Cómo crear espacios de Genie listos para producción y generar confianza en el proceso
Un recorrido para crear un espacio de Genie desde cero hasta que esté listo para producción, mejorando la precisión a través de la evaluación de benchmarks y la optimización sistemática
por Pulkit Pareek y Eric Lind
- Aprovecha los benchmarks para medir el nivel de preparación de tu Genie space de forma objetiva, en lugar de subjetiva.
- Sigue un ejemplo de extremo a extremo para desarrollar un Genie space listo para producción, que cubre muchas situaciones comunes de solución de problemas.
- Genera confianza con los usuarios finales al compartir los resultados finales de precisión de las preguntas que necesitan una respuesta correcta.
El desafío de la confianza en el análisis de autoservicio
Genie es una función de Databricks que permite a los equipos de negocio interactuar con sus datos usando lenguaje natural. Utiliza IA generativa adaptada a la terminología y los datos de tu organización, con la capacidad de supervisar y perfeccionar su rendimiento a través de los comentarios de los usuarios.
Un desafío común con cualquier herramienta de análisis de lenguaje natural es generar confianza en los usuarios finales. Piense en Sarah, una experta en el dominio de marketing, que prueba Genie por primera vez en lugar de sus paneles.
Sarah: "¿Cuál fue nuestra tasa de clics el trimestre pasado?"
Genie: 8.5%
El pensamiento de Sarah: Espera, recuerdo que celebramos cuando alcanzamos el 6 % el trimestre pasado...
Esta es una pregunta para la que Sarah sabe la respuesta, pero no está viendo el resultado correcto. Quizás la consulta generada incluyó diferentes campañas o usó una definición de calendario estándar para “último trimestre” cuando debería usar el calendario fiscal de la empresa. Pero Sarah no sabe qué está mal. El momento de incertidumbre ha generado dudas. Sin una evaluación adecuada de las respuestas, esta duda sobre la usabilidad puede crecer. Los usuarios vuelven a solicitar soporte de analistas, lo que interrumpe otros proyectos y aumenta el costo y el tiempo necesarios para generar una sola información valiosa. La inversión en autoservicio queda infrautilizada.
La pregunta no es solo si tu espacio de Genie puede generar SQL. Es si tus usuarios confían en los resultados lo suficiente como para tomar decisiones con ellos.
Para generar esa confianza, es necesario ir más allá de la evaluación subjetiva ("parece que funciona") y pasar a una validación medible ("lo hemos probado sistemáticamente"). Demostraremos cómo la función de benchmarks integrada de Genie transforma una implementación de base en un sistema listo para producción en el que los usuarios confían para tomar decisiones críticas. Los benchmarks proporcionan una forma basada en datos para evaluar la calidad de tu espacio de Genie y ayudan a abordar las brechas al momento de curar el espacio de Genie.
En este blog, te guiaremos a través de un ejemplo de un proceso de extremo a extremo para construir un espacio de Genie con benchmarks para desarrollar un sistema confiable.
Los datos: Análisis de campañas de marketing
Nuestro equipo de marketing necesita analizar el rendimiento de la campaña en cuatro conjuntos de datos interconectados.
- Prospectos: información de la empresa, como el sector y la ubicación
- Contactos: información del destinatario, incluido el departamento y el tipo de dispositivo
- Campañas: detalles de la campaña, incluidos el presupuesto, la plantilla y las fechas.
- Eventos: seguimiento de eventos de correo electrónico (envíos, aperturas, clics, reportes de spam)
El flujo de trabajo: Identificar empresas objetivo (prospectos) → encontrar contactos en esas empresas → enviar campañas de marketing → hacer un seguimiento de cómo responden los destinatarios a esas campañas (eventos).
Algunos ejemplos de preguntas que los usuarios debían responder son:
- "¿Qué campañas generaron el mejor ROI por industria?"
- "¿Cuál es nuestro riesgo de cumplimiento en los diferentes tipos de campaña?"
- "¿Cómo difieren los patrones de interacción (CTR) por dispositivo y departamento?"
- "¿Qué plantillas tienen el mejor rendimiento para segmentos específicos de clientes potenciales?"
Estas preguntas requieren unir tablas, calcular métricas específicas del dominio y aplicar conocimiento del dominio sobre lo que hace que una campaña sea "exitosa" o de "alto riesgo". Obtener las respuestas correctas es importante porque influyen directamente en la asignación del presupuesto, la estrategia de la campaña y las decisiones de cumplimiento. ¡Manos a la obra!
El recorrido: del desarrollo de la base de referencia a la producción
No se debe esperar que agregar tablas de forma anecdótica y un puñado de prompts de texto den como resultado un espacio de Genie lo suficientemente preciso para los usuarios finales. Una comprensión profunda de las necesidades de sus usuarios finales, combinada con el conocimiento de los datasets y las capacidades de la plataforma de Databricks, lo llevará a los resultados deseados.
En este ejemplo de extremo a extremo, evaluamos la precisión de nuestro espacio de Genie a través de benchmarks, diagnosticamos las brechas de contexto que causan respuestas incorrectas e implementamos soluciones. Considera este marco de trabajo para abordar el desarrollo y las evaluaciones de tu Genie.
- Defina su suite de benchmarks (el objetivo es tener de 10 a 20 preguntas representativas). Estas preguntas deben ser determinadas por expertos en la materia y los usuarios finales que se espera que utilicen Genie para la analítica. Idealmente, estas preguntas se crean antes de cualquier desarrollo real de su espacio de Genie.
- Establece tu precisión de referencia. Ejecuta todas las preguntas de benchmark en tu espacio solo con los objetos de datos de referencia agregados al espacio de Genie. Documenta la precisión, qué preguntas pasan, cuáles fallan y por qué.
- Optimiza sistemáticamente. Implementa un conjunto de cambios (p. ej., agregar descripciones de columna). Vuelve a ejecutar todas las preguntas del benchmark. Mide el impacto y las mejoras, y continúa el desarrollo iterativo siguiendo las prácticas recomendadas publicadas.
- Medir y comunicar. Ejecutar los benchmarks proporciona criterios de evaluación objetivos de que el espacio de Genie cumple suficientemente con las expectativas, lo que genera confianza en los usuarios y las partes interesadas.
Creamos un conjunto de 13 preguntas de referencia que representan lo que los usuarios finales buscan en nuestros datos de marketing. Cada pregunta de referencia es una pregunta realista en inglés sencillo, acompañada de una consulta SQL validada que la responde.
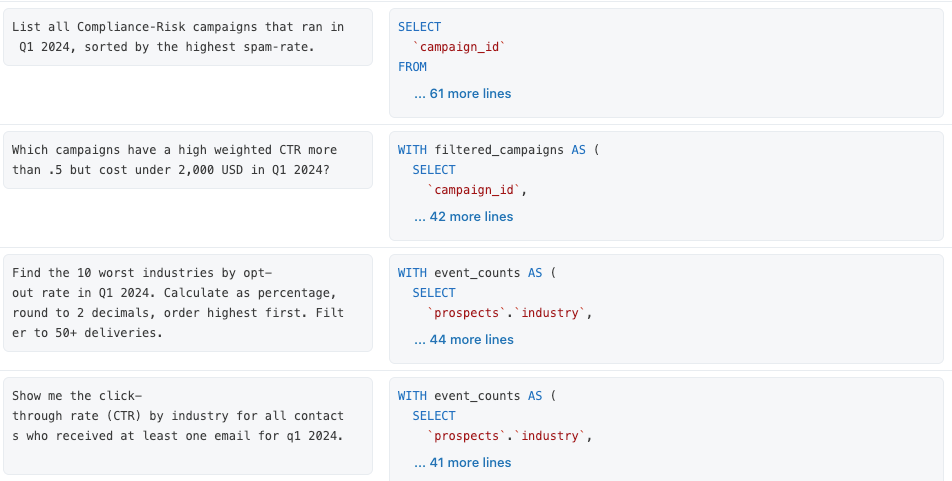
Por diseño, Genie no incluye estas consultas SQL de referencia como contexto existente. Se utilizan únicamente para la evaluación. Es nuestro trabajo proporcionar el contexto adecuado para que esas preguntas se puedan responder correctamente. ¡Manos a la obra!
Iteración 0: Establecer la base de referencia
Comenzamos intencionalmente con nombres de tabla deficientes como cmp y proc_delta, y nombres de columna como uid_seq (para campaign_id), label_txt (para campaign_name), num_val (para cost) y proc_ts (para event_date). Este punto de partida refleja lo que muchas organizaciones realmente enfrentan: datos modelados para convenciones técnicas en lugar de para un significado de negocio.
Las tablas por sí solas tampoco proporcionan contexto sobre cómo calcular los KPI y las métricas específicas del dominio. Genie sabe cómo aprovechar cientos de funciones de SQL integradas, pero aun así necesita las columnas y la lógica correctas para usarlas como entradas. Entonces, ¿qué sucede cuando Genie no tiene suficiente contexto?
Análisis comparativo: Genie no pudo responder correctamente ninguna de nuestras 13 preguntas de referencia. No porque la IA no fuera lo suficientemente potente, sino porque carecía de cualquier contexto relevante, como se muestra a continuación.

Información clave: Cada pregunta que hacen los usuarios finales depende de que Genie produzca una consulta de SQL a partir de los objetos de datos que usted proporciona. Por lo tanto, las malas convenciones de nomenclatura de datos afectarán a cada una de las consultas generadas. ¡No puede omitir la calidad fundamental de los datos y esperar generar confianza con los usuarios finales! Genie no genera una consulta de SQL para cada pregunta. Solo lo hace cuando tiene suficiente contexto. Este es un comportamiento esperado para evitar alucinaciones y respuestas engañosas.
Siguiente acción: Los puntajes bajos de los benchmarks iniciales indican que primero debes enfocarte en limpiar los objetos de Unity Catalog, así que comenzaremos por ahí.
Iteración 1: Significados de columna ambiguos
Mejoramos los nombres de las tablas a campaigns, events, contacts y prospects, y agregamos descripciones de tabla claras en Unity Catalog.

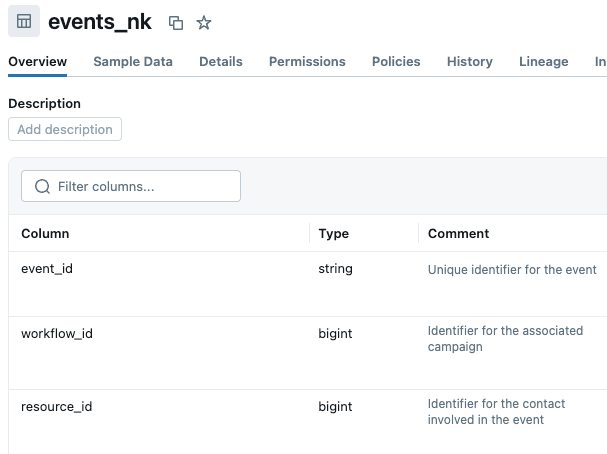
Sin embargo, nos encontramos con otro desafío relacionado: nombres de columnas o comentarios engañosos que sugieren relaciones que no existen.
Por ejemplo, columnas como workflow_id, resource_id y owner_id existen en varias tablas. Pareciera que deberían conectar las tablas entre sí, pero no lo hacen. La tabla events usa workflow_id como la clave foránea para las campañas (no para una tabla de flujos de trabajo separada), y resource_id como la clave foránea para los contactos (no para una tabla de recursos separada). Mientras tanto, campaigns tiene su propia columna workflow_id que no tiene ninguna relación. Si los nombres y las descripciones de estas columnas no se anotan correctamente, esto puede llevar a un uso incorrecto de esos atributos. Actualizamos las descripciones de las columnas en Unity Catalog para aclarar el propósito de cada una de esas columnas ambiguas. Nota: si no puedes editar los metadatos en UC, puedes agregar descripciones de tablas y columnas en el almacén de conocimiento del espacio de Genie.
Análisis de benchmarks: Las consultas simples de una sola tabla empezaron a funcionar gracias a nombres y descripciones claros. Preguntas como "Contar eventos por tipo en 2023" y "¿Qué campañas comenzaron en los últimos tres meses?" ahora recibían respuestas correctas. Sin embargo, cualquier consulta que requiriera uniones (joins) entre tablas fallaba; Genie aún no podía determinar correctamente qué columnas representaban relaciones.
Observación: Las convenciones de nomenclatura claras ayudan, pero sin definiciones explícitas de relaciones, Genie debe adivinar qué columnas conectan las tablas. Cuando varias columnas tienen nombres como workflow_id o resource_id, estas suposiciones pueden llevar a resultados incorrectos. Los metadatos adecuados sirven como base, pero las relaciones deben definirse explícitamente.
Siguiente acción: Define las relaciones de unión entre tus objetos de datos. Nombres de columna como id o resource_id aparecen todo el tiempo. Aclaremos exactamente cuáles de esas columnas hacen referencia a otros objetos de tabla.
Iteración 2: Modelo de datos ambiguo
La mejor manera de aclarar qué columnas debe usar Genie al unir tablas es mediante el uso de claves primarias y foráneas. Agregamos restricciones de clave primaria y foránea en Unity Catalog para indicarle explícitamente a Genie cómo se conectan las tablas: campaigns.campaign_id se relaciona con events.campaign_id, que se vincula con contacts.contact_id, que se conecta con prospects.prospect_id. Esto elimina las conjeturas y dicta cómo se crean las uniones de múltiples tablas de forma predeterminada. Nota: si no puede editar las relaciones en UC o si la relación de la tabla es compleja (p. ej., múltiples condiciones JOIN), puede definirlas en el almacén de conocimiento del espacio de Genie.
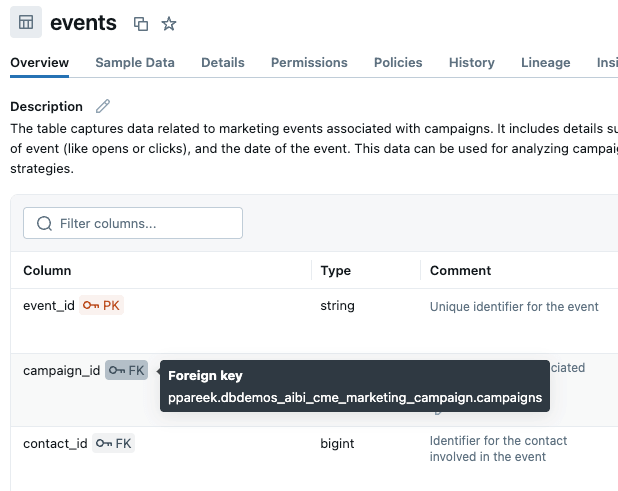
Como alternativa, podríamos considerar la creación de una vista de métricas que puede incluir los detalles de la unión (join) explícitamente en la definición del objeto. Más sobre eso más adelante.
Análisis comparativo: Progreso constante. Las preguntas que requerían uniones entre varias tablas comenzaron a funcionar: "Show campaign costs by industry for Q1 2024" y "Which campaigns had more than 1,000 events in January?" ahora se ejecutaron con éxito.
Observación: Las relaciones permiten las consultas complejas de varias tablas que aportan un valor de negocio real. Genie está generando SQL estructurado correctamente y haciendo cosas simples como sumas de costos y recuentos de eventos de forma correcta.
Acción: De los benchmarks incorrectos restantes, muchos de ellos incluyen referencias a valores que los usuarios pretenden aprovechar como filtros de datos. La forma en que los usuarios finales hacen las preguntas no coincide directamente con los valores que aparecen en el dataset.
Iteración 3: comprender los valores de los datos
Un espacio de Genie debe ser curado para responder preguntas específicas del dominio. Sin embargo, las personas no siempre hablan usando exactamente la misma terminología que la forma en que aparecen nuestros datos. Los usuarios pueden decir "empresas de bioingeniería", pero el valor de los datos es "biotecnología".
Habilitar los diccionarios de valores y el muestreo de datos produce una búsqueda más rápida y precisa de los valores tal como existen en los datos, en lugar de que Genie use solo el valor exacto según lo solicitado por el usuario final.

Los valores de ejemplo y los diccionarios de valores ahora están activados de forma predeterminada, pero vale la pena corroborar que las columnas correctas que se usan comúnmente para filtrar estén habilitadas y tengan diccionarios de valores personalizados cuando sea necesario.
Análisis de benchmark: más del 50 % de las preguntas de benchmark ahora obtienen respuestas exitosas. Las preguntas que involucran valores de categoría específicos, como “biotecnología”, comenzaron a identificar correctamente esos filtros. Ahora, el desafío es implementar métricas y agregaciones personalizadas. Por ejemplo, Genie proporciona una mejor estimación sobre cómo calcular el CTR, basándose en que encuentra “clic” como un valor de datos y en su comprensión de las métricas basadas en tasas. Pero no tiene la confianza suficiente como para simplemente generar las consultas:
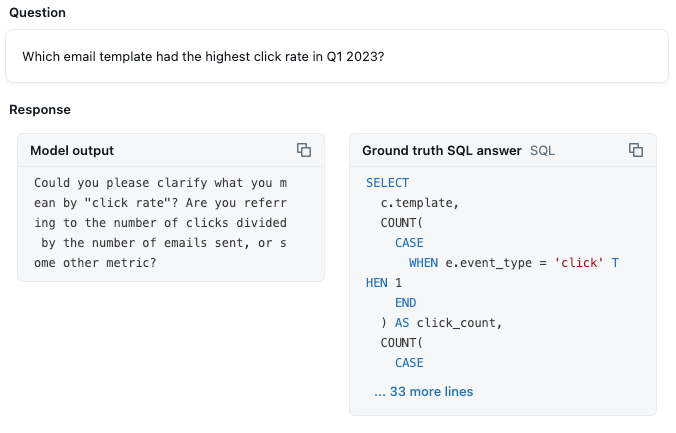
Esta es una métrica que queremos que se calcule correctamente el 100 % de las veces, por lo que debemos aclarar ese detalle para Genie.
Información: el muestreo de valores mejora la generación de SQL de Genie, ya que proporciona acceso a valores de datos reales. Cuando los usuarios hacen preguntas conversacionales con errores de ortografía o terminología diferente, el muestreo de valores ayuda a Genie a hacer coincidir las instrucciones con los valores de datos reales en tus tablas.
Próxima acción: El problema más común ahora es que Genie todavía no genera el SQL correcto para nuestras métricas personalizadas. Abordemos nuestras definiciones de métricas de forma explícita para lograr resultados más precisos.
Iteración 4: Definición de métricas personalizadas
En este punto, Genie tiene contexto para los atributos de datos categóricos que existen en los datos, puede filtrar nuestros valores de datos y realizar agregaciones sencillas a partir de funciones SQL estándar (p. ej., “count events by type” usa COUNT()). Para agregar más claridad sobre cómo Genie debería calcular nuestras métricas, agregamos consultas SQL de ejemplo a nuestro espacio de Genie. Este ejemplo demuestra la definición correcta de la métrica para el CTR:
Ten en cuenta que se recomienda dejar comentarios en tus consultas SQL, ya que es un contexto relevante junto con el código.
Análisis de benchmark: Esto produjo la mayor mejora de precisión individual hasta ahora. Considere que nuestro objetivo es hacer que Genie sea capaz de responder preguntas a un nivel muy detallado para una audiencia definida. Se espera que la mayoría de las preguntas de los usuarios finales se basen en métricas personalizadas, como el CTR, las tasas de spam, las métricas de engagement, etc. Lo que es más importante, las variaciones de estas preguntas también funcionaron. Genie aprendió la definición de nuestra métrica y la aplicará a cualquier consulta en el futuro.
Información: Las consultas de ejemplo enseñan una lógica de negocio que los metadatos por sí solos no pueden transmitir. Una consulta de ejemplo bien elaborada suele resolver simultáneamente toda una categoría de brechas de referencia. Esto aportó más valor que cualquier otro paso de iteración individual hasta ahora.
Próxima acción: solo algunas preguntas de benchmark siguen siendo incorrectas. Tras una inspección más detallada, notamos que los benchmarks restantes están fallando por dos razones:
- Los usuarios hacen preguntas sobre atributos de datos que no existen directamente en los datos. Por ejemplo, “¿cuántas campañas generaron un CTR alto en el último trimestre?” Genie no sabe a qué se refiere un usuario con un CTR “alto” porque no existe ningún atributo de datos.
- Estas tablas de datos incluyen registros que deberíamos excluir. Por ejemplo, tenemos muchas campañas de prueba que no se envían a los clientes. Necesitamos excluirlos de nuestros KPI.
Iteración 5: Documentación de reglas específicas del dominio
Estas lagunas restantes son elementos de contexto que se aplican de forma global a cómo deben crearse todas nuestras consultas y se relacionan con valores que no existen directamente en nuestros datos.
Tomemos ese primer ejemplo sobre un CTR alto, o algo similar como las campañas de alto costo. No siempre es fácil, ni siquiera recomendable, agregar datos específicos del dominio a nuestras tablas, por varias razones:
- Realizar cambios, como agregar un campo
campaign_cost_segmentation(alto, medio, bajo) a las tablas de datos, tomará tiempo e impactará otros procesos, ya que tanto los esquemas de las tablas como los pipelines de datos deben modificarse. - Para cálculos agregados como el CTR, a medida que fluyen nuevos datos, los valores del CTR cambiarán. De todos modos, no deberíamos precalcular este cálculo; queremos que se haga sobre la marcha mientras aclaramos los filtros, como los períodos de tiempo y las campañas.
Por lo tanto, podemos usar una instrucción basada en texto en Genie para que realice por nosotros esta segmentación específica del dominio.

Del mismo modo, podemos especificar cómo Genie debe escribir siempre las consultas para alinearlas con las expectativas del negocio. Esto puede incluir cosas como calendarios personalizados, filtros globales obligatorios, etc. Por ejemplo, estos datos de campaña incluyen campañas de prueba que deben excluirse de nuestros cálculos de KPI.


Análisis de referencia: ¡100 % de precisión de referencia! Los casos extremos y las preguntas basadas en umbrales empezaron a funcionar de manera consistente. Las preguntas sobre "campañas de alto rendimiento" o "campañas con riesgo de incumplimiento" ahora aplicaron nuestras definiciones de negocio correctamente.
Idea clave: Las instrucciones basadas en texto son una forma sencilla y eficaz de llenar cualquier vacío que haya quedado de los pasos anteriores para garantizar que se generen las consultas correctas para los usuarios finales. Sin embargo, no debería ser el primer ni el único lugar en el que confíes para la inyección de contexto.
Nota: puede que no sea posible alcanzar una precisión del 100 % en algunos casos. Por ejemplo, a veces las preguntas de benchmark requieren consultas muy complejas o múltiples prompts para generar la respuesta correcta. Si no puedes crear fácilmente una única consulta SQL de ejemplo, simplemente anota esta deficiencia al compartir los resultados de tu evaluación del benchmark con otros. La expectativa típica es que los benchmarks de Genie superen el 80 % antes de pasar a las pruebas de aceptación del usuario (UAT).
Siguiente acción: ahora que Genie alcanzó el nivel de precisión que esperábamos en nuestras preguntas de referencia, pasaremos a la UAT para recopilar más comentarios de los usuarios finales.
(Opcional) Iteración 6: Precalculando métricas complejas
Para nuestra iteración final, creamos una vista personalizada que predefine las métricas de marketing clave y aplicamos clasificaciones de negocio. Crear una vista o una vista de métricas puede ser más sencillo en los casos en que todos tus datasets encajan en un único modelo de datos y tienes docenas de métricas personalizadas. Es más fácil encajar todo eso en la definición de un objeto de datos, en lugar de escribir una consulta SQL de ejemplo para cada uno de ellos específica para el espacio de Genie.
Resultado del benchmark: Aun así, logramos una precisión del 100 % en el benchmark usando vistas en lugar de solo tablas base, porque el contenido de los metadatos se mantuvo igual.
Información clave: En lugar de explicar cálculos complejos a través de ejemplos o instrucciones, puede encapsularlos en una vista o una vista de métricas y, así, definir una única fuente de verdad.
Lo que aprendimos: el impacto del desarrollo basado en benchmarks
No existe una "solución mágica" para configurar un espacio de Genie que lo resuelva todo. La precisión lista para la producción generalmente solo se logra cuando se tienen datos de alta calidad, metadatos enriquecidos adecuadamente, una lógica de métricas definida y un contexto específico del dominio inyectado en el espacio. En nuestro ejemplo de extremo a extremo, encontramos problemas comunes que abarcaban todas estas áreas.
Los benchmarks son fundamentales para evaluar si tu espacio cumple con las expectativas y está listo para recibir los comentarios de los usuarios. También guio nuestros esfuerzos de desarrollo para abordar las deficiencias en la interpretación de las preguntas de Genie. En revisión:
- Iteraciones 1-3: 54 % de precisión de referencia. Estas iteraciones se centraron en que Genie tuviera un conocimiento más claro de nuestros datos y metadatos. Implementar nombres de tabla, descripciones de tabla, descripciones de columna y claves de unión adecuados, y habilitar valores de ejemplo son pasos fundamentales para cualquier espacio de Genie. Con estas capacidades, Genie debería identificar correctamente la tabla, las columnas y las condiciones de unión correctas que afectan a cualquier consulta que genere. También puede hacer agregaciones y filtrados sencillos. Genie pudo responder correctamente a más de la mitad de nuestras preguntas de referencia específicas del dominio solo con este conocimiento fundamental.
- Iteración 4 - 77 % de precisión del benchmark. Esta iteración se centró en aclarar las definiciones de nuestras métricas personalizadas. Por ejemplo, el CTR no es parte de todas las preguntas de benchmark, pero es un ejemplo de una métrica no estándar (es decir, sum(), avg(), etc.) que necesita responderse correctamente siempre.
- Iteración 5: Precisión del 100 % en el benchmark. En esta iteración se demostró el uso de instrucciones basadas en texto para subsanar las imprecisiones restantes. Estas instrucciones abarcaron situaciones comunes, como la inclusión de filtros globales en los datos para uso analítico y definiciones específicas del dominio (p. ej., qué hace que una campaña tenga una altainteracción) e información específica de los calendarios fiscales.
Al seguir un enfoque sistemático para evaluar nuestro espacio de Genie, detectamos el comportamiento no deseado de las consultas de forma proactiva, en lugar de enterarnos por Sarah de forma reactiva. Transformamos la evaluación subjetiva ("parece que funciona") en una medición objetiva ("validamos que funciona para 13 escenarios representativos que cubren nuestros casos de uso clave, tal como los definieron inicialmente los usuarios finales").
El camino a seguir
Generar confianza en la analítica de autoservicio no se trata de alcanzar la perfección el primer día. Se trata de la mejora sistemática con una validación medible. Se trata de detectar los problemas antes de que lo hagan los usuarios.
La función Benchmarks proporciona la capa de medición que hace que esto sea posible. Transforma el enfoque iterativo que recomienda la documentación de Databricks en un proceso cuantificable y que genera confianza. Repasemos este proceso de desarrollo sistemático basado en benchmarks:
- Crea preguntas de referencia (intenta crear entre 10 y 15) que representen las preguntas realistas de tus usuarios
- Prueba tu espacio para establecer una precisión de referencia.
- Realice mejoras en la configuración siguiendo el enfoque iterativo que Databricks recomienda en nuestras mejores prácticas
- Vuelva a probar todos los puntos de referencia después de cada cambio para medir el impacto e identificar brechas de contexto a partir de las preguntas incorrectas. Documente el progreso de la precisión para generar confianza en las partes interesadas.
Comienza con bases sólidas de Unity Catalog. Agrega contexto de negocio. Prueba de forma exhaustiva mediante benchmarks. Mide cada cambio. Genera confianza a través de la precisión validada.
¡Usted y sus usuarios finales se beneficiarán!
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.