La arquitectura de Liquid Clustering de Arctic Wolf optimizada para una escala de petabytes
- Arctic Wolf procesa más de 1 billón de eventos de seguridad cada día, lo que genera más de 260 mil millones de observaciones enriquecidas que se mantienen en un Delta Lake a escala de petabytes. Nuestra arquitectura está diseñada para brindar acceso a esos datos casi en tiempo real.
- Recientemente, migramos al uso del clustering líquido en tablas administradas de Unity Catalog con Optimización Predictiva (PO), complementando nuestras tablas externas particionadas con un clustering incremental y adaptado a la carga de trabajo para mejorar el rendimiento de las consultas.
- Juntos, el clustering líquido y la PO mantienen las tablas optimizadas para lograr consultas hasta 8 veces más rápidas y mejorar la actualidad de los datos de horas a minutos.
Todos los días, Arctic Wolf procesa más de un billón de eventos y destila miles de millones de registros enriquecidos para convertirlos en información relevante para la seguridad. Esto se traduce en más de 60 TB de telemetría comprimida, que potencia la detección y respuesta a amenazas impulsadas por IA las 24 horas del día, los 7 días de la semana, sin interrupciones. Para potenciar la búsqueda de amenazas en tiempo real, necesitábamos que estos datos estuvieran disponibles para los clientes y el Centro de Operaciones de Seguridad lo más rápido posible, con el objetivo de que la mayoría de las consultas se completaran en 15 segundos.
Históricamente, hemos tenido que utilizar otros almacenes de datos rápidos para proporcionar acceso a datos recientes, ya que el particionamiento y el orden Z (z-ordering) no daban abasto. Cuando detectamos actividad sospechosa, nuestro equipo puede pivotar inmediatamente en tres meses de contexto histórico para comprender los patrones de ataque, el movimiento lateral y el alcance total de la vulneración. Este análisis histórico en tiempo real sobre más de 3.8 PB de datos comprimidos es fundamental en la búsqueda de amenazas moderna: la diferencia entre contener una brecha en horas en lugar de días puede significar millones en daños evitados.
Cuando cada segundo cuenta, la velocidad y la actualidad de los datos importan. Arctic Wolf necesitaba acelerar el acceso a conjuntos de datos masivos sin aumentar los costos de ingesta ni añadir complejidad. ¿El desafío? Las investigaciones se ralentizaban por la pesada E/S de archivos y los datos obsoletos. Al repensar la forma en que se organizan los datos, nuestra arquitectura gestiona de manera eficiente el sesgo de datos multi-tenant, donde una pequeña fracción de los clientes genera la mayoría de los eventos, al mismo tiempo que admite los datos que llegan con retraso, los cuales pueden aparecer hasta semanas después de la ingesta inicial. Los beneficios medibles incluyen la reducción de la cantidad de archivos de más de 4 millones a 2 millones, la disminución de los tiempos de consulta en ~50 % en todos los percentiles y la reducción de las consultas a 90 días de 51 a solo 6.6 segundos. La actualidad de los datos mejoró de horas a minutos, lo que permite el acceso a la telemetría de seguridad casi de inmediato.
Sigue leyendo para saber cómo el clustering líquido y las tablas administradas de Unity Catalog hicieron esto posible, ofreciendo un rendimiento constante e insights casi en tiempo real a escala.
Cuellos de botella heredados: Por qué Arctic Wolf reconstruyó
Nuestra tabla heredada, particionada por fecha y hora de ocurrencia y con orden Z por identificador de tenant, no se podía consultar casi en tiempo real debido a la gran cantidad de archivos pequeños divididos entre las particiones. Además, los datos solo están disponibles para el período anterior a las últimas 24 horas, ya que tuvimos que ejecutar OPTIMIZE con Z-ordering antes de que se pudieran consultar los datos.
Aun así, persistieron los problemas de rendimiento debido a la llegada tardía de datos. Esto ocurre cuando un sistema se desconecta antes de transmitir los datos, lo que provocaría que los nuevos datos se guardaran en particiones más antiguas y afectara el rendimiento.
Los datos obsoletos nos ciegan. Ese retraso es la diferencia entre contener a un adversario y permitirle moverse lateralmente.
Para mitigar estos desafíos de rendimiento y proporcionar la actualidad de los datos que necesitábamos, duplicamos nuestros datos de acceso frecuente en un acelerador de datos y los combinamos mediante consultas con datos de nuestro Data Lake para satisfacer nuestros requisitos de negocio. El funcionamiento de este sistema era costoso y su mantenimiento requería un esfuerzo de ingeniería considerable.
Para abordar estos desafíos de usar un acelerador de datos, rediseñamos nuestro diseño de datos para distribuir los datos de manera uniforme y admitir datos de llegada tardía. Esto optimiza el rendimiento de las consultas y permite el acceso casi en tiempo real para los casos de uso actuales y emergentes de IA agéntica.
Construcción de la base para datos en streaming con clustering líquido
Con nuestra nueva arquitectura, nuestro objetivo principal es poder consultar los datos más recientes y ofrecer un rendimiento de consulta consistente para clientes de diferentes tamaños, con consultas que se resuelven en segundos.
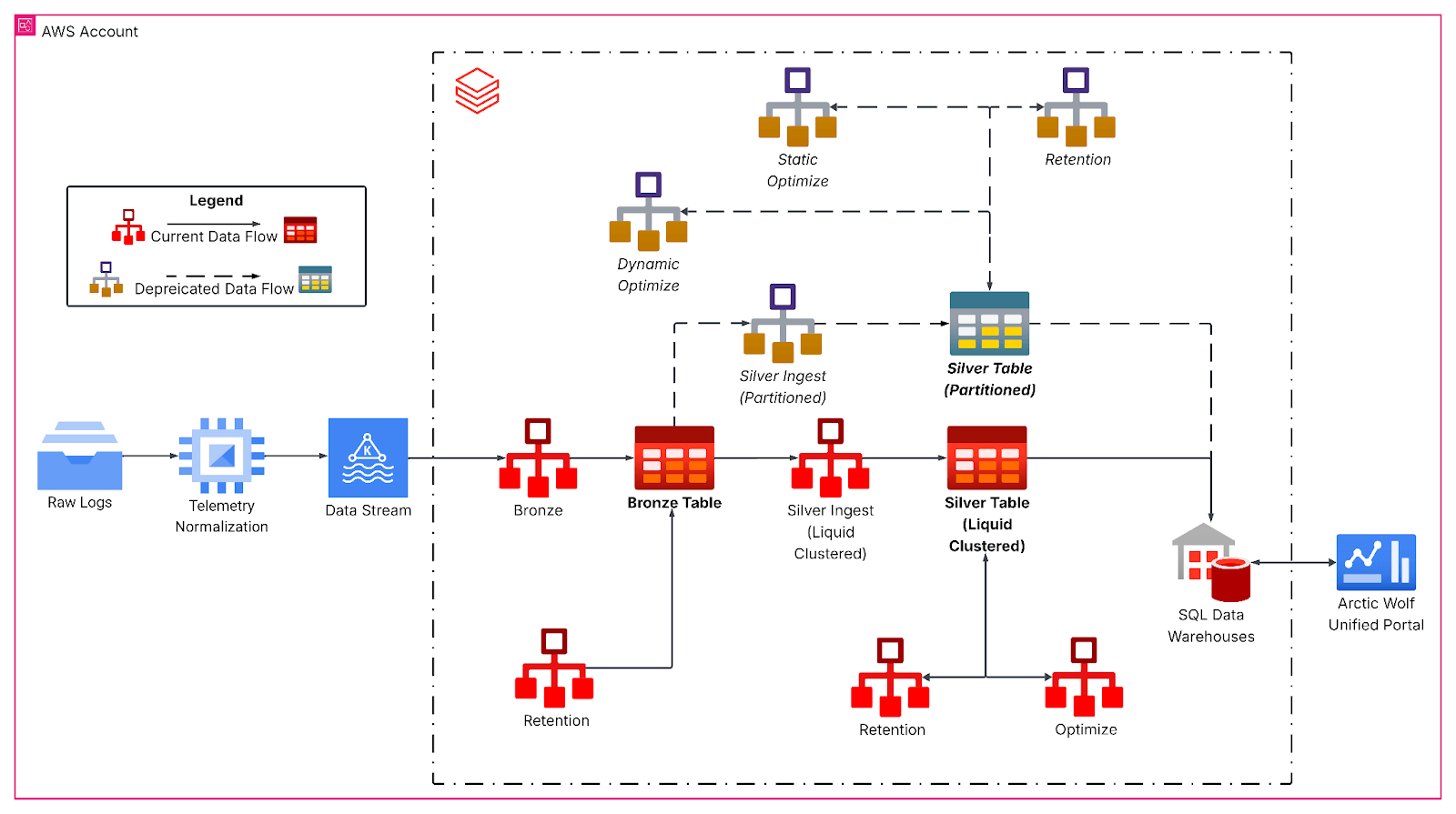
El pipeline rediseñado sigue una arquitectura medallion, que comienza con la ingesta continua de Kafka en una capa de bronce para los datos de eventos brutos. Luego, los trabajos de streaming estructurado por hora aplanan las cargas útiles de JSON anidadas y escriben en las tablas silver con liquid clustering, lo que forma la base analítica principal. Aquí, las transformaciones de bronze a silver gestionan la evolución del esquema, generan columnas temporales derivadas y preparan los datos para las cargas de trabajo analíticas posteriores con SLA de latencia estrictos.
El clustering líquido reemplazó los esquemas de particionamiento rígidos por claves de clustering multidimensionales y adaptadas a la carga de trabajo, alineadas con los patrones de consulta; específicamente, por identificador de inquilino y granularidad de fecha, tamaño de la tabla y características de llegada de los datos. Hacer que los datos se distribuyeran de manera más uniforme, en nuestro caso, aumentó el tamaño promedio de los archivos a más de 1 GB, lo que redujo drásticamente la cantidad de archivos escaneados durante las consultas típicas con ventana de tiempo para nuestra tabla.
Análisis detallado: Clustering en la escritura
Además, nuestros trabajos de structured streaming aprovechan el clustering en la escritura para mantener el diseño de los archivos a medida que llegan nuevos datos. Funciona como una operación OPTIMIZE localizada, que aplica el clustering solo a los datos recién incorporados. Así, los datos incorporados ya están optimizados. Sin embargo, si los lotes de ingesta son demasiado pequeños, producen muchos archivos pequeños pero bien agrupados que aun así necesitan agruparse durante una operación OPTIMIZE global para lograr un diseño de datos ideal. En cambio, si el tamaño del lote en la ingesta se acerca al tamaño del lote necesario para la optimización global, a menudo no es necesaria una optimización adicional.
Para las cargas de trabajo que ingieren volúmenes de datos muy grandes (p. ej., terabytes), recomendamos el procesamiento por lotes en el origen, como el uso de foreachBatch con maxBytesPerTrigger, para garantizar una agrupación en clústeres y un diseño de archivos eficientes. Con maxBytesPerTrigger, podemos controlar el tamaño del lote, lo que elimina muchas islas pequeñas agrupadas que requerirían conciliación a través de la operación OPTIMIZE. Con tamaños cercanos a aquellos con los que trabaja la operación OPTIMIZE, pudimos crear lotes óptimos para reducir aún más el trabajo que necesita OPTIMIZE.
Impacto en Security Analytics de Arctic Wolf
La migración de Arctic Wolf a Liquid Clustering aportó mejoras sustanciales y cuantificables en el rendimiento, la actualidad de los datos y la eficiencia operativa. UC Managed Tables con Predictive Optimization también redujo la necesidad de programar mantenimiento.
El número de archivos se redujo de más de 4 millones a 2 millones, lo que minimizó la E/S de archivos durante las consultas y, al mismo tiempo, mantuvo una buena calidad del clúster. Como resultado, el rendimiento de las consultas mejoró drásticamente, lo que permite a los analistas de seguridad investigar incidentes más rápido: un ~50 % más rápido en todos los percentiles y un ~90 % más rápido para un gran número de nuestros clientes, con consultas de 90 días que pasaron de 51 segundos a 6,6 segundos.
Al implementar el clustering en la escritura, redujimos la actualidad de los datos de horas a minutos, lo que aceleró el tiempo para la obtención de insights en aproximadamente un ~90 %. Esta mejora permite la detección de amenazas casi en tiempo real en el Data Lake de Arctic Wolf.
La transición a liquid clustering y a las tablas administradas de Unity Catalog eliminó el particionamiento heredado, redujo la deuda técnica y desbloqueó funciones avanzadas de gobernanza y rendimiento. Con una arquitectura capaz de procesar y consultar más de 260 mil millones de filas al día, ofrecemos un acceso más rápido y eficiente a los datos de seguridad críticos de todas estas fuentes. En combinación con nuestro equipo Concierge Security® 24/7 y la detección de amenazas en tiempo real, esto permite una respuesta y mitigación de amenazas más rápida y precisa. Estos diferenciadores ayudan a nuestros clientes a lograr una postura de seguridad más sólida y ágil, y a tener una mayor confianza en la capacidad de Arctic Wolf para proteger sus entornos y respaldar el éxito continuo de su negocio.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.