Monitoreo de la calidad de los datos a escala con IA agentiva
Basado en Unity Catalog para detectar problemas de forma temprana y resolverlos rápidamente
• La calidad de los datos manual y basada en reglas no escala a medida que los entornos de datos crecen para el análisis y la IA.
• El monitoreo agéntico de la calidad de los datos aprende los patrones de datos esperados y detecta problemas en los conjuntos de datos críticos.
• Las señales nativas de la plataforma, como el linaje de Unity Catalog, ayudan a los equipos a resolver problemas más rápido a escala empresarial.
El desafío de la calidad de los datos a gran escala
A medida que las organizaciones crean más productos de datos e IA, mantener la calidad de los datos se vuelve más difícil. Los datos impulsan todo, desde los dashboards ejecutivos hasta los bots de preguntas & respuestas para toda la empresa. Una tabla desactualizada genera respuestas desactualizadas o incluso incorrectas, lo que afecta directamente los resultados del negocio.
La mayoría de los enfoques de calidad de datos no escalan a esta realidad. Los equipos de datos dependen de reglas definidas manualmente que se aplican a un pequeño conjunto de tablas. A medida que los ecosistemas de datos crecen, crean puntos ciegos y limitan la visibilidad del estado general.
Los equipos agregan continuamente nuevas tablas, cada una con sus propios patrones de datos. Mantener comprobaciones personalizadas para cada conjunto de datos no es sostenible. En la práctica, solo se supervisan unas pocas tablas críticas, mientras que la mayor parte de los datos permanece sin verificar.
El resultado es que las organizaciones tienen más datos que nunca, pero menos confianza para usarlos.
Presentamos la supervisión agéntica de la calidad de los datos
Hoy, Databricks anuncia la vista previa pública de Data Quality Monitoring en AWS, Azure Databricks y GCP.
El monitoreo de la calidad de los datos reemplaza las verificaciones manuales y fragmentadas con un enfoque agentivo diseñado para escalar. En lugar de umbrales estáticos, los agentes de IA aprenden los patrones de datos normales, se adaptan a los cambios y monitorean el patrimonio de datos de forma continua.
La integración profunda con la plataforma Databricks permite más que la detección.
- La causa raíz se muestra directamente en los trabajos y las canalizaciones ascendentes de Lakeflow. Los equipos pueden pasar de Data Quality Monitoring al trabajo afectado y aprovechar las capacidades de observabilidad integradas de Lakeflow para obtener un contexto más profundo sobre las fallas y resolver los problemas más rápido.
- Los problemas se priorizan utilizando el linaje de Unity Catalog y las etiquetas certificadas, lo que garantiza que los conjuntos de datos de alto impacto se aborden primero.
Con el monitoreo nativo de la plataforma, los equipos detectan los problemas antes, se enfocan en lo más importante y resuelven los problemas más rápido a escala empresarial.
“Nuestro objetivo siempre ha sido que nuestros datos nos digan cuándo hay un problema. Data Quality Monitoring de Databricks por fin lo hace a través de su enfoque impulsado por la IA. Se integra perfectamente en la UI y monitorea todas nuestras tablas con un enfoque sin intervención y sin configuración, lo que siempre fue un factor limitante con otros productos. En lugar de que los usuarios informen los problemas, nuestros datos los señalan primero, lo que mejora la calidad, la confianza y la integridad en nuestra plataforma”. —Jake Roussis, ingeniero de datos principal de Alinta Energy
Cómo funciona la supervisión de la calidad de los datos
La supervisión de la calidad de los datos ofrece información procesable a través de dos métodos complementarios.
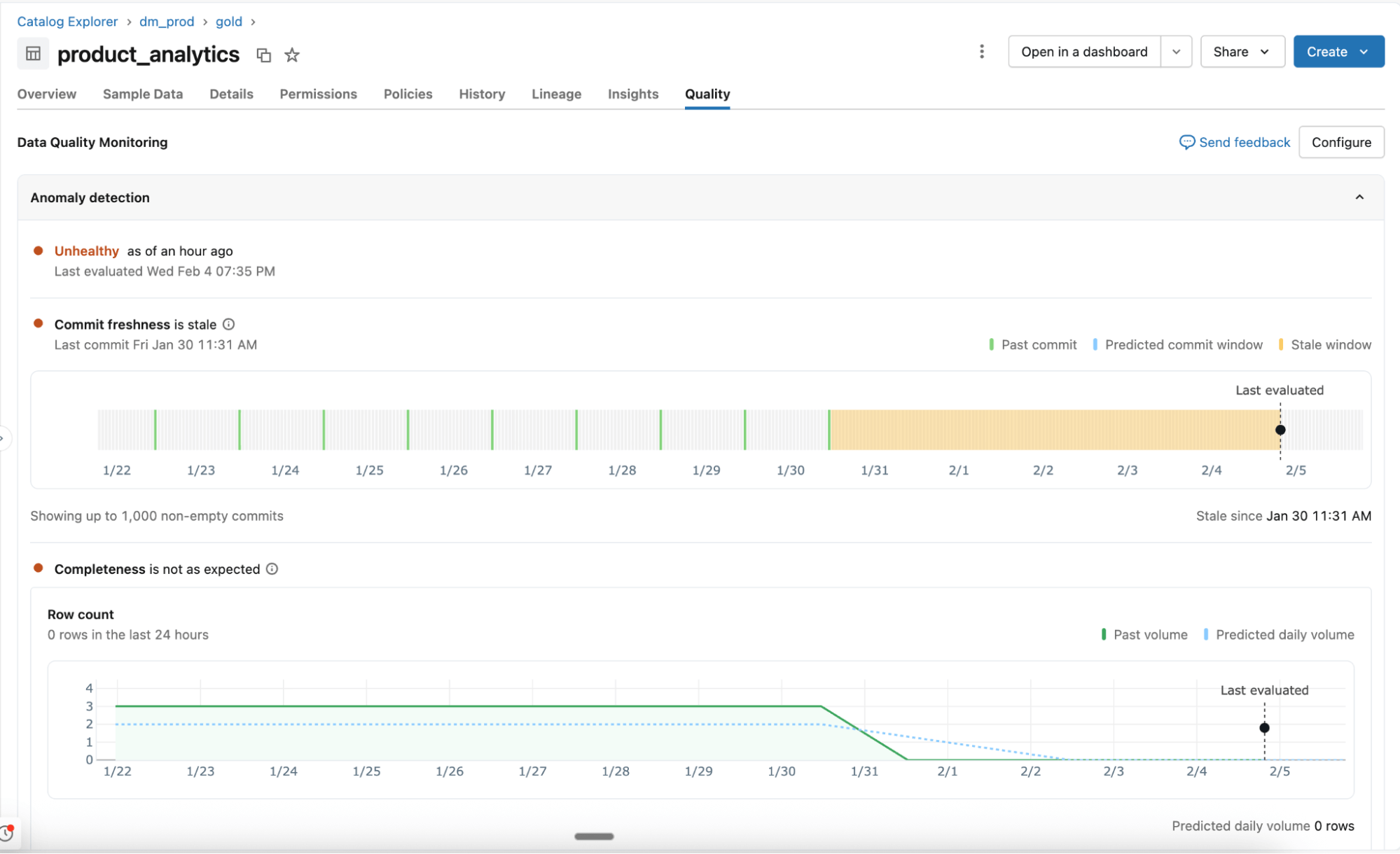
Detección de anomalías
Habilitada a nivel de esquema, la detección de anomalías supervisa todas las tablas críticas sin configuración manual. Los agentes de IA aprenden los patrones históricos y el comportamiento estacional para identificar cambios inesperados.
- Comportamiento aprendido, no reglas estáticas: Los agentes se adaptan a la variación normal y supervisan señales de calidad clave, como la actualidad y la completitud. Próximamente se agregará soporte para verificaciones adicionales, que incluyen porcentajes de valores nulos, unicidad y validez.
- Análisis inteligente a escala: Todas las tablas de un esquema se analizan una vez y, luego, se vuelven a revisar en función de su importancia y frecuencia de actualización. El linaje de Unity Catalog y la certificación determinan qué tablas son más importantes. Las tablas que se usan con frecuencia se analizan más a menudo, mientras que las estáticas u obsoletas se omiten automáticamente.
- Tablas del sistema para visibilidad y generación de informes: El estado de la tabla, los umbrales aprendidos y los patrones observados se registran en las tablas del sistema. Los equipos usan estos datos para alertas, generación de informes y análisis más profundos.
Perfilado de datos
Habilitado a nivel de tabla, el perfilado de datos captura estadísticas de resumen y realiza un seguimiento de sus cambios a lo largo del tiempo. Estas métricas proporcionan contexto histórico y se usarán para la detección de anomalías, para que puedas detectar problemas fácilmente.
“En OnePay, nuestra misión es ayudar a las personas a alcanzar el progreso financiero, empoderándolas para ahorrar, gastar, pedir prestado y hacer crecer su dinero. Los datos de alta calidad en todos nuestros conjuntos de datos son fundamentales para cumplir con esa misión. Con el Monitoreo de Calidad de Datos, podemos detectar problemas a tiempo y tomar medidas rápidamente. Podemos garantizar la precisión en nuestros análisis, informes y en el desarrollo de modelos de ML robustos, todo lo cual contribuye a que brindemos un mejor servicio a nuestros clientes”. —Nameet Pai, director de Plataforma e Ingeniería de Datos en OnePay
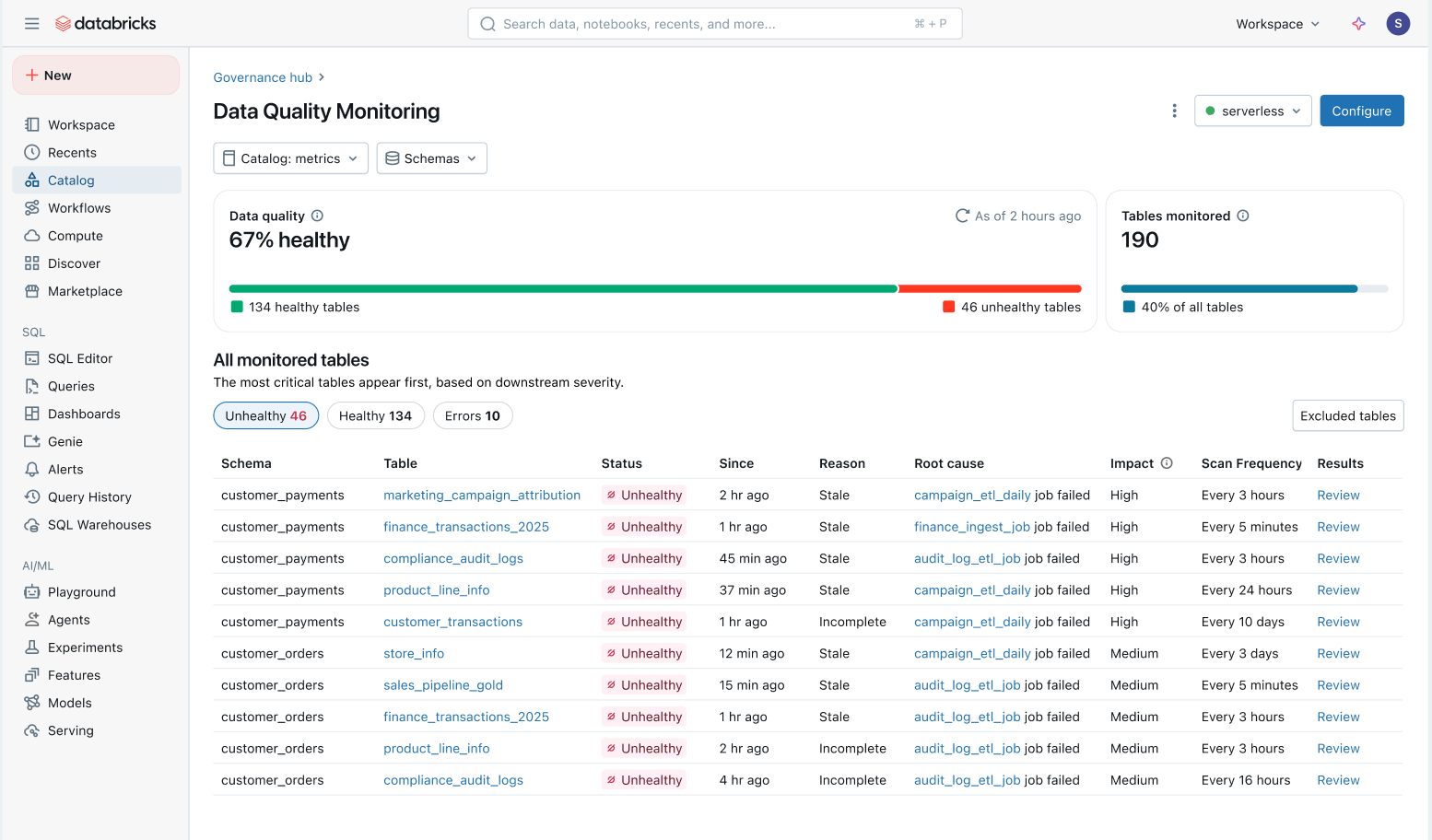
Asegure la calidad de un patrimonio de datos en constante crecimiento
Con el monitoreo de calidad automatizado, los equipos de la plataforma de datos pueden mantenerse al tanto del estado general de sus datos y garantizar la resolución oportuna de cualquier problema.
Monitoreo agéntico con un solo clic: Monitorea esquemas completos sin necesidad de escribir reglas manualmente ni de configurar umbrales. El monitoreo de la calidad de los datos aprende los patrones históricos y los comportamientos estacionales (p. ej., caídas en el volumen durante los fines de semana, temporada de impuestos, etc.) para detectar anomalías de forma inteligente en todas tus tablas.
Vista integral de la salud de los datos: Supervisa fácilmente la salud de todas las tablas en una vista consolidada y asegúrate de que los problemas se solucionen.
- Problemas priorizados por el impacto descendente: Todas las tablas se priorizan en función de su linaje descendente y su volumen de consultas. Los problemas de calidad en sus tablas más importantes se marcan primero.
- Menor tiempo de resolución: En Unity Catalog, el monitoreo de la calidad de los datos rastrea el origen de los problemas directamente hasta los Lakeflow Jobs y las Spark Declarative Pipelines. Los equipos pueden ir desde el catálogo hasta el job afectado para investigar fallas específicas, cambios en el código y otras causas raíz.
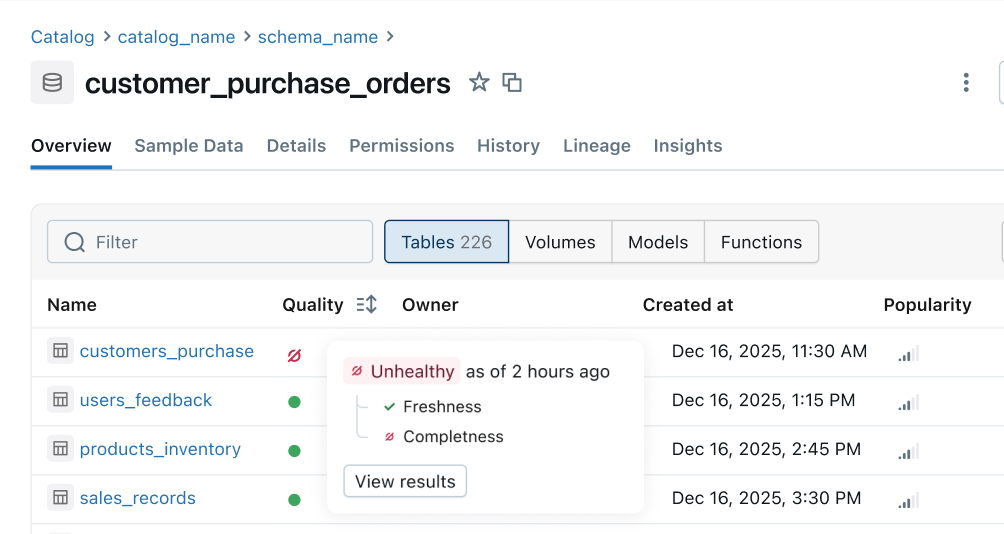
Indicador de estado: Las señales de calidad consistentes se propagan desde las canalizaciones ascendentes a las superficies de negocio descendentes. Los equipos de ingeniería de datos son los primeros en recibir una notificación sobre los problemas y los consumidores pueden saber al instante si los datos son seguros para su uso.
¿Qué sigue?
Esto es lo que incluye nuestra hoja de ruta para los próximos meses:
- Más reglas de calidad: Soporte para más comprobaciones, como el porcentaje de nulos, la unicidad y la validez.
- Alertas automatizadas y análisis de causa raíz: Reciba alertas automáticamente y resuelva problemas rápidamente con indicadores inteligentes de causa raíz integrados directamente en sus trabajos y canalizaciones.
- Indicador de estado en toda la plataforma: Vea señales de estado consistentes en Unity Catalog, Lakeflow Observability, Lineage, Notebooks, Genie, etc.
- Filtre y ponga en cuarentena los datos incorrectos: Identifique proactivamente los datos incorrectos y evite que lleguen a los consumidores.
Primeros pasos: Vista previa pública
Experimente el monitoreo inteligente a gran escala y cree una plataforma de datos confiable y de autoservicio. Pruebe la vista previa pública hoy mismo:
- Habilitar la supervisión de la calidad de los datos desde la pestaña Detalles del esquema en Unity Catalog
- Obtén una vista holística de todas las tablas monitoreadas directamente en el producto.
- Configure alertas con esta plantilla
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.