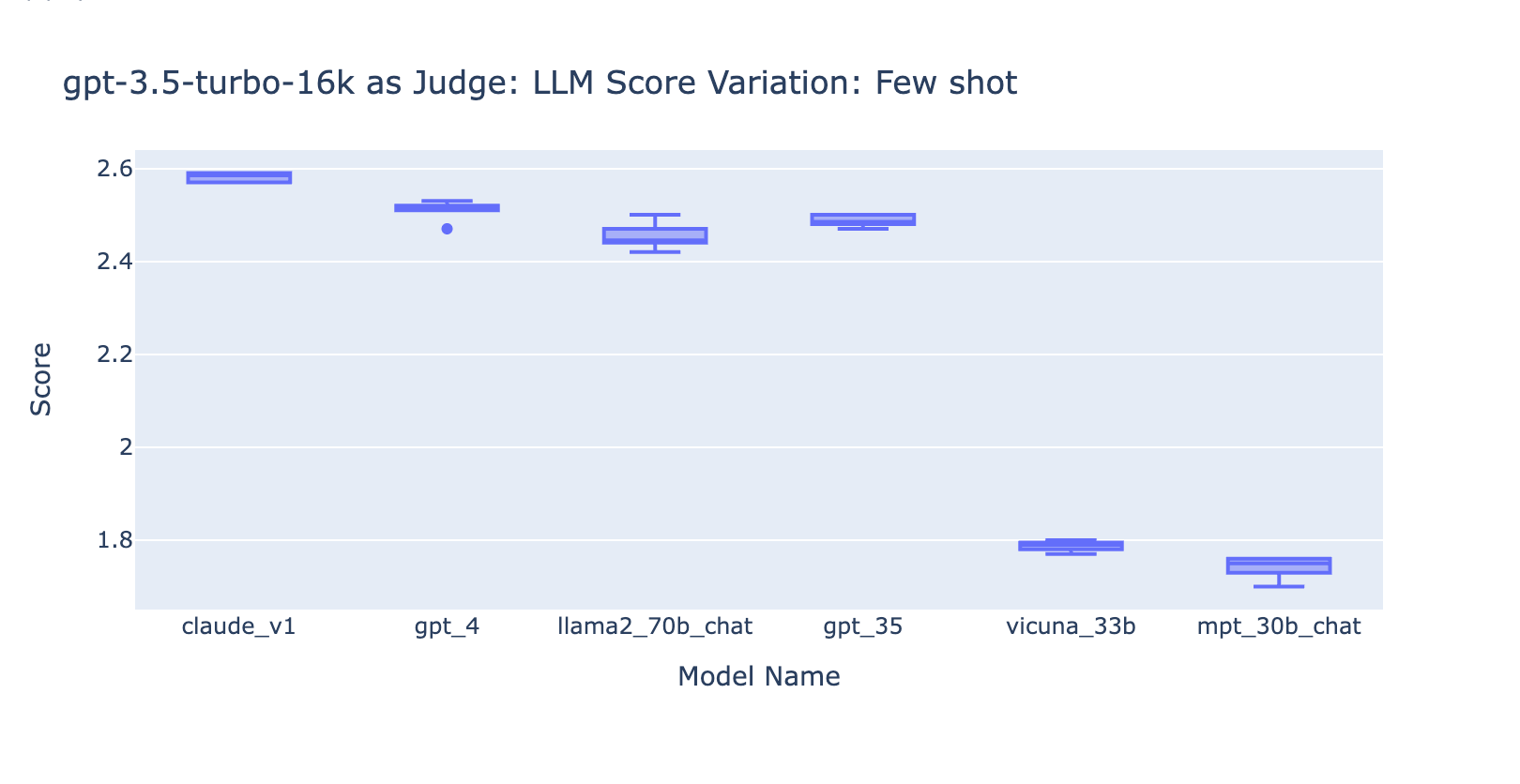
- Incluir algunos ejemplos para GPT-3.5-turbo-16k mejora significativamente la consistencia de las puntuaciones y hace que el resultado sea utilizable. Incluir una rúbrica de calificación/ejemplos detallados tiene una mejora muy obvia en el resultado de la calificación de GPT-3.5 (gráfico de la derecha). Aunque el valor real de la puntuación promedio es ligeramente diferente entre GPT-4 y GPT-3.5 (puntuación 3.0 frente a puntuación 2.6), la clasificación y la precisión se mantienen bastante consistentes.
- Por el contrario, (captura de pantalla a la izquierda) usar GPT-3.5 sin una rúbrica de calificación obtiene resultados muy inconsistentes y es completamente inutilizable
- Tenga en cuenta que estamos usando GPT-3.5-turbo-16k en lugar de GPT-3.5-turbo ya que el prompt puede tener más de 4k tokens.
Experimento 3: Escalas de calificación apropiadas
El artículo sobre LLM como juez usa una escala no entera de 0 a 10 (es decir, de punto flotante) para la escala de calificación; en otras palabras, utiliza una rúbrica de alta precisión para la puntuación final. Descubrimos que estas escalas de alta precisión causan problemas en etapas posteriores con lo siguiente:
- Consistencia: Los evaluadores (tanto humanos como LLM) tuvieron dificultades para mantener el mismo estándar para el mismo puntaje al calificar con alta precisión. Como resultado, descubrimos que los puntajes de salida son menos consistentes entre los jueces si se pasa de escalas de baja precisión a escalas de alta precisión.
- Explicabilidad: Además, si queremos validar de forma cruzada los resultados evaluados por el LLM con los resultados evaluados por humanos, debemos proporcionar instrucciones sobre cómo calificar las respuestas. Es muy difícil proporcionar instrucciones precisas para cada “puntaje” en una escala de calificación de alta precisión; por ejemplo, ¿cuál es un buen ejemplo para una respuesta que tiene un puntaje de 5.1 en comparación con 5.6?
Experimentamos con varias escalas de calificación de baja precisión para proporcionar orientación sobre la “mejor” para usar, finalmente recomendamos una escala de enteros de 0-3 o 0-4 (si desea ceñirse a la escala de Likert). Probamos 0-10, 1-5, 0-3 y 0-1 y aprendimos:
- La calificación binaria funciona para métricas simples como “usabilidad” o “bueno/malo”.
- En escalas como 0-10 es difícil establecer criterios de distinción entre todas las puntuaciones.
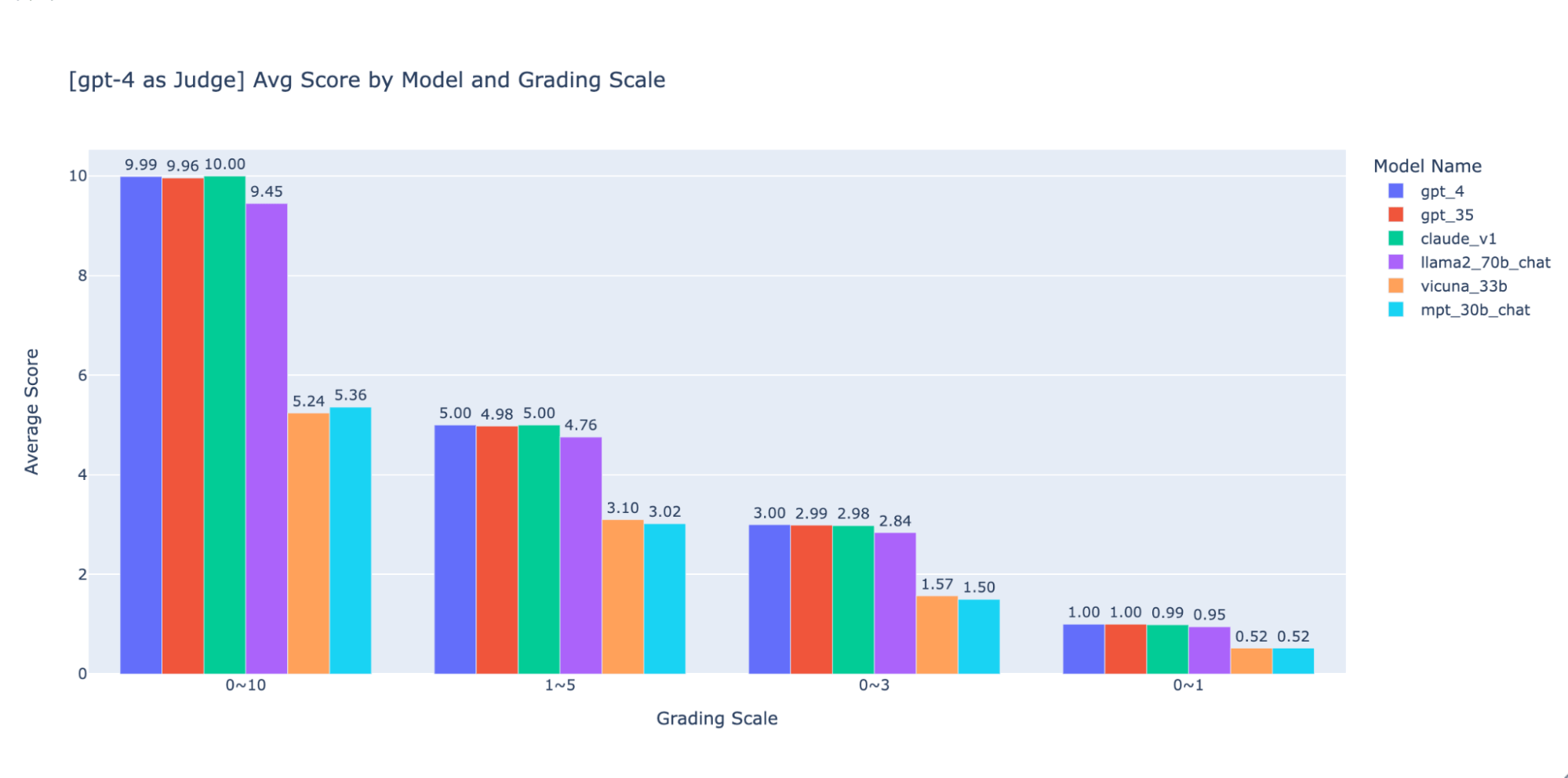
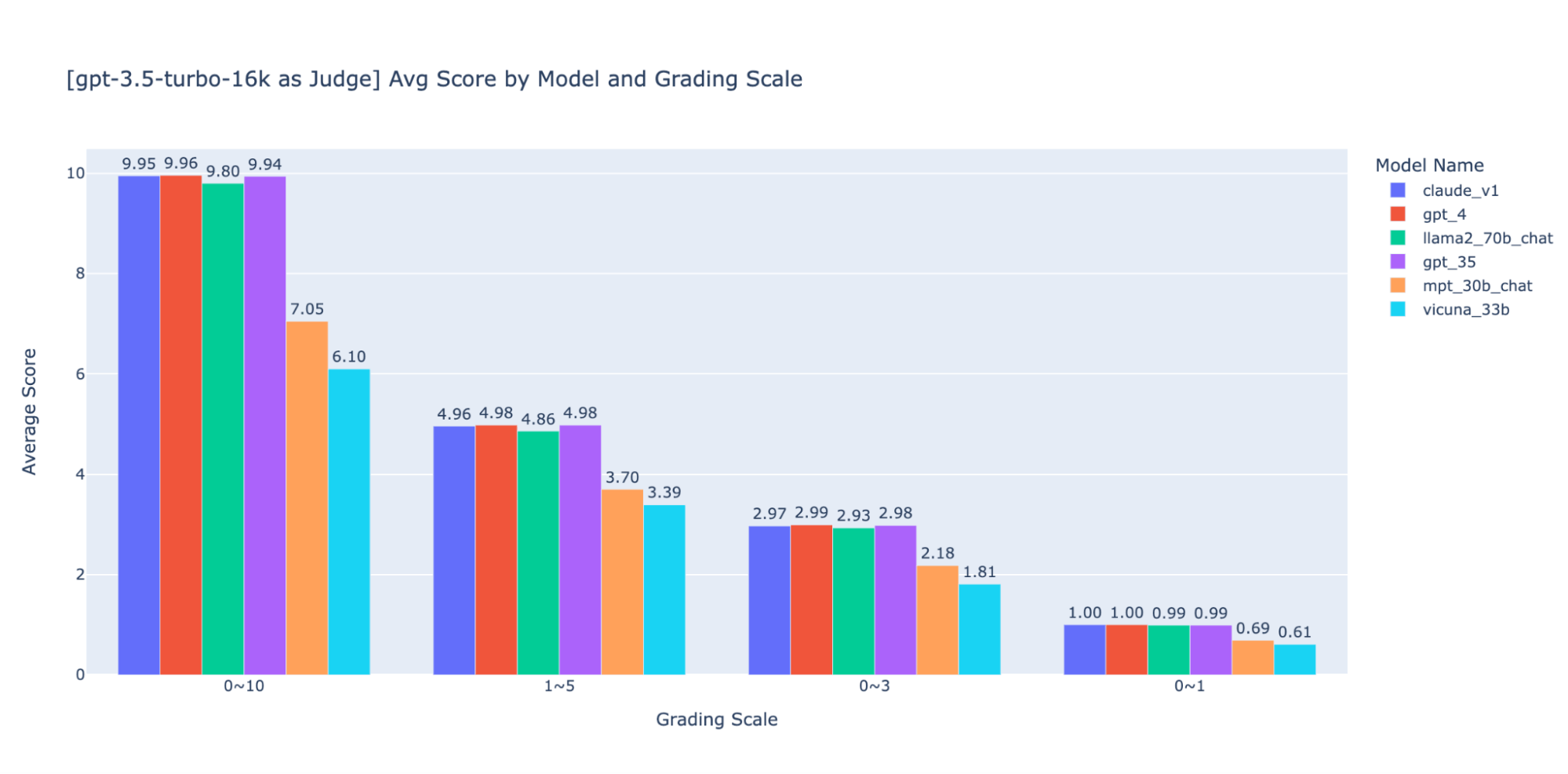
Como se muestra en los gráficos anteriores, tanto GPT-4 como GPT-3.5 pueden mantener una clasificación coherente de los resultados utilizando diferentes escalas de calificación de baja precisión; por lo tanto, el uso de una escala de calificación más baja como 0~3 o 1~5 puede equilibrar la precisión con la explicabilidad).
Por lo tanto, recomendamos 0-3 o 1-5 como escala de calificación para que sea más fácil alinearla con las etiquetas humanas, razonar sobre los criterios de puntuación y proporcionar ejemplos para cada puntaje en el rango.
Experimento 4: Aplicabilidad en todos los casos de uso
El artículo LLM-as-judge muestra que tanto el juicio del LLM como el humano clasifican el modelo Vicuna-13B como un competidor cercano a GPT-3.5:
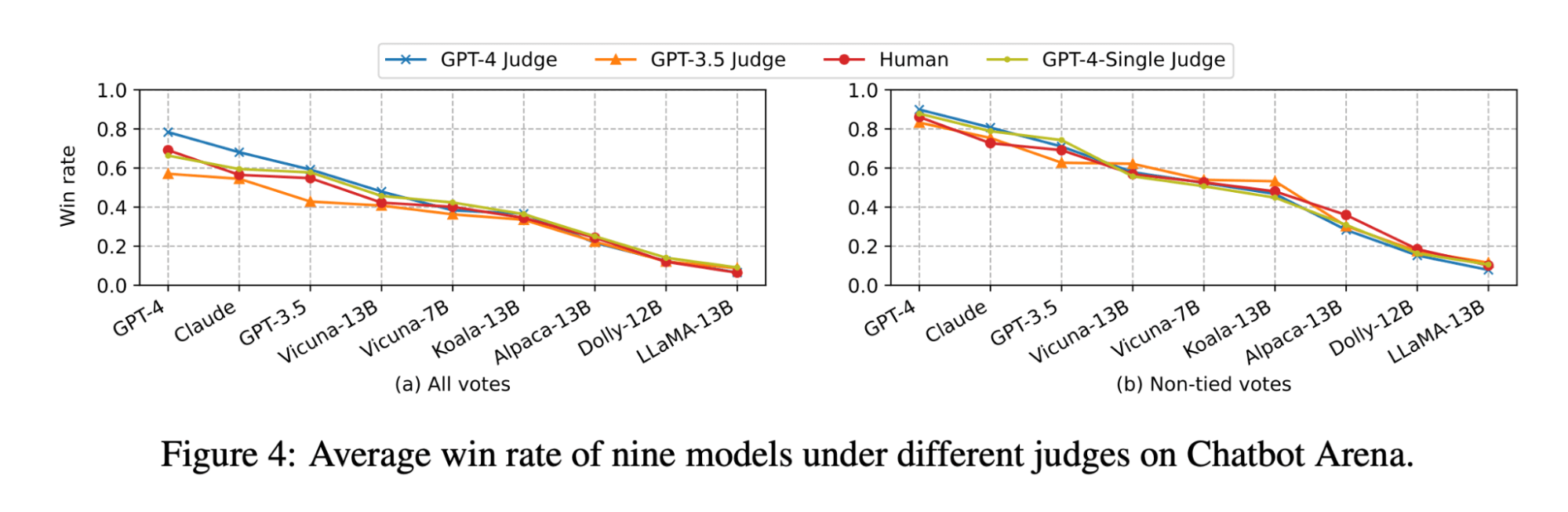
(La figura proviene de la Figura 4 del documento LLM-as-judge: https://arxiv.org/pdf/2306.05685.pdf )
Sin embargo, cuando comparamos el conjunto de modelos para nuestros casos de uso de preguntas y respuestas (Q&A) sobre documentos, descubrimos que incluso el modelo Vicuna-33B, mucho más grande, tiene un rendimiento notablemente peor que GPT-3.5 al responder preguntas basadas en el contexto. Estos hallazgos también son verificados por GPT-4, GPT-3.5 y jueces humanos (como se mencionó en el Experimento 1), los cuales coinciden en que Vicuna-33B tiene un rendimiento peor que GPT-3.5.
Analizamos más de cerca el conjunto de datos de benchmark propuesto por el artículo y descubrimos que las 3 categorías de tareas (escritura, matemáticas, conocimiento) no reflejan ni contribuyen directamente a la capacidad del modelo para sintetizar una respuesta basada en un contexto. En cambio, intuitivamente, los casos de uso de preguntas y respuestas (Q&A) de documentos necesitan benchmarks sobre comprensión de lectura y seguimiento de instrucciones. Por lo tanto, los resultados de la evaluación no se pueden transferir entre casos de uso y necesitamos crear benchmarks específicos para cada caso de uso para evaluar adecuadamente qué tan bien un modelo puede satisfacer las necesidades del cliente.
Use MLflow para aprovechar nuestras mejores prácticas
Con los experimentos anteriores, exploramos cómo diferentes factores pueden afectar significativamente la evaluación de un chatbot y confirmamos que un LLM como juez puede reflejar en gran medida las preferencias humanas para el caso de uso de preguntas y respuestas de documentos. En Databricks, estamos desarrollando la API de evaluación de MLflow para ayudar a su equipo a evaluar eficazmente sus aplicaciones de LLM en función de estos hallazgos. MLflow 2.4 introdujo la API de evaluación para LLM para comparar la salida de texto de varios modelos en paralelo, MLflow 2.6 introdujo métricas basadas en LLM para la evaluación como la toxicidad y la perplejidad, ¡y estamos trabajando para dar soporte a LLM-como-juez en un futuro próximo!
Mientras tanto, recopilamos la lista de recursos a los que hicimos referencia en nuestra investigación a continuación:
- Repositorio Doc_qa
- El código y los datos que usamos para realizar los experimentos
- Artículo de investigación sobre LLM como juez del grupo lmsys
- El artículo es la primera investigación sobre el uso de LLM como juez para los casos de uso de chat informal, exploró ampliamente la viabilidad y los pros y contras de usar LLM (GPT-4, ClaudeV1, GPT-3.5) como juez para tareas de escritura, matemáticas y conocimiento del mundo.
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.