Construyendo Búsqueda de Productos en Tiempo Real en Databricks
por Jiayi Wu, Luke Lefebure y Adam Gurary
- Cómo construir un sistema de búsqueda de productos en tiempo real en Databricks, cubriendo los componentes de ingesta, recuperación y clasificación necesarios para impulsar experiencias de búsqueda modernas.
- Una arquitectura de referencia que utiliza Databricks AI Search, Lakeflow y Lakebase para procesar datos de productos, recuperar resultados relevantes e incorporar señales operativas en tiempo real como precios, inventario y preferencias del usuario.
- Mejores prácticas y métricas para operar la búsqueda a escala, incluyendo la evaluación de la calidad de la recuperación, el monitoreo de la latencia y cómo los agentes y las aplicaciones pueden construirse sobre sistemas de búsqueda.
Imagina que estás diseñando un sistema de búsqueda para un mercado en línea que vende coches. En milisegundos, los usuarios esperan resultados que se ajusten a su presupuesto, coincidan con sus preferencias, estén disponibles cerca de ellos y se sientan relevantes.
Así es como se ve la búsqueda de productos web moderna. No es solo una herramienta de consulta, sino un motor de decisiones en tiempo real que debe recuperar, filtrar, clasificar y responder casi instantáneamente, todo mientras equilibra métricas comerciales y técnicas como ingresos, tasa de clics, latencia y relevancia.
Databricks proporciona la plataforma integral para construir estos sistemas, desde la ingesta de datos escalable (Lakeflow) hasta la recuperación basada en vectores (AI Search), los datos operativos en tiempo real (Lakebase) y las experiencias de búsqueda impulsadas por agentes (Agent Bricks). Este blog explica cómo estas piezas se unen para impulsar la búsqueda de productos en tiempo real.
Componentes para la búsqueda de productos
La búsqueda de productos no se trata simplemente de responder una pregunta o mostrar información a través de un chatbot. Es un proceso de descubrimiento y decisión: dinámico, personalizado y profundamente ligado a los ingresos. Los compradores esperan navegar, comparar y explorar. El objetivo no es generar una única respuesta, sino presentar un conjunto clasificado de opciones que se sientan relevantes, confiables y dignas de consideración.
Un sistema de búsqueda de productos en tiempo real generalmente tiene 3 segmentos (Figura 1).
- La ingesta prepara los datos del producto para la búsqueda. Los títulos, descripciones y atributos del producto se procesan, se convierten en incrustaciones (embeddings), se enriquecen con metadatos y se indexan para una recuperación rápida.
- La recuperación encuentra lo que podría ser relevante generando un conjunto de candidatos utilizando búsqueda de texto completo, semántica o híbrida combinada con filtrado estructurado.
- El refinamiento determina cómo deben interpretarse y ordenarse los resultados aplicando comprensión de consultas, lógica de clasificación, personalización y reglas de negocio.

{kind=link}
Detrás de la barra de búsqueda
Ninguna de esas experiencias existe sin una infraestructura sólida y métricas significativas.
- La infraestructura hace posible la velocidad y la relevancia.
- Las métricas demuestran que su sistema es realmente rápido y relevante, no solo en teoría.
La búsqueda de productos moderna requiere ambos: la base de ingeniería para entregar resultados y la disciplina de métricas para validar continuamente que esos resultados son lo suficientemente buenos.
Recorrido por la arquitectura
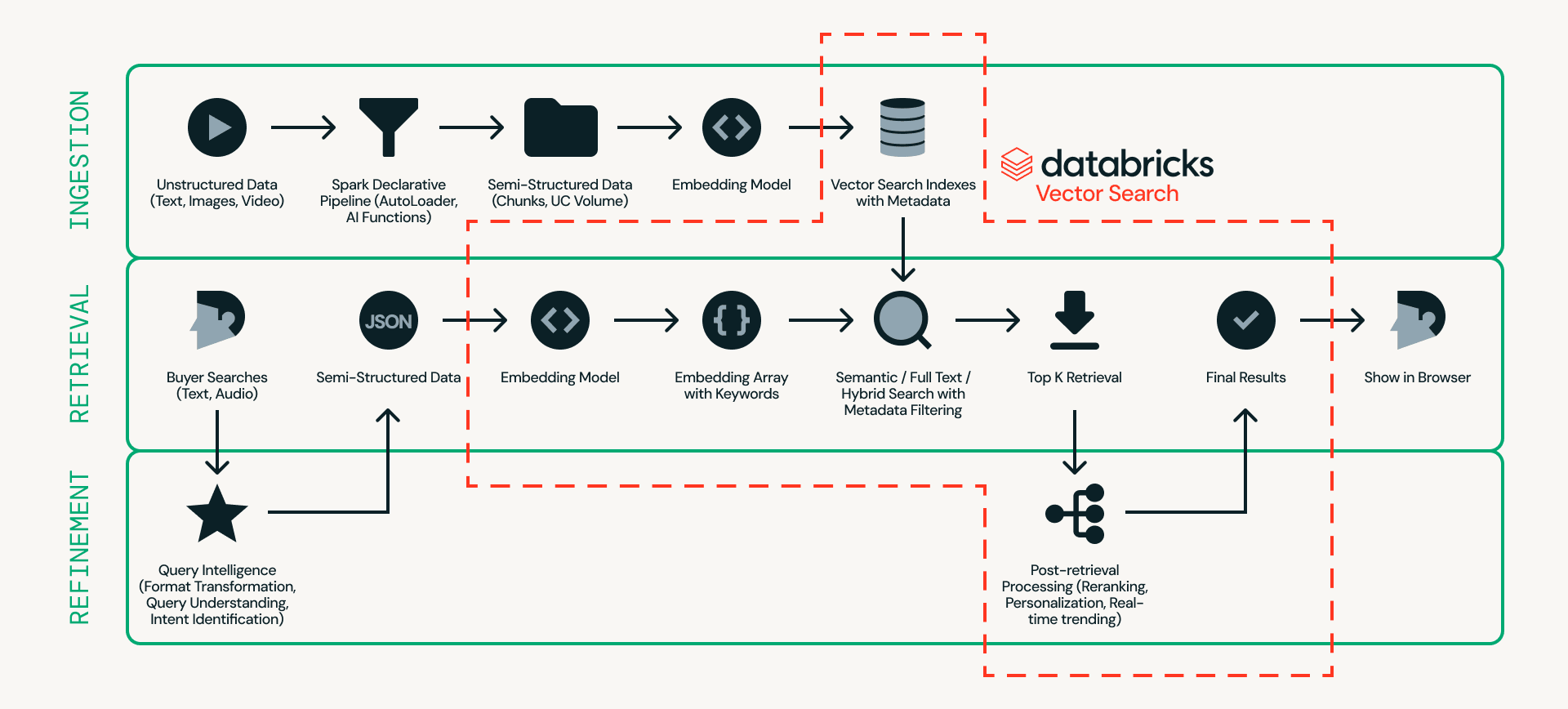
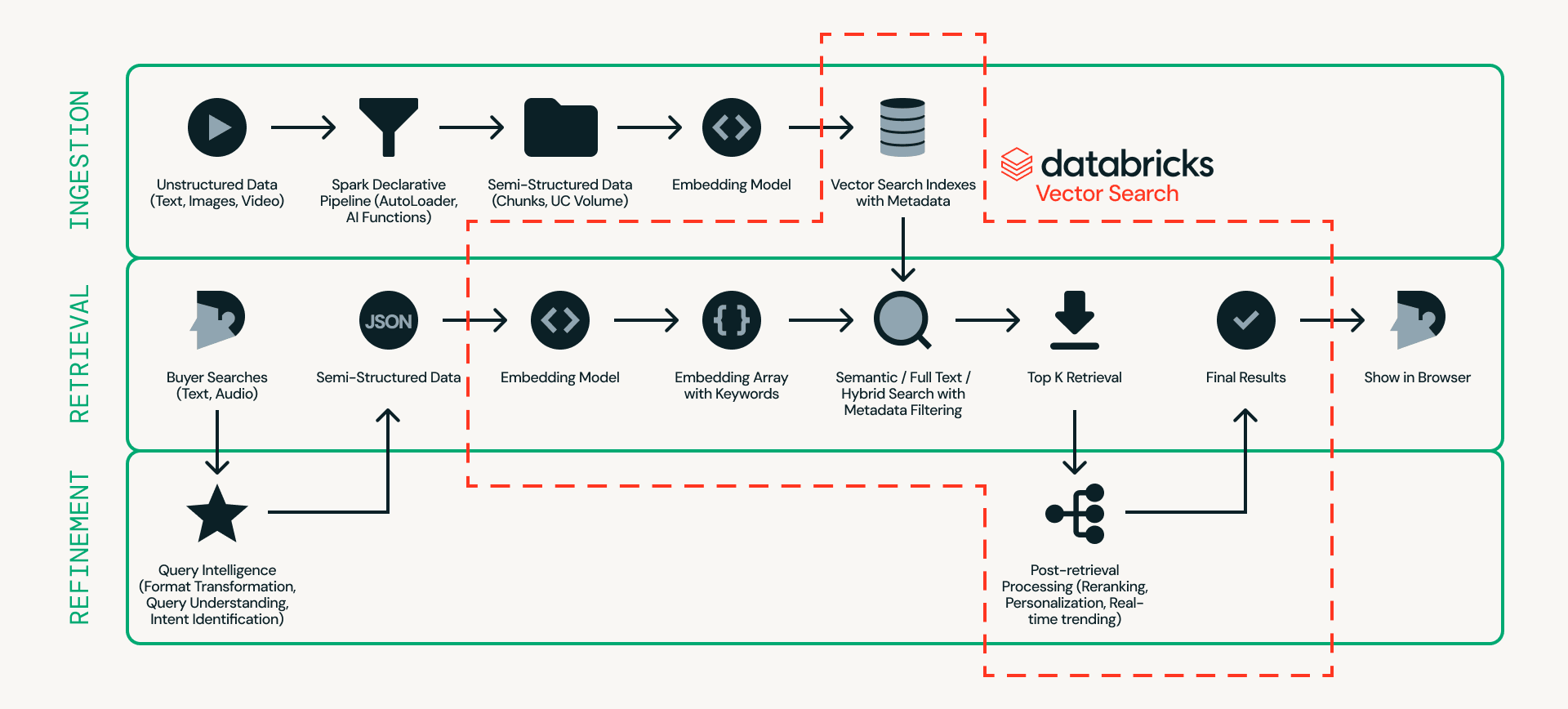
Primero, veamos la arquitectura. La Figura 2 muestra un ejemplo detallado de una arquitectura de búsqueda de productos en tiempo real.
{kind=link}
En el centro de este diseño se encuentra Databricks AI Search, que gestiona la ingesta, recuperación y refinamiento en una única plataforma, eliminando la necesidad de unir múltiples sistemas externos.
- La ingesta prepara los datos del producto para que puedan buscarse de manera eficiente. Las fuentes no estructuradas, como listados de productos e imágenes, se procesan a través de pipelines escalables utilizando Databricks Auto Loader, Lakeflow Spark Declarative Pipeline y AI Functions (por ejemplo, ai_parse_document). Los datos pueden luego ser divididos en fragmentos y convertidos en incrustaciones (embeddings) con metadatos (por ejemplo, modelo de coche, color o precio) en Databricks AI Search.
- La recuperación gestiona las consultas en tiempo real. La entrada del usuario se transforma en incrustaciones (embeddings) y filtros estructurados, y Databricks AI Search recupera los principales candidatos utilizando búsqueda semántica, búsqueda de texto completo o búsqueda híbrida con filtrado de metadatos.
- El refinamiento mejora los candidatos recuperados para convertirlos en resultados finales. Si bien la recuperación proporciona una base sólida, esta capa refina los resultados interpretando la intención, aplicando lógica de clasificación e incorporando personalización y reglas de negocio cuando sea necesario. El contexto operativo en tiempo real, como el estado de la sesión, el inventario, los precios y las preferencias del usuario, se puede servir a través de Lakebase, lo que permite que las señales de baja latencia (menos de 10 ms) influyan en el orden final.
Algunas pautas prácticas al construir sistemas de búsqueda en Databricks:
- Experimenta con modelos fácilmente. Intercambia modelos de incrustación (embedding) con mínima fricción y aprovecha las capacidades nativas de reordenamiento (reranking). Futuras actualizaciones permitirán el ajuste fino de modelos de reordenamiento con un solo clic directamente dentro de la plataforma, simplificando la optimización de la relevancia.
- Sirve el estado de la aplicación a la velocidad de la búsqueda. Utiliza Lakebase para almacenar el estado de la aplicación en tiempo real (contexto de sesión, inventario, precios, preferencias de usuario) con una latencia inferior a 10 ms. La CDC gestionada sincroniza Lakebase con Delta automáticamente, por lo que los modelos de clasificación y los análisis siempre reflejan los datos operativos actuales sin pipelines personalizados.
- Prueba la escalabilidad antes de la producción. Valida la latencia y el rendimiento bajo tráfico realista, incluyendo escenarios de alto QPS. Puedes simular cargas de trabajo de producción hoy utilizando el notebook de prueba de carga de búsqueda, con soporte nativo de prueba de carga con un solo clic en una futura versión. Para tráfico sostenido, aprovecha los endpoints de alto QPS para manejar la concurrencia a escala, y monitorea el rendimiento a través de la observabilidad de endpoints para rastrear la latencia, el rendimiento y la salud del sistema.
- Crea una búsqueda lista para agentes desde el primer día. Cada índice de AI Search con incrustaciones (embeddings) gestionadas obtiene automáticamente un servidor MCP gestionado. Úsalo para la integración de agentes sin configuración, la VectorSearchRetrieverTool para control basado en código, o apunta un Knowledge Assistant a tu índice para preguntas y respuestas instantáneas con citas, impulsado por Instructed Retriever, que ofrece un 70% más de precisión que los sistemas RAG estándar.
Métricas importantes
Un sistema de búsqueda no tiene éxito porque se vea elegante en un diagrama. Tiene éxito porque ofrece resultados rápidos y relevantes que impulsan los resultados comerciales.
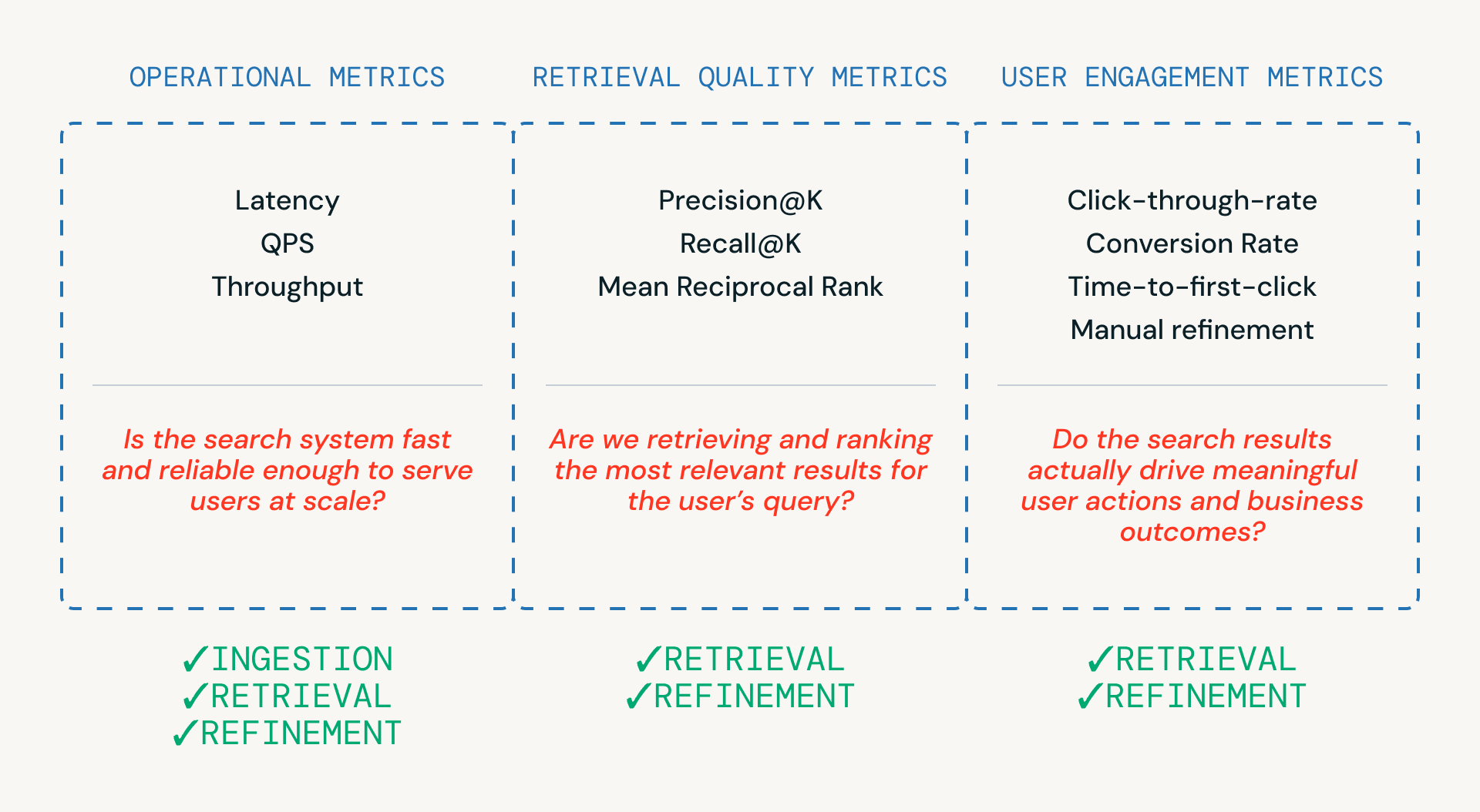
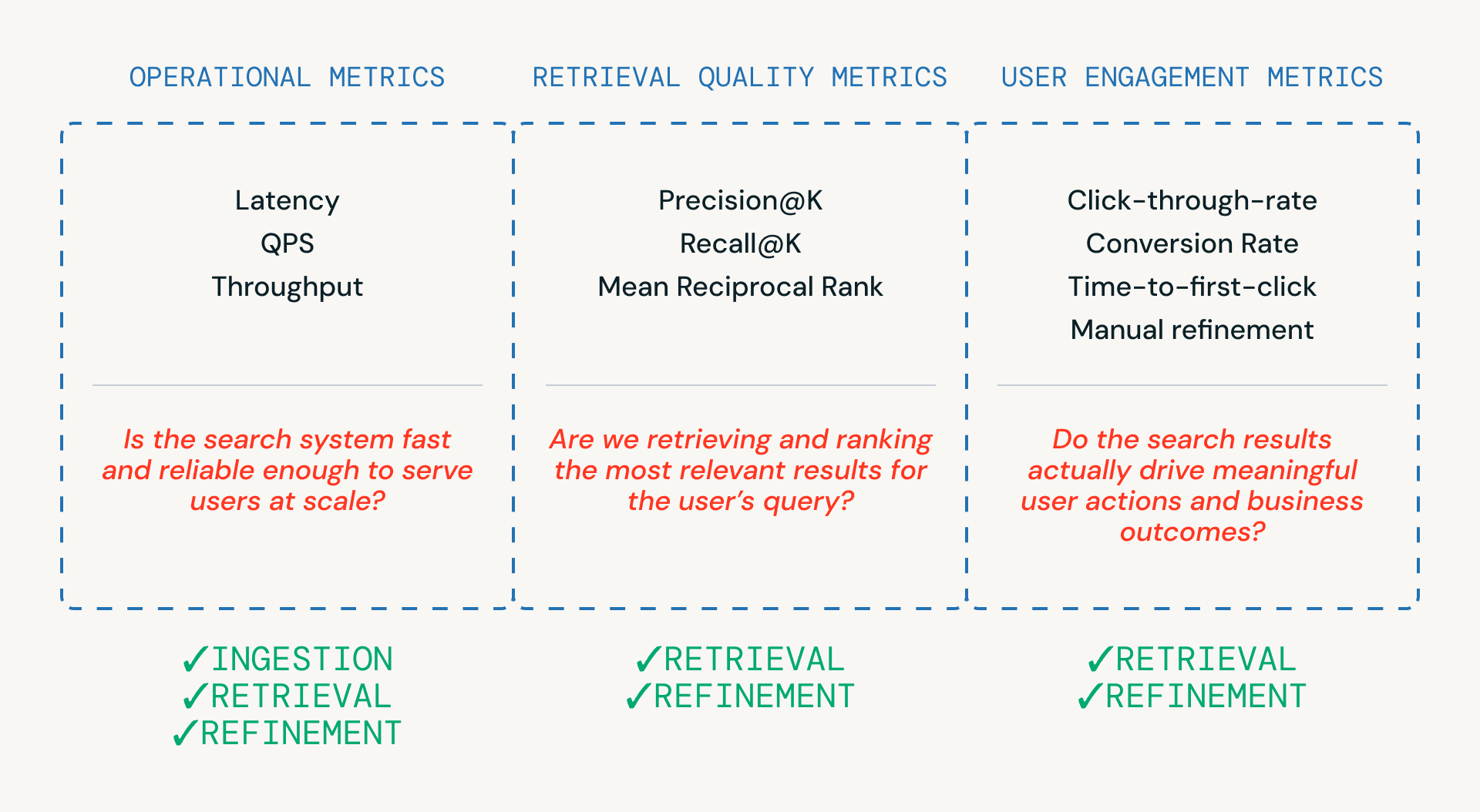
Como se muestra en la Figura 3, tres categorías de métricas ayudan a los equipos a evaluar un pipeline de búsqueda, cada una ligada a una capa diferente del sistema.
- Las métricas operativas aseguran que el sistema sea lo suficientemente rápido y confiable para servir a los usuarios a escala. Estas son críticas en los pasos de ingesta, recuperación y refinamiento.
- Las métricas de calidad de recuperación miden si el sistema está realmente recuperando y clasificando candidatos relevantes, y están más estrechamente ligadas a las etapas de recuperación y refinamiento donde ocurren la clasificación y el reordenamiento.
- Las métricas de interacción del usuario capturan el comportamiento del mundo real —si los usuarios hacen clic, refinan o finalmente convierten—, proporcionando retroalimentación que informa las mejoras en la recuperación y los refinamientos a lo largo del tiempo.
{kind=link}
Algunas pautas prácticas al evaluar sistemas de búsqueda en Databricks:
- Equilibre las métricas, no solo optimice una. Los sistemas de búsqueda efectivos deben equilibrar múltiples métricas; rara vez se gana en todas las métricas a la vez. Por ejemplo, optimizar agresivamente la precisión puede aumentar la latencia u ocultar resultados relevantes, lo que en última instancia frustra a los compradores.
- Monitoree cuidadosamente la latencia en tiempo real. Desglose la latencia por etapas del pipeline y rastree la latencia de cola, como p95/p99, para identificar rápidamente los cuellos de botella. Técnicas como el almacenamiento en caché pueden ayudar a cumplir con los SLA de latencia estrictos.
- Rastree las métricas sistemáticamente. Use MLflow para registrar y evaluar las métricas de recuperación y participación en todos los experimentos. La evaluación nativa de la calidad de recuperación estará disponible pronto en Databricks AI Search, lo que lo hará aún más fácil.
Búsqueda en Producción a Escala — FOX Sports
FOX Sports construyó su barra de búsqueda impulsada por IA en Databricks AI Search, manejando miles de QPS con una mejora de 2x en la tasa de éxito de las consultas. Lanzada para el Super Bowl LIX, su arquitectura demuestra varios patrones cubiertos en este blog:
- Ingesta en tiempo real. Spark Structured Streaming ingiere continuamente contenido en los Delta Sync Indexes a medida que se publica.
- Recuperación en dos fases. Coincidencia exacta de entidades para jugadores y equipos, además de búsqueda semántica ponderada por tiempo para artículos y videos, orquestada por Databricks Model Serving.
- Optimización de producción. Una capa de caché y una función de búsquedas de tendencias —que impulsa más del 25% de todas las solicitudes de búsqueda— manejan los picos de alto tráfico durante los eventos en vivo.
De la Búsqueda a las Aplicaciones Inteligentes
La búsqueda de productos no existe de forma aislada; es una capa en una pila de aplicaciones más amplia. Así es como el resto de la plataforma Databricks amplía lo que puede construir sobre AI Search.
Aplicaciones en Tiempo Real con Lakebase
Para las aplicaciones de búsqueda orientadas al cliente —mercados, catálogos de productos, plataformas de medios—, el índice de búsqueda es solo una parte de la historia. Las aplicaciones también necesitan una base de datos transaccional para el estado operativo: niveles de inventario, precios, sesiones de usuario, preferencias de personalización. Lakebase proporciona esto como una base de datos totalmente gestionada y compatible con PostgreSQL, integrada de forma nativa con la plataforma Databricks. La sincronización bidireccional gestionada con Delta Lake significa que los modelos de clasificación se entrenan con los datos operativos más recientes, y los conocimientos analíticos fluyen de vuelta a la capa de aplicación, todo ello gobernado por Unity Catalog.
Búsqueda Impulsada por Agentes con Agent Bricks
Databricks proporciona automáticamente un servidor MCP gestionado para cada índice de AI Search, desbloqueando múltiples patrones de integración:
- Asistente de Conocimiento. Un chatbot de preguntas y respuestas sobre sus documentos. Apúntelo a un índice de AI Search y obtenga una búsqueda de documentos lista para producción con citas. Utiliza Instructed Retriever internamente — 70% mejor precisión que RAG estándar y 30% mejor que RAG agéntico.
- Agentes personalizados. Use VectorSearchRetrieverTool o MCP con cualquier framework (OpenAI Agents SDK, LangGraph, LlamaIndex). Control total sobre los parámetros de recuperación, incrustaciones y filtros. Despliegue como Databricks Apps con el rastreo de MLflow.
- Agente Supervisor. Orqueste múltiples subagentes: un Asistente de Conocimiento para preguntas y respuestas de documentos, un espacio Genie para consultas de datos estructurados y UC Functions para lógica de negocio personalizada, todo coordinado por un único supervisor.
Conclusión
Construir un sistema de búsqueda de productos moderno requiere más que un índice de búsqueda. Requiere una infraestructura diseñada para manejar la escala, el rendimiento y la observabilidad del mundo real:
- Ejecución de baja latencia. La comprensión de consultas, la recuperación, el filtrado y la reclasificación deben completarse dentro de estrictos presupuestos de latencia p95/p99.
- Capacidad de recuperación híbrida. Combine la similitud semántica (embeddings) con el filtrado estructurado, como precio, categoría o disponibilidad.
- Escalabilidad bajo carga. Mantenga un alto QPS y concurrencia durante el tráfico pico sin degradar el rendimiento.
- Observabilidad. Mantenga una visibilidad clara de los desgloses de latencia, el rendimiento de clasificación y la salud general del sistema.
- Listo para agentes por defecto. Cada índice de AI Search es una herramienta MCP, inmediatamente utilizable por el Asistente de Conocimiento, agentes personalizados y Agentes Supervisores.
- Soporte operativo de pila completa. Lakebase proporciona la base de datos transaccional para el estado de la aplicación en tiempo real, sincronizada con Delta sin ETL.
¿Listo para construir? Siga la guía de calidad de recuperación para comparar y optimizar su pipeline de búsqueda, vea cómo FOX Sports construyó una búsqueda impulsada por IA a escala, y sumérjase en la documentación de AI Search para empezar.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.