Anuncio de Sincronización Nativa de Lakehouse desde Lakebase
Abriendo datos de Lakebase a modelos, análisis y otros motores
- La Sincronización Nativa de Lakehouse (Vista Previa Pública) replica automáticamente datos de Lakebase Postgres en tablas administradas de Unity Catalog, sin canalizaciones ni cómputo externo.
- Las pilas CDC tradicionales fallan bajo cargas de trabajo impulsadas por agentes. Debido a que Lakebase y el Lakehouse comparten el mismo almacenamiento abierto, la sincronización se convierte en una propiedad nativa de la base de datos con cero impacto en el rendimiento de Postgres, sin costo adicional y propagación automática de esquemas.
- Características de ML en vivo basadas en el estado actual de la aplicación, datos operativos como la capa de Bronce de una arquitectura medallion con historial SCD Tipo 2 completo, y captura de auditoría incorporada para cada cambio.
Hoy nos complace anunciar la Vista Previa Pública de Sincronización Nativa de Lakehouse, una capacidad central de Lakebase Postgres que replica datos de Lakebase en tablas administradas de Unity Catalog, sin canalizaciones ni cómputo externo. La Sincronización Nativa de Lakehouse está disponible en todas las regiones de Lakebase en AWS y Azure.
Por qué lo construimos
Las aplicaciones solían ejecutarse en una única base de datos operativa. A medida que los casos de uso se expandieron, una base de datos dejó de ser suficiente. El análisis, el ML y la búsqueda viven fuera de la base de datos operativa, lo que significa que los datos tienen que moverse.
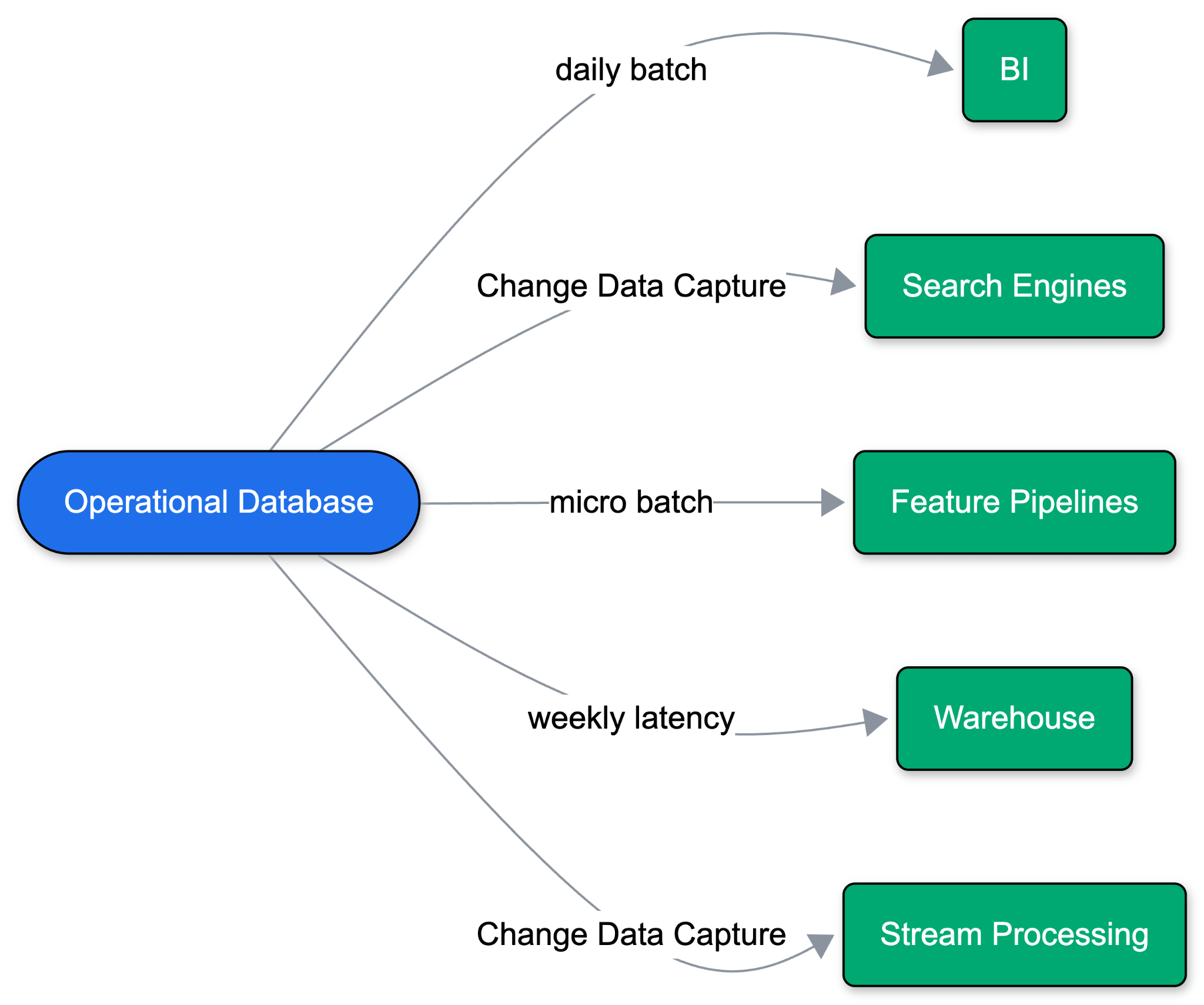
Históricamente, esto significaba volcados diarios por lotes a un almacén de datos, que eventualmente evolucionaron a Captura de Datos de Cambio (CDC). Los hiperescaladores empaquetaron esto como sincronizaciones 'administradas' ("zero-ETL"), implementando canalizaciones de datos junto con la base de datos. Pero estas sincronizaciones administradas dependen de suposiciones heredadas: cargas de trabajo siempre activas, esquemas estables, volúmenes de consulta predecibles y un único almacén de datos de destino. El problema se agrava con cada nuevo destino de datos: el rendimiento operativo se degrada, los esquemas cambian y los puntos de falla se multiplican en toda la pila.
El desarrollo basado en agentes rompe este modelo por completo. Los agentes ramifican datos rápidamente para iterar de forma segura, escalar a cero entre tareas y activar entornos de corta duración. Administrar una canalización personalizada para cada rama y cada destino simplemente no escala.
Conectarse a un almacén de datos es el enfoque incorrecto. Los consumidores descendentes rara vez son solo paneles de control; están integrando modelos, LLMs, servicios de predicción y canalizaciones de características. Los formatos de tabla abiertos como Delta Lake y Apache Iceberg™ proporcionan el primitivo ideal: almacenar datos una vez en almacenamiento de objetos económico para potenciar cada carga de trabajo sin duplicación. Es un conocimiento conocido: necesita un Lakehouse y desea datos operativos actualizados dentro de él.
Pero escribir datos operativos en un Lakehouse creó nuevos desafíos. Los equipos se vieron obligados a configurar ranuras de replicación de Postgres, conectores Debezium, motores de procesamiento de flujo para escribir en formatos abiertos y cómputo separado solo para optimizar las tablas. Cada salto agrega un punto de falla.
Sincronización como propiedad de Lakebase
Lakebase se basa en una suposición fundamentalmente diferente: una base de datos operativa debe ejecutarse en el mismo almacenamiento en la nube abierto y de bajo costo que su Lakehouse. Debido a que OLTP y OLAP comparten esta base de almacenamiento unificada, podemos eliminar por completo la canalización ETL. El movimiento de datos se convierte en una propiedad nativa de la propia base de datos.
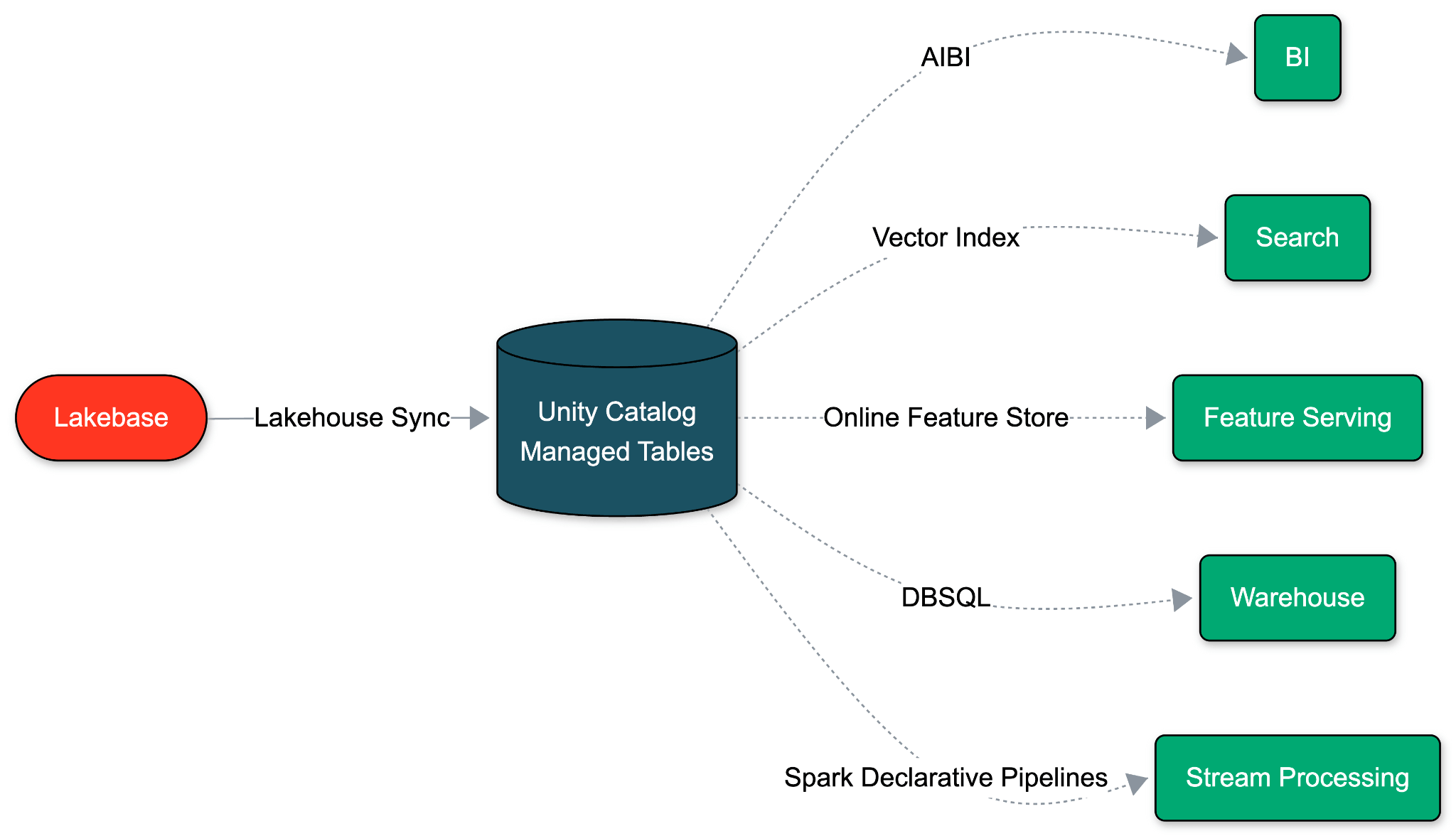
Con la Sincronización Nativa de Lakehouse, Lakebase decodifica su Registro de Escritura Anticipada (WAL) y escribe directamente en Tablas Administradas de Unity Catalog. Un único interruptor a nivel de esquema lo habilita en menos de un minuto. Esta sincronización no tiene impacto en el rendimiento de Postgres, ni costo adicional. Y dado que Databricks controla ambos extremos, los cambios de esquema fluyen automáticamente, eliminando la deriva y el retraso.
Agente primero de extremo a extremo
Los agentes crean aplicaciones en Lakebase. Agentes como Databricks Genie analizan los datos. Para mantener todo este ciclo de vida autónomo, la Sincronización Nativa de Lakehouse se crea como una propiedad central de Lakebase. Hereda los comportamientos exactos que los agentes necesitan para operar sin problemas:
- Escalado a cero: La sincronización se pausa cuando la base de datos escala a cero y se reanuda desde el último LSN al despertar.
- Gestión de cómputo cero: La sincronización es una parte nativa de Lakebase. Todo el monitoreo y la observabilidad permanecen dentro de su Proyecto Lakebase.
- Propagación automática de esquemas: Los cambios de esquema fluyen automáticamente. Agregar una columna se propaga instantáneamente. Eliminar una columna la retiene en el destino. Los agentes nunca tienen que recrear la sincronización.
Primitivas de Lakehouse en el lado del destino
Dado que el destino es una tabla administrada de Unity Catalog, todas las capacidades de Lakehouse están disponibles en los datos sincronizados desde el momento en que aterrizan.
- Análisis nativo de IA: Inmediatamente disponible para consulta, análisis y generación de canalizaciones por agentes como Databricks Genie y Genie Code.
- Legibilidad universal: Legible por Databricks SQL, Apache Spark, Canalizaciones Declarativas de Spark de Lakeflow, cuadernos de ML y cualquier herramienta que hable Delta o Iceberg.
- Gobernanza unificada: El linaje, las políticas de acceso, las etiquetas y las auditorías se heredan de Unity Catalog.
- Optimización automática: La Optimización Predictiva y la Agrupación Líquida se aplican sin configuración.
- Versionado por defecto: Cada inserción, actualización y eliminación se registra como historial SCD Tipo 2. Registros de auditoría, rebobinados y semántica de CDF incorporados.
Qué puedes construir con la Sincronización Nativa de Lakehouse
Juntos, estos comportamientos de origen y destino desbloquean tres patrones que anteriormente requerían una pila personalizada de Captura de Datos de Cambio (CDC):
Memoria de agente y características de ML en vivo. Las escrituras de aplicaciones llegan a Unity Catalog en un minuto, por lo que los modelos se reentrenan y puntúan contra el estado actual de la aplicación sin una canalización de ingesta separada.
Datos operativos en la arquitectura medallion. Utilice Lakebase como las Tablas de Bronce en la arquitectura medallion. Las actualizaciones de alta velocidad ocurren en Postgres, y el historial completo de cambios fluye al Lakehouse automáticamente como SCD Tipo 2.
Cumplimiento y auditoría. Cada inserción, actualización y eliminación se captura como una fila de historial en Unity Catalog. Sin seguimiento de historial en el lado de la aplicación, sin canalización de auditoría separada.
Empezar
Sincronización Nativa de Lakehouse está en Vista Previa Pública. Iniciar un Lakebase es instantáneo. Active la sincronización en un esquema una vez, y cada tabla existente y futura aparecerá en Unity Catalog en un minuto
Lakebase se basa en la misma base de datos abierta que el Lakehouse. La Sincronización Nativa de Lakehouse hace realidad esa visión, permitiendo que los datos de Lakebase fluyan a formatos abiertos automáticamente sin una canalización separada.
El siguiente paso: llevar esa misma apertura desde el Lakehouse a las tablas de Lakebase. Mantente atento.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial)
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.