Cinco pasos simples para implementar un esquema de estrella en Databricks con Delta Lake
Una forma actualizada para obtener consistentemente el mejor rendimiento de las bases de datos con esquema de estrella utilizadas en almacenes de datos y mercados de datos con Delta Lake
por Cary Moore, Lucas Bilbro y Brenner Heintz
- Use Delta Tables para crear sus tablas de hechos y de dimensiones.
- Use Liquid Clustering para proporcionar el mejor tamaño de archivo.
- Use Liquid Clustering en sus tablas de hechos.
Estamos actualizando este blog para mostrarles a los desarrolladores cómo aprovechar las últimas funciones de Databricks y los avances en Spark.
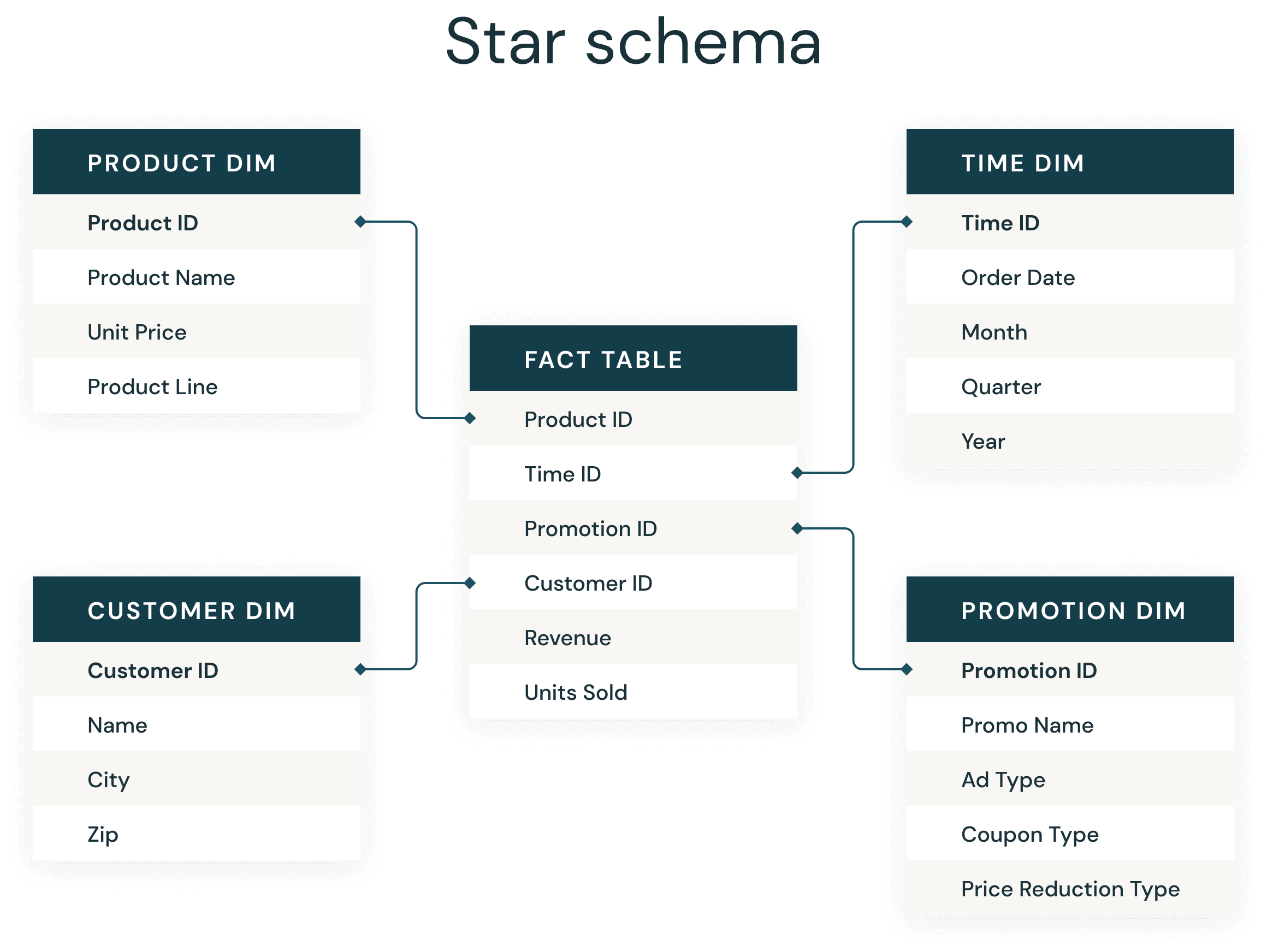
La mayoría de los desarrolladores de almacenes de datos están muy familiarizados con el omnipresente esquema en estrella. Introducido por Ralph Kimball en la década de 1990, un esquema en estrella se utiliza para desnormalizar los datos empresariales en dimensiones (como el tiempo y el producto) y hechos (como las transacciones en importes y cantidades). Un esquema de estrella almacena datos de manera eficiente, mantiene el historial y actualiza los datos al reducir la duplicación de definiciones de negocio repetitivas, lo que agiliza la agregación y el filtrado.
La implementación común de un esquema de estrella para respaldar las aplicaciones de inteligencia empresarial se ha vuelto tan rutinaria y exitosa que muchos modeladores de datos pueden hacerlo casi con los ojos cerrados. En Databricks, hemos producido tantas aplicaciones de datos y buscamos constantemente enfoques de mejores prácticas que sirvan como regla general, una implementación básica que nos garantice un gran resultado.
Al igual que en un data warehouse tradicional, existen algunas reglas generales sencillas que se deben seguir en Delta Lake y que mejorarán significativamente las uniones de su esquema de estrella de Delta.
Estos son los pasos básicos para el éxito:
- Usa Delta Tables para crear tus tablas de hechos y dimensiones
- Use Liquid Clustering para proporcionar el mejor tamaño de archivo
- Use Liquid Clustering en sus tablas de hechos
- Use Liquid Clustering en las claves de su tabla de dimensiones más grande y en los predicados probables.
- Aproveche Predictive Optimization para mantener las tablas y recopilar estadísticas
1. Use tablas Delta para crear sus tablas de hechos y dimensiones.
Delta Lake es una capa de formato de almacenamiento abierto que facilita las inserciones, actualizaciones, eliminaciones y agrega transacciones ACID en las tablas de su data lake, lo que simplifica el mantenimiento y las revisiones. Delta Lake también proporciona la capacidad de realizar la depuración dinámica de archivos para optimizar las consultas SQL y hacerlas más rápidas.
La sintaxis es simple en Databricks Runtimes 8.x y posteriores (el runtime actual de soporte a largo plazo es ahora el 15.4), donde Delta Lake es el formato de tabla predeterminado. Puede crear una tabla Delta con SQL de la siguiente manera:
CREATE TABLE MY_TABLE (COLUMN_NAME STRING) CLUSTER BY (COLUMN_NAME);
Antes del tiempo de ejecución 8.x, Databricks requería crear la tabla con la USING DELTA sintaxis.
Antes del tiempo de ejecución 8.x, Databricks requería crear la tabla con la sintaxis USING DELTA.
2. Usa Liquid Clustering para proporcionar el mejor tamaño de archivo
Dos de los mayores consumidores de tiempo en una consulta de Apache Spark™ son el tiempo que se dedica a leer datos del almacenamiento en la nube y la necesidad de leer todos los archivos subyacentes. Con la omisión de datos en Delta Lake, las consultas pueden leer selectivamente solo los archivos Delta que contienen datos relevantes, lo que ahorra una cantidad de tiempo considerable. La omisión de datos puede ayudar con la depuración estática de archivos, la depuración dinámica de archivos, la depuración estática de particiones y la depuración dinámica de particiones.
Antes del Liquid Clustering, esta era una configuración manual. Existían reglas generales para asegurarse de que los archivos tuvieran el tamaño adecuado y fueran eficientes para las consultas. Ahora, con Liquid Clustering, los tamaños de los archivos se determinan y se mantienen automáticamente con las rutinas de optimización.
Si está leyendo este artículo (o ha leído la versión anterior) y ya ha creado tablas con ZORDER, tendrá que volver a crear las tablas con Liquid Clustering.
Además, la agrupación Liquid se optimiza para evitar archivos demasiado pequeños o demasiado grandes (sesgo y equilibrio) y actualiza los tamaños de los archivos a medida que se anexan nuevos datos para mantener sus tablas optimizadas.
3. Usa Liquid Clustering en tus tablas de hechos
Para mejorar la velocidad de las consultas, Delta Lake admite la capacidad de optimizar el diseño de los datos almacenados en el almacenamiento en la nube con Liquid Clustering. Agrupe por las columnas que usaría en situaciones similares a los índices agrupados en el mundo de las bases de datos, aunque en realidad no son una estructura auxiliar. Una tabla agrupada por líquido agrupará los datos en la definición CLUSTER BY para que las filas con valores de columna similares de la definición CLUSTER BY se ubiquen en el conjunto óptimo de archivos.
La mayoría de los sistemas de bases de datos introdujeron la indexación como una forma de mejorar el rendimiento de las consultas. Los índices son archivos y, por lo tanto, a medida que los datos aumentan de tamaño, pueden convertirse en otro problema de big data que resolver. En su lugar, Delta Lake ordena los datos en los archivos Parquet para que la selección de rangos en el almacenamiento de objetos sea más eficiente. En combinación con el proceso de recopilación de estadísticas y el salto de datos, las tablas en clúster líquido son similares a las operaciones de búsqueda frente a las de examen en las bases de datos, lo que los índices resolvieron, sin crear otro cuello de botella informático para encontrar los datos que busca una consulta.
Para las tablas con agrupación Liquid, la mejor práctica es limitar el número de columnas en la cláusula CLUSTER BY a las 1-4 mejores. Elegimos las claves foráneas (claves foráneas por uso, no claves foráneas aplicadas por restricción) de las 3 dimensiones más grandes que eran demasiado grandes para transmitirse a los workers.
Por último, Liquid clustering reemplaza la necesidad de ZORDER y Partitioning, por lo que si utiliza Liquid clustering, ya no necesita, ni puede, particionar explícitamente las tablas al estilo Hive.
4. Use Liquid Clustering en las claves de su dimensión más grande y los predicados probables
Como está leyendo este blog, es probable que tenga dimensiones y que exista una clave subrogada o una clave primaria en sus tablas de dimensiones. Una clave que es un entero grande, que se valida y se espera que sea única. Después de Databricks Runtime 10.4, las columnas de identidad estuvieron disponibles de forma general y forman parte de la CREATE TABLE sintaxis.
Databricks también introdujo de manera no aplicada claves primarias y claves foráneas en Runtime 11.3 y son visibles en los clústeres y las áreas de trabajo habilitados para Unity Catalog.
Una de las dimensiones con las que trabajábamos tenía más de mil millones de filas y se benefició de la omisión de archivos y la eliminación dinámica de archivos después de agregar nuestros predicados a las tablas agrupadas. Nuestras dimensiones más pequeñas se agruparon en el campo de clave de dimensión y se transmitieron en la unión a los hechos. De forma similar al consejo sobre las tablas de hechos, limite el número de columnas en la cláusula Cluster By a los 1-4 campos de la dimensión que tienen más probabilidades de ser incluidos en un filtro además de la clave.
Además de la omisión de archivos y la facilidad de mantenimiento, el liquid clustering permite agregar más columnas que ZORDER y es más flexible que el particionamiento de estilo Hive.
5. Analiza la tabla para recopilar estadísticas para el optimizador de ejecución de consultas adaptable y habilita la optimización predictiva
Uno de los mayores avances en Apache Spark™ 3.0 fue la ejecución de consultas adaptables, o AQE para abreviar. A partir de Spark 3.0, AQE cuenta con tres características principales: la combinación de particiones post-shuffle, la conversión de sort-merge join a broadcast join y la optimización de skew join. Juntas, estas características permiten el rendimiento acelerado de los modelos dimensionales en Spark.
Para que AQE sepa qué plan elegir, necesitamos recopilar estadísticas sobre las tablas. Esto se hace emitiendo el comando ANALYZE TABLE. Los clientes han informado que la recopilación de estadísticas de las tablas ha reducido significativamente la ejecución de consultas para modelos dimensionales, incluidas las uniones complejas.
ANALYZE TABLE MY_BIG_DIM COMPUTE STATISTICS FOR ALL COLUMNS
Todavía puede utilizar la tabla Analyze como parte de sus rutinas de carga, pero ahora es mejor simplemente habilitar la Optimización predictiva en su cuenta, catálogo y esquema.
ALTER CATALOG [catalog_name] {ENABLE | DISABLE} PREDICTIVE OPTIMIZATION;
ALTER {SCHEMA | DATABASE} schema_name {ENABLE | DISABLE} PREDICTIVE OPTIMIZATION;
Optimización predictiva elimina la necesidad de gestionar manualmente las operaciones de mantenimiento para las tablas gestionadas de Unity Catalog en Databricks.
Con la optimización predictiva habilitada, Databricks identifica automáticamente las tablas que se beneficiarían de las operaciones de mantenimiento y las ejecuta para el usuario. Las operaciones de mantenimiento solo se ejecutan cuando es necesario, lo que elimina las ejecuciones innecesarias de operaciones de mantenimiento y la carga asociada con el seguimiento y la solución de problemas de rendimiento.
Actualmente, las Optimizaciones predictivas ejecutan Vacuum y Optimize en las tablas. Esté atento a las actualizaciones de la Optimización predictiva y manténgase al tanto de cuándo la característica incorporará el análisis de la tabla y la recopilación de estadísticas, además de aplicar automáticamente las claves de liquid clustering.
Conclusión
Al seguir las pautas anteriores, las organizaciones pueden reducir los tiempos de consulta; en nuestro ejemplo, mejoramos el rendimiento de las consultas 9 veces en el mismo clúster. Las optimizaciones redujeron en gran medida el I/O y garantizaron que solo procesáramos los datos necesarios. También nos beneficiamos de la estructura flexible de Delta Lake, ya que puede escalar y manejar los tipos de consultas que se enviarán ad hoc desde las herramientas de Business Intelligence.
Desde la primera versión de este blog, Photon ahora está activado de forma predeterminada para nuestro Databricks SQL Warehouse y está disponible en los clústeres de All Purpose y Jobs. Obtenga más información sobre Photon y el aumento de rendimiento que proporcionará a todas sus consultas de Spark SQL con Databricks.
Los clientes pueden esperar que el rendimiento de sus consultas ETL/ELT y SQL mejore al habilitar Photon en Databricks Runtime. Al combinar las prácticas recomendadas que se describen aquí con Databricks Runtime habilitado para Photon, puede esperar un rendimiento de consultas de baja latencia que puede superar a los mejores almacenes de datos en la nube.
Cree su base de datos de esquema de estrella con Databricks SQL hoy mismo.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.