La evolución de la ingeniería de datos: cómo la computación sin servidor está transformando los notebooks, los trabajos de Lakeflow y las canalizaciones declarativas de Apache Spark
Descubra cómo el proceso informático sin servidor de Databricks proporciona una simplicidad, un rendimiento y una fiabilidad inigualables para Notebooks, Lakeflow Jobs y Spark Declarative Pipelines.
por Aaron Davidson, Ihor Leshko, Justin Breese, Piyush Singh, Vivek Narasimhan, Prashanth Babu Velanati Venkata, Roland Fäustlin, Hemant Saxena y Mostafa Mokhtar
- El proceso informático sin servidor para Notebooks, Lakeflow Jobs y Spark Declarative Pipelines elimina la necesidad de administrar la infraestructura y las actualizaciones de Spark.
- El proceso informático sin servidor está mejorando automáticamente las cargas de trabajo y ha mejorado el rendimiento en un 80 % y la rentabilidad hasta en un 70 % durante el último año sin necesidad de intervención del usuario.
- El proceso informático sin servidor es ahora el producto informático más estable de Databricks, que dimensiona automáticamente los clústeres para adaptarse a los crecientes volúmenes de datos y protege las cargas de trabajo de las interrupciones y la falta de existencias en la nube, lo que da como resultado un 89 % más de ejecuciones exitosas.
La ingeniería de datos ha llegado a un punto de inflexión. A medida que las organizaciones dependen cada vez más de la IA y el aprendizaje automático para impulsar las decisiones empresariales, la complejidad de la gestión de la infraestructura de computación se ha convertido en un cuello de botella crítico. Los avances en la computación sin servidor de Databricks ayudan a los equipos a ahorrar hasta un 20 % de su tiempo en tareas rutinarias, como la actualización de las versiones de Databricks Runtime (DBR), la gestión de la configuración de los clústeres y la solución de problemas de infraestructura. Hoy, nos complace compartir varios lanzamientos de funciones recientes para la computación sin servidor de Databricks y cómo ha transformado fundamentalmente el paradigma al proporcionar una simplicidad, un rendimiento y una fiabilidad inigualables para los Notebooks, los Lakeflow Jobs y las Spark Declarative Pipelines (SDP, formalmente conocidas como DLT). Por ejemplo, la computación sin servidor ofrece un ahorro de costes del 70 % con el modo de rendimiento Standard en comparación con las cargas de trabajo optimizadas para el rendimiento, y más de un 50 % de ahorro de costes para las cargas de trabajo que no son de Apache Spark. Además, las cargas de trabajo optimizadas para el rendimiento se inician en segundos y, por lo general, se ejecutan dos veces más rápido. Versionless ha ejecutado 25 actualizaciones de DBR en más de 4500 millones de cargas de trabajo con una extraordinaria tasa de éxito del 99,998 % en el último año.
El desafío de la gestión de la infraestructura es real
Toda plataforma de ingeniería de datos debe gestionar un amplio conjunto de responsabilidades operativas para mantener los clústeres de Apache Spark tradicionales, como:
- Las redes deben configurarse con VPC, puertas de enlace, rangos de direcciones IP y puntos de conexión privados.
- La seguridad y el cumplimiento requieren una atención cuidadosa a la gestión de vulnerabilidades, el cifrado y la protección contra la filtración de datos.
- Las consideraciones de eficiencia, como el dimensionamiento de instancias, la utilización, los grupos de instancias y la optimización de Delta, son esenciales para ejecutar un entorno de datos sólido.
- El mantenimiento de los runtimes actualizados con las últimas mejoras de rendimiento es otro aspecto importante de las operaciones de la plataforma. Con dos versiones de soporte a largo plazo de DBR cada año, es normal que los equipos evalúen las actualizaciones cuidadosamente para garantizar la estabilidad, el rendimiento y la compatibilidad con sus cargas de trabajo.
La computación sin servidor ofrece un modelo operativo diferente: las tareas fundamentales, como las redes y los rangos de IP, el refuerzo de la seguridad, la gestión del ciclo de vida y las actualizaciones del runtime, se gestionan automáticamente y se optimizan continuamente. Esto permite a los equipos adoptar las últimas optimizaciones antes y dedicar más tiempo a la creación de productos de datos y a la entrega de valor empresarial en lugar de a la gestión de la infraestructura.
Computación sin servidor: sencilla, de alto rendimiento y sin mantenimiento
La computación sin servidor de Databricks es una computación gestionada por Databricks que no requiere intervención, se optimiza automáticamente y aborda estos desafíos a través de tres principios básicos:
- Sencilla: solo tiene que elegir si desea que la carga de trabajo se ejecute rápido (modo optimizado para el rendimiento) o de forma rentable (modo estándar). Databricks se ajusta constante y automáticamente para lograr el objetivo seleccionado. No se necesitan mandos, tipos de instancia ni selección de factor de escala.
- De alto rendimiento: respaldada por la infraestructura optimizada de Databricks y un nuevo escalador automático, la computación sin servidor se inicia en segundos, carga las bibliotecas dependientes en segundos desde la caché y, por lo general, se ejecuta dos veces más rápido que los clústeres clásicos.
- Sin mantenimiento: Databricks sin servidor escala automáticamente su computación horizontal y verticalmente para evitar problemas de falta de memoria, lo protege de las interrupciones de la nube y conmuta por error a los tipos de instancia disponibles, lo que resulta en un alto grado de tolerancia a fallos. También es versionless, actualizándolo automáticamente a las últimas mejoras de rendimiento mientras se mantiene totalmente compatible con versiones anteriores.
Serverless es simple
Rendimiento y eficiencia listos para usar
Con la computación sin servidor para Notebooks, Spark Declarative Pipelines y Lakeflow Jobs, Databricks selecciona automáticamente la infraestructura adecuada para su carga de trabajo y, a continuación, la optimiza continuamente en función de la información histórica de la carga de trabajo. Por lo tanto, los usuarios ya no tienen que seleccionar tipos de instancia específicos, configuración de escalado automático u optimizaciones, como Photon. Nuestra IA detecta automáticamente qué infraestructura y configuración beneficiarían más a la carga de trabajo y las habilita automáticamente, por ejemplo, Photon solo se usa cuando la carga de trabajo específica se beneficia de la aceleración de Photon.
Para las cargas de trabajo que no requieren Apache Spark, nuestra selección automática de infraestructura garantiza que, cuando no se necesita Apache Spark, se aprovisione una VM más pequeña sobre la marcha. Este enfoque puede ofrecer más de un 50 % de ahorro de costes y un inicio más de un 33 % más rápido en comparación con los clústeres clásicos, simplemente utilizando solo los recursos que realmente necesita.
La introducción de modos de rendimiento para Lakeflow Jobs y Spark Declarative Pipelines representa un avance significativo en la optimización de la computación, ya que permite a los usuarios expresar para qué debe optimizar Databricks. El modo optimizado para el rendimiento se inicia en segundos y se ejecuta normalmente dos veces más rápido que los clústeres clásicos. Este modo aprovecha los grupos de máquinas en caliente y el escalado de recursos agresivo para minimizar el tiempo de procesamiento, lo que lo hace ideal para cargas de trabajo interactivas y sensibles al tiempo.
El modo estándar, que está disponible con carácter general desde julio, adopta un enfoque diferente. Al optimizar la rentabilidad en lugar de la velocidad pura, ofrece hasta un 70 % de ahorro de costes en comparación con el modo optimizado para el rendimiento, al tiempo que mantiene un rendimiento competitivo. Este modo es perfecto para cargas de trabajo por lotes, trabajos programados y canalizaciones en las que una latencia de inicio de 4 a 6 minutos es aceptable a cambio de importantes reducciones de costes.
Los modos de rendimiento permiten a los usuarios centrarse en la información de datos y las necesidades empresariales específicas de su caso de uso, en lugar de gestionar la infraestructura. Esta simplicidad permite a los usuarios dedicar más tiempo a generar información a partir de los datos. Tenga en cuenta que la computación sin servidor en los notebooks interactivos siempre se inicia en segundos y se ejecuta rápidamente para aprovechar al máximo el tiempo de los usuarios.
| Modo de computación sin servidor | Rendimiento típico | Ventajas clave |
|---|---|---|
| Modo interactivo para Notebooks La mejor experiencia sin servidor para la ciencia de datos, plataforma totalmente gestionada para Databricks Notebooks | < 10 segundos de inicio, escalado rápido |
|
| Modo optimizado para el rendimiento para Lakeflow Jobs y SDP La mejor experiencia sin servidor para la ingeniería de datos, con un inicio y una ejecución rápidos para Lakeflow Jobs y SDP sensibles al tiempo | < 1 minuto de inicio, escalado rápido |
|
| Modo estándar para Lakeflow Jobs y Pipelines Experiencia sin servidor de menor coste, plataforma totalmente gestionada para ejecutar Jobs y SDP | 4-6 minutos de inicio, escalado conservador |
|
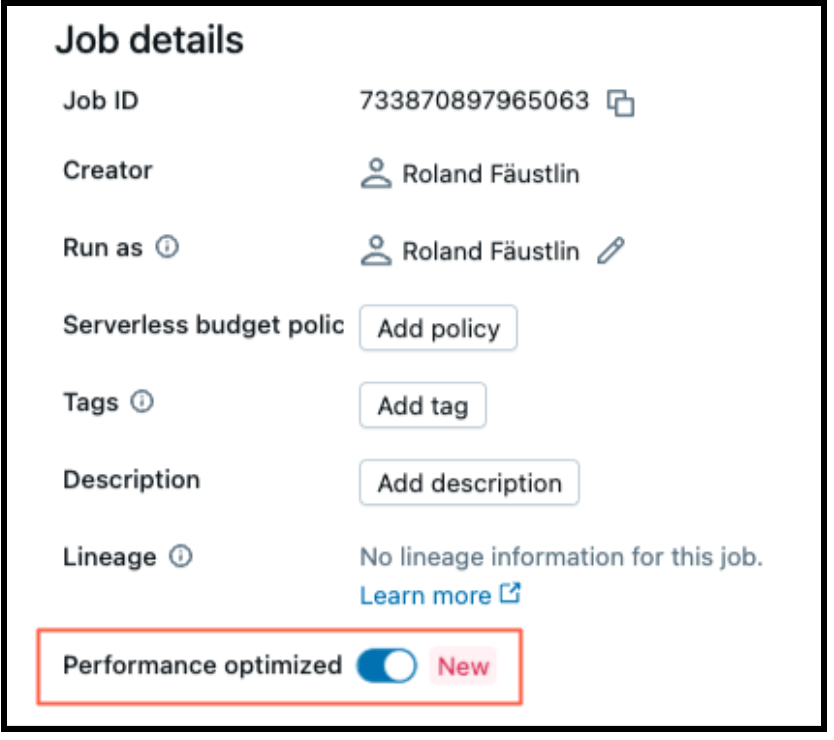
La computación sin servidor hace que sea tan fácil de ajustar para el rendimiento o la eficiencia como accionar un interruptor. Cuando "Optimizado para el rendimiento" está habilitado, sus cargas de trabajo se iniciarán y ejecutarán más rápido. Cuando está deshabilitado, sus cargas de trabajo se ejecutarán en modo "Estándar", optimizando la eficiencia.
Gestión y gobernanza integrales de los costes
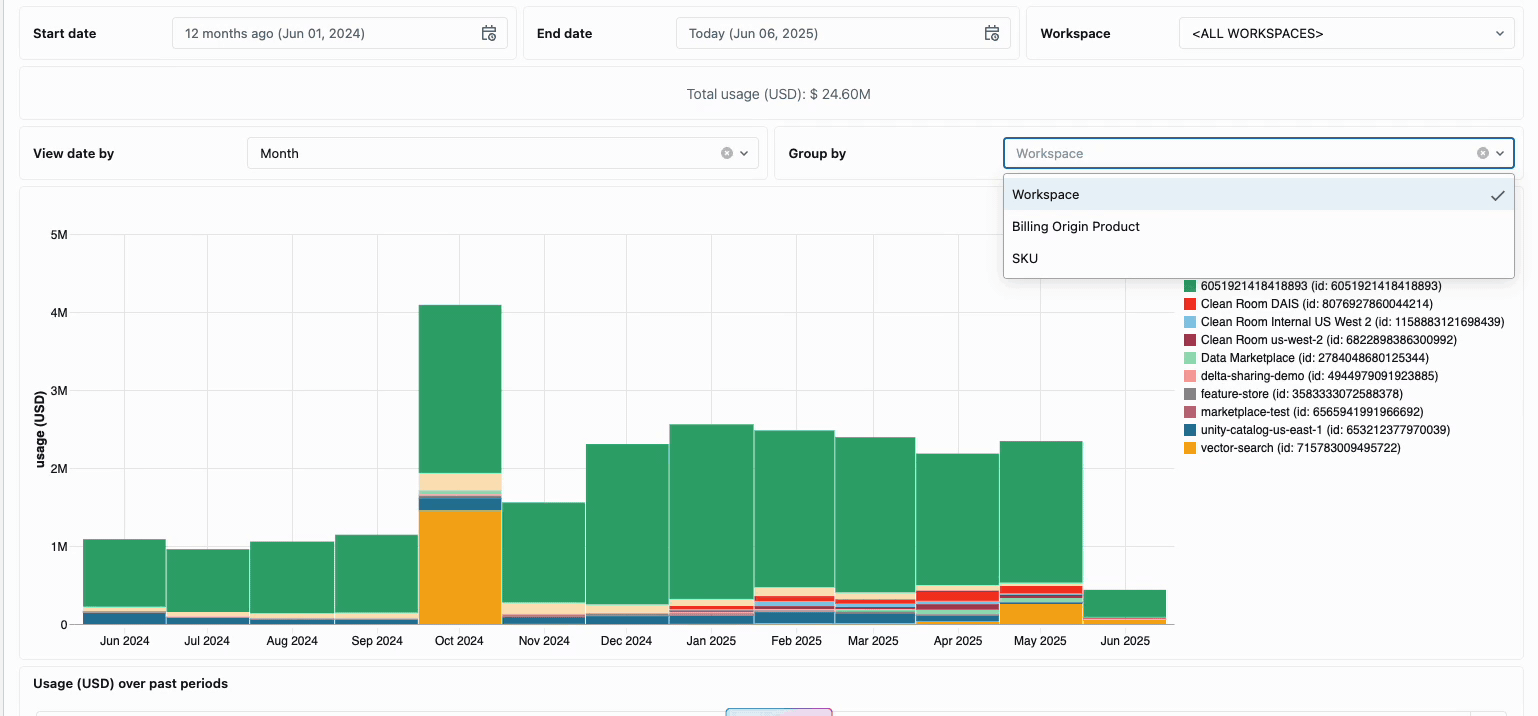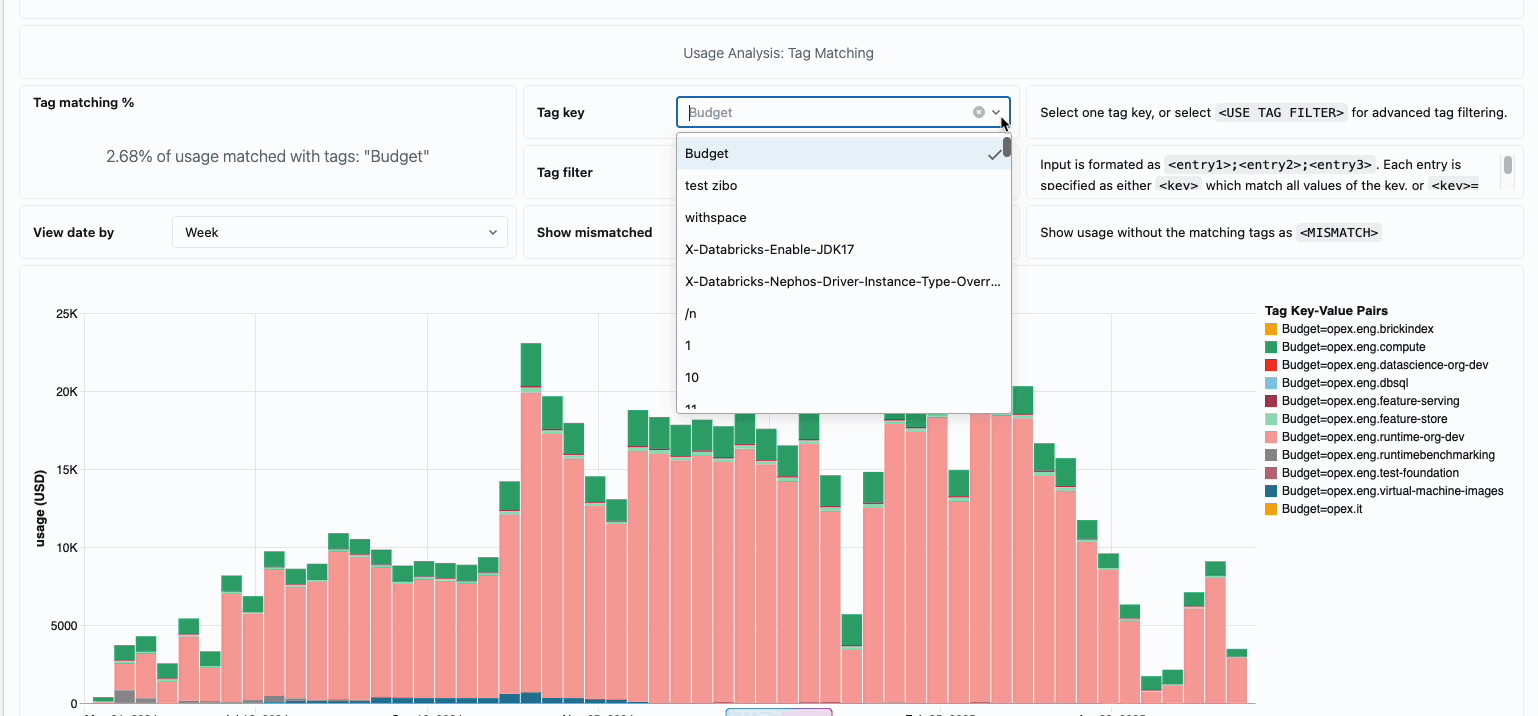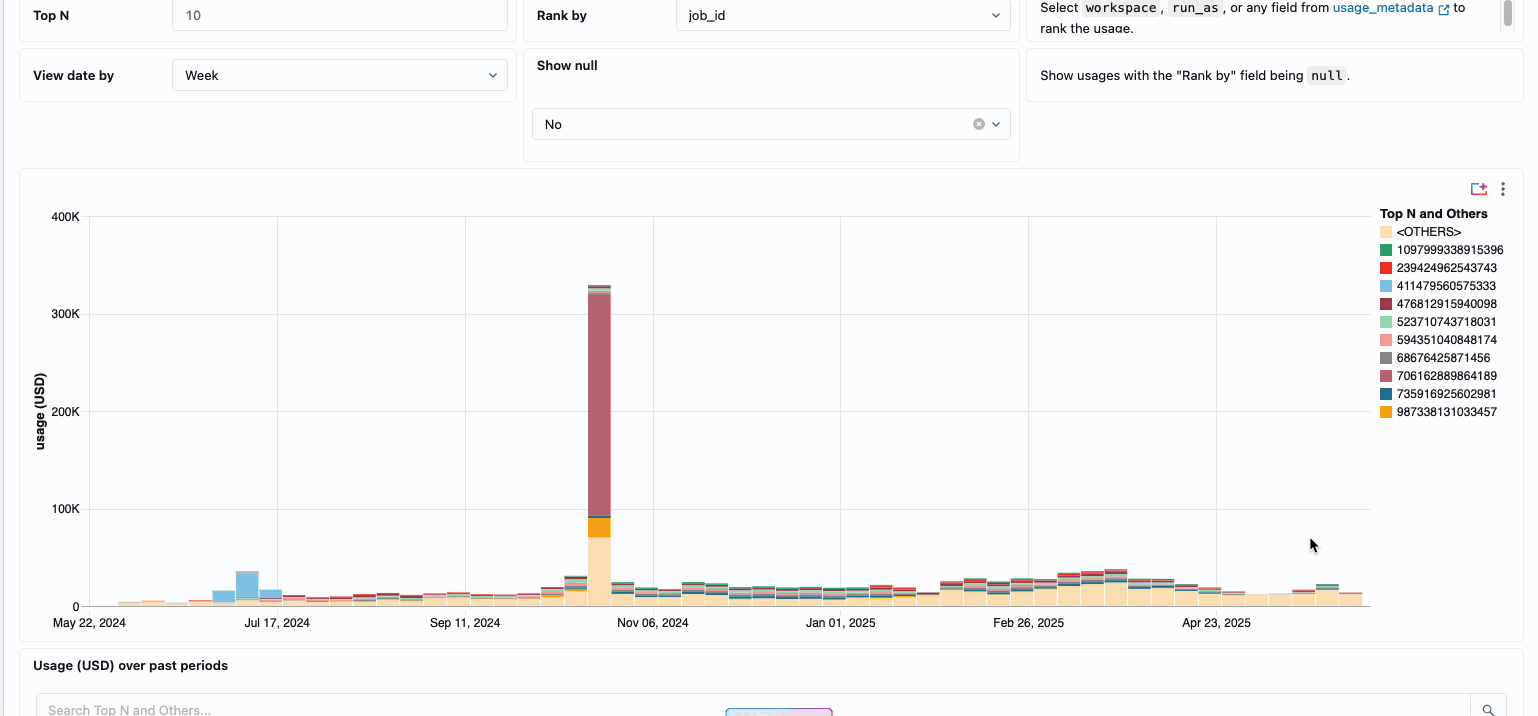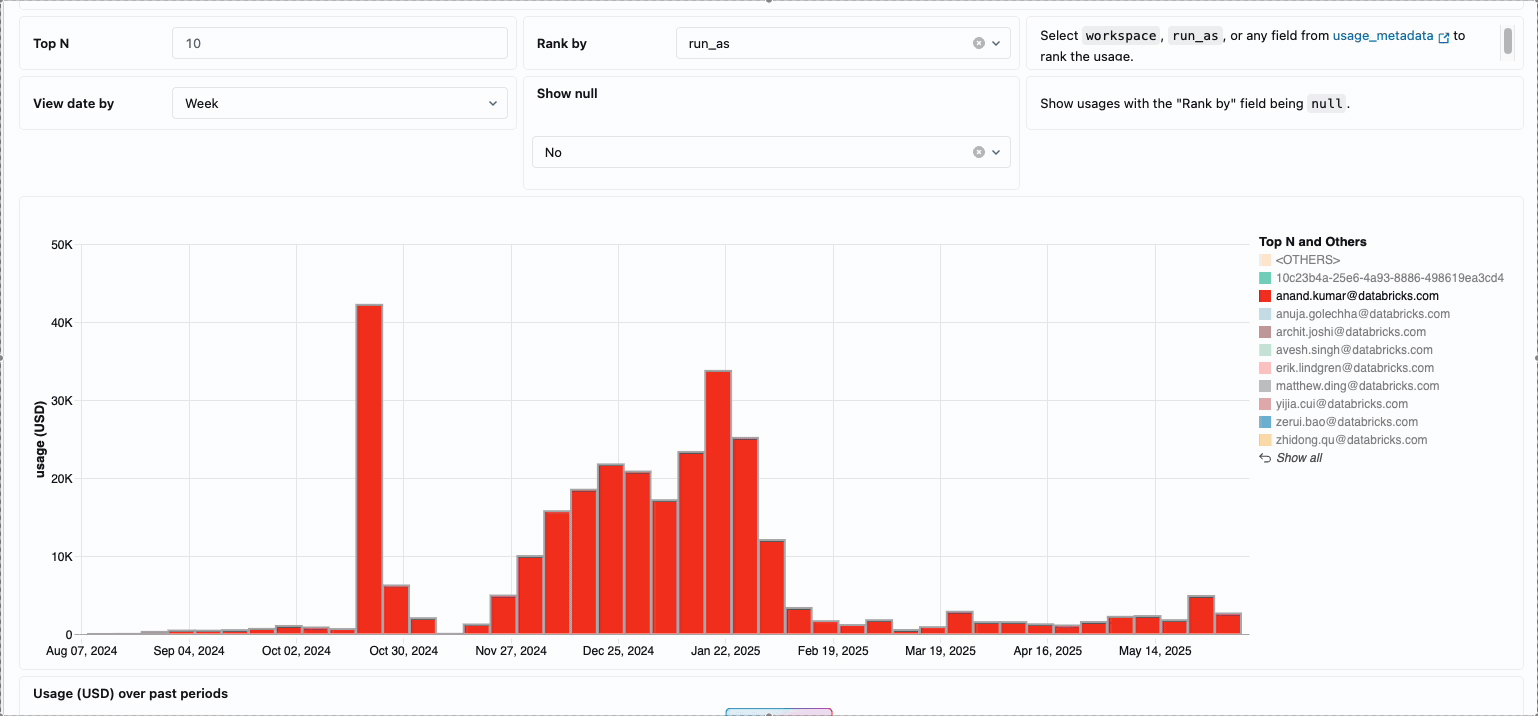
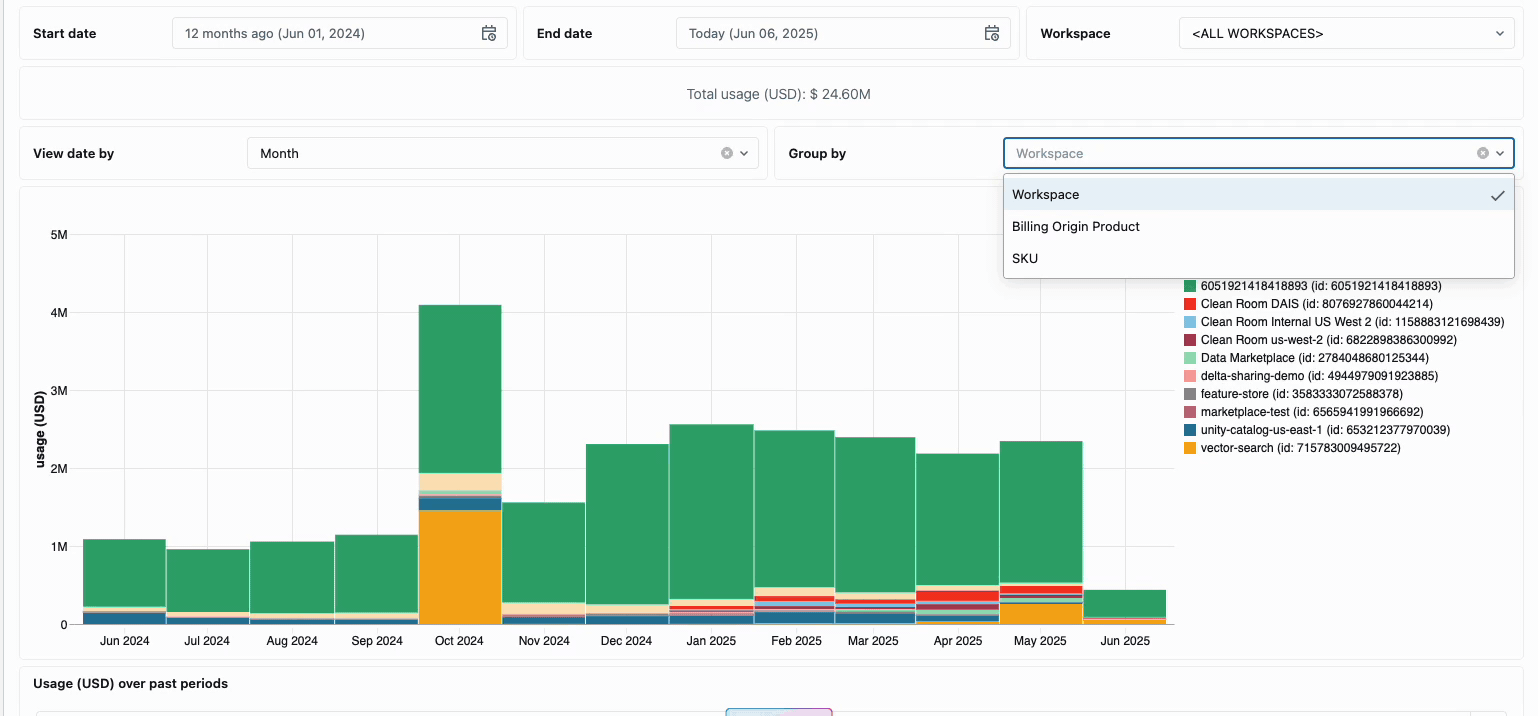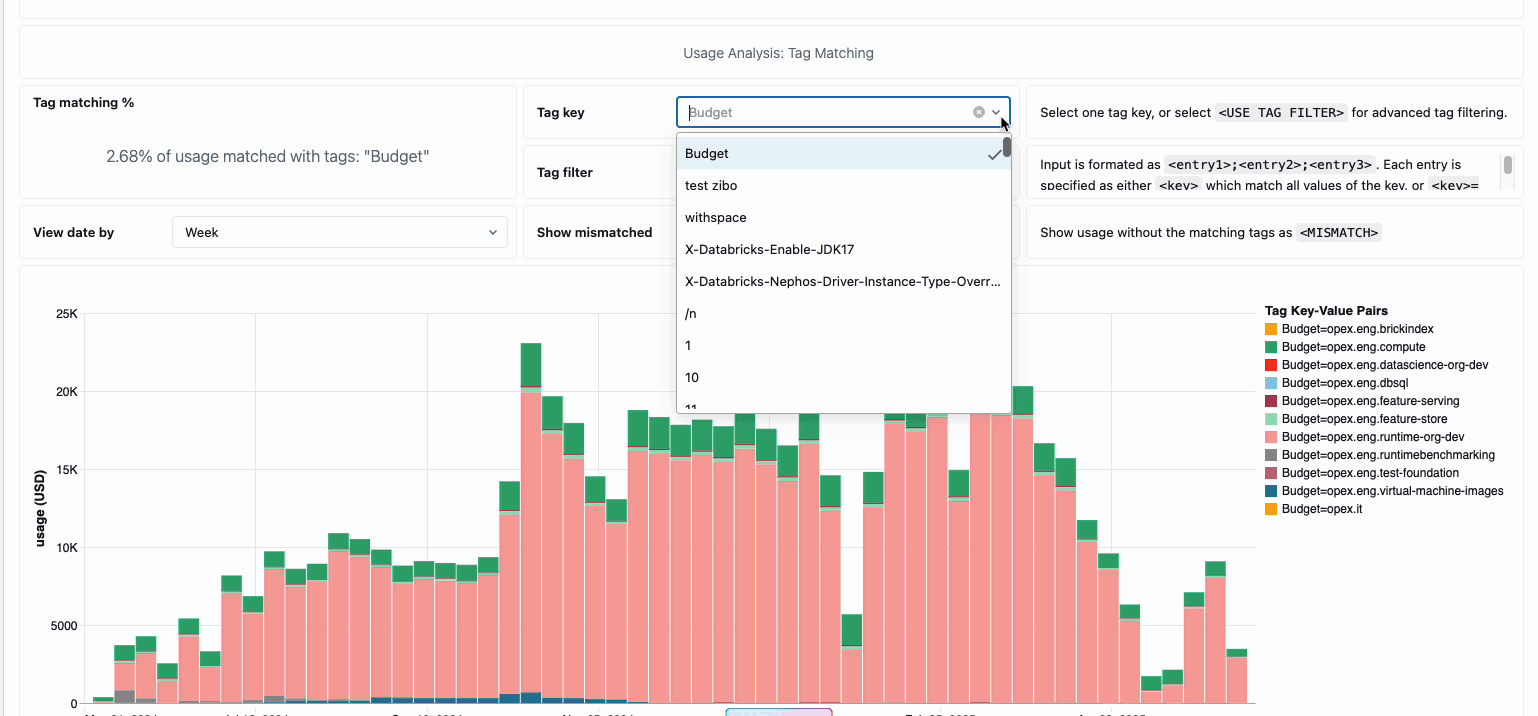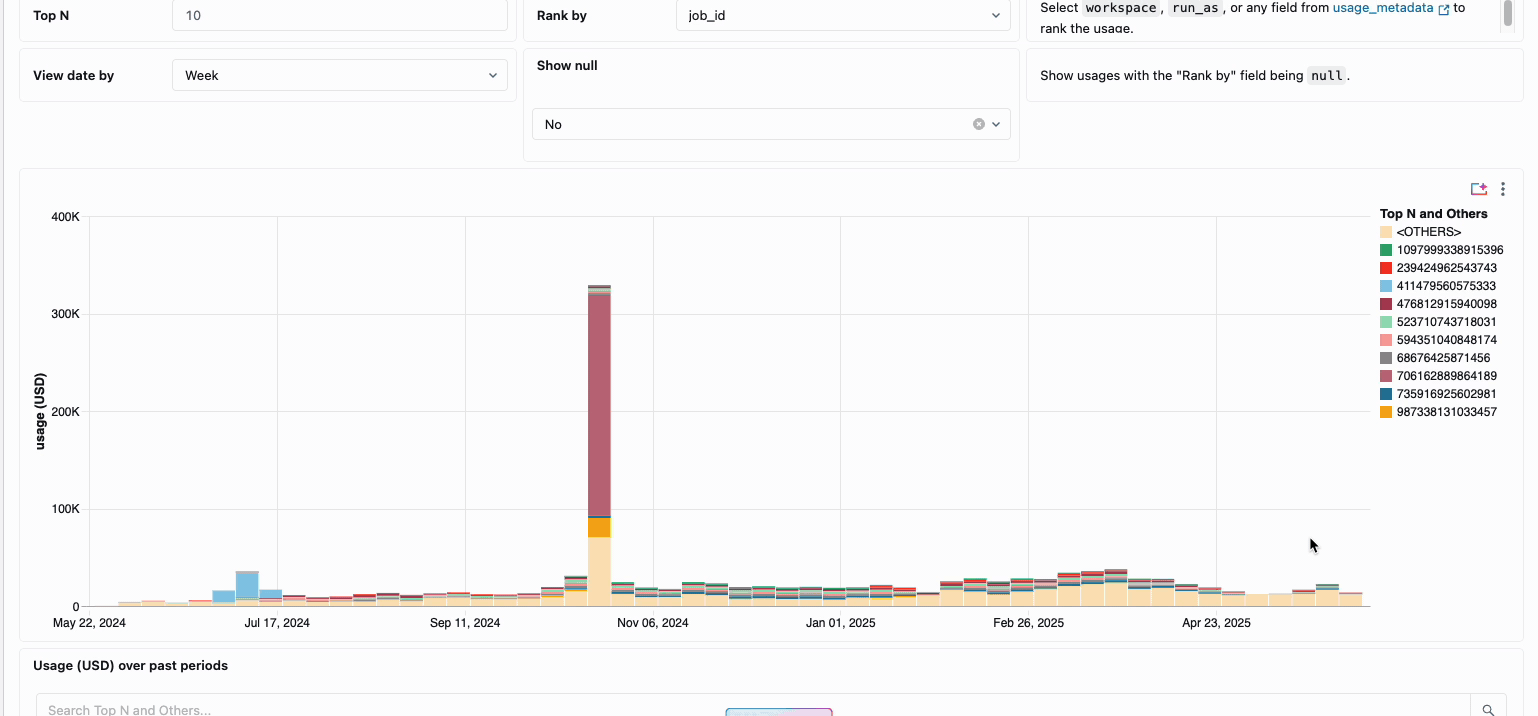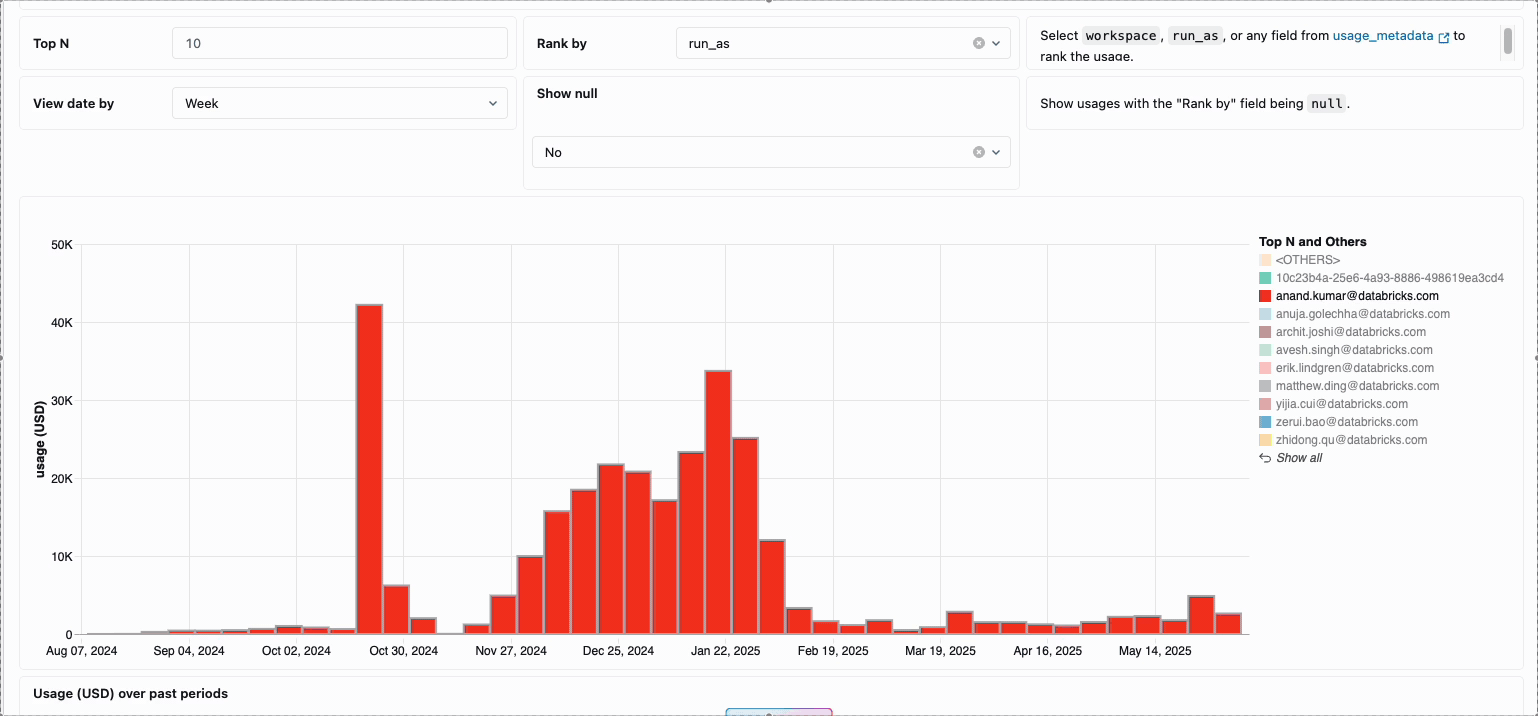
La gestión de los costes de computación en los equipos de ingeniería de datos distribuidos tradicionalmente ha requerido la unión de fuentes de datos dispares y componentes de facturación, un proceso que requiere mucho tiempo y que a menudo oscurece el coste total real de propiedad. La computación sin servidor transforma esta complejidad en claridad a través de la facturación unificada, consolidando todos los componentes de coste en una única vista comprensible. Los administradores obtienen visibilidad instantánea a través de paneles de presupuesto preconstruidos y consultas personalizables construidas en tablas del sistema, eliminando así la necesidad de trabajo de conciliación manual entre diferentes proveedores de servicios.
Para las organizaciones que requieren contracargos internos, las políticas de uso sin servidor permiten la aplicación de etiquetas que agregan automáticamente los costes por equipo o proyecto, lo que garantiza una atribución y responsabilidad precisas en todas las unidades de negocio. La plataforma también proporciona múltiples capas de protección contra el gasto accidental: los tiempos de espera inteligentes evitan que las consultas descontroladas agoten los presupuestos, mientras que las políticas de uso granulares dan a los administradores un control preciso sobre quién puede acceder a la computación sin servidor y a qué velocidad pueden consumir recursos, creando un marco de gobernanza integral que equilibra la innovación con la responsabilidad fiscal.
{kind=link}
Serverless: diseñado para el rendimiento
El almacenamiento en caché del entorno elimina la sobrecarga de la instalación de dependencias
Las configuraciones de computación tradicionales a menudo se basan en pasos de instalación para preparar el entorno adecuado para cada ejecución, especialmente cuando los equipos tienen diversas necesidades de biblioteca. La computación sin servidor cambia esto mediante el uso del almacenamiento en caché inteligente del entorno. Los usuarios definen su entorno una vez, y Databricks analiza, descarga e instala automáticamente las bibliotecas necesarias, luego crea una instantánea y la almacena en caché. Las ejecuciones futuras cargan el entorno desde la caché en segundos, sin necesidad de descargas ni instalaciones. Esto es especialmente útil para cargas de trabajo pequeñas y es, de media, 2 veces más rápido. Los nuevos entornos base predeterminados permiten a los administradores gestionar de forma centralizada los entornos preconfigurados para diferentes equipos, lo que simplifica los flujos de trabajo para los analistas, los científicos de datos y los ingenieros de ML.
El inicio es una prioridad para nosotros, y los Notebooks y flujos de trabajo sin servidor han marcado una gran diferencia. La computación sin servidor para notebooks lo hace fácil con un solo clic.—Chiranjeevi Katta, ingeniero de datos en Airbus
Las Spark Declarative Pipelines sin servidor reducen a la mitad los tiempos de ejecución sin comprometer los costes, mejoran la eficiencia de la ingeniería y agilizan las operaciones de datos complejas, lo que permite a los equipos centrarse en la innovación en lugar de en la infraestructura tanto en los entornos de producción como en los de desarrollo. —Cory Perkins, ingeniero sénior de datos e IA en Qorvo
En la práctica, en todas las cargas de trabajo en Databricks, vemos que la computación sin servidor es, de media, un 20 % más rentable que las cargas de trabajo de clústeres clásicos comparables, y aunque los clientes pagan a su proveedor de nube por el inicio de los clústeres clásicos, Databricks no cobra por el inicio.
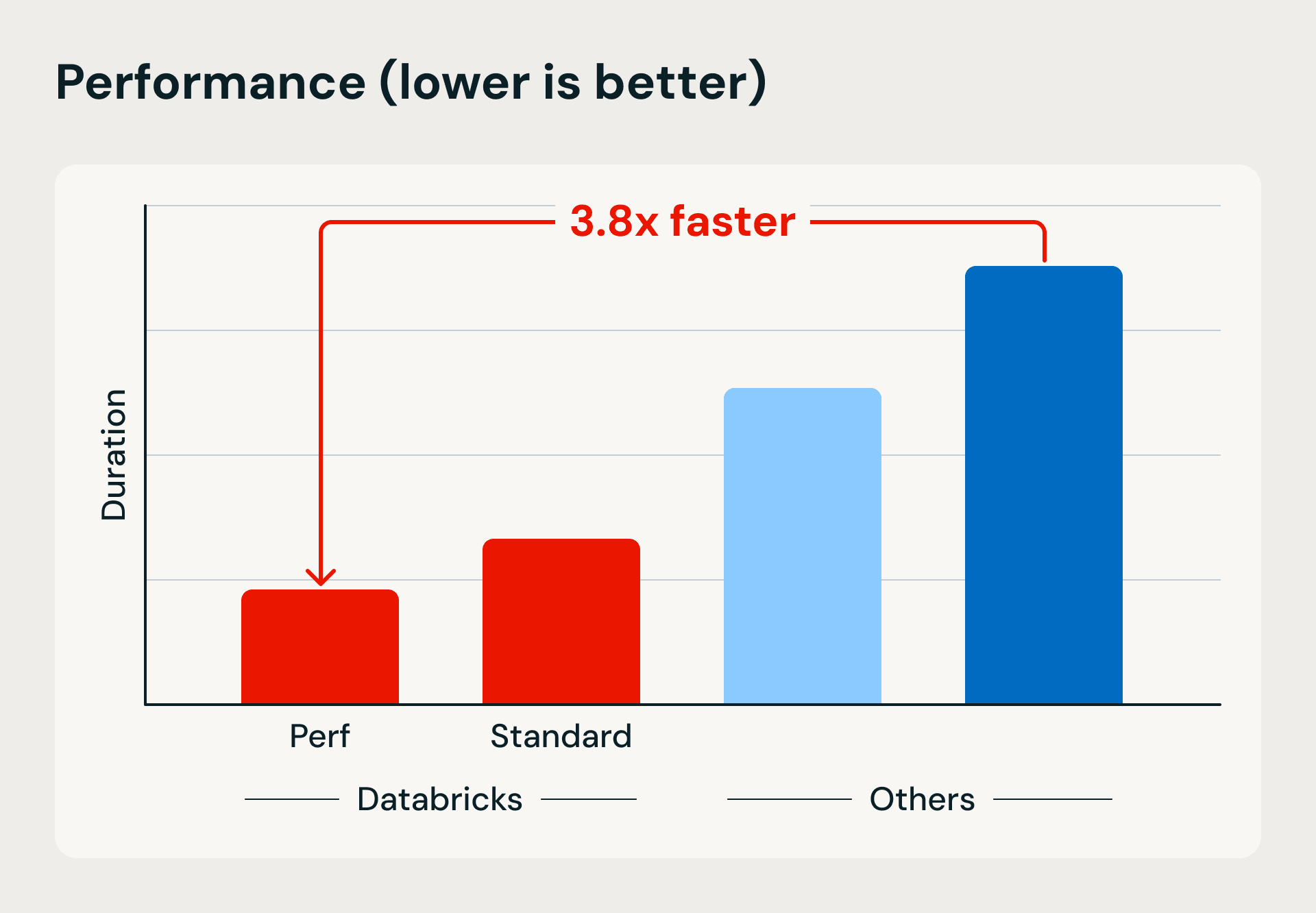
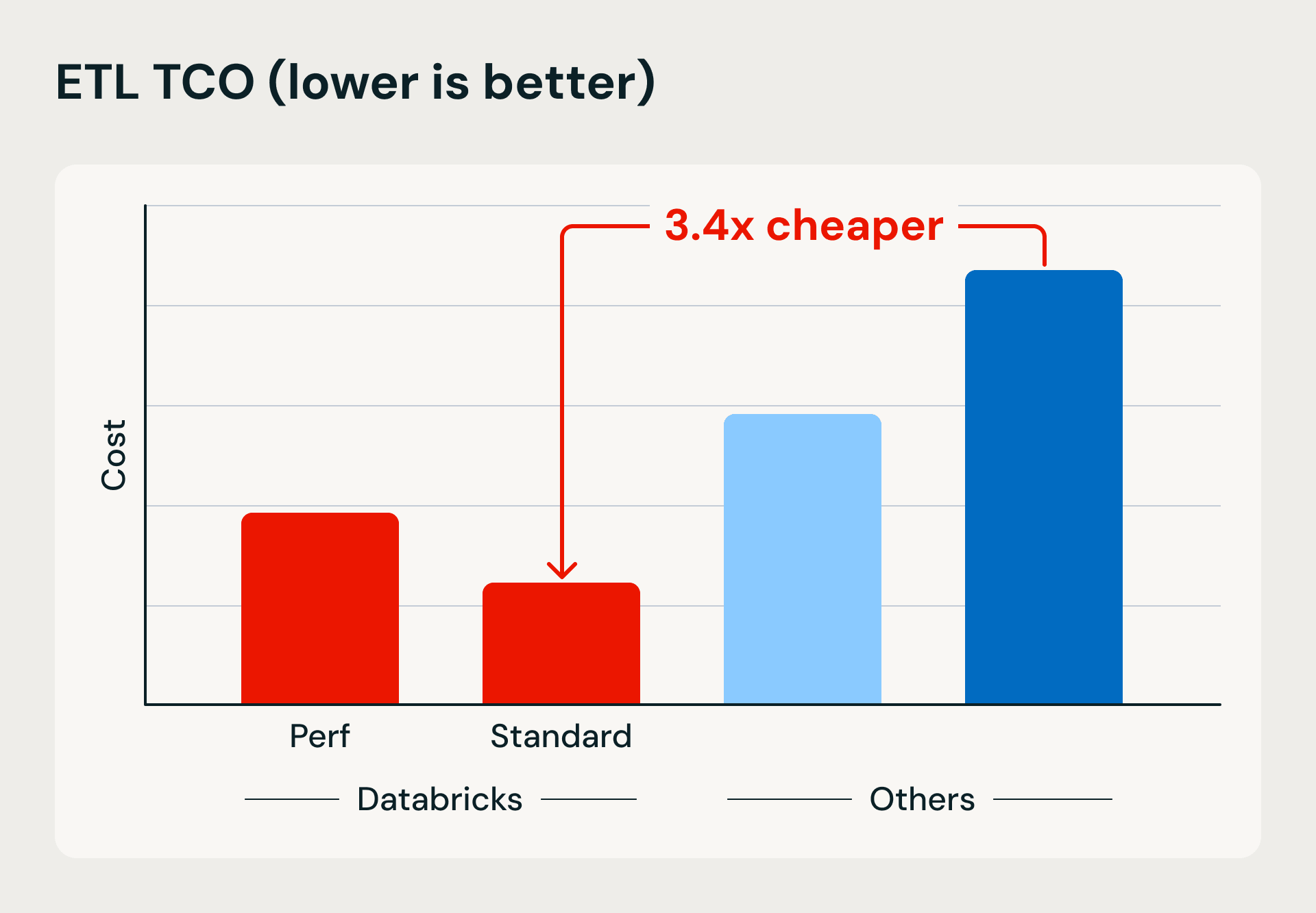
Comparación de rendimiento y costes que muestra las ventajas de la computación sin servidor de Databricks en velocidad de ejecución y eficiencia. El punto de referencia carga 1 TB en Bronze utilizando Lakeflow Jobs e inserciones basadas en combinación, luego refina y desduplica los datos en tablas Silver y Gold.
Después de la transición de nuestras canalizaciones de Databricks a la computación "sin servidor", HP se dio cuenta de un ahorro en la nube de más del 32 % y disminuyó el tiempo de ejecución combinado de los trabajos en un 36 %. La gestión de la infraestructura sin esfuerzo proporcionada por "sin servidor" hizo de esta decisión una opción obvia y estratégica. —Luis Alonso, jefe de estrategia e ingeniería de datos en HP Marketing
Las Spark Declarative Pipelines sin servidor en Google Cloud han redefinido nuestro enfoque en Uplight, lo que nos permite ejecutar cargas de trabajo de ETL más del doble de rápido manteniendo bajos los costes. La facilidad de uso, la optimización automática y la eficiencia de la computación sin servidor hacen que el escalado sea más manejable y nos permiten priorizar la entrega de valor a nuestros clientes. —Micaela Christopher, directora de ciencia de datos e ingeniería en Uplight
Históricamente, pasar de los datos sin procesar a la capa plateada nos llevaba unos 16 minutos, pero después de cambiar a sin servidor, solo tarda unos 7 minutos. —Aaron Jepsen, director de operaciones de TI en Jet Linx Aviation
La mejora significativa en el tiempo de inicio, combinada con la reducción de la configuración y el mantenimiento de DataOps, mejora enormemente la productividad y la eficiencia. —Gal Doron, jefe de datos en AnyClip
Serverless no requiere mantenimiento
Selección automática de infraestructura: eliminación de la gestión manual de clústeres
El enfoque clásico de la gestión de clústeres proporciona a los usuarios la mayor libertad para elegir una de las muchas combinaciones de configuración posibles y ajustar la configuración para satisfacer los requisitos cambiantes de datos y empresariales a lo largo del tiempo, incluida la prevención de errores de falta de memoria o cuellos de botella de rendimiento. La computación sin servidor cambia fundamentalmente el juego a través de la selección de infraestructura de IA. El sistema supervisa continuamente los patrones de carga de trabajo y la utilización de recursos, escalando automáticamente a instancias más grandes cuando se detectan restricciones de memoria y conmutando por error sin problemas a tipos de instancia compatibles durante las interrupciones del proveedor de nube. Al aprovechar el historial completo de la carga de trabajo y los datos de rendimiento en tiempo real, la computación sin servidor toma decisiones óptimas de infraestructura sin intervención humana, lo que resulta en un 89 % menos de interrupciones en comparación con los entornos de computación clásicos. Este enfoque automatizado no solo protege a los usuarios de las limitaciones del proveedor de nube, sino que también permite la corrección automática de problemas comunes de infraestructura, lo que convierte a la computación sin servidor en la oferta de computación más estable y fiable de Databricks.
Con sin servidor [...], hemos logrado una mejora de 3 a 5 veces en la latencia. Lo que antes tardaba 10 minutos ahora solo tarda de 2 a 3 minutos. —Bryce Dugar, gerente de ingeniería de datos en Cincinnati Reds
La disponibilidad de opciones sin servidor facilita la sobrecarga en el mantenimiento de la ingeniería y la optimización de costes. Este movimiento se alinea perfectamente con nuestra estrategia general para migrar todas las canalizaciones a entornos sin servidor dentro de Databricks. —Bala Moorthy, gerente sénior de ingeniería de datos en Compass
Actualizaciones versionless para mejoras automáticas de rendimiento y seguridad
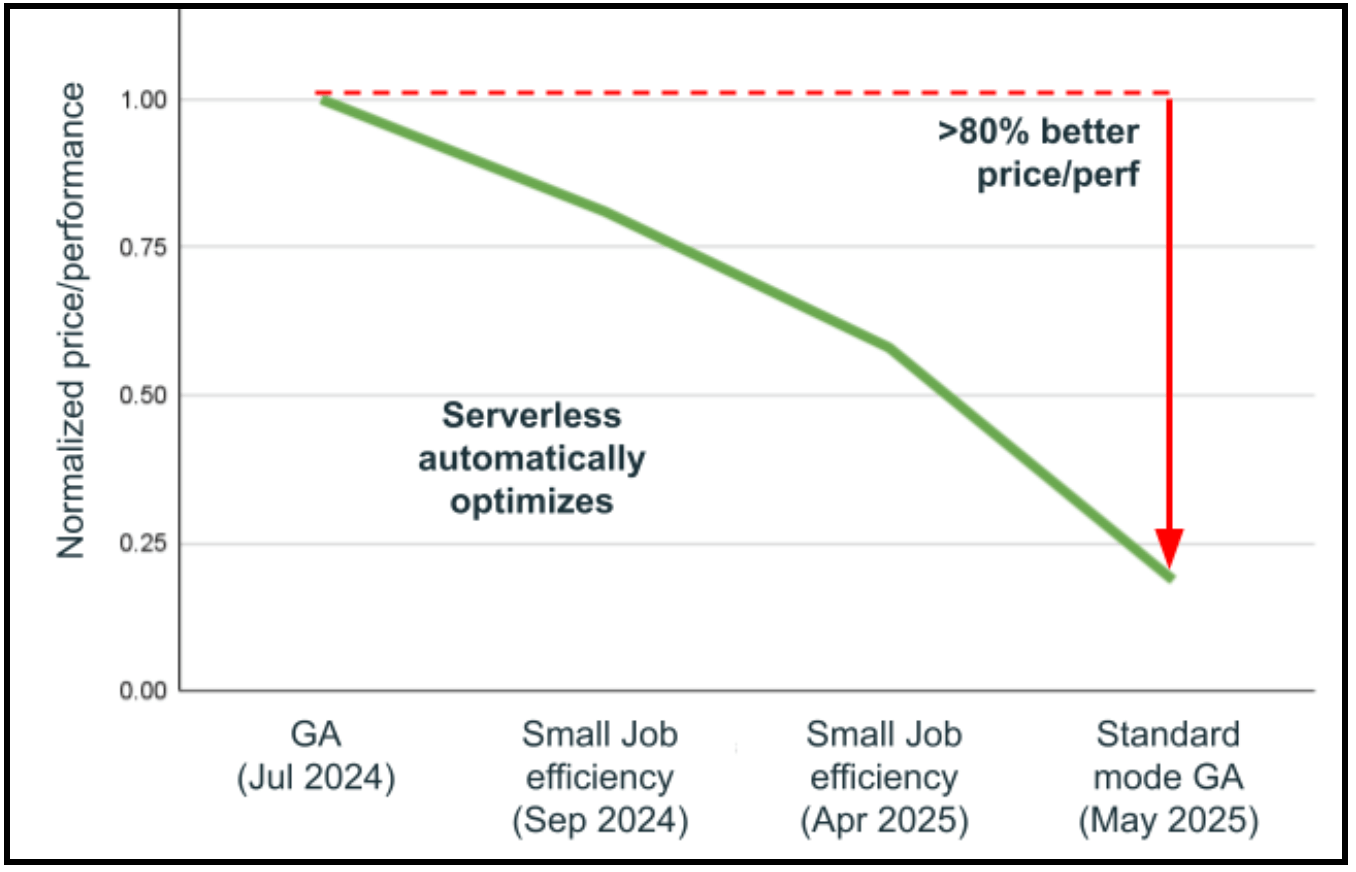
Quizás la capacidad más transformadora de la computación sin servidor es su arquitectura versionless, que elimina la necesidad de actualizaciones manuales del runtime (DBR). Mantenerse al día con el último runtime aporta mejoras significativas en el rendimiento. La computación sin servidor reimagina fundamentalmente este proceso a través de una arquitectura revolucionaria que permite el intercambio de DBR sin problemas sin ningún cambio importante. Solo en el último año, Databricks ha realizado automáticamente 25 actualizaciones de DBR en más de 4500 millones de cargas de trabajo con una extraordinaria tasa de éxito del 99,998 %. Incluso en los raros casos en que se detectan problemas, las cargas de trabajo se revierten automáticamente a la versión estable anterior mientras los problemas se resuelven en segundo plano, lo que garantiza operaciones ininterrumpidas. Los resultados hablan por sí solos: la combinación de mejoras automáticas en la selección de infraestructura y actualizaciones versionless ha conducido a un 80 % mejor de precio-rendimiento en menos de un año, sin requerir que los usuarios toquen la carga de trabajo. Este enfoque versionless significa que la computación sin servidor mejora continuamente, entregando automáticamente las últimas optimizaciones de Apache Spark, parches de seguridad y mejoras de rendimiento mientras los equipos de ingeniería de datos se centran por completo en la creación de valor empresarial en lugar de gestionar las actualizaciones de la infraestructura.
Más características sin servidor
La computación sin servidor ahora ofrece un conjunto completo de capacidades avanzadas, que incluyen:
- Los entornos basados en el área de trabajo permiten a los administradores gestionar de forma centralizada los entornos de usuario con almacenamiento en caché automático para un inicio rápido.
- La compatibilidad con trabajos de Scala aporta capacidades de desarrollo de IDE local con capacidades de implementación de JAR fat.
- La compatibilidad con GPU, incluyendo A10 y H100, y la compatibilidad con SparkML abren sin servidor al aprendizaje automático y las cargas de trabajo de GenAI.
- Suspender y reanudar facilita mucho el desarrollo y la depuración al poder tomar instantáneas de los estados de computación actuales y reanudar el trabajo más tarde sin perder ningún trabajo y sin tener que pagar por los clústeres.
- Las características mejoradas de gestión de costes incluyen límites de velocidad (próximamente), duración de consulta predicha con advertencias y tablas del sistema ampliadas para un análisis detallado de los costes.
Estas adiciones refuerzan la posición de la computación sin servidor como la plataforma de computación más capaz e inteligente para la ingeniería de datos, y solo estamos empezando.
Comience su viaje sin servidor hoy mismo
La evidencia es convincente: la computación sin servidor representa la evolución definitiva de la infraestructura de datos, ofreciendo una simplicidad, fiabilidad y optimización del rendimiento sin precedentes. Con el modo estándar disponible con carácter general y ofreciendo hasta un 70 % de ahorro de costes, nunca ha habido un mejor momento para la transición de la gestión compleja de clústeres a la computación inteligente y automatizada. Ya sea que necesite la ejecución ultrarrápida del modo optimizado para el rendimiento o la rentabilidad del modo estándar, la computación sin servidor elimina la complejidad de la infraestructura al tiempo que mejora continuamente sus cargas de trabajo a través de actualizaciones automáticas de DBR y mejoras de rendimiento.
- Regístrese para obtener una cuenta de Databricks sin servidor
- Computación sin servidor para Notebooks, Lakeflow Jobs y Spark Declarative Pipelines
- Guía para profesionales de la computación sin servidor
- Introducción a SDP
- Demostración de SDP
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.