Razonamiento Agéntico en la Práctica: Dando Sentido a Datos Estructurados y No Estructurados
Los datos empresariales rara vez son útiles de forma aislada. Responder a preguntas como: "¿Cuáles de nuestros productos han tenido una disminución en las ventas durante los últimos tres meses y qué problemas potencialmente relacionados se mencionan en las reseñas de los clientes en varios sitios de vendedores?" requiere razonar a través de una combinación de fuentes de datos estructuradas y no estructuradas, incluyendo lagos de datos, datos de reseñas y sistemas de gestión de información de productos. En esta entrada de blog, demostramos cómo el Databricks Agent Bricks Supervisor Agent (SA) puede ayudar con estas tareas complejas y realistas a través de razonamiento multi-paso basado en una combinación de datos estructurados y no estructurados.
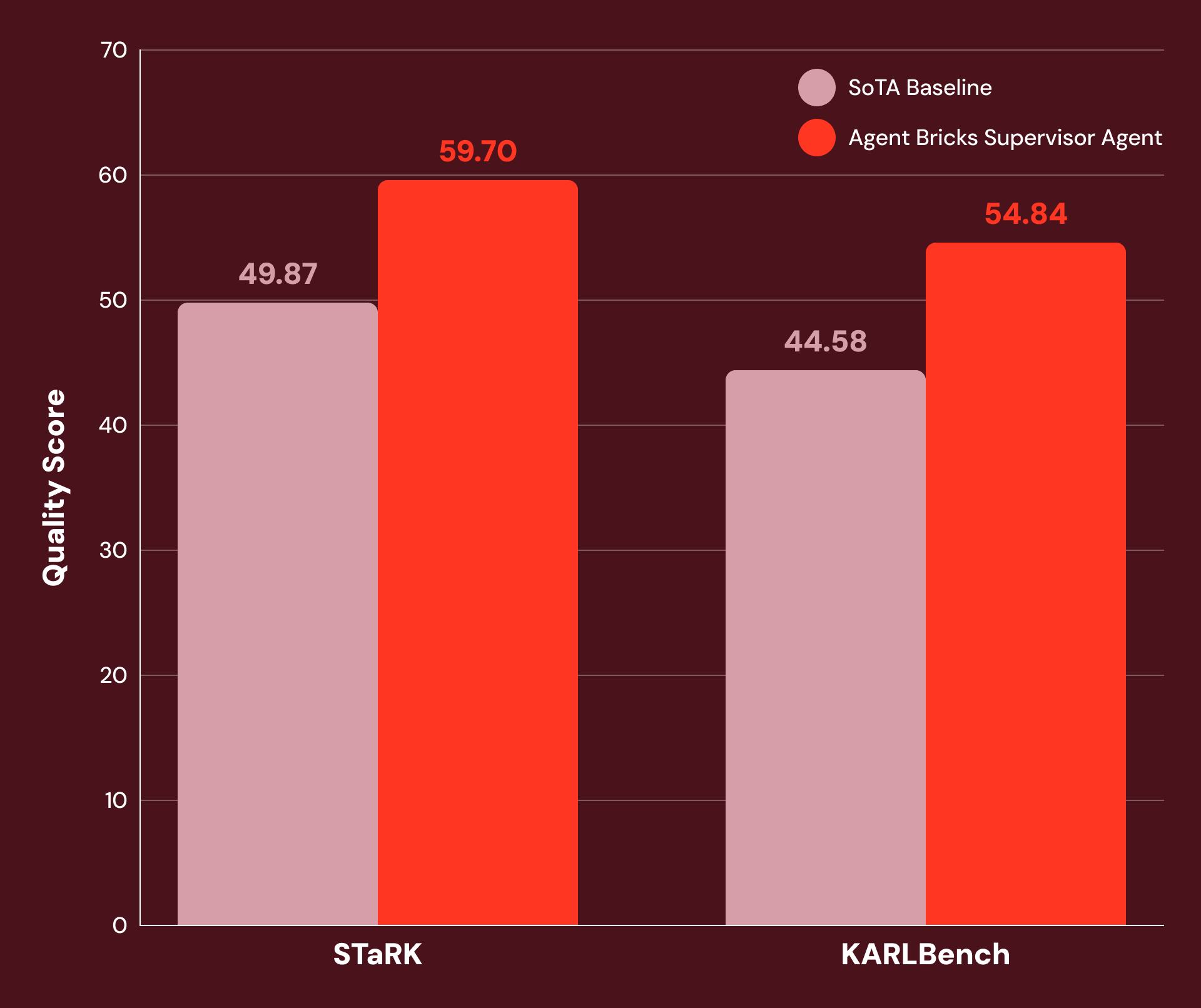
Con instrucciones ajustadas y una cuidadosa configuración de herramientas, encontramos que SA es altamente eficiente en una amplia gama de tareas empresariales intensivas en conocimiento. La Figura 1 muestra que SA logra una mejora del 20% o más sobre las líneas base SoTA en:
- STaRK: un conjunto de tres tareas de recuperación semi-estructurada publicadas por investigadores de Stanford.
- KARLBench: un conjunto de benchmarks para razonamiento complejo basado en conocimiento, publicado recientemente por Databricks.
Supervisor Agent demuestra ganancias significativas en una amplia gama de tareas de valor económico: desde recuperación académica (+21% en STaRK-MAG) hasta razonamiento biomédico (+38% en STaRK Prime) y análisis financiero (+23% en FinanceBench).
Configuración del Agente
Agent Bricks Supervisor Agent es un constructor de agentes declarativo que orquesta agentes y herramientas. Está construido sobre aroll, un framework interno de agentes para construir, evaluar y desplegar flujos de trabajo LLM multi-paso a escala.1 aroll y SA fueron diseñados específicamente para los casos de uso de agentes avanzados que nuestros clientes encuentran con frecuencia.
aroll permite agregar nuevas herramientas e instrucciones personalizadas a través de simples cambios de configuración, puede manejar miles de conversaciones concurrentes y ejecuciones de herramientas paralelas, e incorpora técnicas avanzadas de orquestación de agentes y gestión de contexto para refinar consultas y recuperarse de respuestas parciales. Todo esto es difícil de lograr con los sistemas SoTA de un solo turno hoy en día.
Dado que SA está construido sobre esta arquitectura flexible, su calidad puede mejorarse continuamente a través de una simple curación por parte del usuario, como ajustar las instrucciones de nivel superior o refinar las descripciones de los agentes, sin necesidad de escribir código personalizado.
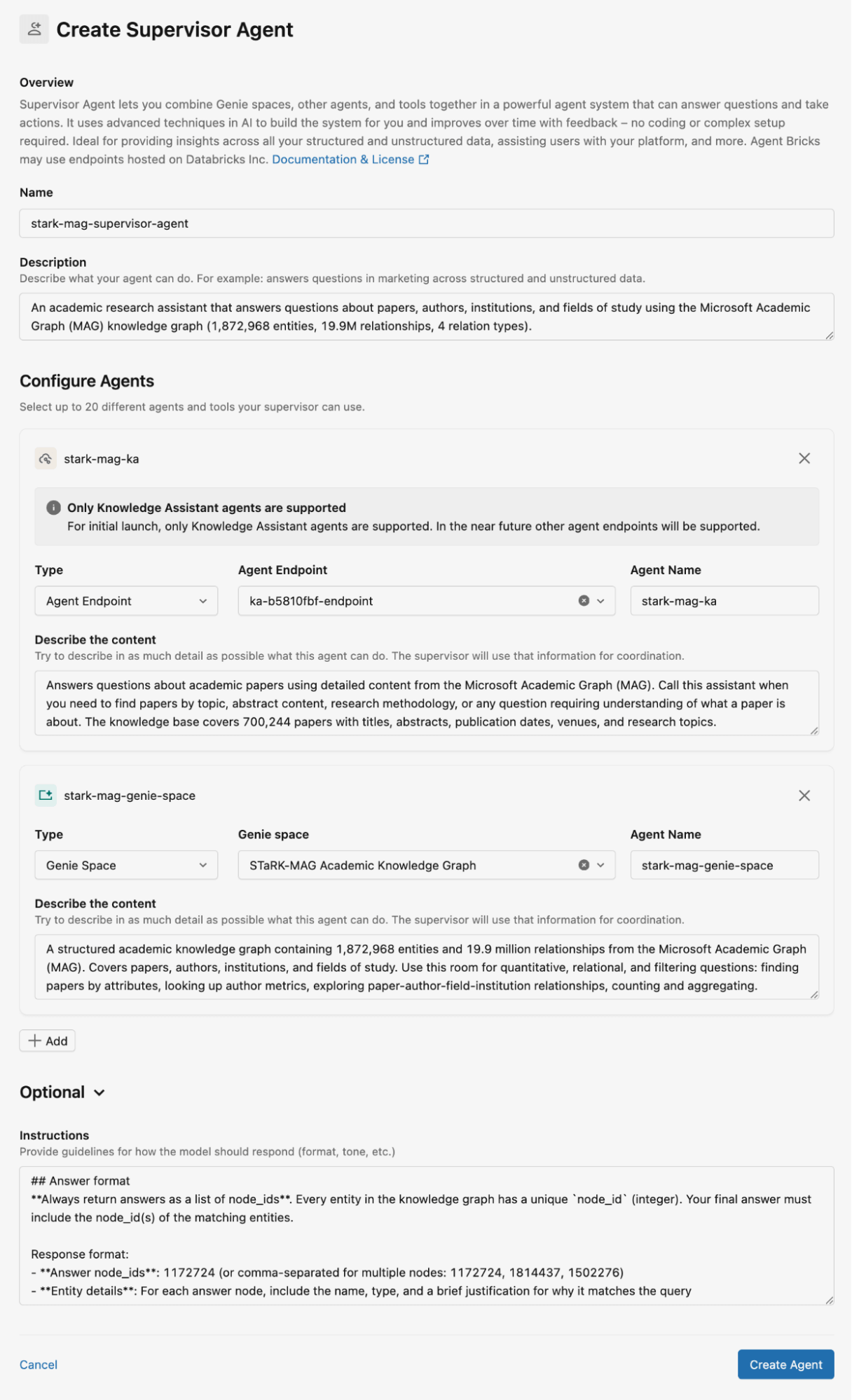
La Figura 2 muestra cómo configuramos el Supervisor Agent para el conjunto de datos STaRK-MAG. En esta entrada de blog, usamos Genie spaces para almacenar las bases de conocimiento relacionales y Knowledge Assistants para almacenar documentos no estructurados para su recuperación. Proporcionamos descripciones detalladas para todos los Knowledge Assistants y Genie spaces, así como instrucciones para las respuestas del agente.
Razonamiento Híbrido: Estructurado Se Une a No Estructurado
Para evaluar el razonamiento basado en conocimiento a partir de datos estructurados y no estructurados, utilizamos el benchmark STaRK, que incluye tres dominios:
- Amazon: atributos de productos (estructurados) y reseñas (no estructuradas)
- MAG: redes de citas (estructuradas) y artículos académicos (no estructurados)
- Prime: entidades biomédicas (estructuradas) y literatura (no estructurada)
Por ejemplo, "Encuéntrame un artículo escrito por un coautor con 115 artículos y que trate sobre el átomo de Rydberg" requiere que el sistema combine el filtrado estructurado ("coautor con 115 artículos") con la comprensión no estructurada ("sobre el átomo de Rydberg"). Las mejores líneas base publicadas utilizan la búsqueda de similitud vectorial con un reordenador basado en LLM, un enfoque sólido de un solo turno, pero que no puede descomponer las consultas entre tipos de datos. Para garantizar una comparación justa, volvimos a ejecutar esta línea base con el modelo fundacional SoTA actual, proporcionando una línea base sustancialmente más sólida.
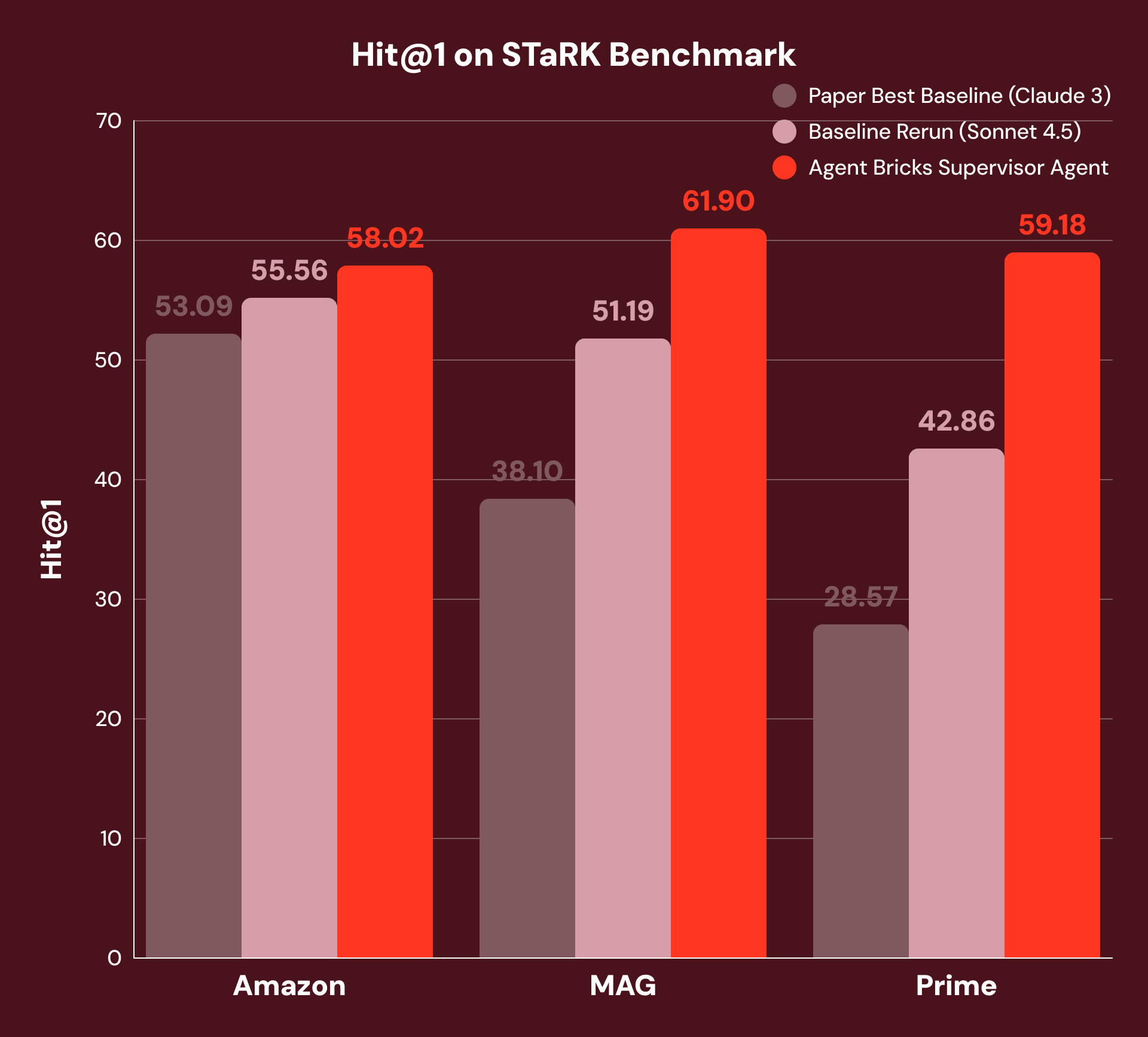
Con nuestro enfoque, SA descompone cada pregunta, dirige las sub-preguntas a la herramienta apropiada y sintetiza los resultados a través de múltiples pasos de razonamiento. Como muestra la Figura 3, esto logra un +4% de Hit@1 en Amazon, +21% en MAG y +38% en Prime sobre las mejores líneas base originales y nuestras líneas base reejecutadas con el modelo fundacional SoTA actual. Vemos las mejores mejoras en MAG y Prime, donde la respuesta requiere la integración más estrecha de datos estructurados y no estructurados.
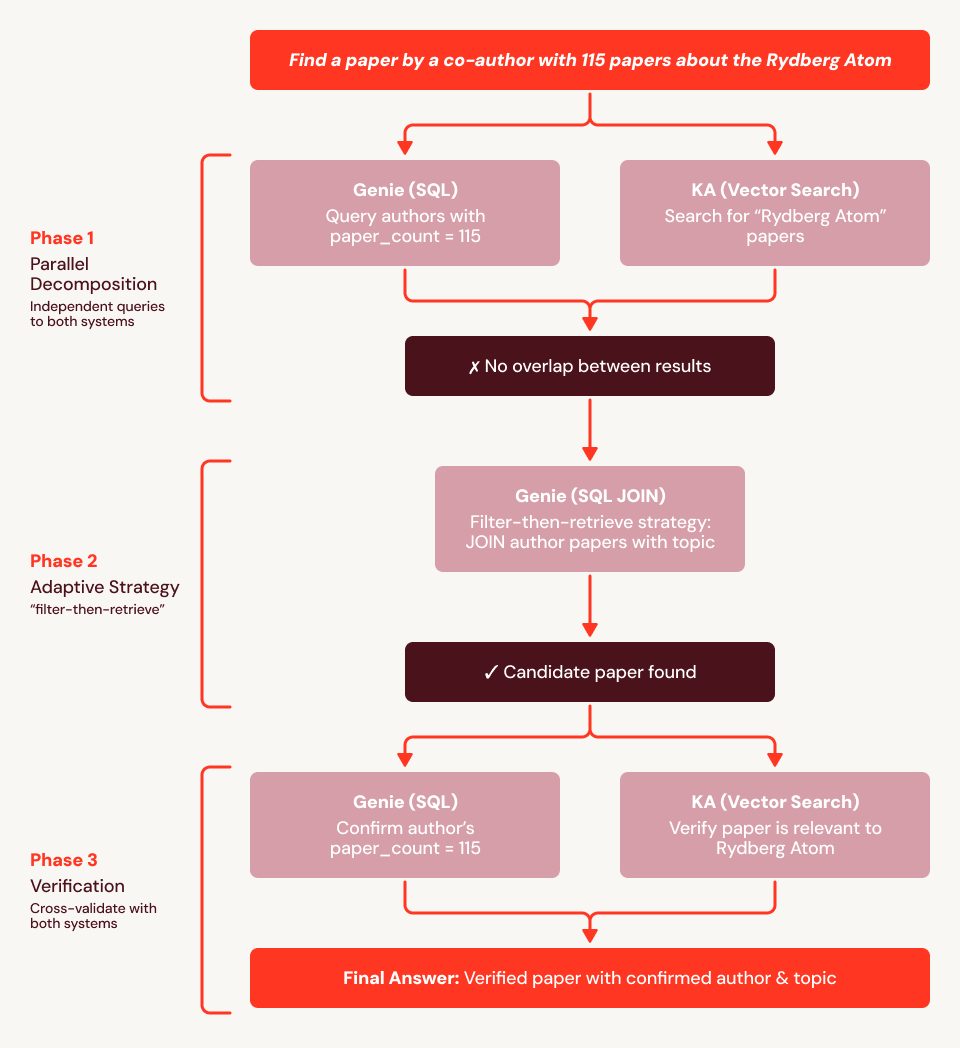
Usando nuestra pregunta de ejemplo anterior ("Encuéntrame un artículo escrito por un coautor con 115 artículos y que trate sobre el átomo de Rydberg"), encontramos que la línea base falla porque los embeddings no pueden codificar la restricción estructural ("coautor tiene exactamente 115 artículos"). En la Figura 4, mostramos un rastro de ejecución para SA: primero usa Genie para encontrar los 759 autores con 115 artículos y Knowledge Assistant para recuperar artículos sobre Rydberg, luego cruza los dos conjuntos. Cuando no se encuentra superposición, SA se adapta: emite una JOIN SQL de la lista de autores de 115 artículos contra todos los artículos que mencionan "Rydberg" en el título o resumen, presentando la respuesta directamente desde los datos estructurados. Luego llama a Knowledge Assistant para verificar la relevancia y a Genie para confirmar el número de artículos del autor, y devuelve con éxito el artículo correcto.
La Ventaja Agente en Tareas Intensivas en Conocimiento
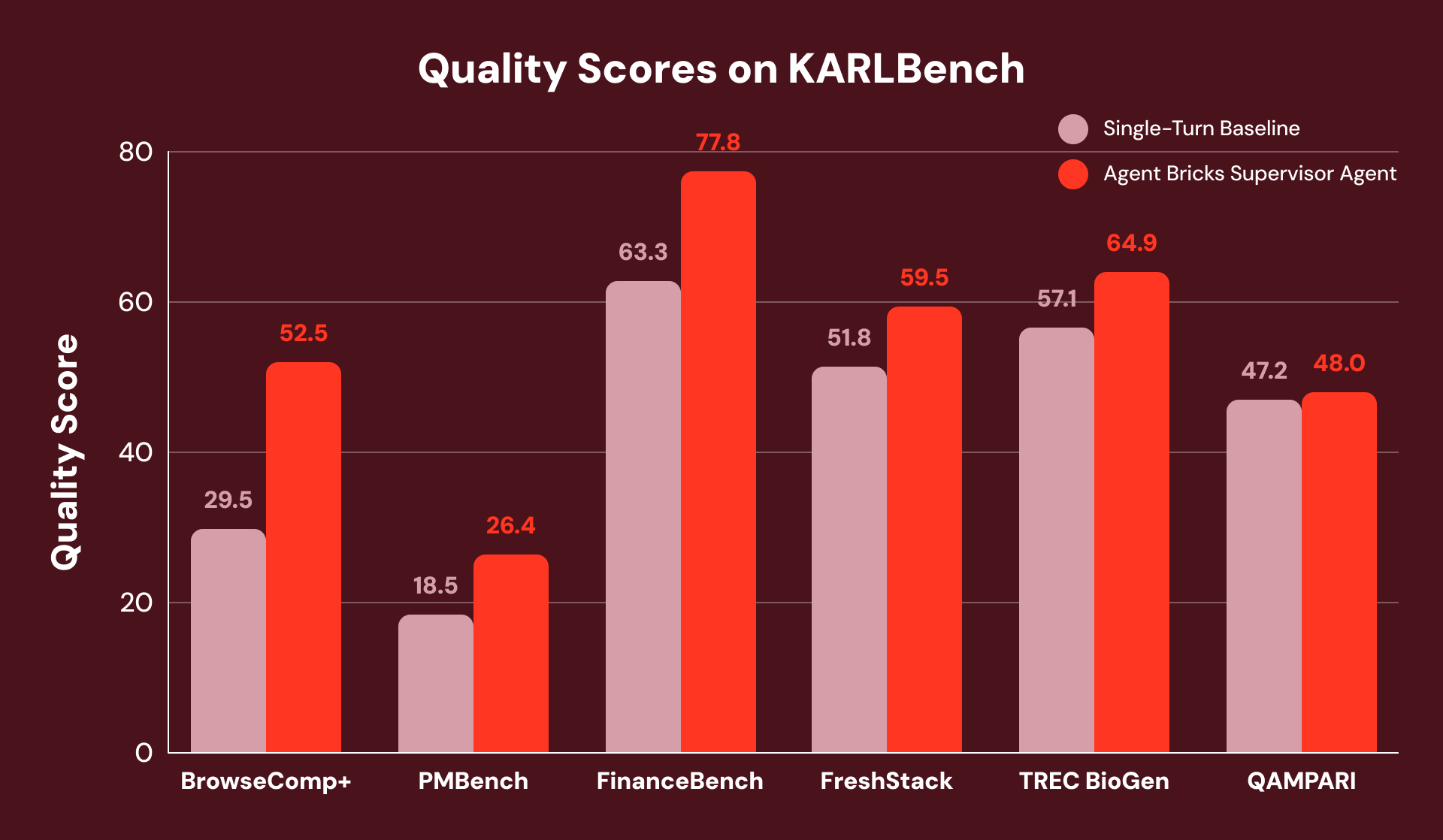
Para comparar el rendimiento de Agent Bricks SA con una línea base sólida de un solo turno (similar a la mejor línea base publicada para STaRK) donde no se requieren datos estructurados, los evaluamos usando KARLBench, un conjunto de benchmarks de razonamiento basado en conocimiento que pone a prueba colectivamente diferentes capacidades de recuperación y razonamiento:
- BrowseComp+: búsqueda de entidades por proceso de eliminación
- TREC BioGen: síntesis de literatura biomédica
- FinanceBench: razonamiento numérico sobre presentaciones financieras
- QAMPARI: recuperación exhaustiva de entidades
- FreshStack: solución de problemas técnicos sobre documentación
- PMBench: comprensión de documentos empresariales internos de Databricks
En general, el Supervisor Agent logra mejoras consistentes en los seis benchmarks, con las mayores mejoras en tareas que requieren un análisis exhaustivo o autocorrección. En FinanceBench, se recupera de una recuperación inicial incompleta detectando lagunas y reformulando consultas, lo que resulta en una mejora general del +23%.
Por ejemplo, las preguntas de BrowseComp+ tienen cada una de 5 a 10 restricciones interconectadas, como “Encuentra un jugador que dejara un club ruso (2015-2020), naturalizado europeo (2010-2016), altura 1.95-2.06m. ¿Cuál fue su tasa de éxito en bloqueos en los Juegos Olímpicos pospuestos por la COVID?” La línea base de un solo turno emite una consulta amplia que identifica correctamente al jugador, pero no recupera documentos de estadísticas detalladas y falla la pregunta.
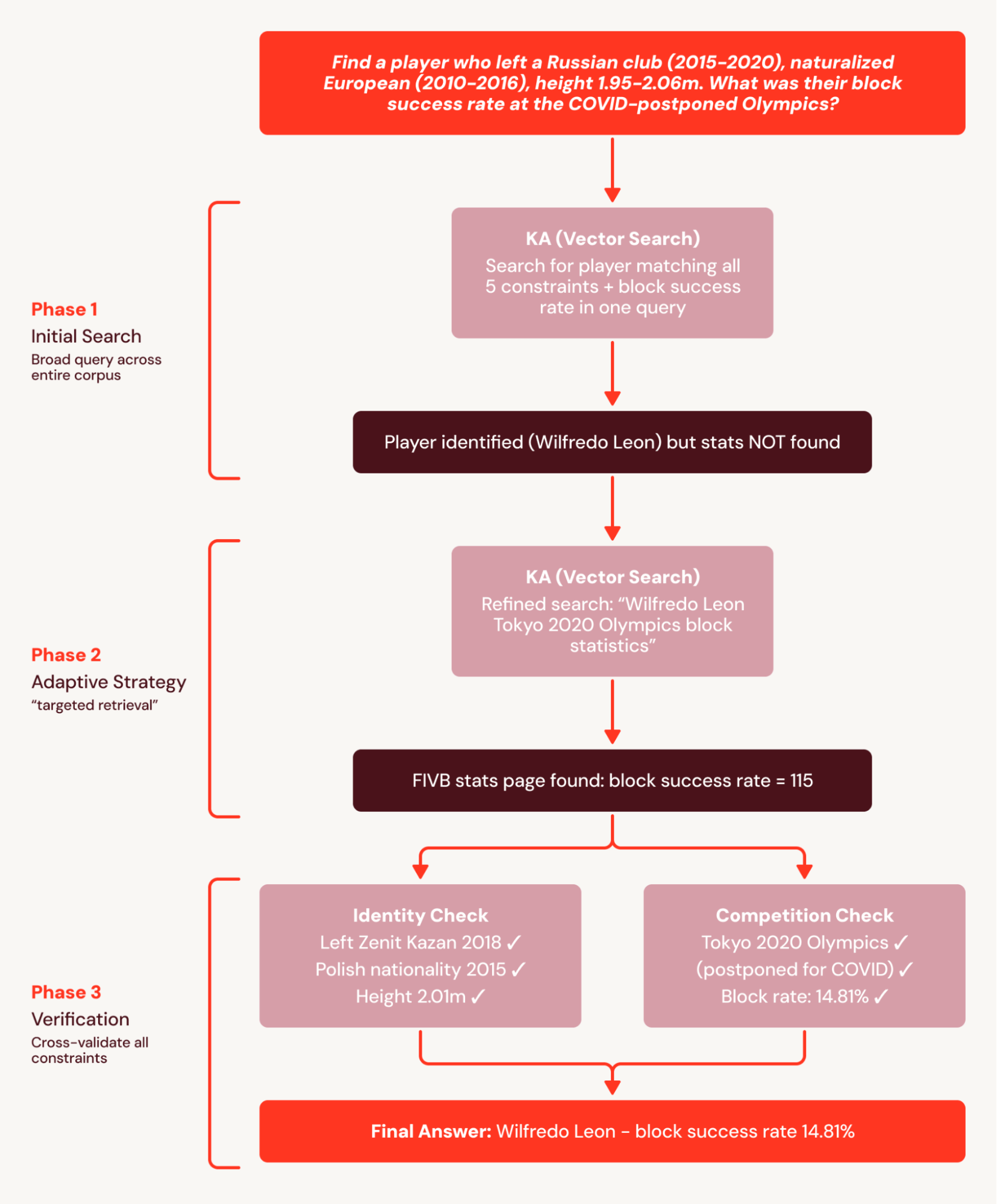
SA descompone esta tarea en un plan de búsqueda coordinado y lo divide en subconjuntos buscables. Esto evita el fallo de la línea base de un solo turno, donde las estadísticas no se encuentran porque se recuperan en una búsqueda posterior. Como resultado, SA logra una mejora relativa del +78%.
En otro ejemplo de PMBench, una de las preguntas es “¿qué tipos de salvaguardias utilizan los clientes?”, que requiere 26 fragmentos (ver definición en el informe de KARL) en más de 10 documentos de conversaciones de clientes para una respuesta exhaustiva. La línea base de un solo turno solo encuentra una mención de cliente porque no puede buscar en todas las categorías de salvaguardias en una sola pregunta. SA busca cada categoría de salvaguardia por separado (“detección de PII”, “alucinación”, “toxicidad”, “inyección de prompts”) y, gradualmente, recupera más y más menciones de clientes en el proceso.
Lo que aprendimos
Los resultados de nuestros experimentos apuntan a algunas conclusiones clave:
- Los agentes de razonamiento fundamentado pueden beneficiarse de una combinación de recuperación de datos estructurados y no estructurados si se les da acceso a las herramientas y representaciones de datos adecuadas.
- Para escenarios de recuperación de alta calidad, se debe evitar la creación de pipelines de RAG personalizados sobre conjuntos de datos heterogéneos, incluso si se utilizan modelos de vanguardia (SoTA) para la etapa de reordenación. El razonamiento multi-paso, donde, en cada paso, el agente selecciona la fuente de datos correcta y reflexiona sobre su utilidad, es crucial para mejorar el rendimiento.
- Un enfoque declarativo para la creación de agentes, como el implementado por el Agente Supervisor de Databricks, proporciona un buen equilibrio entre facilidad de uso y calidad.
Utilizamos el Agente Supervisor de Databricks para crear agentes para los tres dominios de STaRK y seis conjuntos de datos no estructurados en KARLBench. Las únicas cosas que difieren entre estas nueve tareas son las instrucciones y las herramientas; no se requirió código personalizado para procesar estos diversos conjuntos de datos. Por lo tanto, crear un agente de alto rendimiento para una nueva tarea empresarial es en gran medida una cuestión de escribir instrucciones precisas y equiparlo con las herramientas adecuadas, en lugar de construir un nuevo sistema desde cero.
El Agente Supervisor de Agent Bricks está disponible para todos nuestros clientes. Puede comenzar con Agent Bricks SA simplemente creando un agente y conectándolo a sus agentes, herramientas y servidores MCP existentes. Explore la documentación para ver cómo el Agente Supervisor se integra en sus flujos de trabajo de producción.
Autores: Xinglin Zhao, Arnav Singhvi, Mark Rizkallah, Jonathan Li, Jacob Portes, Elise Gonzales, Sabhya Chhabria, Kevin Wang, Yu Gong, Moonsoo Lee, Michael Bendersky y Matei Zaharia.
1Consulte nuestra publicación reciente “KARL: Knowledge Agents via Reinforcement Learning” para obtener más detalles sobre cómo se utiliza aroll para la generación de datos sintéticos, el entrenamiento de RL escalable y la inferencia en línea para tareas de agentes.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.