Desmontando 8 mitos sobre el diseño de datos: por qué Liquid Clustering supera al particionamiento
El diseño de datos para el lakehouse moderno
por Jeffrey Gong, Yu Xu y Rahul Mahadev
- Liquid Clustering es el diseño de datos para formatos de tabla abiertos que supera al particionamiento al tiempo que evita sus limitaciones
- 8 mitos comunes mantienen a los equipos atados al particionamiento, y ninguno de ellos se sostiene ya
- Los clientes que utilizan Liquid Clustering informan mejoras drásticas en la latencia de las consultas, el rendimiento de escritura, la eficiencia del almacenamiento y la frescura de los datos, con las mayores ganancias acumulándose a escala de petabytes
Introducción
Organizar los datos es uno de los problemas más antiguos de la computación.
Durante más de 15 años, desde la llegada de Hadoop y Hive, la partición ha sido la forma estándar de organizar físicamente los datos para su procesamiento y análisis. Sin embargo, los Lakehouses actuales sirven a agentes, pipelines en tiempo real y patrones de consulta que cambian más rápido de lo que cualquier humano puede re-particionar.
Liquid Clustering es el estándar moderno y los clientes lo están ejecutando a todas las escalas, incluyendo docenas con tablas a escala de petabytes en producción. En este blog, cubriremos por qué Liquid Clustering gana en el Lakehouse. A lo largo del camino, desmentiremos 8 mitos comunes sobre la organización de datos, repasaremos 3 historias de éxito de equipos que convierten tablas particionadas a Liquid Clustering, previsualizaremos lo que viene y mostraremos cómo empezar.
Por qué Liquid Clustering gana en el lakehouse moderno
La partición estilo Hive obliga a los usuarios a comprometerse, en el momento de la creación de la tabla, con una organización física de los datos que se manifiesta en la estructura de archivos. Elige una columna con una cardinalidad demasiado alta y obtendrás miles de millones de archivos pequeños. Elige la columna incorrecta y las consultas pueden volverse más lentas, no más rápidas. En cualquier caso, te quedas atascado reescribiendo la tabla. Es común equivocarse: en nuestro análisis, la partición estilo Hive conduce a la sobre-partición y a problemas de archivos pequeños en más del 75% de los casos.
Liquid trata las claves de clúster como una entrada que el motor utiliza para guiar la organización óptima de los archivos. Las claves se pueden cambiar en cualquier momento, o seleccionar inteligentemente a través de Liquid Clustering Automático. La cardinalidad no es una limitación, y la organización puede evolucionar con el tiempo sin reescrituras innecesarias.
Los beneficios de Liquid Clustering se derivan todos del principio anterior: mejor manejo del sesgo, concurrencia a nivel de fila, sin problemas de archivos pequeños, clúster multidimensional y menor amplificación de escritura.
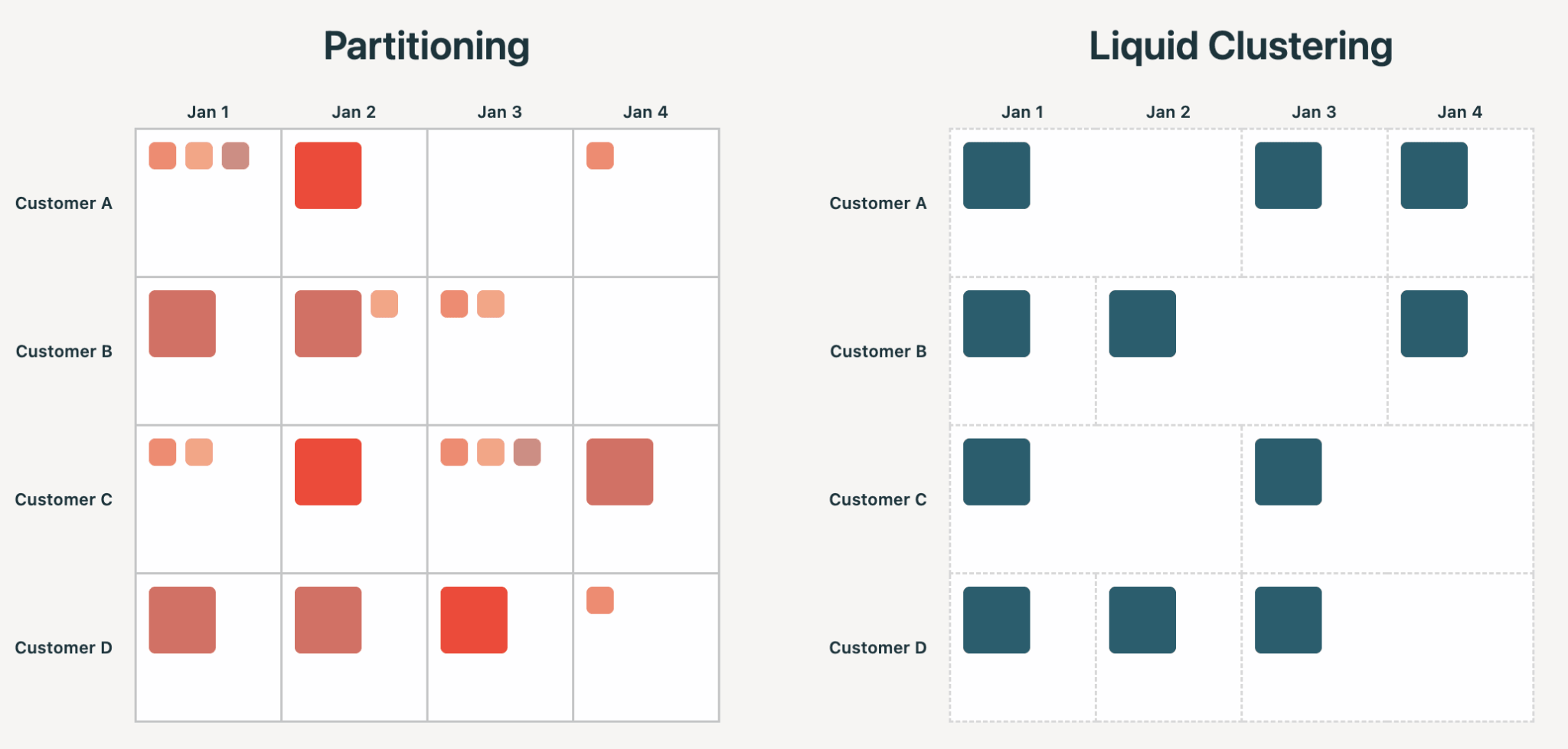
En 2026, la organización de datos debería ser un detalle de implementación de la tabla, y cada motor que lee o escribe se beneficiará de ella. Esto es cada vez más importante a medida que los agentes entran en el Lakehouse, generando y consumiendo más datos que nunca. Los humanos y los agentes necesitan interfaces flexibles, libres de los posibles efectos secundarios de la partición estilo Hive.
Desmintiendo 8 mitos comunes sobre la organización de datos
Liquid Clustering se convirtió en Disponibilidad General en 2024. Desde entonces, lo hemos iterado sin parar con clientes que lo ejecutan a escala. En ese tiempo, han persistido algunos mitos comunes sobre Liquid Clustering y la partición, y hoy queremos desmentirlos.
Mito #1: La partición es más rápida porque puede podar directorios en lugar de archivos
El mito dice: Con la partición, Spark u otros motores pueden podar directorios completos sin abrir ningún archivo dentro de ellos.
Realidad: La poda de directorios no existe en formatos de tabla abiertos modernos como Delta e Iceberg. Delta, por ejemplo, utiliza un registro de transacciones para rastrear cada archivo de datos junto con estadísticas por columna, y la poda se realiza contra esas estadísticas, no contra la estructura del directorio. El motor nunca lista directorios para planificar una consulta. Lee el registro de transacciones, evalúa los filtros contra las estadísticas y omite los archivos que no coinciden. Liquid Clustering utiliza el mismo mecanismo. Ya sea que tus datos residan en `date=x/hour=y/` o en un directorio plano de archivos agrupados, el motor poda a nivel de granularidad de archivo. No hay un atajo a nivel de directorio que perder.
Mito #2: La partición es mejor al filtrar por una columna de baja cardinalidad
El mito dice: Para una columna con un número pequeño de valores distintos, la partición te da una separación de datos perfecta y buenos tamaños de archivo.
Realidad: Liquid Clustering detecta automáticamente cuándo aplicar optimizaciones de baja cardinalidad. Por ejemplo, si agrupas por (date, user_id), y date tiene baja cardinalidad, el sistema apunta a que cada archivo contenga filas de una sola fecha. Las columnas de mayor cardinalidad, como user_id, se utilizan automáticamente para una clasificación más detallada dentro de los archivos de cada fecha, sin tener que depender de otras técnicas de clasificación como Z-Ordering.
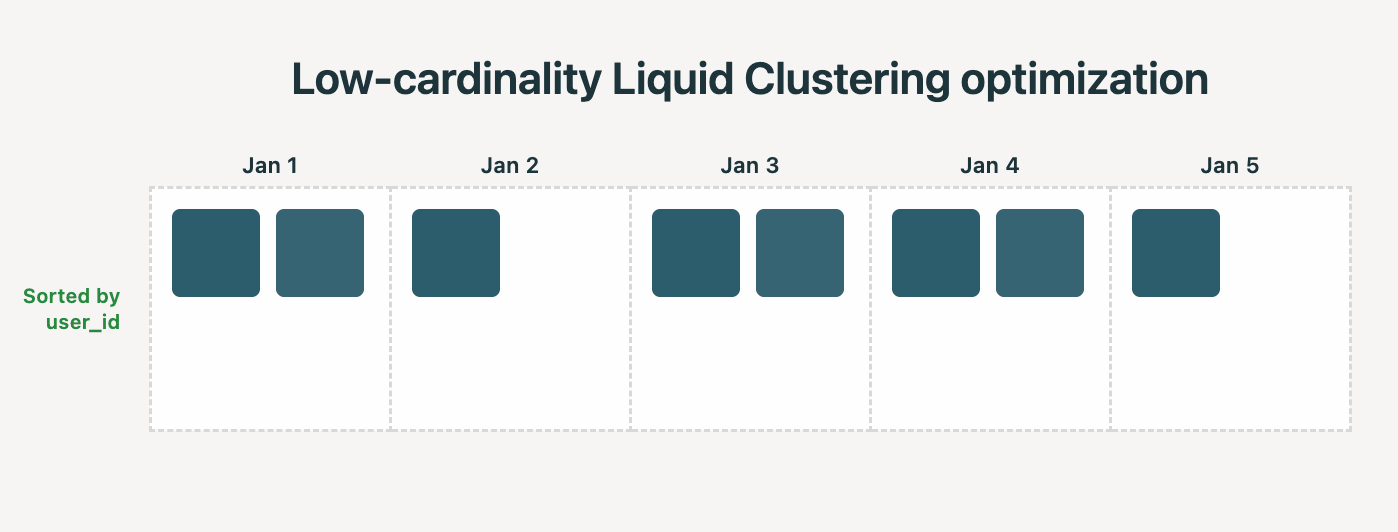
Vimos las siguientes mejoras al evaluar esta optimización de Liquid en un benchmark de data warehousing del mundo real: 35% menos tiempo para la agrupación y 22% tiempos de consulta más rápidos.
Además, Liquid Clustering está diseñado para ser mejor que la partición al agrupar en una columna de alta cardinalidad, ya que siempre intenta crear archivos de buen tamaño.
Mito #3: Liquid Clustering no admite operaciones de solo metadatos
El mito dice: Las operaciones de solo metadatos son soportadas únicamente por la partición. Un DELETE alineado con los límites de la partición solo actualiza los metadatos de la tabla, y los agregados en las columnas de partición se pueden calcular sin escanear archivos. Liquid Clustering no puede hacer lo mismo.
Realidad: Liquid Clustering también admite operaciones de solo metadatos, incluyendo DELETEs, COUNT, DISTINCT y consultas GROUP BY. El motor utiliza las mismas estadísticas min/max por archivo que usa para el salto de datos para determinar cuándo la respuesta de una consulta se puede calcular solo a partir de metadatos. En nuestras pruebas, los DELETEs de solo metadatos en tablas con Liquid Clustering se ejecutaron un ~90% más rápido que los DELETEs de reescritura completa. Otras consultas agregadas de solo metadatos vieron aceleraciones de hasta 27 veces.
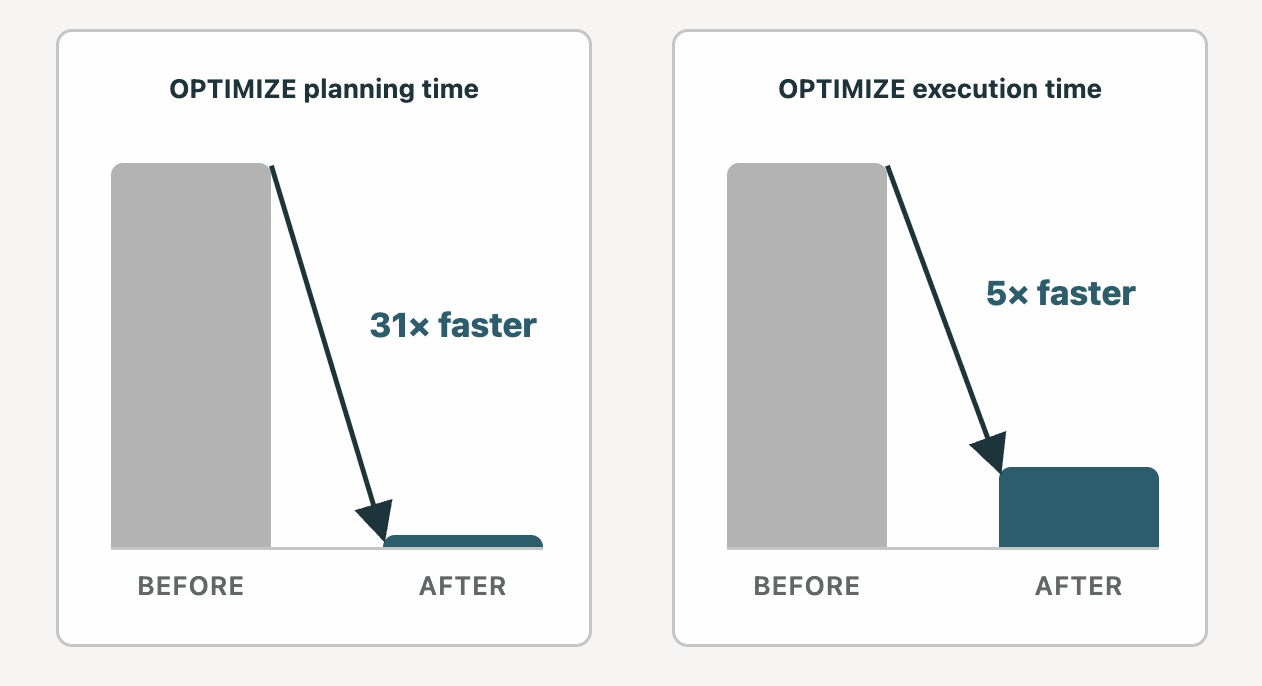
Mito #4: Liquid Clustering no funciona bien a escala de petabytes
El mito dice: OPTIMIZE en una tabla de tamaño PB puede ejecutarse durante horas, y el costo de mantenimiento es demasiado alto.
Realidad: Hemos realizado una serie de mejoras significativas en OPTIMIZE, y docenas de clientes ahora tienen tablas con Liquid Clustering a escala PB en producción. Hace dos años, la planificación, la primera fase de OPTIMIZE, podía llevar hasta 12 horas en una tabla Liquid de 10 PB en algunos casos. Hemos pasado el tiempo desde entonces reduciendo el tiempo de planificación a 23 minutos. La ejecución, la segunda fase de OPTIMIZE, se volvió 5 veces más rápida en un clúster DBSQL Mediano.
Mito #5: Liquid Clustering solo beneficia a un subconjunto de lectores
El mito dice: Liquid Clustering solo es beneficioso para los lectores de Databricks en tablas Delta gestionadas por UC.
Realidad: Liquid Clustering es una optimización del lado de escritura. Es cómo el motor organiza los archivos para un salto de datos eficiente. La salida son archivos Parquet estándar con estadísticas min/max, escritos en formatos de tabla abiertos como Delta/Iceberg. Cualquier lector compatible (por ejemplo, Apache Spark de código abierto, DuckDB, etc.) puede usar esas estadísticas para omitir archivos. Liquid Clustering está disponible tanto en tablas externas/gestionadas como en tablas Delta/ Iceberg, y el beneficio es aplicable independientemente del lector.
Mito #6: La partición es necesaria para ETL concurrente
El mito dice: El ETL concurrente necesita límites de escritura. Sin partición, dos escritores que actualizan la misma tabla corren el riesgo de colisionar, y el control de concurrencia de Delta/Iceberg obliga a uno de ellos a reintentar o fallar. Particiona y dale a cada escritor su propia porción de la tabla, para que dos pipelines nunca toquen los mismos archivos.
Realidad: Operar a nivel de partición era una solución alternativa para un modelo de concurrencia anterior. A diferencia del particionamiento, que solo tiene concurrencia a nivel de archivo, Liquid proporciona concurrencia a nivel de fila. Dos escritores que actualizan filas diferentes ya no entran en conflicto, incluso si esas filas residen en el mismo archivo. Esto elimina una de las principales razones por las que los equipos particionaban tablas: mantener límites de escritura para evitar la serialización. Con Liquid Clustering, ETL puede operar fácilmente de forma concurrente en la misma tabla.
Mito #7: Z-Ordering compensa las deficiencias del particionamiento
El mito dice: El particionamiento maneja los filtros de la columna de partición, y Z-Ordering se encarga del resto. Al ejecutar OPTIMIZE ZORDER BY, el motor ordena los datos para un salto óptimo en los filtros que no se alinean con el esquema de partición.
Realidad: Z-Ordering no salva al particionamiento. De hecho, tiene sus propios problemas estructurales.
- El primero es la mala calidad de agrupación. Z-Order no mantiene un orden real en toda la tabla. Los valores de la misma columna pueden distribuirse en muchos archivos, por lo que los rangos min/max por archivo son más amplios y las consultas saltan menos archivos de los que lo harían con Liquid.
- El segundo son las reescrituras innecesarias. Z-Order debe ejecutarse periódicamente a medida que llegan nuevos datos, y cada ejecución reescribe grandes cantidades de datos antiguos, posiblemente ya agrupados, para restaurar la calidad de la agrupación. Con la ingesta continua, el costo de mantener los datos bien agrupados con Z-Order aumenta junto con la tabla.
Liquid agrupa incrementalmente, incluso en el momento de la escritura, por lo que la disposición se mantiene óptima sin reescrituras innecesarias.
Mito #8: El particionamiento es necesario para sobrescrituras selectivas de datos
El mito dice: La capacidad de sobrescribir datos de forma selectiva solo está disponible a través de Sobrescrituras dinámicas de particiones.
Realidad: Las sobrescrituras selectivas funcionan de forma nativa en tablas Liquid. Databricks admite REPLACE USING y REPLACE ON, dos sintaxis SQL para sobrescribir datos de forma selectiva en cualquier disposición de datos: tablas agrupadas con Liquid, particionadas o sin agrupar. A diferencia de Dynamic Partition Overwrite, que requiere una configuración de Spark, REPLACE USING y REPLACE ON se pueden usar en cualquier cómputo: clústeres clásicos, almacenes SQL y Serverless. La operación es atómica y coincide con cualquier columna que elijas.
Casos de éxito: migración de particionamiento a Liquid Clustering
Aceleración de consultas 7.7x en la tabla de telemetría de seguridad de 3.8 PB de Arctic Wolf
Arctic Wolf ejecuta una tabla de telemetría de seguridad de más de 3.8 PB que ingiere más de 1 billón de eventos al día, donde los cazadores de amenazas dependen de datos actualizados para detectar ataques activos.
Después de migrar del particionamiento a Liquid Clustering en tablas administradas por Unity Catalog con optimización predictiva, Arctic Wolf observó:
- Consultas de 90 días reducidas de 51 segundos a 6.6 segundos
- Número de archivos reducido de 4M a 2M
- Frescura de los datos mejorada de horas a minutos
Mejoras de lectura y escritura en tablas críticas de CDC para Bolt
Bolt probó recientemente Liquid Conversion (actualmente en vista previa privada), que convierte tablas particionadas a Liquid en su lugar utilizando ALTER TABLE .. REPLACE PARTITIONED BY WITH CLUSTER BY. Observaron los siguientes beneficios de lectura y escritura en una tabla de CDC a escala de TB después de convertirla a Liquid Clustering:
- Rendimiento de escritura (filas/seg) aumentado en un 138%
- Tiempos de lectura reducidos hasta en un 63%, con una reducción promedio del 21% en 9 consultas representativas
Liquid Clustering redujo drásticamente el trabajo que realizaba cada escritura, aumentando significativamente nuestro rendimiento en nuestra tabla CDC más crítica. Las lecturas también mejoraron en general. Lo mejor fue que ejecutamos la conversión del particionamiento junto con la ingesta en vivo sin tiempo de inactividad. Con esto, Liquid Clustering nos proporcionó exactamente el tipo de rendimiento y confiabilidad que necesitábamos a escala de plataforma. —Marcin, ingeniero principal de plataforma en Bolt
Aceleración 5.9x en el tiempo de consulta en una carga de trabajo interna a escala de petabytes
Ejecutamos una tabla de 1.1 PB internamente que se consulta miles de veces al día, principalmente por ingenieros que realizan investigaciones de producción y paneles de observabilidad. Originalmente, estaba particionada por fecha y hora, asumiendo que los escaneos de rango de tiempo dominarían. Sin embargo, esa suposición resultó ser incompleta. Si bien los escaneos de rango de tiempo eran comunes, la tabla también se consultaba con frecuencia por fuente e id, lo que obligaba al motor a escanear todos los archivos en las particiones de fecha y hora relevantes para encontrar un puñado de filas.
Agregar fuente e id como particiones no era viable, porque había demasiados valores distintos. Esto habría creado miles de millones de archivos pequeños. Liquid Clustering eliminó la compensación, permitiendo la agrupación por tiempo y las columnas de identificador adicionales simultáneamente, manteniendo un buen tamaño de archivo.
| Disposición | |
|---|---|
| Antes | Particionado por fecha, hora |
| Después | Agrupado por date, hour, source, id |
Las pruebas de rendimiento mostraron mejoras masivas en 16 consultas de producción representativas:
| Métrica | Antes (particionado) | Después (Liquid) | Mejoras |
|---|---|---|---|
| Tiempo de reloj | 406s | 70s | Aceleración 5.9x |
| Bytes leídos | 3.5 TB | 0.48 TB | 86% menos bytes leídos |
La tabla en sí también se redujo. El tamaño total disminuyó de 1.1 PB a 0.8 PB, una reducción del 27% sin cambios en los datos subyacentes. Los archivos mejor agrupados se comprimen de manera más eficiente, y desaparece el impuesto de archivos pequeños que viene con la sobrepartición.
Qué viene a continuación para Liquid Clustering
Optimización de uniones Liquid-a-Liquid: hasta un 51% más rápido con un 87% menos de shuffle
Hoy en día, unir tablas Liquid en sus columnas de agrupación puede requerir un shuffle completo de datos, incluso cuando los datos ya están organizados por esas columnas. Las uniones co-agrupadas (ahora en vista previa privada) eliminan ese shuffle automáticamente. En una prueba de rendimiento de data warehousing del mundo real, una unión Liquid-a-Liquid se ejecutó ~51% más rápido (28 minutos → 14 minutos) y revolvió un 87% menos de datos (1.2 TiB → 150 GiB) que la misma consulta sin la optimización.
Conversión Liquid fácil de tablas particionadas
Anteriormente, convertir una tabla particionada a Liquid Clustering requería una reescritura completa de la tabla y cambios disruptivos posteriores con REPLACE TABLE o un corte con escrituras duales y tiempo de inactividad planificado. Estamos introduciendo un nuevo comando (ahora en vista previa privada) que facilita esta conversión, minimizando tanto el tiempo de inactividad como las reescrituras.
Cómo empezar con Liquid Clustering
Crea una tabla con Liquid Clustering:
O, si estás usando tablas administradas por UC con Optimización Predictiva, usa Liquid Clustering Automático para seleccionar inteligentemente las claves de agrupación según tu carga de trabajo y patrones de consulta:
Liquid Clustering es el diseño para el Lakehouse moderno. Pruébalo en tu próxima tabla, o contacta a tu equipo de cuentas hoy mismo para probar las vistas previas privadas de Conversión de particionado a Liquid y uniones Co-Clustered.
¡No olvides encontrarnos en DAIS!
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.